摘要: 快来利用深度学习和维基百科构建一个属于你自己的图书推荐系统吧,手把手教学,够简单够酷炫。
深度学习应用甚广,在诸多方面的表现,如图像分割、时序预测和自然语言处理,都优于其他机器学习方法。以前,你只能在学术论文或者大型商业公司中看到它的身影,但如今,我们已能利用自己的电脑进行深度学习计算。本文将利用深度学习和维基百科构建图书推荐系统。
该推荐系统基于假设:链接到类似的维基百科页面的书籍彼此相似。

完整代码详见Jupyter Notebook on GitHub。如果你没有GPU也没关系,可以通过notebook on Kaggle获取免费的GPU。
神经网络嵌入(Neural Network Embeddings)
嵌入(embedding),即用连续向量表示离散变量的方法。与独热编码不同的是,神经网络嵌入维度较低,并能令相似实体在嵌入空间中相邻。
神经网络嵌入的主要用途有三种:
- 在嵌入空间中找到最近邻。
- 作为有监督的机器学习模型的输入。
- 挖掘变量间的关系。
数据集:来自维基百科
与以往的数据科学项目一样,我们需要从数据集入手。点击此处,查看如何下载和处理维基百科上的每一篇文章,以及搜索书籍页面。我们保存了图书标题、基本信息以、wikilinks(wikiLinks 在搜索界面中集成了维基百科与维基词典两项服务,可以根据自己的不同需求在页面上方自由切换,而搜索历史与收藏的词条则位于屏幕右上角,点击即可跳转)。

数据下载完成后,我们需要对其进行探索和清洗,此时你可能会发现一些原始数据之间的关系。如下图,展示了与维基百科图书中的页面关联性最强的链接:

从上图可看出,排名前四的都是常用页面,对构建推荐系统没有任何帮助。就像书籍的装订版本,是平装(paperback)还是精装(hardcover)对我们了解图书的内容没有任何作用,并且神经网络无法根据这个特征判别书籍是否相似。因此,可以选择过滤掉这些无用的特征。
仔细思考哪些数据对构建推荐系统是有帮助的,哪些是无用的,有用的保留,无用的过滤,这样的数据清洗工作才算到位。
接下来,找出与其他书籍联系最紧密的书籍。以下是前10本“联系最紧密”的书籍:

完成数据清洗后,我们的数据集中剩余41758条wikilinks以及37020本图书。接下来,我们需要引入有监督的机器学习方法。
监督学习
监督学习就是最常见的分类问题,即通过已有的训练样本去训练得到一个最优模型,再利用这个模型将所有的输入映射为相应的输出,对输出进行简单的判断从而实现分类的目的。基于我们预先给定的假设:类似的书籍会链接到类似的维基百科页面,我们可将监督学习的任务定义为:给定(book title,wikilink)对,确定wikilink是否出现在书籍的某一章中。
我们将提供数十万个由书籍名称,wikilink以及标签组成的训练示例,同时给神经网络提供一些正确的训练示例,即数据集中包含的,以及一些错误的示例,以促使神经网络学会区分wikilink是否出现在书籍的某一章中。
嵌入是为特定的任务而学习的,并且只与该问题有关。如果我们的任务是想要确定哪些书籍由Jane Austen撰写,嵌入会根据该任务将Austen所写的书映射在嵌入空间中更相邻的地方。或者我们希望通过训练来判断书籍的页面中是否有指定的wikilink页面,此时神经网络会根据内容使相似书籍在嵌入空间中相邻。
一旦我们定义了学习任务,接下来便可开始编写代码进行实现。由于神经网络只能接受整数输入,我们会将书籍分别映射为整数:

对链接我们也进行同样的映射,并创建一个训练集。对所有书籍进行遍历,并记录页面上记录出现的wikilink,列出所有的(book,wikilink)对:

