Kafka:无丢失提取kafka的值,详解kafka的消费过程
目录:
1、需求
2、代码步鄹
3、代码展现
4、pom.xml文件
5、结果展现
1、需求
**前提:将org.apache.spark.streaming.kafka.KafkaCluster这个类抽出来变成KafkaClusterHelper
** 需求:
1、将kafka中的数据无丢失提取,且存到本地
2、详解Kafka读取数据步鄹
3、详解Zookeeper存储TopicAndPartition和对应的Offset
2、代码步鄹
步鄹:
1、将org.apache.spark.streaming.kafka.KafkaCluster这个类抽出来变成KafkaClusterHelper
2、编写ZookeeperHelper类便于将TopicAndPartition和对应的Offset存储到Zookeeper中
3、将类变成对象kafkaHelper
4、通过kafkaHelper.getFromOffsets获取开始的Offset,如果不是第一次则从Zookeeper中获取TopicAndPartition和对应的Offset
5、通过kafkaHelper.getLatestLeaderOffsets获取最后的Offset
6、通过org.apache.spark.streaming.kafka.OffsetRange类将TopicAndPartition和对应的Offset转为对象且放入Array数组中
7、通过org.apache.spark.streaming.kafka.KafkaUtils.createRDD方法创建RDD
8、将RDD存储本地
9、最后ZookeeperHelper类将TopicAndPartition和对应的Offset存储到Zookeeper中
3、代码展现
总计三个类:kafkaConsumer.scala KafkaClusterHelper.scala ZookeeperHelper.scala
###kafkaConsumer.scala
package com.donews.localspark
import com.donews.util.{KafkaClusterHelper,ZookeeperHelper}
import kafka.common.TopicAndPartition
import kafka.serializer.StringDecoder
import org.apache.spark.streaming.kafka.{KafkaUtils, OffsetRange}
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by yuhui on 2016/11/17.
*/
object kafkaConsumer extends Serializable{
val topicsSet = Set("donews_website_nginx_log")
val filePath = "E:\\web_nginx_log"
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("App_Name").setMaster("local[4]").set("spark.driver.port", "18080");
val sc = new SparkContext(conf)
val blockSize = 1024 * 1024 * 128 // 128MB
sc.hadoopConfiguration.setInt("dfs.blocksize", blockSize)
val kafkaParams = Map[String, String](
"metadata.broker.list" -> "tagtic-master:9092,tagtic-slave01:9092,tagtic-slave02:9092,tagtic-slave03:9092",
"auto.offset.reset" -> "smallest"
)
val kafkaHelper = new KafkaClusterHelper(kafkaParams)
var num: Long = 0
try {
//获取Zookeeper中最新的offset,如果第一次则取kafkaParams中的smallest
val offsets = ZookeeperHelper.loadOffsets(topicsSet, kafkaHelper.getFromOffsets(kafkaParams, topicsSet))
//获取kafka中最新的offset
val latestOffsets = KafkaClusterHelper.checkErrors(kafkaHelper.getLatestLeaderOffsets(offsets.keySet))
val offsetRanges = offsets.keys.map { tp =>
val fromOffset = offsets(tp)
val latestOffset = latestOffsets(tp).offset
println("topicName和partition====>"+tp+ " fromOffset====>"+fromOffset+" latestOffset====>"+latestOffset)
//OffsetRange(tp, 8800000, Math.min(fromOffset + 1024 * 1024, latestOffset)) //限制成大约是500M
OffsetRange(tp, 170000, 170006) //限制成大约是500M
}.toArray
val rdd = KafkaUtils.createRDD[String, String, StringDecoder, StringDecoder](sc, kafkaParams, offsetRanges)
println("rdd.count()====================》"+rdd.count())
//rdd存在本地
rdd.map(line=>{val lenth = line.toString().substring(38,line.toString().length-1)}).coalesce(1,true).saveAsTextFile(filePath)
val nextOffsets = offsetRanges.map(x => (TopicAndPartition(x.topic, x.partition), x.untilOffset)).toMap
//将offset存储到zookeeper,zookeeper存储路径可以删除,保证数据不丢失及数据重新读入
ZookeeperHelper.storeOffsets(nextOffsets)
}
}
}
ZookeeperHelper.scala
package com.donews.util
import kafka.common.TopicAndPartition
import org.apache.curator.framework.CuratorFrameworkFactory
import org.apache.curator.retry.ExponentialBackoffRetry
import org.slf4j.LoggerFactory
import scala.collection.JavaConversions._
/**
* Created by yuhui on 16-6-8.
