C++多线程之旅-内存模式和内存屏障
目录
- 前言
- synchronizes-with和happens-before
- 内存顺序
- 顺序一致模式
- 宽松模式
- 获得/释放模式
- 消费/释放模式
- 内存屏障
- 总结
前言
前面的线程都是随机进行的,但是在内存中应该是有一个先后顺序的。至于先后顺序如何规定那就要取决于内存模型。下面看一个例子:
vector<int> data;
atomic<bool> data_ready(false);
void reader(){
while (!data_ready.load())
this_thread::sleep_for(chrono::milliseconds(2));
std::cout << "the answer = " << data[0];
}
void write() {
int x;
cin >> x;
data.push_back(x);
cout << "write ready" << endl;
data_ready.store(true);
}
int main(){
thread t1(reader);
thread t2(write);
t1.join();
t2.join();
}
执行结果如下:

两个线程中的代码之间一定存在先后顺序关系,即只有当write()函数完成之后,才能执行cout语句。即write函数必须发生于cout之前。而且是使用原子变量来实现这一同步关系。
synchronizes-with和happens-before
synchronizes-with:
The synchronizes-with relationship is something that you can get only between operations on atomic types. Operations on a data structure (such as locking a mutex) might provide this relationship if the data structure contains atomic types and the operations on that data structure perform the appropriate atomic operations internally, but fundamentally it comes only from operations on atomic types.
if thread A stores a value and thread B reads that value, there’s a synchronizes-with relationship between the store in thread A and the load in thread B.
happens-before:
it specifies which operations see the effects of which other operations.
if operation A on one thread inter-thread happens-before operation B on another thread, then A happens-before B.
单线程之间的执行顺序当然是很直观的,上一条语句先于下一条语句执行。但是我们所谈到的happens before关系指的是线程间的执行关系。
也就是线程A与线程B之间存在一个先后执行的顺序。happens-before其实是综合了inter-thread happens before和synchronize-with两个关系。
内存顺序
常见的6种内存顺序选项:memory_order_relaxed、memory_order_consume、memory_order_acquire、memory_order_release、memory_order_acq_rel、memory_order_seq_cst。
| 模型 | 内存选项 |
|---|---|
| 顺序一致模式(sequentially consistent) | memory_order_seq_cst |
| 宽松模式(relaxed) | memory_order_relaxed |
| 获得/释放模式(acquire/release) | memory_order_consume、memory_order_acquire、memory_order_release、memory_order_acq_rel |
现代处理器执行指令时并不是逐条执行的,而是通过重排,同样的现代编译器也会这样。编译器或者 CPU 会因为性能因素而重排代码指令,这种重排操作对于单线程程序而言是无感知的,但对于多线程程序情况就完全不一样了。此时我们就需要对处理器和编译器重排的顺序此时只有这一种情况:

