100天的ML day04-06 逻辑回归
Table of Contents
逻辑回归简介
什么是逻辑回归
如何工作
Sigmoid函数
做出预测
逻辑回归VS线性回归
实现
步骤1:数据预处理
步骤2:逻辑回归模型
步骤3:预测
步骤4:评估预测结果
相关知识点
特征缩放处fit_transform()和transform()的区别。
混淆矩阵简介
range()和numpy.arange()函数区别
numpy.meshgrid()
numpy.array()
numpy.ravel
plt.coutourf()和plt.coutourf()的简介和区别
逻辑回归简介
什么是逻辑回归
用途:处理不同的分类问题。
目的:预测当前被观察的对象属于哪个组。
输出:提供一个离散的二进制输出。
例子:判断一个人是否会在即将到来的选举中进行投票。
如何工作
逻辑回归使用基础逻辑函数通过估算概率来测量因变量(我们想要预测的标签)和一个或者多个自变量之间的关系。
Sigmoid函数
Sigmoid函数是一个S形曲线,可以实现将任意真实值映射为值域范围为0-1的值,但不局限于这些限制。
做出预测
这些概率值必须转换为二进制数,以便实际中进行预测。这是逻辑函数的任务,也被称为sigmoid函数。然后使用阈值分类器将(0,1)范围的值转化成0和1的值来表示结果。
逻辑回归VS线性回归
逻辑回归给出离散的输出结果,然而线性回归给出的是连续的输出结果。
实现
步骤1:数据预处理
- 导入库
- 导入数据集
- 将数据集分为训练集和测试集
- 进行特征缩放
#导入库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
#导入数据集
dataset = pd.read_csv('./datasets/Social_Network_Ads.csv')
print(dataset)
X = dataset.iloc[:,[2, 3]].values #X只包含Age列和EstimatedSalary列
Y = dataset.iloc[:,4].values
#将数据集分为训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size = 0.25,random_state = 0)
#特征缩放
from sklearn.preprocessing import StandardScaler
# 标准化数据,保证每个维度的特征数据方差为1,均值为0,使得预测结果不会被某些维度过大的特征值而主导
sc = StandardScaler()
#fit_transform()先拟合数据再标准化
X_train = sc.fit_transform(X_train)
#transform()将数据标准化
X_test = sc.transform(X_test)
步骤2:逻辑回归模型
#步骤2:逻辑回归模型
from sklearn.linear_model import LogisticRegression
classifier = LogisticRegression()
classifier.fit (X_train, y_train)步骤3:预测
#步骤3: 预测
y_pred = classifier.predict(X_test)步骤4:评估预测结果
- 生成混淆矩阵 sklearn.metrics的confusion_matrix函数
- 画等高线图
- 训练集可视化
- 测试集可视化
- 先通过np.meshgrid(x,y)转换为网格数据(x,y为ndarray),因为等高线的显示是在网格的基础上添加上高度值
- 然后利用plt.contourf(X,Y,f(x,y))填充等高线
#评估评测结果
#生成混淆矩阵
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
#print(cm)
#[[65 3]
# [ 8 24]]
#可视化
from matplotlib.colors import ListedColormap
X_set, y_set = X_train, y_train
#
X1,X2 = np.meshgrid(np.arange(start=X_set[:,0].min()-1, stop = X_set[:,0].max()+1, step = 0.01),
np.arange(start=X_set[:,1].min()-1, stop = X_set[:,1].max()+1, step = 0.01)) #为什么最大最小值要减一加一
plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(),X2.ravel()]).T).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap(('red', 'green'))) #cmp意思是color map
plt.xlim(X1.min(),X1.max())
plt.ylim(X2.min(),X2.max())
for i,j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j,0],X_set[y_set==j,1],
c = ListedColormap(('red','green'))(i), label = j)
plt.title('LOGISTIC(Training set)')
plt.xlabel ('Age')
plt.ylabel(' Estimated Salary')
plt.legend()
plt.show()
X_set,y_set=X_test,y_test
X1,X2=np. meshgrid(np. arange(start=X_set[:,0].min()-1, stop=X_set[:, 0].max()+1, step=0.01),
np. arange(start=X_set[:,1].min()-1, stop=X_set[:,1].max()+1, step=0.01))
plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(),X2.ravel()]).T).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap(('red', 'green')))
plt.xlim(X1.min(),X1.max())
plt.ylim(X2.min(),X2.max())
for i,j in enumerate(np. unique(y_set)):
plt.scatter(X_set[y_set==j,0],X_set[y_set==j,1],
c = ListedColormap(('red', 'green'))(i), label=j)
plt. title(' LOGISTIC(Test set)')
plt. xlabel(' Age')
plt. ylabel(' Estimated Salary')
plt. legend() #显示标签
plt. show()
相关知识点
特征缩放处fit_transform()和transform()的区别。
https://blog.csdn.net/quiet_girl/article/details/72517053
先对X_train进行fit,找到找到均值μ和方差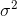 ,即找到了转换规则,然后分别对X_train和X_test进行transform()标准化数据。
,即找到了转换规则,然后分别对X_train和X_test进行transform()标准化数据。
混淆矩阵简介
- 定义:混淆矩阵也称误差矩阵,是表示精度评价的一种标准格式,用n行n列的矩阵形式来表示。
- 简介:混淆矩阵的每一列代表了预测类别,每一列的总数表示预测为该类别的数据的数目;每一行代表了数据的真实归属类别,每一行的数据总数表示该类别的数据实例的数目。
- cm = confusion_matrix(y_test, y_pred)本例生成混淆矩阵处的输出结果
[[65 3]
[ 8 24]]含义:
两行两列表示输出类别有两类,本例为0、1.
每一行之和表示类别的真实样本数量,每一列之和表示被预测为该类别的样本数量。
本例第一行说明有68个样本实际是第一类,其中65个属于第一类的样本被正确预测为了第一类,有3个属于第一类的样本被错误预测为了第二类。
第一列表示预测有73个样本属于第一类,其中65个属于第一类的样本被正确预测为了第一类,8个属于第二类的样本被错误预测为了第一类。
- 特征:混淆矩阵的正确分类都在矩阵的对角线上。
range()和numpy.arange()函数区别
- range()是python的内置函数,其返回值是range对象(迭代值),可用于生成秩为1的数组。(不支持步长为小数)
- arange()是Numpy库中的函数,其返回值是ndarray对象,常用于循环。(支持步长为小数)
- 两者都有三个参数[start,end,step)
numpy.meshgrid()
-
X1,X2=np.meshgrid(np. arange(start=X_set[:,0].min()-1, stop=X_set[:, 0].max()+1, step=0.01), np. arange(start=X_set[:,1].min()-1, stop=X_set[:,1].max()+1, step=0.01)) - Return coordinate matrices from coordinate vectors。 从坐标向量返回坐标矩阵
- Make N-D coordinate arrays for vectorized evaluations of N-D scalar/vector fields over N-D grids, given one-dimensional coordinate arrays x1, x2,…, xn. 在给定一维坐标阵x1、x2、…、xn的情况下,建立N-D坐标阵,在N-D网格上对N-D标量场/向量场进行矢量化计算。
numpy.array()
- Numpy提供的最重要的数据结构是一个称为Numpy数组的强大对象,被称为ndarrays.
- 使用array()函数可以创建一维、二维....数组。
- numpy中文文档 https://www.numpy.org.cn/article/index.html
numpy.ravel
- api https://docs.scipy.org/doc/numpy/reference/generated/numpy.ravel.html
- 用于将多维数组降至一维数组,ravel()返回的是视图,如果对这个返回的视图修改,原始矩阵也会被修改。
- 区别numpy.flatten()。返回的是拷贝,对拷贝进行修改不会影响原始矩阵。
plt.coutourf()和plt.coutourf()的简介和区别
- 都是画三维等高线图,不同点在于coutourf会对等高线间的区域进行填充。https://blog.csdn.net/cymy001/article/details/78513712
- f:filled,即对等高线间的填充区域进行填充(使用不同颜色)
- 通过这两天的学习,发现如果遇到一个陌生的函数库或者方法,查看api进行学习是最有效率的方法。
- plt.contourf的api https://matplotlib.org/api/_as_gen/matplotlib.pyplot.contourf.html#matplotlib.pyplot.contourf
-
plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(),X2.ravel()]).T).reshape(X1.shape), alpha = 0.75, cmap = ListedColormap(('red', 'green'))) #.T表转置 cmap表填充的颜色