.NET Core 3.0里新的JSON API:System.Text.Json
目录
- 一 什么是序列化
- 二 为什么需要新的JSON API
- 1 System.Text.Json
- 2 特点
- 3 例子
- 三 Utf8JsonReader
- 四 JsonDocument类
- 五 Utf8JsonWriter类
- 1 写JSON对象
- 2 写属性和值
- 六 JsonSerializer
- 1 反串行化
- 2 格式化
- 3 串行化
- 七 总结
- 八 其他问题
- 1 解决中文会被 Unicode 编码的问题
- 2 可空的 Guid 类型
- 九 Newtonsoft.Json
- 1 Newtonsoft.Json介绍
- 十 文章
一 什么是序列化
序列化是将对象状态转换为可保持或可传输的格式的过程。与序列化相对的是反序列化,它将流转换为对象。这两个过程结合起来,可以轻松地存储和传输数据。
将对象的状态信息转换为可以存储或传输的窗体的过程。 在序列化期间,对象将其当前状态写入到临时或持久性存储区。以后,可以通过从存储区中读取或反序列化对象的状态,重新创建该对象。
通常,对象实例的所有字段都会被序列化,这意味着数据会被表示为实例的序列化数据。这样,能 够解释该格式的代码有可能能够确定这些数据的值,而不依赖于该成员的可访问性。类似地,反序列化从序列化的表示形式中提取数据,并直接设置对象状态,这也 与可访问性规则无关。 对于任何可能包含重要的安全性数据的对象,如果可能,应该使该对象不可序列化。如果它必须为可序列化的,请尝试生成特定字段来保存不可序列化的重要数据。 如果无法实现这一点,则应注意该数据会被公开给任何拥有序列化权限的代码,并确保不让任何恶意代码获得该权限。
二 为什么需要新的JSON API
JSON.NET 大家都用过,老版本的ASP.NET Core也依赖于JSON.NET。
然而这个依赖就会引起一些版本问题:例如ASP.NET Core某个版本需要使用JSON.NET v10,而另一个库需要使用JSON.NET v11;或者JSON.NET 出现了一个新版本,而ASP.NET Core还不能支持这个版本,而您却想使用该版本。
1 System.Text.Json
随着NET Core 3.0的出现,出现了System.Text.Json命名空间和它下面一些用于处理JSON的类。
2 特点
这个内置JSON API具有与生俱来的高性能、地分配的特点:
JSON.NET 使用.NET 里面的字符串作为基本数据类型,其实也就是UTF16,而.NET Core中新的JSON API直接使用数据原始的UTF8格式。
新的JSON API基于Span
但是新的JSON API的特性还不那么丰富,有一些JSON.NET具有的特性都还不支持。
3 例子
{
"postTitle": "Programming",
"language": "c",
"author": {
"firstName": "你好",
"lastName": "Carter"
},
"publishedAt": "2019-10-22T20:50:21.000Z",
"wordCount": 12435,
"isOrigial": true,
"tags": [ "C#", "JSON API", ".net core" ]
}
在项目中将文件存为utf-8编码,并将属性设置为总是复制。
三 Utf8JsonReader
先使用 Utf8JsonReader 来读取JSON文件。Utf8JsonReader 并不会读取文件或者stream,它会读取Span数据类型。
static void Main(string[] args)
{
var dataBytes = File.ReadAllBytes(path: "./Config/config.json");
var jsonSpan = dataBytes.AsSpan();
var jsonReader = new Utf8JsonReader(jsonSpan);
while (jsonReader.Read())
{
Console.WriteLine(GetTokenInfo(jsonReader));
}
}
private static string GetTokenInfo(Utf8JsonReader jsonReader) =>
jsonReader.TokenType switch
{
JsonTokenType.StartObject => "START OBJECT",
JsonTokenType.EndObject => "END OBJECT",
JsonTokenType.StartArray => "START ARRAY",
JsonTokenType.EndArray => "END ARRAY",
JsonTokenType.PropertyName => $"PROPERTY:{jsonReader.GetString()}",
JsonTokenType.Comment => $"COMMENT:{jsonReader.GetString()}",
JsonTokenType.String => $"NUMBER:{jsonReader.GetString()}",
JsonTokenType.Number => $"NUMBER:{jsonReader.GetInt32()}",
JsonTokenType.True => $"BOOL:{jsonReader.GetBoolean()}",
JsonTokenType.False => $"BOOL:{jsonReader.GetBoolean()}",
JsonTokenType.Null => "NULL",
_ => $"**UNHANDLED TOKEN: {jsonReader.TokenType}"
};
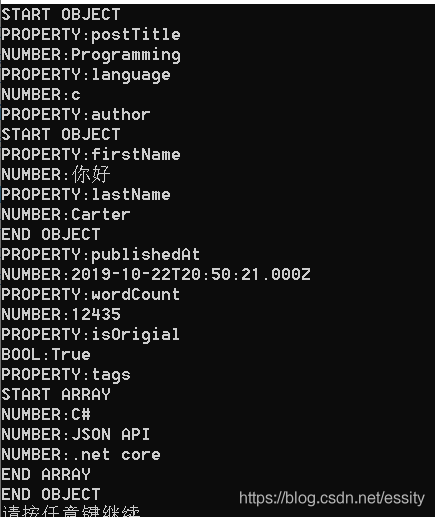
Main方法里面,我们使用File.ReadAllBytes从sample.json文件读取数格式为byte[],然后通过AsSpan这个扩展方法将其转化为Span数据类型,然后把它传递到 Utf8JsonReader 的构造函数来创建一个JSON的reader。
接下来使用while循环对JSON数据的每个Token进行读取,每次执行Read()方法时,reader就会移动到JSON数据里面的下一个Token那里。
