AI识虫:林业病虫害数据集和数据预处理方法
林业病虫害数据集和数据预处理方法
- 林业病虫害数据集和数据预处理
- 读取AI识虫数据集标注信息
- 数据读取和预处理
- 数据读取
使用百度与林业大学合作开发的林业病虫害防治项目中用到昆虫数据集。在这一小节中将为读者介绍该数据集,以及计算机视觉任务中常用的数据预处理方法。




林业病虫害数据集和数据预处理
读取AI识虫数据集标注信息
AI识虫数据集结构如下:
- 提供了2183张图片,其中训练集1693张,验证集245,测试集245张。
- 包含7种昆虫,分别是Boerner、Leconte、Linnaeus、acuminatus、armandi、coleoptera和linnaeus。
- 包含了图片和标注,请读者先将数据解压,并存放在insects目录下。
# 解压数据脚本,第一次运行时打开注释,将文件解压到work目录下
!unzip -d /home/aistudio/work /home/aistudio/data/data19638/insects.zip
将数据解压之后,可以看到insects目录下的结构如下所示。
insects
|---train
| |---annotations
| | |---xmls
| | |---100.xml
| | |---101.xml
| | |---...
| |
| |---images
| |---100.jpeg
| |---101.jpeg
| |---...
|
|---val
| |---annotations
| | |---xmls
| | |---1221.xml
| | |---1277.xml
| | |---...
| |
| |---images
| |---1221.jpeg
| |---1277.jpeg
| |---...
|
|---test
|---images
|---1833.jpeg
|---1838.jpeg
|---...
insects包含train、val和test三个文件夹。train/annotations/xmls目录下存放着图片的标注。每个xml文件是对一张图片的说明,包括图片尺寸、包含的昆虫名称、在图片上出现的位置等信息。
<annotation>
<folder>刘霏霏folder>
<filename>100.jpegfilename>
<path>/home/fion/桌面/刘霏霏/100.jpegpath>
<source>
<database>Unknowndatabase>
source>
<size>
<width>1336width>
<height>1336height>
<depth>3depth>
size>
<segmented>0segmented>
<object>
<name>Boernername>
<pose>Unspecifiedpose>
<truncated>0truncated>
<difficult>0difficult>
<bndbox>
<xmin>500xmin>
<ymin>893ymin>
<xmax>656xmax>
<ymax>966ymax>
bndbox>
object>
<object>
<name>Lecontename>
<pose>Unspecifiedpose>
<truncated>0truncated>
<difficult>0difficult>
<bndbox>
<xmin>622xmin>
<ymin>490ymin>
<xmax>756xmax>
<ymax>610ymax>
bndbox>
object>
<object>
<name>armandiname>
<pose>Unspecifiedpose>
<truncated>0truncated>
<difficult>0difficult>
<bndbox>
<xmin>432xmin>
<ymin>663ymin>
<xmax>517xmax>
<ymax>729ymax>
bndbox>
object>
<object>
<name>coleopteraname>
<pose>Unspecifiedpose>
<truncated>0truncated>
<difficult>0difficult>
<bndbox>
<xmin>624xmin>
<ymin>685ymin>
<xmax>697xmax>
<ymax>771ymax>
bndbox>
object>
<object>
<name>linnaeusname>
<pose>Unspecifiedpose>
<truncated>0truncated>
<difficult>0difficult>
<bndbox>
<xmin>783xmin>
<ymin>700ymin>
<xmax>856xmax>
<ymax>802ymax>
bndbox>
object>
annotation>
上面列出的xml文件中的主要参数说明如下:
size:图片尺寸
object:图片中包含的物体,一张图片可能中包含多个物体
- name:昆虫名称
- bndbox:物体真实框
- difficult:识别是否困难
下面我们将从数据集中读取xml文件,将每张图片的标注信息读取出来。在读取具体的标注文件之前,我们先完成一件事情,就是将昆虫的类别名字(字符串)转化成数字表示的类别。因为神经网络里面计算时需要的输入类型是数值型的,所以需要将字符串表示的类别转化成具体的数字。昆虫类别名称的列表是:['Boerner', 'Leconte', 'Linnaeus', 'acuminatus', 'armandi', 'coleoptera', 'linnaeus'],这里我们约定此列表中:'Boerner’对应类别0,'Leconte’对应类别1,…,'linnaeus’对应类别6。使用下面的程序可以得到表示名称字符串和数字类别之间映射关系的字典。
INSECT_NAMES = ['Boerner', 'Leconte', 'Linnaeus',
'acuminatus', 'armandi', 'coleoptera', 'linnaeus']
def get_insect_names():
"""
return a dict, as following,
{'Boerner': 0,
'Leconte': 1,
'Linnaeus': 2,
'acuminatus': 3,
'armandi': 4,
'coleoptera': 5,
'linnaeus': 6
}
It can map the insect name into an integer label.