最终有772798个示例用于模型训练。接下来,随机选择链接索引和book索引,如果它们不在(book,wikilink)对中,那么它们就是能用于增强模型的学习能力false examples。
训练集及测试集
虽然在有监督的机器学习任务中需要划分验证集(validation set)以及测试集,但本文的目的不在于得到精确的模型,只是想训练神经网络模型完成预测任务。训练结束后,我们也不需要在新的数据集中测试我们的模型,所以并不需要评估模型的性能或者使用验证集以防止过拟合。为了更好的学习嵌入,我们将所有的示例都用于训练。
嵌入模型
神经网络嵌入虽然听上去十分复杂,但使用Keras深度学习框架实现它们却相对容易。
嵌入模型分为5层:
- Input:并行输入书籍和链接
- Embedding:设置代表book和link两个类别的向量长度为50
- Dot:进行点积运算
- Reshape:把点积reshape成一个一维向量
- Dense:一个带sigmod激活函数的输出神经元
在嵌入神经网络中,能够通过训练权重最小化损失函数。神经网络将一本书和一个链接作为输入,输出一个0到1之间的预测值,并与真实值进行比较,模型采用Adam优化器。
模型代码如下:
from keras.layers import Input, Embedding, Dot, Reshape, Dense
from keras.models import Model
def book_embedding_model(embedding_size = 50, classification = False):
"""Model to embed books and wikilinks using the Keras functional API.
Trained to discern if a link is present in on a book's page"""
# Both inputs are 1-dimensional
book = Input(name = 'book', shape = [1])
link = Input(name = 'link', shape = [1])
# Embedding the book (shape will be (None, 1, 50))
book_embedding = Embedding(name = 'book_embedding',
input_dim = len(book_index),
output_dim = embedding_size)(book)
# Embedding the link (shape will be (None, 1, 50))
link_embedding = Embedding(name = 'link_embedding',
input_dim = len(link_index),
output_dim = embedding_size)(link)
# Merge the layers with a dot product along the second axis
# (shape will be (None, 1, 1))
merged = Dot(name = 'dot_product', normalize = True,
axes = 2)([book_embedding, link_embedding])
# Reshape to be a single number (shape will be (None, 1))
merged = Reshape(target_shape = [1])(merged)
# Squash outputs for classification
out = Dense(1, activation = 'sigmoid')(merged)
model = Model(inputs = [book, link], outputs = out)
# Compile using specified optimizer and loss
model.compile(optimizer = 'Adam', loss = 'binary_crossentropy',
metrics = ['accuracy'])
return model这个框架可以扩展至各类嵌入模型。并且,我们并不关心模型是否精准,只想获取嵌入。在嵌入模型中,权重才是目标,预测只是学习嵌入的手段。
本模型约含400万个权重,如下所示:
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
book (InputLayer) (None, 1) 0
__________________________________________________________________________________________________
link (InputLayer) (None, 1) 0
__________________________________________________________________________________________________
book_embedding (Embedding) (None, 1, 50) 1851000 book[0][0]
__________________________________________________________________________________________________
link_embedding (Embedding) (None, 1, 50) 2087900 link[0][0]
__________________________________________________________________________________________________
dot_product (Dot) (None, 1, 1) 0 book_embedding[0][0]
link_embedding[0][0]
__________________________________________________________________________________________________
reshape_1 (Reshape) (None, 1) 0 dot_product[0][0]
==================================================================================================
Total params: 3,938,900
Trainable params: 3,938,900
Non-trainable params: 0利用上述方法,我们不仅可以得到书籍的嵌入,还可以得到链接的嵌入,这意味着我们可以比较所有通过书籍链接的维基百科页面。
生成训练示例
神经网络是batch learners,因为它们是基于一小批样本进行训练的,对所有的数据批次都进行了一次迭代称为epochs。常用的神经网络训练方法是使用生成器,它能产生批量样本函数,优点是不需要将所有的训练集都加载到内存中。
下面的代码完整地显示了生成器:
import numpy as np
import random
random.seed(100)
def generate_batch(pairs, n_positive = 50, negative_ratio = 1.0):
"""Generate batches of samples for training.
Random select positive samples
from pairs and randomly select negatives."""
# Create empty array to hold batch
batch_size = n_positive * (1 + negative_ratio)
batch = np.zeros((batch_size, 3))
# Continue to yield samples
while True:
# Randomly choose positive examples
for idx, (book_id, link_id) in enumerate(random.sample(pairs, n_positive)):
batch[idx, :] = (book_id, link_id, 1)
idx += 1
# Add negative examples until reach batch size
while idx < batch_size:
# Random selection
random_book = random.randrange(len(books))
random_link = random.randrange(len(links))
# Check to make sure this is not a positive example
if (random_book, random_link) not in pairs_set:
# Add to batch and increment index
batch[idx, :] = (random_book, random_link, neg_label)
idx += 1
# Make sure to shuffle order
np.random.shuffle(batch)
yield {'book': batch[:, 0], 'link': batch[:, 1]}, batch[:, 2]其中n_positive表示每个batch中正例样本的数量,negative_ration表示每个batch中负例样本与正例样本的比率。
在有监督的学习任务、生成器、嵌入模型都准备完毕的情况下,我们正式进入图书推荐系统的构建。
训练模型
有一些训练参数是可以调节的,如每个批次中正例样本的数量。通常,我会从一小批量开始尝试,直到性能开始下降。同样,我们需要通过尝试调整负例样本与正例样本的比率。

一旦神经网络开始训练,我们就能获取权重:

构建推荐系统
嵌入本身不那么有趣,无非是50维向量。

然而我们可以利用这些向量些有趣的事,例如构建图书推荐系统。为了在嵌入空间中找到与所查询书籍最接近的书,我们取那本书的向量,并计算它与所有其他书的向量的点积。如果我们的嵌入是标准化的,那么向量之间的范围会从-1,最不相似,到+1,最相似。
以查询《战争与和平》为例,相似书籍如下:

上图所示全是经典的俄罗斯小说,说明我们推荐系统是可用的。

除了对书籍进行嵌入,我们也对链接做了嵌入,以此查询与维基百科页面最为相似的链接:

