使用XGboost模块XGBClassifier、plot_importance来做特征重要性排序
anaconda安装xgboost库戳这儿
更新:修改f1,f2等字段请戳这里
'''
参考:http://www.shujuren.org/article/625.html
'''
from numpy import loadtxt
from xgboost import XGBClassifier
from xgboost import plot_importance
from matplotlib import pyplot
import warnings
warnings.filterwarnings("ignore")
# np.load_txt使用方法:www.manongjc.com/article/4883.html
# 以','为分割符,跳过1行(标features那一行)
dataset = loadtxt(r"H:\randomForest_file\feat_sort\XGboot\label_csv.csv", skiprows=1, delimiter=",")
print(dataset)
# 数据集划分特征矩阵X和目标变量y
X = dataset[:,1:-1] # 每一行都要(之前已经把第一行跳过了,所以这里全都是纯数据)
y = dataset[:,-1] # 这个是分类结果label
print('*****************')
# print(X)
print(y.shape)
# 全量数据集训练模型
model = XGBClassifier()
model.fit(X, y)
# 变量重要性列表
print(model.feature_importances_)
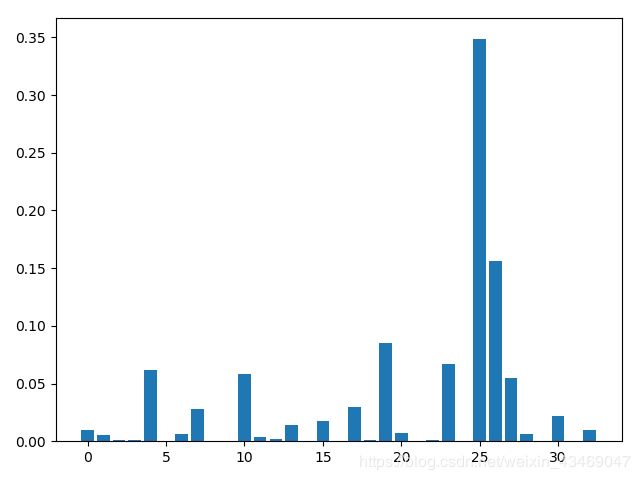
# 变量重要性可视化
pyplot.bar(range(len(model.feature_importances_)), model.feature_importances_)
pyplot.show()
# 变量重要性排序可视化
plot_importance(model)
pyplot.show()
因为原数据保密,你们用下面的数据集data.csv也可以(看下格式就好啦~)
1.特征值重要性图:
2.特征重要性排序图:
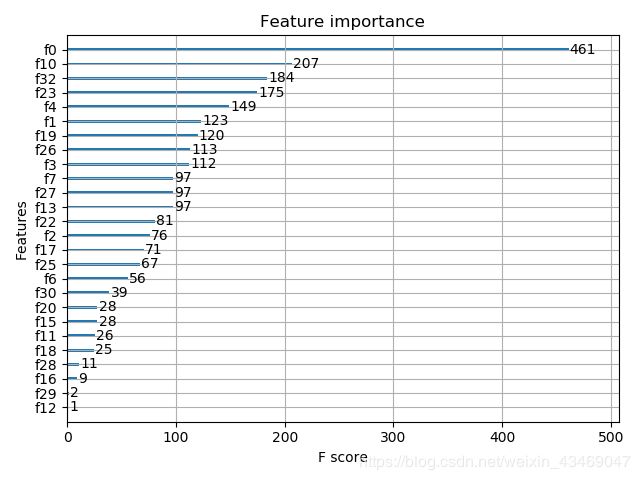
(这里有个不完美的地方,xgboost模块竟然没有提供改feature name的方法!所以全是f0,f1,f2,…,你只能对照数据文件看谁是第0个feature谁是第1个了)
想要修改f1,f2等字段请戳这里