重温大数据---Hbase部署以及架构分析
这篇文章主要介绍一下,Hbase是什么,能干什么,干的怎么样。以及Hbase的安装配置和调试等。总的来说Hbase在大数据的生态系统中占有很重要的位置,对于Hbase的学习还需要更加深入才行。对于大数据的内容我都建议多看看官方文档,以前我总觉得自己看不懂哪些高大上的,其实不然。???感觉官方文档写的都很亲民。
Hbase

HBase是一个分布式的、面向列的开源数据库,该技术来源于 Fay Chang 所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”。就像Bigtable利用了Google文件系统(File System)所提供的分布式数据存储一样,HBase在Hadoop之上提供了类似于Bigtable的能力。HBase是Apache的Hadoop项目的子项目。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。-- 百度百科
简单的说HBase就是一个分布式的可扩展的大数据量的非关系型数据库(NoSQL)。它具有一般的关系型数据 Oracle/MySQL的基础功能如:
- 存储数据
- 检索数据
- 查询数据
Hbase能做的什么
Hbase 作为一个非关系型数据库,首先就是对数据的基础的存储,其次是可以提供传统关系型数据库达不到的亿级数据量实时的查询。
- 海量数据的存储
- 海量数据的查询
Hbase在上亿的数据表里能做到秒级别查询(实时查询)
Hbase使用场景
- 交通数据
- 账单数据
- 游戏数据
- 电商交易数据
一切大数据量的,对实时查询依赖高的的场景都能解决。
Hbase在生态圈中的位置
图中可见,Hbase是基于HDFS的,也就是说Hbase的数据是存储在HDFS上面的,它可以很好地继承MapReduce和Hive来进行数据的处理。
Hbase数据存储方式存储
Hbase是非关系型数据库中典型的列式存储数据库
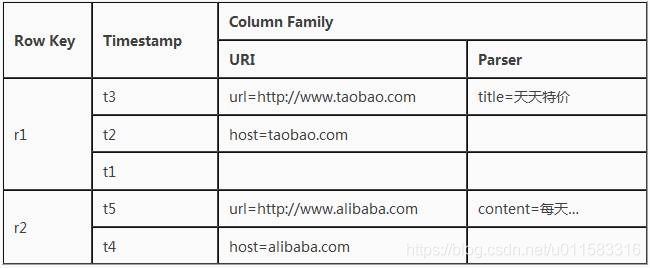
Hbase数据的组成元素
Hbase中数据是以字节数组进行存储,不存在数据类型。默认数据三份(HDFS)并且每条数据有唯一的标识符。
rowkey + columnfamily(列蔟) + column01(列名) + timestamp(时间戳) : value (值) => cell (单元)
-
Row Key: 行键,Table的主键,Table中的记录按照Row Key排序
-
Timestamp: 时间戳,每次数据操作对应的时间戳,可以看作是数据的version number
-
Column Family:列簇,Table在水平方向有一个或者多个Column Family组成,一个Column Family中可以由任意多个Column组成,即Column Family支持动态扩展,无需预先定义Column的数量以及类型,所有Column均以二进制格式存储,用户需要自行进行类型转换。
为什么Hbase能这么快呢?