目前,我正在阅读Stephen Jay Gould的经典著作《Bully for Brontosaurus》,将其输入构建的推荐系统便可以知道接下来应该读什么:

嵌入可视化
嵌入的优点是可以将所学到的嵌入进行可视化处理,以显示哪些类别是相似的。首先需要将这些权重的维度降低为2-D或3-D。然后,在散点图上可视化这些点,以查看它们在空间中的分离情况。目前最流行的降维方法是——t-Distributed Stochastic Neighbor Embedding (TSNE)。
我们将37000维的图书通过神经网络嵌入映射为50维,接着使用TSNE将维数将至为2。
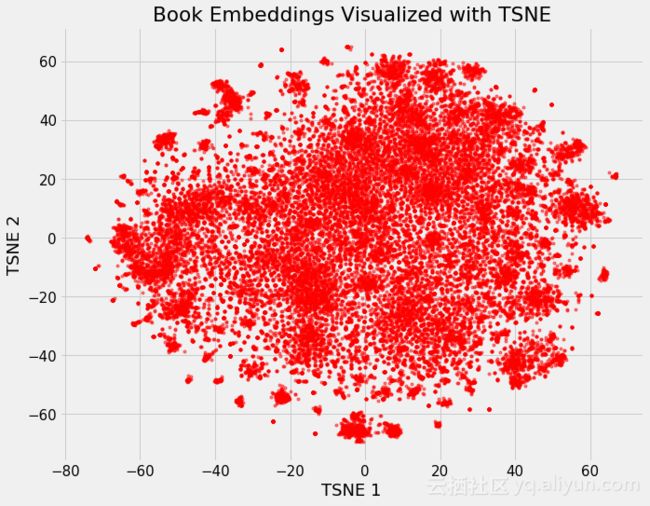
下图展示了降维后图书在向量空间中的分布情况:
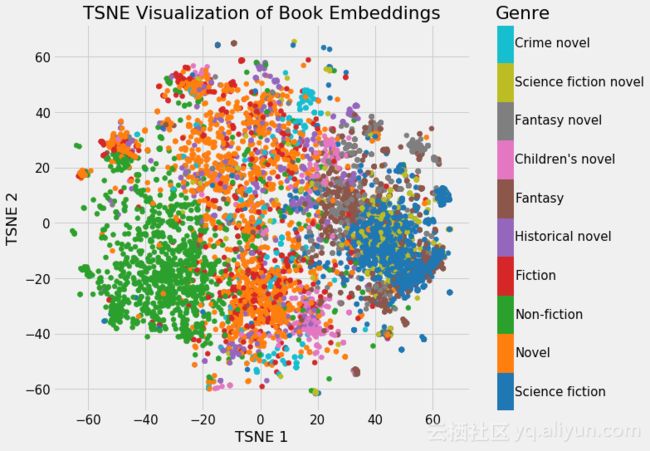
通过颜色对书本类型进行区分,可以快速的找出相似流派的书籍。
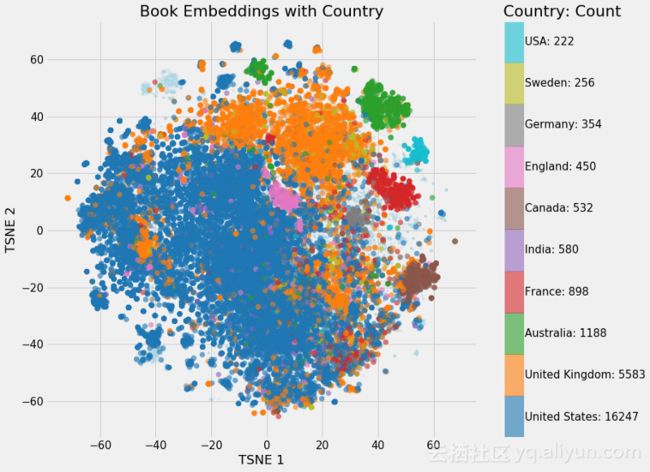
同样的,我们可以对Country进行嵌入:
此外,你还可以根据自己的需求对嵌入进行可视化,以开展后续的分析工作。
交互式可视化
刚才所展示的图片均为静态效果,为了更好的查看变量之间的关系,点击[此处]()以获取动态效果。
总结
神经网络嵌入能够将离散的数据表示为连续的低维向量,克服了传统编码方法的局限性,能查找最近邻,作为另一个模型的输入以及进行可视化,是处理离散变量的有效工具,也是深度学习的有效应用。在本文中,我们基于链接到相似页面间彼此相似的假设,利用神经网络嵌入构建了图书推荐系统。
构建神经网络嵌入的步骤总结如下:
- 收集数据
- 制定一个有监督的学习任务
- 训练嵌入神经网络模型
- 进行推荐实战及可视化
完整的项目可点击此处获取。
本文作者:【方向】
本文为云栖社区原创内容,未经允许不得转载。