Token分成几种类型,GetTokenInfo方法就是判断一下Token的类型,并返回一些描述性信息,这里面应该是包含了所有的类型。这里面使用到了C# 8 的 switch 表达式。
四 JsonDocument类
JsonDocument是基于Utf8JsonReader 构建的。JsonDocument 可分析 JSON 数据并生成只读文档对象模型 (DOM),可对模型进行查询,以支持随机访问和枚举。使用 JsonDocument 分析常规 JSON 有效负载并访问其所有成员比使用 Json.NET 快 2-3 倍,且为合理大小(即 < 1 MB)的数据所分配的量非常少。
JsonDocument可以处理Span,也可以处理Stream。
例子:
using var stream = File.OpenRead(path: "./Config/config.json");
using var doc = JsonDocument.Parse(stream);
这里我通过File.OpenRead把json文件转化为stream。然后使用JsonDocument.Parse方法把stream解析成JSON文档对象模型。
注意,这里我使用了C# 8的using var语法,这个以后再说。
下面我们开始从这个JSON文档对象模型的根节点开始遍历,也就是RootElement:
var root = doc.RootElement;
然后通过root这个JsonElement类型的对象的GetProperty方法来获得相应的属性,而且这个方法可以连串使用:
var firstName = root
.GetProperty("author")
.GetProperty("firstName")
.GetString();
最后一行使用GetString方法来获得该属性的字符串值。
然后我们可以写一个递归调用的方法来遍历整个模型的每个属性:
private static void EnumerateElement(JsonElement root)
{
foreach(var prop in root.EnumerateObject())
{
if(prop.Value.ValueKind == JsonValueKind.Object)
{
Console.WriteLine($"{prop.Name}");
Console.WriteLine("-----Object Start-----");
EnumerateElement(prop.Value);
Console.WriteLine("-----Object End-----");
}
else
{
Console.WriteLine($"{prop.Name}:{prop.Value.GetRawText()}");
}
}
}
这个方法接受JsonElement类型的对象,然后对该元素的属性进行循环。
如果当前属性是另一个对象,那么就继续递归调用这个方法;
否则就输出原始的文本。
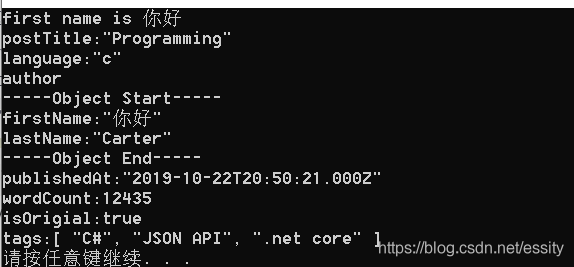
最后调用该方法:
using var stream = File.OpenRead(path: "./Config/config.json");
using var doc = JsonDocument.Parse(stream);
var root = doc.RootElement;
var firstName = root
.GetProperty("author")
.GetProperty("firstName")
.GetString();
Console.WriteLine($"first name is {firstName}");
五 Utf8JsonWriter类
下面研究一下如何写入json文件。这里需要使用Utf8JsonWriter类。这个类需要传递的参数类型是Stream或者Buffer,也就是向Stream或Buffer里面写入数据。
var buffer = new ArrayBufferWriter<byte>();
using var json = new Utf8JsonWriter(buffer);
1 写JSON对象
现在我想写一个json对象,那么就从WriteStartObject()开始,然后以WriteEndObject()结束:
json.WriteStartObject();
json.WriteEndObject();
这样的话,实际上我已经拥有了一个合法的json文档。
2 写属性和值
可以分开写属性和值:
json.WritePropertyName("title");
json.WriteStringValue("programming");
也可以同时把属性和值写出来:
json.WriteString(propertyName: "firstName", value: "Nice");
然后在Main方法里面调用一下:
private static void PopulateJson(Utf8JsonWriter json)
{
json.WriteStartObject();
json.WritePropertyName("title");
json.WriteStringValue("programming");
json.WriteString(propertyName: "language", value: "拔萝卜");
json.WriteString(propertyName: "firstName", value: "Nice");
json.WriteString(propertyName: "endName", value: "Carter");
json.WriteEndObject();
}
static void Main(string[] args)
{
var buffer = new ArrayBufferWriter<byte>();
using var json = new Utf8JsonWriter(buffer, options: new System.Text.Json.JsonWriterOptions
{
//对输出进行缩进
Indented = true,
//打印中文