关键点在于表中rowkey的设计。
1、hbase是可划分成多个region。
2、rowkey是排好序了的。
3、数据是按列存储的。
-
首先,能快速找到行所在的region(分区),假设表有10亿条记录,占空间1TB, 分列成了500个region, 1个region占2个G. 最多读取2G的记录,就能找到对应记录
-
其次,是按列存储的,其实是列族,假设分为3个列族,每个列族就是666M, 如果要查询的东西在其中1个列族上,1个列族包含1个或者多个HStoreFile,假设一个HStoreFile是128M, 该列族包含5个HStoreFile在磁盘上. 剩下的在内存中。
-
再次,是排好序了的,你要的记录有可能在最前面,也有可能在最后面,假设在中间,我们只需遍历2.5个HStoreFile共300M
-
最后,每个HStoreFile(HFile的封装),是以键值对(key-value)方式存储,只要遍历一个个数据块中的key的位置,并判断符合条件可以了。 一般key是有限的长度,假设跟value是1:19(忽略HFile上其它块),最终只需要15M就可获取的对应的记录,按照磁盘的访问100M/S,只需0.15秒。 加上块缓存机制(LRU原则),会取得更高的效率。
Hbase的数据模型
Hbase架构
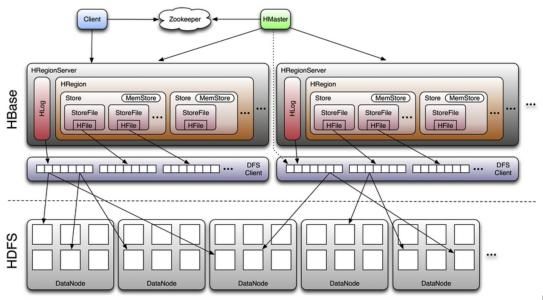
图中可见HDFS,Zookeeper。Hbase有多少个RS,其管理的内容都存在ZK的ZNode上面,ZK可以帮助用户找到某张表在哪个RS,做一个检索功能。架构的详细,请往后面看。
Hbase安装部署
-
解压安装,不必多说
-
配置hbase-env.sh 配置JDK
-
配置hbase-site.xml 设置HDFS上hbase数据存储目录,
同时关闭默认ZK管理,由我们启动自己安装的ZK。注释掉就行。
hbase-env.sh

# export HBASE_MANAGES_ZK=true
- 修改 regionservers
- 启动Hbase(提前启动Hadoop)
./hbase-deamon.sh start master
./start-hbase.sh
* zookeeper
* namenode
* datanode
* HM
- 访问Web页面 端口号60010
各个目录的含义(官方文档):
1./.tmp
这个目录用来存储临时文件,当对表进行操作的时候,首先会将表移动到该目录下,然后再进行操作。
2./WALs
WAL意为Write ahead log用来做灾难恢复。被HLog实例管理的WAL文件。
3./data
hbase 的核心目录,系统会预置两个 namespace 即:hbase和default。/data/hbase 存储了存储了 HBase 的 namespace、meta 两个系统级表。namespace 中存储了 HBase 中的所有 namespace 信息,包括预置的hbase 和 default。/data/default/ 存储所有用户数据表/data/default/表名。
4./hbase.id
存储集群唯一的 cluster id 号,是一个 uuid。
5./hbase.version
同样也是一个文件,存储集群的版本号,貌似是加密的,看不到,只能通过web-ui 才能正确显示出来。
6./oldWALs
当/WALs 中的HLog文件被持久化到存储文件中,不再需要日志文件时,它们会被移动到/oldWALs目录。
注意 :如果有需要的话就换hadoop的jar,替换Hadoop的版本。
Hbase Shell使用
-
list 查看表
-
help ‘’查看帮助细节 help ‘create’
-
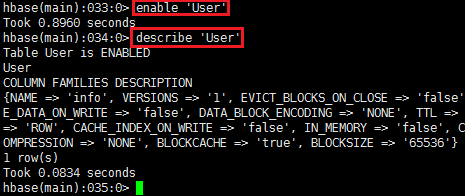
创建表 create ‘user’,‘info’
-
描述表 describe ‘user’
-
插数据 put ‘user’,‘1001’,‘info:name’,‘xianglei’ (表名,rowkey,列蔟:列名,值)
-
查看数据(三种方式)
- 依据rowkey查询,最快的
-
从memstore写到storefile flush ‘user’
-
手动compact compact ‘user’
-
查看数据
get
-
范围查询(用的最多)
scan ‘user’,{STARTROW=>‘1002’}
-
全表扫描
scan
-
删除数据
delete ‘user’,‘1001’,‘info:name’
deleteall ‘user’,‘1001’
删除所有数据
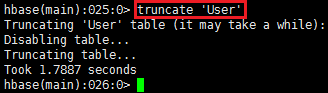
-
删除表
删除前,必须先disable
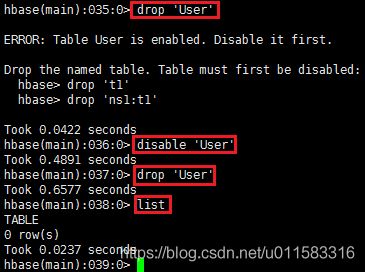
-
表的启用禁用
禁用
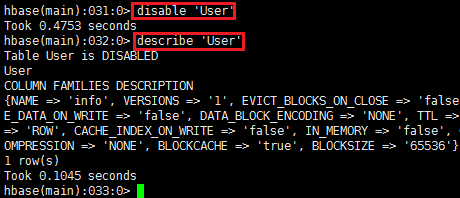
启用
Hbase 物理模型