*/
object ZookeeperHelper {
val LOG = LoggerFactory.getLogger(ZookeeperHelper.getClass)
val client = {
val client = CuratorFrameworkFactory
.builder
.connectString(WebConfig.ZOOKEEPER_CONNECT)
.retryPolicy(new ExponentialBackoffRetry(1000, 3))
.namespace("statistic")
.build()
client.start()
client
}
//zookeeper创建路径
def ensurePathExists(path: String): Unit = {
if (client.checkExists().forPath(path) == null) {
client.create().creatingParentsIfNeeded().forPath(path)
}
}
//zookeeper加载offset的方法
def loadOffsets(topicSet: Set[String], defaultOffset: Map[TopicAndPartition, Long]): Map[TopicAndPartition, Long] = {
val kafkaOffsetPath = s"/kafkaOffsets"
ensurePathExists(kafkaOffsetPath)
val offsets = for {
//t就是路径webstatistic/kafkaOffsets下面的子目录遍历
t <- client.getChildren.forPath(kafkaOffsetPath)
if topicSet.contains(t)
//p就是新路径 /webstatistic/kafkaOffsets/donews_website
p <- client.getChildren.forPath(s"$kafkaOffsetPath/$t")
} yield {
//遍历路径下面的partition中的offset
val data = client.getData.forPath(s"$kafkaOffsetPath/$t/$p")
//将data变成Long类型
val offset = java.lang.Long.valueOf(new String(data)).toLong
(TopicAndPartition(t, Integer.parseInt(p)), offset)
}
defaultOffset ++ offsets.toMap
}
//zookeeper存储offset的方法
def storeOffsets(offsets: Map[TopicAndPartition, Long]): Unit = {
val kafkaOffsetPath = s"/kafkaOffsets"
if (client.checkExists().forPath(kafkaOffsetPath) == null) {
client.create().creatingParentsIfNeeded().forPath(kafkaOffsetPath)
}
for ((tp, offset) <- offsets) {
val data = String.valueOf(offset).getBytes
val path = s"$kafkaOffsetPath/${tp.topic}/${tp.partition}"
ensurePathExists(path)
client.setData().forPath(path, data)
}
}
}
KafkaClusterHelper.scala
package com.donews.util
/**
* Created by yuhui on 16-6-29.
* copy from spark-kafka source
*/
import java.util.Properties
import kafka.api._
import kafka.common.{ErrorMapping, OffsetAndMetadata, OffsetMetadataAndError, TopicAndPartition}
import kafka.consumer.{ConsumerConfig, SimpleConsumer}
import org.apache.spark.SparkException
import scala.collection.mutable.ArrayBuffer
import scala.util.Random
import scala.util.control.NonFatal
/**
* Convenience methods for interacting with a Kafka cluster.
*
* @param kafkaParams Kafka
* configuration parameters.
* Requires "metadata.broker.list" or "bootstrap.servers" to be set with Kafka broker(s),
* NOT zookeeper servers, specified in host1:port1,host2:port2 form
*/
class KafkaClusterHelper(val kafkaParams: Map[String, String]) extends Serializable {
import KafkaClusterHelper.{Err, LeaderOffset, SimpleConsumerConfig}
// ConsumerConfig isn't serializable
@transient private var _config: SimpleConsumerConfig = null
def config: SimpleConsumerConfig = this.synchronized {
if (_config == null) {
_config = SimpleConsumerConfig(kafkaParams)
}
_config
}
def connect(host: String, port: Int): SimpleConsumer =
new SimpleConsumer(host, port, config.socketTimeoutMs,
config.socketReceiveBufferBytes, config.clientId)
def findLeaders(
topicAndPartitions: Set[TopicAndPartition]
): Either[Err, Map[TopicAndPartition, (String, Int)]] = {
val topics = topicAndPartitions.map(_.topic)
val response = getPartitionMetadata(topics).right
val answer = response.flatMap { tms: Set[TopicMetadata] =>
val leaderMap = tms.flatMap { tm: TopicMetadata =>
tm.partitionsMetadata.flatMap { pm: PartitionMetadata =>
val tp = TopicAndPartition(tm.topic, pm.partitionId)
if (topicAndPartitions(tp)) {
pm.leader.map { l =>
tp -> (l.host -> l.port)
}
} else {
None
}
}
}.toMap
if (leaderMap.keys.size == topicAndPartitions.size) {
Right(leaderMap)
} else {
val missing = topicAndPartitions.diff(leaderMap.keySet)
val err = new Err
err.append(new SparkException(s"Couldn't find leaders for ${missing}"))
Left(err)
}
}
answer
}
def getPartitions(topics: Set[String]): Either[Err, Set[TopicAndPartition]] = {
getPartitionMetadata(topics).right.map { r =>
r.flatMap { tm: TopicMetadata =>
tm.partitionsMetadata.map { pm: PartitionMetadata =>
TopicAndPartition(tm.topic, pm.partitionId)
}
}
}
}
def getPartitionMetadata(topics: Set[String]): Either[Err, Set[TopicMetadata]] = {
val req = TopicMetadataRequest(
TopicMetadataRequest.CurrentVersion, 0, config.clientId, topics.toSeq)
val errs = new Err
withBrokers(Random.shuffle(config.seedBrokers), errs) { consumer =>
val resp: TopicMetadataResponse = consumer.send(req)
val respErrs = resp.topicsMetadata.filter(m => m.errorCode != ErrorMapping.NoError)
if (respErrs.isEmpty) {
return Right(resp.topicsMetadata.toSet)
} else {
respErrs.foreach { m =>
val cause = ErrorMapping.exceptionFor(m.errorCode)
val msg = s"Error getting partition metadata for '${m.topic}'. Does the topic exist?"