Encoder = System.Text.Encodings.Web.JavaScriptEncoder.UnsafeRelaxedJsonEscaping
});
PopulateJson(json);
json.Flush();
var output = buffer.WrittenSpan.ToArray();
var outJson = Encoding.UTF8.GetString(output);
Console.WriteLine(outJson);
}
六 JsonSerializer
前面几节的内容可能稍微有点底层,我们大部分时候可能只需要对C#的类进行串行化或者将JSON数据反串行化成C#类,在.NET Core 3.0里面,我们可以使用JsonSerializer这个类来做这些事情。
对于之前的json数据,建立两个类,对应这个文件:
public class BlogPost
{
public string PostTitle { get; set; };
public string Language { get; set; };
public Author Author { get; set; };
public DateTime PublishedAt { get; set; };
public int WordCount { get; set; };
public bool IsOriginal { get; set; };
public string[] Tags { get; set; };
}
public class Author
{
public string FirstName { get; set; };
public string LastName { get; set; };
}
1 反串行化
可以使用JsonSerializer类的Deserialize()方法对json数据反串行化。这个方法支持三种类型的输入参数,分别是:1、JSON数据的字符串;2、Utf8JsonReader;3、ReadOnlySpan
为了简单一点,我直接把json文件读取成字符串,然后传给Deserialize方法:
var text = File.ReadAllText(path: "./Config/config.json");
var post = JsonSerializer.Deserialize<BlogPost>(text);
Console.WriteLine(post.PostTitle);
Console.WriteLine($"{post.Author.FirstName} - {post.Author.LastName}");
Console.WriteLine(post.PublishedAt);
然后我试图打印出反串行化之后的一些属性数据。但是这不会成功。因为JSON文件里面数据的大小写命名规范使用的是camel casing(简单理解为首字母是小写的),而默认情况下Deserializer会寻找Pascal casing这种规范(简单理解为每个单词的首字母都是大写的)的属性名。
2 格式化
为解决这个问题,就需要使用JsonSerializerOptions类:
var option = new JsonSerializerOptions
{
PropertyNamingPolicy = JsonNamingPolicy.CamelCase
};
var post = JsonSerializer.Deserialize<BlogPost>(text, option);
3 串行化
JsonSerializer也支持串行化,也就是把C#数据转化为JSON数据:
var json = JsonSerializer.Serialize(post, option);
Console.WriteLine(json);

七 总结
总结一下.NET Core 3.0新的JSON API:
Utf8JsonReader - 读操作,快速,低级
Utf8JsonWriter - 写操作,快速,低级
JsonDocument - 基于DOM,快速
JsonSeriliazer - 串行化/反串行化,快速、
八 其他问题
1 解决中文会被 Unicode 编码的问题
这个问题是在博客园里找到的一种答案: .NET Core 3.0 中使用 System.Text.Json 序列化中文时的编码问题:
[TestMethod]
[Description(description: "测试中文序列化")]
public void TestChinese()
{
object jsonObject = new { chinese = "灰长标准的布咚发" };
string aJsonString = Newtonsoft.Json.JsonConvert.SerializeObject(value: jsonObject);
string bJsonString = System.Text.Json.JsonSerializer.Serialize(
value: jsonObject,
options: new System.Text.Json.JsonSerializerOptions
{
Encoder = System.Text.Encodings.Web.JavaScriptEncoder.Create(allowedRanges: UnicodeRanges.All)
});
Assert.AreEqual(expected: aJsonString, actual: bJsonString, message: "测试中文序列化失败");
}
关键在于序列化配置加了一句
new System.Text.Json.JsonSerializerOptions
{
Encoder = System.Text.Encodings.Web.JavaScriptEncoder.Create(allowedRanges: UnicodeRanges.All)
}
但是一些符号被转义的问题还是不管用, 寻思了一上午暂时没找到答案…
回娘家找源码, 寻寻匿匿最后发现这么一句
// If the user hasn't explicitly configured the encoder, use the less strict encoder that does not encode all non-ASCII characters.
