Hbase入门之三HBase Client API使用入门1
今天公司进行了一样关于Hbase的培训,让我对Hbase有了基础的了解。和大家分享一样。自己的理解不是很深,如果有说的不对地方,希望大家斧正。
什么是Hbase?
HBase是一个分布式的、面向列的开源数据库。
分布式:Hbase的分布式是依托于Hadoop的,那Hadoop又是什么?Hadoop 是一个能够对大量数据进行分布式处理的软件框架。其实我也不懂这是个什么框架,我的理解是利用Hadoop可以将很多台服务器集成一个集群,接受这个框架统一的调配。不再是分散的,而变成一个有机的整体。Hbase架设在整个服务器集群上。当Hbase创建表时,Hbase会建立一个region,假设为A(默认的region大小为64M),当表中数据越来越大,大小超过64M时,就会发生spite即将这台服务器上该region移动到另外一台服务器上,重新建立一个region B继续保存数据,然后超过64M又继续spite。 这样可以将数据分摊到整个服务器的集群中,在查询的时候会首先查找A,如果没有继续查B....这样充分利用了多台服务器资源,防止某一单一的服务器查询工作量过大,实现了负载均衡。 Hbase还可以实现MapReduce。 MapReduce其实就是Map和Reduce两个步骤。Map是将数据分散到各个服务器上去。Reduce就是每个服务器做同样的工作,然后统计出结果。比如:有一张全国所有人名字的表,服务器集群有6台机器,我们想统计出全国姓”张“有多少个。首先Map过程会将这样表分成6份,放到集群中的6台机器中。Reduce就是每台机器都统计自己分到的表中有多少个姓”张“的。然后将每台机器的结果汇总。得出结果。让效率得到极大的提高。
面向列:指的是同一个列簇里所有数据都存放在一个文件中,从而在读写时有效降低磁盘I/O的开销,并且由于类似数据存放在一起,提高了压缩比。Hbase数据存储是一个四维的表,1、Rowkey 2、版本数 3、ColumnFamily 4、Qualify。Rowkey就是这个表的关键字,相当于一个Map的key。然后value是ColumnFamily。 版本数是数据的版本的数,是以时间戳来记录的。默认的Hbase记录数据的3个版本。就是第一次存入的数据是第一个版本,然后更新之后的数据,Hbase不会讲原来的数据删除,而是作为该数据的老版本继续保留。直到更新的3次。才将最原始数据删除。这样导致数据量翻了3倍。如果不需要最好在更改默认设置。ColumnFamily也相当于一个Map里面继续存Qualify。不过ColumnFamily最好不要超过3个。3个以上会导致查询速率出现问题。Qualify同样是一个Map结构。里面支持好像支持100W对键值对。 以一个例子来看一样Hbase的存储结构吧。例如:一张个人信息表,姓名:Mark 年龄:22 性别:男 毕业学校:xxx学校 获奖情况:最佳新人奖。 可以这样建立表结构,Rowkey中存入姓名Mark,2个ColumnFamily一个保存这个人的base基本信息如:年龄,性别,一个保存other其他信息。如:学校、获奖。然后Qualify保存详细信息,如name:mark。 最后得到格式为: mark:{"base":{"name":"Mark","age":22,"sex":"man"},"other":{"school":"xxx学校",{"reward":"最佳新人奖"}}} 可以看到所有的列名都会存在数据库中所以最好将名字取得短。
还有一个索引问题,这种map类型的数据格式。是没有索引的。如果要加索引就是以要加索引的字段为key,原来的Rowkey做值重新建立一张表。也可以存入其他数据。这个就看使用空间换时间还是用时间换空间了。
大概就是这么一个基本介绍。
最佳实践:
1、如果不要用到多版本记录。那么就将最大版本数设为1。否则会多增加很多数据量。
2、尽可能将字段的名字长度减少,因为这些也都会保存到数据库中。
3、当存入数据量很大,很快的时候,可以调节region的大小。防止过多的spite操作。过多的spite的操作可能导致hbase挂掉,从而会导致整个集群宕机。
4、在存入数据前,先把表格式定好。因为存Hbase中的数据一般都是上T的数据,没办法更改表结构。只能重新建立表导入。
前言
1. 创建表:(由master完成)
- 首先需要获取master地址(master启动时会将地址告诉zookeeper)因而客户端首先会访问zookeeper获取master的地址
- client和master通信,然后有master来创建表( 包括表的列簇,是否 cache ,设置存储的最大版本数,是否压缩等 )。
2. 读写删除数据
- client与regionserver通信,读写、删除数据
- 写入和删除数据时讲数据打上不同的标志append,真正的数据删除操作在compact时发生
3. 版本信息

configuration
HbaseConfiguration, 表示HBase的配置信息
