在物体检测任务上进行预训练的实验分析

©PaperWeekly 原创 · 作者|费玥姣
学校|西湖大学博士生
研究方向|视频预测

论文标题:An Analysis of Pre-Training on Object Detection
论文链接:https://arxiv.org/abs/1904.05871

摘要
本工作主要将在物体检测上进行预训练的 CNN 模型在不同的视觉任务上的结果进行分析:
在大的数据集(包括 OpenImagesV4, ImageNet Localization and COCO)预训练检测器,再将特征用到分类、分割、小数据集检测上(比如 PASCAL-VOC, Caltech-256, SUN-397, Flowers-102)。
分析的结果:
OD 预训练对于小数据集的 OD 有很好的效果
OD 预训练有利于分割但是不利于分类
检测中的图像特征和分类中的更接近,但是反之不是
神经元可视化反应分割网络更注重整体而分类网络更注重细节

简介
对于多种视觉任务如物体检测、图像分割、图片分类等,通常会在大型数据集上进行预训练,实验证明预训练往往能帮助模型获得更好的结果,更快收敛。
然后预训练往往基于图像分类任务,在大型的分类数据集(如 ImageNet,Places,JFT 等)上进行,再迁移到其他任务或者数据集上进行 finetune,而很少在物体检测任务上预训练。但是分类任务是物体检测的子任务,我们是否可以猜想物体检测模型获得比分类很丰富的特征?

分析
预训练步骤:

Finetune数据集:

3.1 物体检测的Finetune:
检测预训练在 PASCAL-VOC 上 finetune 后,在不同 IoU 阈值上都有提升。
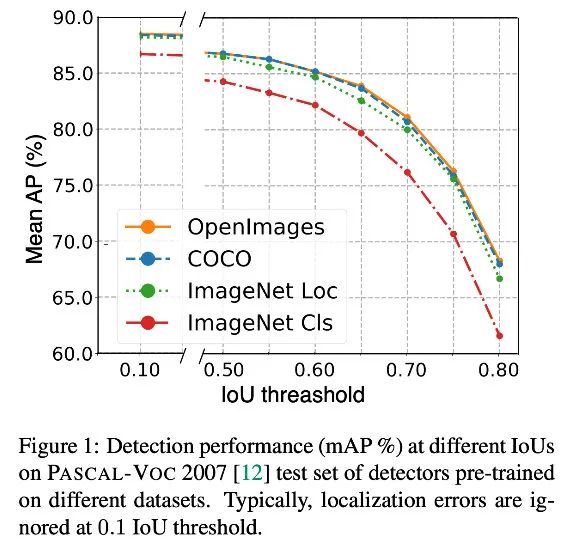
尤其在大 IoU 阈值,OD 预训练能够提高更多 mAP,在 PASCAL-VOC 数据集上,IoU=0.7 时提高了 4.8mAP,IoU=0.5 时只提高 2.2mAP。

并且 OpenImage 预训练模型能更好的处理遮挡情况。

3.2 语义分割
Baseline:还是 Deformable ConvNets 作为 Backbone 模型,在 PASCAL-VOC 2012 进行语义分割 finetune,结果发现有 3 个点的提升:

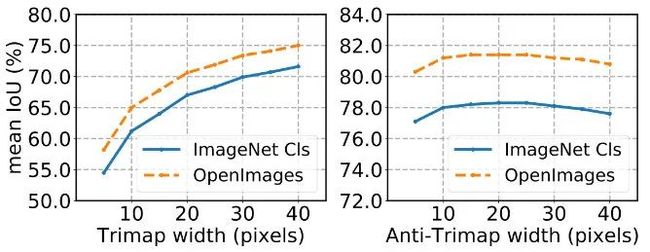
进行了 trimap experiment 判断这个提升是否是由于边缘像素点的分割效果更好造成的。trimap experiment 计算针对距离边缘长度为 x 的像素分类精确度,anti-trimap experiment计 算除去边缘的像素分类精确度。
发现随着边缘区域的增大,两种预训练模型的 IoU 之间的差别不变,对于远离边缘的像素点来说也是一样,因此得出结论分割模型的好坏不是由于边缘像素分类精确度造成的。
上方是分类预训练的分割结果,下方是检测预训练的分割结果,可见检测预训练模型能够覆盖整个物体,即分类模型无法理解物体边界。Detection pre-training provides a better prior about the spatial extent of an instance which helps in recognizing parts of an object.