"""
insect_category2id = {}
for i, item in enumerate(INSECT_NAMES):
insect_category2id[item] = i
return insect_category2id
cname2cid = get_insect_names()
cname2cid
{'Boerner': 0,
'Leconte': 1,
'Linnaeus': 2,
'acuminatus': 3,
'armandi': 4,
'coleoptera': 5,
'linnaeus': 6}
调用get_insect_names函数返回一个dict,描述了昆虫名称和数字类别之间的映射关系。下面的程序从annotations/xml目录下面读取所有文件标注信息。
import os
import numpy as np
import xml.etree.ElementTree as ET
def get_annotations(cname2cid, datadir):
filenames = os.listdir(os.path.join(datadir, 'annotations', 'xmls'))
records = []
ct = 0
for fname in filenames:
fid = fname.split('.')[0]
fpath = os.path.join(datadir, 'annotations', 'xmls', fname)
img_file = os.path.join(datadir, 'images', fid + '.jpeg')
tree = ET.parse(fpath)
if tree.find('id') is None:
im_id = np.array([ct])
else:
im_id = np.array([int(tree.find('id').text)])
objs = tree.findall('object')
im_w = float(tree.find('size').find('width').text)
im_h = float(tree.find('size').find('height').text)
gt_bbox = np.zeros((len(objs), 4), dtype=np.float32)
gt_class = np.zeros((len(objs), ), dtype=np.int32)
is_crowd = np.zeros((len(objs), ), dtype=np.int32)
difficult = np.zeros((len(objs), ), dtype=np.int32)
for i, obj in enumerate(objs):
cname = obj.find('name').text
gt_class[i] = cname2cid[cname]
_difficult = int(obj.find('difficult').text)
x1 = float(obj.find('bndbox').find('xmin').text)
y1 = float(obj.find('bndbox').find('ymin').text)
x2 = float(obj.find('bndbox').find('xmax').text)
y2 = float(obj.find('bndbox').find('ymax').text)
x1 = max(0, x1)
y1 = max(0, y1)
x2 = min(im_w - 1, x2)
y2 = min(im_h - 1, y2)
# 这里使用xywh格式来表示目标物体真实框
gt_bbox[i] = [(x1+x2)/2.0 , (y1+y2)/2.0, x2-x1+1., y2-y1+1.]