两种构造函数如下:
public HBaseConfiguration() -----------默认的构造方式会从hbase-default.xml和hbase-site.xml中读取配置,如果classpath中没有这两个文件,需要自己配置
public HBaseConfiguration(final Configuration c)
eg:
static HBaseConfiguration cfg = null; static { Configuration HBASE_CONFIG = new Configuration(); HBASE_CONFIG.set("hbase.zookeeper.quorum", "192.168.1.95"); HBASE_CONFIG.set("hbase.zookeeper.property.clientPort", "2181"); cfg = new HBaseConfiguration(HBASE_CONFIG); }
创建表
使用HBaseAdmin对象的createTable方法
eg:
public static void createTable(String tableName) { System.out.println("************start create table**********"); try { HBaseAdmin hBaseAdmin = new HBaseAdmin(cfg); if (hBaseAdmin.tableExists(tableName)) {// 如果存在要创建的表,那么先删除,再创建 hBaseAdmin.disableTable(tableName); hBaseAdmin.deleteTable(tableName); System.out.println(tableName + " is exist"); } HTableDescriptor tableDescriptor = new HTableDescriptor(tableName);// 代表表的schema tableDescriptor.addFamily(new HColumnDescriptor("name")); //增加列簇 tableDescriptor.addFamily(new HColumnDescriptor("age")); tableDescriptor.addFamily(new HColumnDescriptor("gender")); hBaseAdmin.createTable(tableDescriptor); } catch (MasterNotRunningException e) { e.printStackTrace(); } catch (ZooKeeperConnectionException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } System.out.println("*****end create table*************"); }
public static void main(String[] agrs) { try { String tablename = "wishTest"; HBaseTest.createTable(tablename); } catch (Exception e) { e.printStackTrace(); } }
日志信息如下:
************start create table**********
14/05/18 14:14:22 INFO zookeeper.ZooKeeper: Client environment:zookeeper.version=3.4.5-1392090, built on 09/30/2012 17:52 GMT
14/05/18 14:14:22 INFO zookeeper.ZooKeeper: Client environment:host.name=LJ-PC
14/05/18 14:14:22 INFO zookeeper.ZooKeeper: Client environment:java.version=1.6.0_11
14/05/18 14:14:22 INFO zookeeper.ZooKeeper: Client environment:java.vendor=Sun Microsystems Inc.
14/05/18 14:14:22 INFO zookeeper.ZooKeeper: Client environment:java.home=D:\java\jdk1.6.0_11\jre
14/05/18 14:14:22 INFO zookeeper.ZooKeeper: Client environment:java.class.path=....
...
