我们可以使用Python内置的urllib包来请求网络资源。但它用起来比较麻烦,而且缺少很多实用的高级功能。本文我们将会介绍一个更加方便的Python第三方库——Requests的使用。
安装Requests
要安装Requests,只要在终端中运行这个简单命令即可:
pip install -i https://pypi.douban.com/simple requests安装好Requests后,就可以开始尝试使用它啦!
发送请求
使用Requests发送网络请求非常简单。导入Requests模块:
import requests然后获取某个网页。我们来获取Github的公共时间线:
r = requests.get('https://api.github.com/events')现在,有了一个名为r的Response的对象。我们可以从这个对象中获取所有我们想要的信息。
传递URL参数
我们可能会想用URL的查询字符串传递某种数据。如果是手动构建URL,那么数据会以键值对的形式置于URL中,跟在一个问号的后面。例如,http://httpbin.org/get?key=val。Requests允许我们使用params关键字参数,以一个字符串字典来提供这些参数。举例来说,如果想传递key1=value1和key2=value2到http://httpbin.org/get,那么可以使用如下代码:
import requests
payload = {'name':'viljw', 'cat':'ruby'}
r = requests.get('http://httpbin.org/get', params=payload)打印输出该URL,能看到URL已被正确编码:
print(r.url)
# http://httpbin.org/get?name=viljw&cat=ruby响应内容
我们能读取服务器响应内容。举个例子:
import requests
r = requests.get("http://httpbin.org/get")
print(r.text)输出内容如下:

Requests会自动节码来自服务器的内容。大多数unicode字符集都能被无缝地解码。
请求发出后,Requests会基于HTTP头部对响应的编码作出有根据的推测。当访问r.text时,Requests会使用其推测的文本编码。我们可以找出Requests使用了什么编码,并且能够使用r.encoding属性来改变它:
import requests
r = requests.get("http://httpbin.org/get")
print(r.encoding)
r.encoding = 'utf-8'
print(r.encoding)
如果改变了编码,每当访问r.text,Requests都将会使用r.encoding的新值。
二进制响应内容
对于非文本请求,也能以字节的方式访问请求响应体。例如,以请求返回的二进制数据创建一张图片,可以使用如下代码:
import requests
from PIL import Image
from io import BytesIO
r = requests.get("https://github.com/fluidicon.png")
im = Image.open(BytesIO(r.content))
im.show()
JSON响应内容
Requests中有一个内置的JSON解码器,帮助我们处理JSON数据:
import requests
from pprint import pprint
payload = {'name':"viljw", 'cat':'ruby'}
r = requests.get("http://httpbin.org/get", params=payload)
pprint(r.json())
定制请求头
如果想为请求添加HTTP头部,只要简单地传递一个dict给headers参数就可。
import requests
from pprint import pprint
headers = {'User-Agent': 'viljw-agent'}
r = requests.get("http://httpbin.org/get", headers=headers)
pprint(r.json())如下图所示,User-Agent字段的值已被更改为viljw-agent。
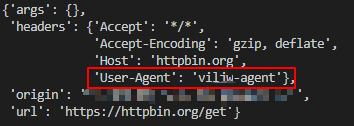
POST请求
通常,我们会想要发送一些编码为表单形式的数据——非常像一个HTML表单。要实现这个,只需要简单地传递一个字典给data参数。字典数据在发出请求时会自动编码为表单形式:
import requests
payload = {"name":"viljw", "actor":"peter"}
r = requests.post("http://httpbin.org/post", data=payload)
print(r.text)
还可以给data参数传入一个元组列表。在表单中多个元素使用同一key的时候,这种方式很有用:
import requests
payload = [("name","viljw"), ("actor","peter"),("actor",'marry')]
r = requests.post("http://httpbin.org/post", data=payload)
print(r.text)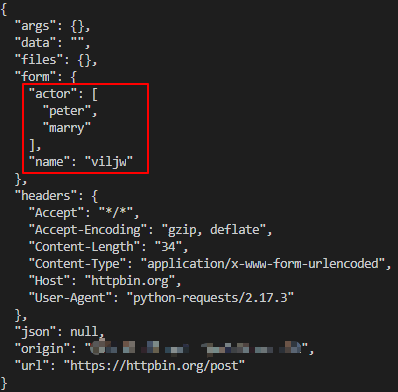
响应状态码
我们可以查看响应状态码:
import requests
r = requests.get("http://httpbin.org/get")
print(r.status_code)