jsonSerializerOptions = jsonSerializerOptions.Copy(JavaScriptEncoder.UnsafeRelaxedJsonEscaping);
less strict ? 那对照的意思是 Newtonsoft.Json 一直使用的就是非严格模式咯, 而我们习惯使用的也是这种模式.
那么改下, 还报错的单元测试都加上配置 JavaScriptEncoder.UnsafeRelaxedJsonEscaping, 果然测试结果顺眼多了. 连上面的 UnicodeRanges.All 都不需要配置了.
string bJsonString = System.Text.Json.JsonSerializer.Serialize(
value: jsonObject,
options: new System.Text.Json.JsonSerializerOptions
{
Encoder = System.Text.Encodings.Web.JavaScriptEncoder.UnsafeRelaxedJsonEscaping
});
2 可空的 Guid 类型
对于可空的 Guid 类型(Guid?),如果 json 中对应的值为空字符串(""),则反序列化时会报错:
九 Newtonsoft.Json
本节内容来自这里。
1 Newtonsoft.Json介绍
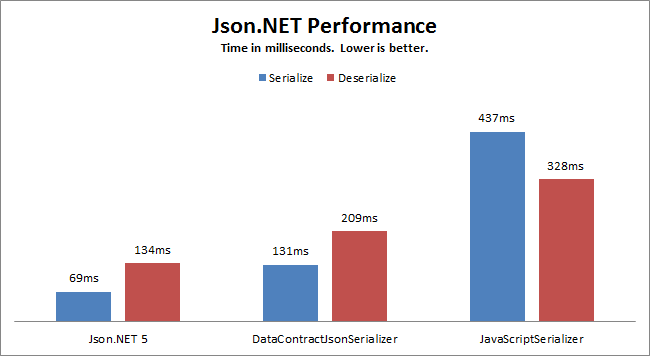
做 Web 开发的,没有接触过 JavaScript 的肯定很少,做前端开发,没有接触过Ajax的估计更不多了。现在的系统大多数是分布式系统,分布式系统就会涉及到数据的传输,JSON在数据传输和提交方面有着天生的优势。当我们使用Json的时候,很多时候会涉及到几个序列化对象的使用:DataContractJsonSerializer,JavaScriptSerializer 和 Json.NET即 Newtonsoft.Json。大多数人都会选择性能以及通用性较好 Json.NET,这个不是微软的类库,是一个开源的Json操作类库,速度比 DataContractJsonSerializer 快 50%,比 JavaScriptSerializer 快 250%,从下面的性能对比就可以看到它的其中之一的性能优点。
示例:
string jsonString = File.ReadAllText("./Config/config.json", Encoding.Default);//读取文件
JObject jobject = JObject.Parse(jsonString);//解析成json
StreamReader file = File.OpenText("./Config/config.json");
JsonTextReader reader = new JsonTextReader(file);
JObject jsonObject = (JObject)JToken.ReadFrom(reader);
file.Close();
Console.WriteLine(jobject["CAN"].ToString());
jobject["CAN"] = true;//改变关键值
/*
* 序列化
*/
//将json装换为string,json字符串是非格式化输出
//string convertString = JsonConvert.SerializeObject(jsonObject);
//将json装换为string,json字符串是格式化的格式
string convertString = Convert.ToString(jsonObject);//将json装换为string
File.WriteAllText("./Config/config.json", convertString);//将内容写进json文件中
Pascal 命名法,就是每个单词的首字符都是大写的({“BoyFirend”:“xxx”,“HomeAddress”:“xxxx”});Camel 命名法(比如:{“boyFirend”:“xxx”,“homeAddress”:“xxxx”})。
十 文章
.NETCore3.1中的Json互操作最全解读-收藏级:https://www.cnblogs.com/viter/p/12116640.html