14/05/18 14:14:22 INFO zookeeper.RecoverableZooKeeper: The identifier of this process is 6560@LJ-PC
14/05/18 14:14:22 INFO zookeeper.ClientCnxn: Socket connection established to hadoop/192.168.1.95:2181, initiating session
14/05/18 14:14:22 INFO zookeeper.ClientCnxn: Session establishment complete on server hadoop/192.168.1.95:2181, sessionid = 0x460dd23bda0007, negotiated timeout = 180000
14/05/18 14:14:22 INFO zookeeper.ZooKeeper: Session: 0x460dd23bda0007 closed
14/05/18 14:14:22 INFO zookeeper.ClientCnxn: EventThread shut down
*****end create table*************
在centos中查看是否创建成功:
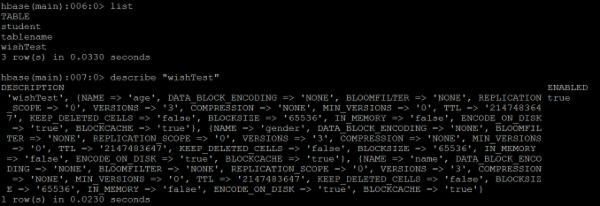
网页上查看:

HTableDescriptor其他方法如下:
- setMaxFileSize ,指定最大的 region size
- setMemStoreFlushSize 指定 memstore flush 到 HDFS 上的文件大小,默认是64M
- public void addFamily(final HColumnDescriptor family)
HColumnDescriptor 其他方法如下:
- setTimeToLive: 指定最大的 TTL, 单位是 ms, 过期数据会被自动删除。
- setInMemory: 指定是否放在内存中,对小表有用,可用于提高效率。默认关闭
- setBloomFilter: 指定是否使用 BloomFilter, 可提高随机查询效率。默认关闭
- setCompressionType: 设定数据压缩类型。默认无压缩。
- setScope(scope): 集群的 Replication ,默认为 flase
- setBlocksize(blocksize); block 的大小默认是 64kb , block 小适合随机读,但是可能导 Index 过大而使内存 oom, block 大利于顺序读。
- setMaxVersions: 指定数据最大保存的版本个数。默认为 3 。版本数最多为Integer.MAX_VALUE, 但是版本数过多可能导致 compact 时 out of memory 。
- setBlockCacheEnabled: 是否可以 cache, 默认设置为 true ,将最近读取的数据所在的 Block 放入内存中,标记为 single ,若下次读命中则将其标记为 multi
插入数据
使用HTable获取table 注意: HTable 不是线程安全的,因此当多线程插入数据的时候推荐使用 HTablePool
使用put插入数据,可以单条插入数据和批量插入数据,put方法如下:
public void put(final Put put) throws IOException
public void put(final List
put 常用方法:
- add: 增加一个 Cell
- setTimeStamp: 指定所有 cell 默认的 timestamp, 如果一个 Cell 没有指定timestamp, 就会用到这个值。如果没有调用, HBase 会将当前时间作为未指定timestamp 的 cell 的 timestamp.
- setWriteToWAL: WAL 是 Write Ahead Log 的缩写,指的是 HBase 在插入操作前是否写 Log 。默认是打开,关掉会提高性能,但是如果系统出现故障 ( 负责插入的Region Server 挂掉 ) ,数据可能会丢失。
下面两个方法会影响插入性能
- setAutoFlash:
AutoFlush 指的是在每次调用 HBase 的 Put 操作,是否提交到 HBase Server 。默认是 true, 每次会提交。如果此时是单条插入,就会有更多的 IO, 从而降低性能。进行大量 Put 时, HTable 的 setAutoFlush 最好设置为 flase 。否则每执行一个 Put 就需要和 RegionServer 发送一个请求。如果 autoFlush = false ,会等到写缓冲填满才会发起请求。显式的发起请求,可以调用 flushCommits 。 HTable 的 close 操作也会发起flushCommits
- setWriteBufferSize:
Write Buffer Size 在 AutoFlush 为 false 的时候起作用,默认是 2MB, 也就是当插入数据超过 2MB, 就会自动提交到 Server
eg:
public static void insert(String tableName) { System.out.println("************start insert ************"); HTablePool pool = new HTablePool(cfg, 1000); Put put = new Put("1".getBytes());// 一个PUT代表一行数据,每行一个唯一的ROWKEY,此处rowkey为1 put.add("name".getBytes(), null, "wish".getBytes());// 本行数据的第一列 put.add("age".getBytes(), null, "20".getBytes());// 本行数据的第三列 put.add("gender".getBytes(), null, "female".getBytes());// 本行数据的第三列 try { pool.getTable(tableName).put(put); } catch (IOException e) { e.printStackTrace(); } System.out.println("************end insert************"); }