errs.append(new SparkException(msg, cause))
}
}
}
Left(errs)
}
//获取kafka最新的offset
def getLatestLeaderOffsets(
topicAndPartitions: Set[TopicAndPartition]
): Either[Err, Map[TopicAndPartition, LeaderOffset]] =
getLeaderOffsets(topicAndPartitions, OffsetRequest.LatestTime)
def getEarliestLeaderOffsets(
topicAndPartitions: Set[TopicAndPartition]
): Either[Err, Map[TopicAndPartition, LeaderOffset]] =
getLeaderOffsets(topicAndPartitions, OffsetRequest.EarliestTime)
def getLeaderOffsets(
topicAndPartitions: Set[TopicAndPartition],
before: Long
): Either[Err, Map[TopicAndPartition, LeaderOffset]] = {
getLeaderOffsets(topicAndPartitions, before, 1).right.map { r =>
r.map { kv =>
// mapValues isnt serializable, see SI-7005
kv._1 -> kv._2.head
}
}
}
private def flip[K, V](m: Map[K, V]): Map[V, Seq[K]] =
m.groupBy(_._2).map { kv =>
kv._1 -> kv._2.keys.toSeq
}
def getLeaderOffsets(
topicAndPartitions: Set[TopicAndPartition],
before: Long,
maxNumOffsets: Int
): Either[Err, Map[TopicAndPartition, Seq[LeaderOffset]]] = {
findLeaders(topicAndPartitions).right.flatMap { tpToLeader =>
val leaderToTp: Map[(String, Int), Seq[TopicAndPartition]] = flip(tpToLeader)
val leaders = leaderToTp.keys
var result = Map[TopicAndPartition, Seq[LeaderOffset]]()
val errs = new Err
withBrokers(leaders, errs) { consumer =>
val partitionsToGetOffsets: Seq[TopicAndPartition] =
leaderToTp((consumer.host, consumer.port))
val reqMap = partitionsToGetOffsets.map { tp: TopicAndPartition =>
tp -> PartitionOffsetRequestInfo(before, maxNumOffsets)
}.toMap
val req = OffsetRequest(reqMap)
val resp = consumer.getOffsetsBefore(req)
val respMap = resp.partitionErrorAndOffsets
partitionsToGetOffsets.foreach { tp: TopicAndPartition =>
respMap.get(tp).foreach { por: PartitionOffsetsResponse =>
if (por.error == ErrorMapping.NoError) {
if (por.offsets.nonEmpty) {
result += tp -> por.offsets.map { off =>
LeaderOffset(consumer.host, consumer.port, off)
}
} else {
errs.append(new SparkException(
s"Empty offsets for ${tp}, is ${before} before log beginning?"))