# 200为了方便使用,Requests附带了也给内置的状态码查询对象:
r.status_code == requests.codes.ok
# True如果发送了一个错误请求(一个4XX客户端错误,或5XX服务器错误响应),我们可以通过Response.raise_for_status()来抛出异常:
In [1]: import requests
In [2]: bad_r = requests.get('http://httpbin.org/status/404')
In [3]: bad_r.status_code
Out[3]: 404
In [4]: bad_r.raise_for_status()
---------------------------------------------------------------------------
HTTPError Traceback (most recent call last)
in ()
----> 1 bad_r.raise_for_status()
c:\python\lib\site-packages\requests\models.py in raise_for_status(self)
927
928 if http_error_msg:
--> 929 raise HTTPError(http_error_msg, response=self)
930
931 def close(self):
HTTPError: 404 Client Error: NOT FOUND for url: http://httpbin.org/status/404 但由于我们的例子中r的status_code是200,当我们调用raise_for_status()时,得到的是:
In [6]: r.raise_for_status()
# None响应头
我们可以查看以字典形式的服务器响应头:
In [7]: r.headers
Out[7]: {'Access-Control-Allow-Credentials': 'true', 'Access-Control-Allow-Origin': '*', 'Content-Encoding': 'gzip', 'Content-Type': 'application/json', 'Date': 'Thu, 03 Oct 2019 07:11:16 GMT', 'Referrer-Policy': 'no-referrer-when-downgrade', 'Server': 'nginx', 'X-Content-Type-Options': 'nosniff', 'X-Frame-Options': 'DENY', 'X-XSS-Protection': '1; mode=block', 'Content-Length': '184', 'Connection': 'keep-alive'}Cookie
如果某个响应中包含一些cookie,可以快速访问它们:
In [19]: r = requests.get('https://www.baidu.com')
In [20]: r.cookies
Out[20]:
In [21]: r.cookies['BDORZ']
Out[21]: '27315' 要想发送cookies到服务器,可以使用cookies参数:
In [27]: url = 'http://httpbin.org/cookies'
In [28]: cookies = dict(cookies_are="working")
In [29]: r = requests.get(url, cookies=cookies)
In [30]: r.json()
Out[30]: {'cookies': {'cookies_are': 'working'}}超时
可以告诉Requests在经过以timeout参数设定的秒数时间之后停止等待响应。
>>> requests.get('http://github.com', timeout=0.001)
Traceback (most recent call last):
File "", line 1, in
requests.exceptions.Timeout: HTTPConnectionPool(host='github.com', port=80): Request timed out. (timeout=0.001) 错误与异常
遇到网络问题(如:DNS查询失败、拒绝连接等)时,Requests会抛出一个ConnectionError异常。
如果HTTP请求返回了不成功的状态码, Response.raise_for_status()会抛出一个HTTPError异常。
若请求超时,则抛出一个Timeout异常。
若请求超过了设定的最大重定向次数,则会抛出一个TooManyRedirects异常。
所有Requests显式抛出的异常都继承自 requests.exceptions.RequestException 。
代理
如果需要使用代理,可以通过任意请求方法提供proxies参数来配置单个请求:
import requests
proxies = {
'https': 'https://127.0.0.1:1080'
}
r = requests.get('https://www.google.com', proxies=proxies)
print(r.status_code)
# 200也可以通过环境变量HTTP_PROXY和HTTPS_PROXY来配置代理。
$ export HTTP_PROXY="http://10.10.1.10:3128"
$ export HTTPS_PROXY="http://10.10.1.10:1080"
$ python
>>> import requests
>>> requests.get("http://example.org")