CPU只读一次的x和y值。不需反复读取寄存器来交替x和y值。
处理器重排

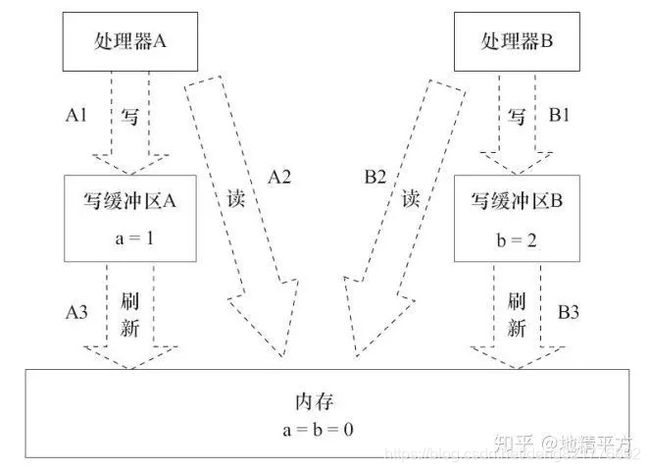
写缓存区没有及时刷新,使得处理器执行的读写操作与内存上顺序不一致。
顺序一致模式
这也是原子操作的默认模式,同时也是限制最严格的一种模式.我们可以通过 std::memory_order_seq_cst来显示的指定这种模式.这种模式下,线程间指令重排的限制与在顺序性代码中进行指令重排的限制是一致的。完全不允许编译器和CPU对代码进行重排操作,这种情况下结果可能和单线程完全一致。
-Thread A- -Thread B-
y = 3 if (x.load() == 1)
x.store (1); assert (y == 3)
此时这两个线程执行情况完全确定,就是线程A对于y的写入必然早于对x的写入。所以如果线程B得到x的值为1时,那么y一定完成了写入3的过程,那么assert断言一定会实现。
但是如果不是顺序一致模型,那么线程A的两行语句进行重排,先执行对x的写入,然后此时线程B进行到判断x的语句,则会进入,此时y还未进行写入操作,这时这个assert断言就不会实现。
虽然顺序一致模型在很多方面性能都十分优秀,但是在这就失去了一部分多线程优化的效果了。即原本可以更好的使用多个线程资源的功能,由于这个模型给阉割掉了一部分。而且很多处理器在处理线程同步的时候会增加花费,降低性能。
由于保证顺序一致的特性, 顺序一致模式成为了原子操作中默认使用的内存模式, 当程序员使用这种模式时,一般不太可能获得意外的程序结果.
宽松模式
以宽松模式执行的原子类型不参与synchronizes-with关系,但是在单线程中同一个变量的操作依然满足happens-before关系。**唯一要求就是同一个线程对单个原子变量的访问不能被重排。**在宽松模式下,编译器和硬件可以随意更改线程中的除原子变量外语句的顺序。
atomic<bool> x(false);
atomic<bool> y(false);此时只有这一种情况:
{
x.store(true, memory_order_relaxed);
y.store(true, memory_order_relaxed);
}
void fun_2() {
if (y.load(memory_order_relaxed))
cout << "y" << endl;
if (x.load(memory_order_relaxed))获得/释放模式
cout << "x" << endl;
}
但是这种情况在Intel很难会出现,可能出现显示了y但是没有显示x。出现重排之后y先存储,然后此时x还未进行存储,线程2则会只输出y而没有x。
但是这种情况我测试很多次都没有出现过,应该是处理器的性质决定了。
获得/释放模式
第一种模式顺序模式,主要的问题就是过分强调顺序,而浪费了一部分CPU多线程资源;第二种模式宽松模式,则通过重排尽可能的利用CPU资源,但是会出现一些意想不到的情况。
获取操作: memory_order_acquire,释放操作: memory_order_release。
release和acquire是成对出现的,仅建立在释放和获取同一原子对象线程之间,线程A中所有发生在release之前的写操作,对线程B的acquire之后都可见。
即
-thread A- -thread B-
程序段1 程序段3
release操作 acquire操作
程序段2 程序段4
线程A中程序段1的所有操作在程序段4中都可见,说明程序段1必须在程序段4之前结束。这就是局部的获取释放模式,相较于顺序一致模型来说,这种模式允许除程序段1重排后必须在程序段4之前之外,没有其他的限制了。
案例如下:
-Thread 1-
y.store (20, memory_order_release);
-Thread 2-
x.store (10, memory_order_release);
-Thread 3-
assert (y.load (memory_order_acquire) == 20 && x.load (memory_order_acquire) == 0)
-Thread 4-
assert (y.load (memory_order_acquire) == 0 && x.load (memory_order_acquire) == 10)
消费/释放模式
-Thread 1-
n = 1
m = 1此时只有这一种情况:

-Thread 2-
t = p.load (memory_order_acquire);
assert( *t == 1 && m == 1 );
-Thread 3-
t = p.load (memory_order_consume);
assert( *t == 1 && m == 1 );
线程 2 中的断言不会失败,因为线程 1 中 对 m 的写入 先发生于 对 p 的写入。
但是线程 3 中的断言就可能失败了,因为 p 和 m 没有依赖关系,而线程 3 中读取 p 使用了消费模式,这导致线程 1 中 对 m 的写入 并不能与线程 3 中的 断言 形成先发生于的关系,该 断言 自然也就可能失败了.PowerPC 架构和 ARM 架构中,指针加载的默认内存模式就是消费模式(一些 MIPS 架构可能也是如此)。
另外的,线程 1 和 线程 2 都能够正确的读取到 n 的数值,因为 n 和 p 存在依赖关系p 中写入了 n 的地址,于是 p 和 n 形成依赖关系)。
内存模式的真正区别其实就是为了同步,硬件需要刷新的状态数量.消费/释放模式相较获取/释放模式而言,执行速度上会更快一些,可以用于一些对性能极度敏感的程序之中。
内存屏障
屏障前后的代码执行顺序必须相对不变,即在屏障之前的代码永远在屏障之前,在屏障之后的代码必须在屏障之后。
前面的几种模式仅仅对原子变量有效,但是对于非原子变量就失去的效果,但是这个内存屏障对非原子变量依旧有效。
关键字为std::atomic_thread_fence(内存模型)
atomic<bool> y;
void fun_3(){
x = true;
atomic_thread_fence(memory_order_release); // 内存屏障1
y.store(true, memory_order_relaxed);
}
void fun_4() {
while (y.load(memory_order_relaxed))
cout << "error" << endl;
atomic_thread_fence(memory_order_acquire);
cout << y << endl;
}
int main(){
thread t1(fun_3);
thread t2(fun_4);
t1.join();
t2.join();
}
总结
如果没特殊的需求,需要极高的并发效率,这个内存模型无需过度关注。但是如果要深入理解多线程的执行情况,那么内存模型的将必不可少。