}
} else {
errs.append(ErrorMapping.exceptionFor(por.error))
}
}
}
if (result.keys.size == topicAndPartitions.size) {
return Right(result)
}
}
val missing = topicAndPartitions.diff(result.keySet)
errs.append(new SparkException(s"Couldn't find leader offsets for ${missing}"))
Left(errs)
}
}
// Consumer offset api
// scalastyle:off
// https://cwiki.apache.org/confluence/display/KAFKA/A+Guide+To+The+Kafka+Protocol#AGuideToTheKafkaProtocol-OffsetCommit/FetchAPI
// scalastyle:on
// this 0 here indicates api version, in this case the original ZK backed api.
private def defaultConsumerApiVersion: Short = 0
// Try a call against potentially multiple brokers, accumulating errors
private def withBrokers(brokers: Iterable[(String, Int)], errs: Err)
(fn: SimpleConsumer => Any): Unit = {
brokers.foreach { hp =>
var consumer: SimpleConsumer = null
try {
consumer = connect(hp._1, hp._2)
fn(consumer)
} catch {
case NonFatal(e) =>
errs.append(e)
} finally {
if (consumer != null) {
consumer.close()
}
}
}
}
//获取kafka最开始的offset
def getFromOffsets(kafkaParams: Map[String, String], topics: Set[String]): Map[TopicAndPartition, Long] = {
val reset = kafkaParams.get("auto.offset.reset").map(_.toLowerCase)
val result = for {
topicPartitions <- getPartitions(topics).right
leaderOffsets <- (if (reset == Some("smallest")) {
getEarliestLeaderOffsets(topicPartitions)
} else {
getLatestLeaderOffsets(topicPartitions)
}).right
} yield {
leaderOffsets.map { case (tp, lo) =>
(tp, lo.offset)
}
}
KafkaClusterHelper.checkErrors(result)
}
}
object KafkaClusterHelper {
type Err = ArrayBuffer[Throwable]
/** If the result is right, return it, otherwise throw SparkException */
def checkErrors[T](result: Either[Err, T]): T = {
result.fold(
errs => throw new SparkException(errs.mkString("\n")),
ok => ok
)
}
case class LeaderOffset(host: String, port: Int, offset: Long)
/**
* High-level kafka consumers connect to ZK. ConsumerConfig assumes this use case.
* Simple consumers connect directly to brokers, but need many of the same configs.
* This subclass won't warn about missing ZK params, or presence of broker params.
*/
class SimpleConsumerConfig private(brokers: String, originalProps: Properties)
extends ConsumerConfig(originalProps) {
val seedBrokers: Array[(String, Int)] = brokers.split(",").map { hp =>
val hpa = hp.split(":")
if (hpa.size == 1) {
throw new SparkException(s"Broker not in the correct format of : [$brokers]")
}
(hpa(0), hpa(1).toInt)
}
}
object SimpleConsumerConfig {
/**
* Make a consumer config without requiring group.id or zookeeper.connect,
* since communicating with brokers also needs common settings such as timeout
*/
def apply(kafkaParams: Map[String, String]): SimpleConsumerConfig = {
// These keys are from other pre-existing kafka configs for specifying brokers, accept either
val brokers = kafkaParams.get("metadata.broker.list")
.orElse(kafkaParams.get("bootstrap.servers"))
.getOrElse(throw new SparkException(
"Must specify metadata.broker.list or bootstrap.servers"))
val props = new Properties()
kafkaParams.foreach { case (key, value) =>
// prevent warnings on parameters ConsumerConfig doesn't know about
if (key != "metadata.broker.list" && key != "bootstrap.servers") {
props.put(key, value)
}
}
Seq("zookeeper.connect", "group.id").foreach { s =>
if (!props.containsKey(s)) {
props.setProperty(s, "")
}
}
new SimpleConsumerConfig(brokers, props)
}
}
}
4、pom.xml文件
com.alibaba
fastjson
1.2.11
org.apache.spark
spark-sql_2.11
1.6.1
org.apache.spark
spark-streaming_2.11
1.6.1
org.apache.spark
spark-streaming-kafka_2.11
1.6.1
5、结果展现
总计有40个Partition,每个Partition中只获取6条数据,结果保存到本地的数据只有240条
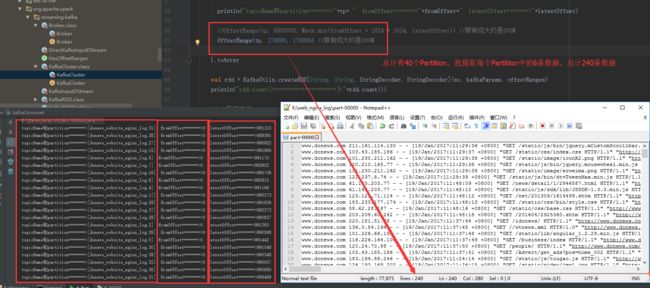
Zookeeper中存储TopicAndPartition对应的Offset

