Centos7下安装Hbase伪分布式图文详解
一、什么是Hbase
HBase是一个开源的非关系型分布式数据库,实现的编程语言为Java。它是Apache软件基金会Hadoop项目的一部分,运行于HDFS文件系统之上。HBase,是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PCServer上搭建起大规模结构化存储集群。
二、安装前提以及安装包
安装了Hadoop的伪分布式或者完全分布式集群
安装Hadoop链接
安装包百度云链接
提取码:h7ab
java、Hadoop与HBase存在一定的匹配关系


在这里我选择的是Hadoop2.7.7和Hbase1.3.6版本进行搭配
三、首先安装zookeeper
ZooKeeper是一个分布式的,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。zookeeper看安装可不安装,因为hbase自带有,但这里我们还是安装。
1、解压
[root@master ~]# tar -zxvf zookeeper-3.4.14.tar.gz -C /opt

2、更改名字
[root@master opt]# mv zookeeper-3.4.14 zookeeper
3、配置环境
[root@master opt]# vim /etc/profile
添加以下内容:
export ZOOKEEPER_HOME="/opt/zookeeper/"
export PATH=.:$HADOOP_HOME/bin:$ZOOKEEPER_HOME/bin:$JAVA_HOME/bin:$PATH

4、配置生效
[root@master opt]# source /etc/profile
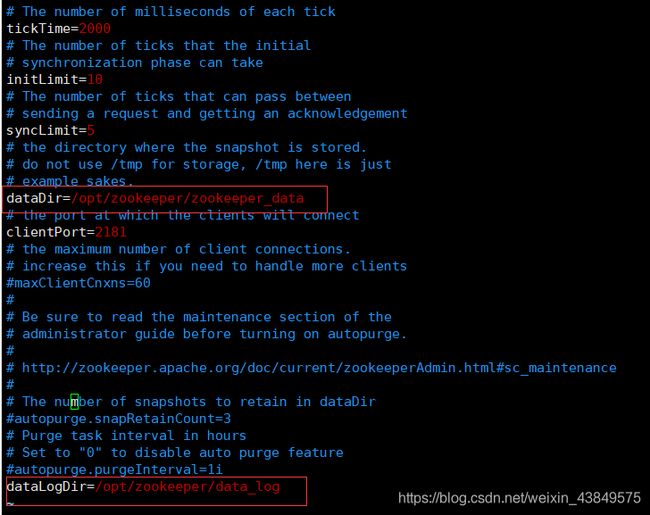
5、配置文件zoo.cfg(文件在/zookeeper/conf下)
因为没有zoo.cfg文件,所以:
[root@master conf]# cp zoo_sample.cfg zoo.cfg
然后编辑这个文件,添加以下内容:
dataDir=/opt/zookeeper/zookeeper_data
dataLogDir=/opt/zookeeper/data_log
注:这里的文件不需要自己手动创建文件,自动生成
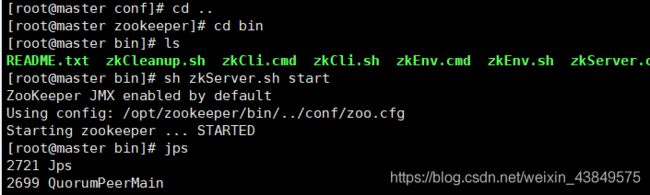
6、启动测试
到bin下
[root@master bin]# sh zkServer.sh start
[root@master bin]# sh zkServer.sh status
我们可以看到它的模式为:standalone
jps查看一下节点
有QuorumPeerMain,就证明是ok的
最后sh zkServer.sh stop把它关了
四、安装Hbase
1、解压
[root@master ~]# tar -zxvf hbase-1.3.6-bin.tar.gz -C /opt
![]()
2、更改名字
[root@master opt]# mv hbase-1.3.6 hbase
3、配置环境
[root@master opt]# vim /etc/profile
添加以下内容:
export HBASE_HOME="/opt/hbase/"
export PATH=$PATH:$HBASE_HOME/bin

4、配置生效
[root@master opt]# source /etc/profile
5、配置文件(文件在/hbase/conf/下)
(1)、hbase-env.sh文件
添加以下内容:
export JAVA_HOME=/opt/jdk1.8.0_201/
export HBASE_PID_DIR=/opt/hbase/pids
export HBASE_MANAGES_ZK=false
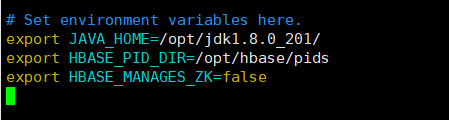
注:false是自己下载的zookeeper,true是hbase自带
(2)、hbase-site.xml 文件
添加以下文件:
hbase.rootdir
hdfs://master:9000/hbase
hbase.rootdir是RegionServer的共享目录,用来持久化存储HBase数据的,默认是写到/tmp的,如果不修改此配置,在HBase重启时,数据会丢失。此处一般设置的是hdfs的文件目录,比如NameNode运行在namenode.Example.org主机的9090端口,则需要设置为hdfs://namenode.example.org:9000/hbase
hbase.cluster.distributed
true
此项用来配置HBase的部署模式,false表示单机,true表示完全分布式模式或者伪分布式模式。
hbase.tmp.dir
/opt/hbase/tmp
hbase.zookeeper.property.dataDir
/opt/hbase/zk_data
hbase.zookeeper.quorum
master
hbase.zookeeper.property.clientPort
2181

注:不需要创建文件,它会自动给你创建文件
6、运行
注:确保首先运行 HDFS,如果使用自己的zookeeper也要启动
启动顺序
Hadoop及hbase集群启动顺序hadoop->zookeeper->hbase
停止顺序
Hadoop及hbase集群关闭顺序hbase->zookeeper->Hadoop
既:
(1)、[root@master ~]# start-all.sh
(2)、[root@master bin]# sh zkServer.sh start
(3)、[root@master bin]# start-hbase.sh
注:一定要到相应的目录文件去启动
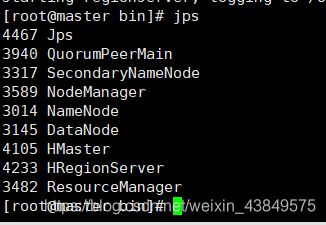
全部启动后jps查看一下,如果有这些节点就说明没什么问题!
五、shell命令
[root@master bin]# hbase shell
使用 create 命令创建一个新表。我们必须指定表名称和列族名称:
hbase(main):001:0> create 'test', 'cf'
Created table test
Took 1.2144 seconds
=> Hbase::Table - test
使用 list 命令确认表是否存在
hbase(main):002:0> list 'test'
TABLE
test
1 row(s)
Took 0.0378 seconds
使用 put 命令将数据放入表中:
hbase(main):005:0> put 'test', 'row1', 'cf:a', 'value1'
Took 0.1687 seconds
从 HBase 获取数据的一种方法是扫描。使用 scan 命令扫描表中的数据:
hbase(main):008:0> scan 'test'
ROW COLUMN+CELL
row1 column=cf:a, timestamp=1570442045109, value=value1
1 row(s)
Took 0.0038 seconds

要多练习Hbase shell命令,来认识Hbase。可以从网上找Hbase shell命令来练习一下。