public static void main(String[] agrs) { try { String tablename = "wishTest"; HBaseTest.insert(tablename); } catch (Exception e) { e.printStackTrace(); } }
日志信息如下:
************start insert ************
14/05/18 15:01:17 WARN hbase.HBaseConfiguration: instantiating HBaseConfiguration() is deprecated. Please use HBaseConfiguration#create() to construct a plain Configuration
14/05/18 15:01:17 INFO zookeeper.ZooKeeper: Client environment:zookeeper.version=3.4.5-1392090, built on 09/30/2012 17:52 GMT
14/05/18 15:01:17 INFO zookeeper.ZooKeeper: Client environment:host.name=LJ-PC
14/05/18 15:01:17 INFO zookeeper.ZooKeeper: Client environment:java.version=1.6.0_11
14/05/18 15:01:17 INFO zookeeper.ZooKeeper: Client environment:java.vendor=Sun Microsystems Inc.
14/05/18 15:01:17 INFO zookeeper.ZooKeeper: Client environment:java.home=D:\java\jdk1.6.0_11\jre
.....
14/05/18 15:01:17 INFO zookeeper.ZooKeeper: Client environment:java.compiler=
14/05/18 15:01:17 INFO zookeeper.ZooKeeper: Client environment:os.name=Windows Vista
14/05/18 15:01:17 INFO zookeeper.ZooKeeper: Client environment:os.arch=x86
14/05/18 15:01:17 INFO zookeeper.ZooKeeper: Client environment:os.version=6.1
14/05/18 15:01:17 INFO zookeeper.ZooKeeper: Client environment:user.name=root
14/05/18 15:01:17 INFO zookeeper.ZooKeeper: Client environment:user.home=C:\Users\LJ
14/05/18 15:01:17 INFO zookeeper.ZooKeeper: Client environment:user.dir=D:\java\eclipse4.3-jee-kepler-SR1-win32\workspace\hadoop
14/05/18 15:01:17 INFO zookeeper.ZooKeeper: Initiating client connection, connectString=192.168.1.95:2181 sessionTimeout=180000 watcher=hconnection
14/05/18 15:01:17 INFO zookeeper.RecoverableZooKeeper: The identifier of this process is 1252@LJ-PC
14/05/18 15:01:17 INFO zookeeper.ClientCnxn: Opening socket connection to server hadoop/192.168.1.95:2181. Will not attempt to authenticate using SASL (无法定位登录配置)
14/05/18 15:01:17 INFO zookeeper.ClientCnxn: Socket connection established to hadoop/192.168.1.95:2181, initiating session
14/05/18 15:01:17 INFO zookeeper.ClientCnxn: Session establishment complete on server hadoop/192.168.1.95:2181, sessionid = 0x460dd23bda000b, negotiated timeout = 180000
************end insert************
查看插入结果:

查询数据
分为单条查询和批量查询,单条查询通过get查询。 通过HTable的getScanner实现批量查询
public Result get(final Get get) //单条查询
public ResultScanner getScanner(final Scan scan) //批量查询
eg:单条查询:
public static void querySingle(String tableName) { HTablePool pool = new HTablePool(cfg, 1000); try { Get get = new Get("1".getBytes());// 根据rowkey查询 Result r = pool.getTable(tableName).get(get); System.out.println("rowkey:" + new String(r.getRow())); for (KeyValue keyValue : r.raw()) { System.out.println("列:" + new String(keyValue.getFamily()) + " 值:" + new String(keyValue.getValue())); } } catch (IOException e) { e.printStackTrace(); } }