说说Hbase中数据存储的物理模型。数据是怎么在Hbase中存储的。简单来说是按rowkey来进行动态分区(region)存储的。
细节说明:
每个columnfamily存储在HDFS上的一个单独文件中;Key 和 Version number在每个 column family中均由一份;空值不会被保存。
HBase数据写入流程
put —> cell - wal(预写日志) -> hdfs- memstore(溢写)- storefile -> hdfs
细节描述
-
Client通过Zookeeper的调度,向RegionServer发出写数据请求,在Region中写数据;
-
数据被写入Region的MemStore,知道MemStore达到预设阀值(即MemStore满);
-
MemStore中的数据被Flush成一个StoreFile;
-
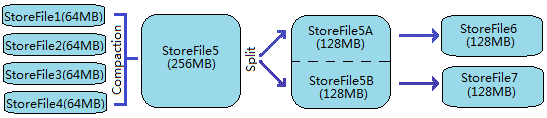
随着StoreFile文件的不断增多,当其数量增长到一定阀值后,触发Compact合并操作,将多个StoreFile合并成一个StoreFile,同时进行版本合并和数据删除;
-
StoreFiles通过不断的Compact合并操作,逐步形成越来越大的StoreFile;
-
单个StoreFile大小超过一定阀值后,触发Split操作,把当前Region Split成2个新的Region。父Region会下线,新Split出的2个子Region会被HMaster分配到相应的RegionServer上,使得原先1个Region的压力得以分流到2个Region上。
可以看出HBase只有增添数据,所有的更新和删除操作都是在后续的Compact历程中举行的,使得用户的写操作只要进入内存就可以立刻返回,实现了HBase I/O的高性能。
HBase数据读取流程
数据读取:先到memstore读(没有溢写到)再到storefile最后合并。
细节描述
-
Client访问Zookeeper,获取.META.表信息;
-
从.META.表查找,获取存放目标数据的Region信息,从而找到对应的RegionServer;
-
通过RegionServer获取需要查找的数据;
-
RegionServer的内存分为MemStore和BlockCache两部分,MemStore主要用于写数据,BlockCache主要用于读数据。读请求先到MemStore中查数据,查不到就到BlockCache中查,再查不到就会到StoreFile上读,并把读的结果放入BlockCache。
寻址过程:client—>Zookeeper–>.META. 表–>RegionServer—>Region–>User Table—>client
Hbase Region理解
Region
rowkey
startrowkey[ - stoprowkey ) 包头不包尾
0011
.. Region-00
1001
.. Region-01 <--------1009
1011
.. Region-02
1021
.. Region-03
1031
Region-04
1041
特别说明:
默认的情况下,创建一个表时,会给一个表创建一个Region这时是没有明确start(end)key的值的。
如下:
startkey
null
1200001
endkey
null
当插入数据达到一个阀值,会增加一个新的region。
Hbase 架构细节
这张图有一个缺陷就是,Hbase中一个Hlog是管理的一个HRegionServer的,不是一个HRegion。
Hbase读取数据流程说明:
客户端读取数据首先连接ZK,他需要去ZK找到这个表(region)所在的位置。
这里Zk存储了下图内容:

然后去meta表扫描信息,比如找到user的rowkey然后找到他对应的region,得到管理他的regionserver。
Master需要连接ZK是因为他需要知道哪些RS是活着的。
特殊说明:
- 有几个列蔟就有几个Store,Store里面有一个memstore和很多个storeFile。
- Hlog存在的意义是,当集群突然挂掉memstore数据丢失后,当重启机器时Hlog重新读取文件系统的数据,并且恢复回来。
RS->一个RS对应一个目录
- meta-region-server
存储meta表对应的region被哪个regionserver管理的信息
HBase新版本中,有了类似于RDBMS中DataBase的概念

- 命令空间
- 用户自定义的表,默认情况下命名空间
default
- 系统自带的元数据表的命名空间
hbase
总结
前两天的Hue的安装配置把我害惨了,最近也不打算弄了,等到后面做CDH的时候再搞搞吧。我也奉劝大家入坑需谨慎。☠☠☠
Hbase这一块需要学习的内容很多很多。这一节主要就是说说Hbase的一些基础特性,shell,以及Hbase的架构分析。内容虽然看着比较多,但是肯定也不全,暂时就记录这么多,如有需要再去看官方文档???。深入学习必不可少。