is_crowd[i] = 0
difficult[i] = _difficult
voc_rec = {
'im_file': img_file,
'im_id': im_id,
'h': im_h,
'w': im_w,
'is_crowd': is_crowd,
'gt_class': gt_class,
'gt_bbox': gt_bbox,
'gt_poly': [],
'difficult': difficult
}
if len(objs) != 0:
records.append(voc_rec)
ct += 1
return records
TRAINDIR = '/home/aistudio/work/insects/train'
TESTDIR = '/home/aistudio/work/insects/test'
VALIDDIR = '/home/aistudio/work/insects/val'
cname2cid = get_insect_names()
records = get_annotations(cname2cid, TRAINDIR)
通过上面的程序,将所有训练数据集的标注数据全部读取出来了,存放在records列表下面,其中每一个元素是一张图片的标注数据,包含了图片存放地址,图片id,图片高度和宽度,图片中所包含的目标物体的种类和位置。
数据读取和预处理
数据预处理是训练神经网络时非常重要的步骤。合适的预处理方法,可以帮助模型更好的收敛并防止过拟合。首先我们需要从磁盘读入数据,然后需要对这些数据进行预处理,为了保证网络运行的速度,通常还要对数据预处理进行加速。
数据读取
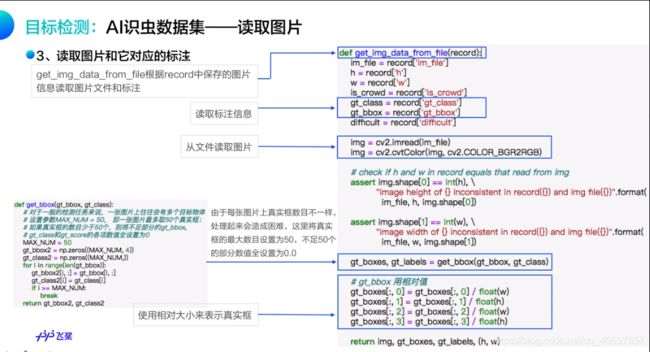
前面已经将图片的所有描述信息保存在records中了,其中每一个元素都包含了一张图片的描述,下面的程序展示了如何根据records里面的描述读取图片及标注。
### 数据读取
import cv2
def get_bbox(gt_bbox, gt_class):
# 对于一般的检测任务来说,一张图片上往往会有多个目标物体
# 设置参数MAX_NUM = 50, 即一张图片最多取50个真实框;如果真实
# 框的数目少于50个,则将不足部分的gt_bbox, gt_class和gt_score的各项数值全设置为0
MAX_NUM = 50
gt_bbox2 = np.zeros((MAX_NUM, 4))
gt_class2 = np.zeros((MAX_NUM,))
for i in range(len(gt_bbox)):
gt_bbox2[i, :] = gt_bbox[i, :]
gt_class2[i] = gt_class[i]
if i >= MAX_NUM:
break
return gt_bbox2, gt_class2
def get_img_data_from_file(record):
"""
record is a dict as following,
record = {
'im_file': img_file,
'im_id': im_id,
'h': im_h,
'w': im_w,
'is_crowd': is_crowd,
'gt_class': gt_class,
'gt_bbox': gt_bbox,
'gt_poly': [],
'difficult': difficult
}
"""
im_file = record['im_file']
h = record['h']
w = record['w']
is_crowd = record['is_crowd']
gt_class = record['gt_class']
gt_bbox = record['gt_bbox']
difficult = record['difficult']
img = cv2.imread(im_file)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# check if h and w in record equals that read from img
assert img.shape[0] == int(h), \
"image height of {} inconsistent in record({}) and img file({})".format(
im_file, h, img.shape[0])
assert img.shape[1] == int(w), \
"image width of {} inconsistent in record({}) and img file({})".format(
im_file, w, img.shape[1])
gt_boxes, gt_labels = get_bbox(gt_bbox, gt_class)
# gt_bbox 用相对值
gt_boxes[:, 0] = gt_boxes[:, 0] / float(w)
gt_boxes[:, 1] = gt_boxes[:, 1] / float(h)
gt_boxes[:, 2] = gt_boxes[:, 2] / float(w)
gt_boxes[:, 3] = gt_boxes[:, 3] / float(h)
return img, gt_boxes, gt_labels, (h, w)
get_img_data_from_file()函数可以返回图片数据的数据,它们是图像数据img,真实框坐标gt_boxes,真实框包含的物体类别gt_labels,图像尺寸scales。