public static void main(String[] agrs) { try { String tablename = "wishTest"; HBaseTest.querySingle(tablename); } catch (Exception e) { e.printStackTrace(); } }
查询结果:
rowkey:1
列:age 值:20
列:gender 值:female
列:name 值:wish
eg:批量查询:
public static void queryAll(String tableName) { HTablePool pool = new HTablePool(cfg, 1000); try { ResultScanner rs = pool.getTable(tableName).getScanner(new Scan()); for (Result r : rs) { System.out.println("rowkey:" + new String(r.getRow())); for (KeyValue keyValue : r.raw()) { System.out.println("列:" + new String(keyValue.getFamily()) + " 值:" + new String(keyValue.getValue())); } } } catch (IOException e) { e.printStackTrace(); } }
public static void main(String[] agrs) { try { String tablename = "wishTest"; HBaseTest.queryAll(tablename); } catch (Exception e) { e.printStackTrace(); } }
结果如下:
rowkey:1
列:age 值:20
列:gender 值:female
列:name 值:wish
rowkey:112233bbbcccc
列:age 值:20
列:gender 值:female
列:name 值:wish
rowkey:2
列:age 值:20
列:gender 值:female
列:name 值:rain
删除数据
使用HTable的delete删除数据:
public void delete(final Delete delete)
eg:
public static void deleteRow(String tablename, String rowkey) { try { HTable table = new HTable(cfg, tablename); List list = new ArrayList(); Delete d1 = new Delete(rowkey.getBytes()); list.add(d1); table.delete(list); System.out.println("删除行成功!"); } catch (IOException e) { e.printStackTrace(); } } public static void main(String[] agrs) { try { String tablename = "wishTest"; System.out.println("****************************删除前数据**********************"); HBaseTest.queryAll(tablename); HBaseTest.deleteRow(tablename,"112233bbbcccc"); System.out.println("****************************删除后数据**********************"); HBaseTest.queryAll(tablename); } catch (Exception e) { e.printStackTrace(); } }
结果如下:
****************************删除前数据**********************
rowkey:1
列:age 值:20
列:gender 值:female
列:name 值:wish
rowkey:112233bbbcccc
列:age 值:20
列:gender 值:female
列:name 值:wish
rowkey:2
列:age 值:20
列:gender 值:female
列:name 值:rain
删除行成功!
****************************删除后数据**********************
rowkey:1
列:age 值:20
列:gender 值:female
列:name 值:wish
rowkey:2
列:age 值:20
列:gender 值:female
列:name 值:rain
删除表
和hbase shell中类似,删除表前需要先disable表 ;分别使用disableTable和deleteTable来删除和禁用表
同创建表一样需要使用HbaseAdmin
eg:
public static void dropTable(String tableName) { try { HBaseAdmin admin = new HBaseAdmin(cfg); admin.disableTable(tableName); admin.deleteTable(tableName); System.out.println("table: "+tableName+"删除成功!"); } catch (MasterNotRunningException e) { e.printStackTrace(); } catch (ZooKeeperConnectionException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } } public static void main(String[] agrs) { try { String tablename = "wishTest"; HBaseTest.dropTable(tablename); } catch (Exception e) { e.printStackTrace(); } }
结果:
table: wishTest删除成功!