3.3 图像分类
在不同分类数据集上测试不同预训练模型的表现,发现物体检测预训练(前三个数据集)对于图像分类(IMAGENET-CLS)效果表现更差:

为了研究为什么会产生这样的现象,这里将图片分类的预训练模型中的特征提取出来进行分析。
Conv5 features 在 OPENIMAGES 和 IMAGENET-CLS 上预训练的模型的 Conv5 进行平均池化,softmax 后加上一个线性分类器,进行图像分类。发现进行检测预训练的模型效果比分类模型差非常多:
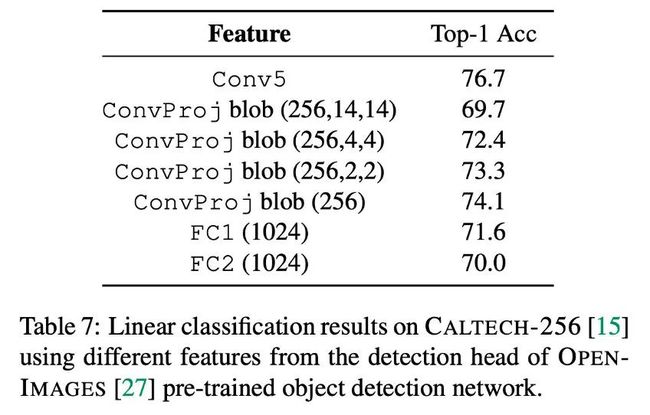
中间层特征 还选择了在 OPENIMAGES 上预训练的检测模型的 detection head 中中间层特征的分类表现,发现 ConvProj blob(256) 上的效果是最好的,FC1 好于 FC2。
语义和特征分析 Conv5 在 ImageNet 上距离最近的图片对(图中可能有多个物体)|Conv5 在 ImageNet 上距离近,但是在 OpenImage 上远的图片对|Conv5 在 OpenImages 上最近的图片对(形状和大小都差不多)。衡量距离用 L2 distance。

用 k-means 聚类,检查在 OpenImages 的 embedding 里是同一个 cluster 的图片对,在 ImageNet Cls 的 embedding 里是否是一个 cluster 中的,反之亦然,得到的结果如下,在 OpenImages 特征空间中相似的图片,在 ImageNet Cls 中更可能相似,而反之不是这样。
在 ImgaNet Cls 特征空间中,不同大小和纹理的同种物体相对于在 OpenImages 特征空间中可能会更加接近。

同 tSNE 可视化平均池化的 Conv5 特征,发现在 ImageNet Cls 特征空间中,同一种物体的特征在相同的 cluster 中且距离更近。然而 OpenImages 特征比较分散。

3.4 可视化
Activations 可视化:这里将 CNN activation(Conv5)可视化出来,发现 IMAGENET-CLS 预训练的 activations 更加集中于明显的区域,OpenImages 预训练的模型的 activations 更注重整个物体的覆盖。
Mask-out可视化:用一个 60x60 的空白遮罩在图像中移动,得到遮罩在不同位置的输出正确类别的置信度。下图可见在 ImageNet-CLS 中的许多位置(如狗和骆驼的头部)分类得分接近于零,而在 OpenImage 中不是。
因为检测依靠物体全局的空间特征去检测,因此对局部的变化不敏感。而分类问题依靠明显部位进行识别,当关键区域被遮住,就容易无法识别。

更多阅读




#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
???? 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
???? 投稿邮箱:
• 投稿邮箱:[email protected]
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
????
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