完整代码
package wish.hbase;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.KeyValue;
import org.apache.hadoop.hbase.MasterNotRunningException;
import org.apache.hadoop.hbase.ZooKeeperConnectionException;
import org.apache.hadoop.hbase.client.Delete;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.HTablePool;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
//import org.apache.hadoop.hbase.io.BatchUpdate;
@SuppressWarnings("deprecation")
public class HBaseTest {
static HBaseConfiguration cfg = null;
static {
Configuration HBASE_CONFIG = new Configuration();
HBASE_CONFIG.set("hbase.zookeeper.quorum", "192.168.1.95");
HBASE_CONFIG.set("hbase.zookeeper.property.clientPort", "2181");
cfg = new HBaseConfiguration(HBASE_CONFIG);
}
/**
* 创建一张表
*/
public static void createTable(String tableName) {
System.out.println("************start create table**********");
try {
HBaseAdmin hBaseAdmin = new HBaseAdmin(cfg);
if (hBaseAdmin.tableExists(tableName)) {// 如果存在要创建的表,那么先删除,再创建
hBaseAdmin.disableTable(tableName);
hBaseAdmin.deleteTable(tableName);
System.out.println(tableName + " is exist");
}
HTableDescriptor tableDescriptor = new HTableDescriptor(tableName);// 代表表的schema
tableDescriptor.addFamily(new HColumnDescriptor("name")); //增加列簇
tableDescriptor.addFamily(new HColumnDescriptor("age"));
tableDescriptor.addFamily(new HColumnDescriptor("gender"));
hBaseAdmin.createTable(tableDescriptor);
} catch (MasterNotRunningException e) {
e.printStackTrace();
} catch (ZooKeeperConnectionException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
System.out.println("*****end create table*************");
}
/**
* 插入数据
*/
public static void insert(String tableName) {
System.out.println("************start insert ************");
HTablePool pool = new HTablePool(cfg, 1000);
//HTable table = (HTable) pool.getTable(tableName);
Put put = new Put("2".getBytes());// 一个PUT代表一行数据,再NEW一个PUT表示第二行数据,每行一个唯一的ROWKEY,此处rowkey为put构造方法中传入的值
put.add("name".getBytes(), null, "rain".getBytes());// 本行数据的第一列
put.add("age".getBytes(), null, "20".getBytes());// 本行数据的第三列
put.add("gender".getBytes(), null, "female".getBytes());// 本行数据的第三列
try {
pool.getTable(tableName).put(put);
} catch (IOException e) {
e.printStackTrace();
}
System.out.println("************end insert************");
}
/**
* 查询所有数据
*/
public static void queryAll(String tableName) {
HTablePool pool = new HTablePool(cfg, 1000);
try {
ResultScanner rs = pool.getTable(tableName).getScanner(new Scan());
for (Result r : rs) {
System.out.println("rowkey:" + new String(r.getRow()));
for (KeyValue keyValue : r.raw()) {
System.out.println("列:" + new String(keyValue.getFamily())
+ " 值:" + new String(keyValue.getValue()));
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
/*
* 查询单条数据
*/
public static void querySingle(String tableName) {
HTablePool pool = new HTablePool(cfg, 1000);
try {
Get get = new Get("1".getBytes());// 根据rowkey查询
Result r = pool.getTable(tableName).get(get);
System.out.println("rowkey:" + new String(r.getRow()));
for (KeyValue keyValue : r.raw()) {
System.out.println("列:" + new String(keyValue.getFamily())
+ " 值:" + new String(keyValue.getValue()));
}
} catch (IOException e) {
e.printStackTrace();
}
}
/*
* 删除数据
*/
public static void deleteRow(String tablename, String rowkey) {
try {
HTable table = new HTable(cfg, tablename);
List list = new ArrayList();
Delete d1 = new Delete(rowkey.getBytes());
list.add(d1);
table.delete(list);
System.out.println("删除行成功!");
} catch (IOException e) {
e.printStackTrace();
}
}
/*
* 删除表
*/
public static void dropTable(String tableName) {
try {
HBaseAdmin admin = new HBaseAdmin(cfg);
admin.disableTable(tableName);
admin.deleteTable(tableName);
System.out.println("table: "+tableName+"删除成功!");
} catch (MasterNotRunningException e) {
e.printStackTrace();
} catch (ZooKeeperConnectionException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] agrs) {
try {
String tablename = "wishTest";
HBaseTest.dropTable(tablename);
} catch (Exception e) {
e.printStackTrace();
}
}
}