Seq2Seq源码解析(基于Theano框架)
1、初步认识 se2seq
1.1 这是一个通用型 端到端(end-to-end)的学习框架,包括2个部分,一个是Encoder(编码器,负责编码源句子的输入),另外一个是Decoder(解码器,负责解析目标句子的生成)。你既可以用它来做翻译模型,也可以用来做单轮或多轮对话系统、甚至古诗词生成任务等等等…… (简直是深度学习的万金油啊!)
1.2 关于seq2seq的两篇经典之作,希望大家都去拜读一下原文,真的写得很棒!
第一篇采用seq2seq翻译模型框架
Sutskever et al., 2014. Sequence to Sequence Learning with Neural Networks
第一篇采用seq2seq+attention机制
Neural Machine Translation by Jointly Learning to Align and Translate
2、简单了解 seq2seq
2.1 基于Theano框架的seq2seq源码github地址
https://github.com/nyu-dl/dl4mt-tutorial
2.2 下载完解压缩,得到如下文件:
其中,session1是不带attention机制的seq2seq,session2是带attention机制的seq2seq。提醒一下:本次代码剖析是不带attention机制的seq2seq,即session1文件。
2.3 如何运行这份代码
首先 ,假如你拥有了一份平行语料库(源数据集合,目标数据集合)。你应该修改data目录下的setup_local_env.sh,修改输入数据的路径,以及经过处理后数据保存的路径(生成.tok文件,生成的源/目标字典.pkl)。 (运行命令: ./setup_local_env.sh)
其次 ,训练模型的时候。修改session1目录下的train.sh,记得设置成gpu(否则cpu得跑N天啊,N=无穷大),对应代码 export THEANO_FLAGS=device= gpu ,floatX=float32 。因为train.sh本质上是运行python train_nmt.py,因此你得修改session1目录下的train_nmt.py,设置数据的路径,以及初始化一些参数。
最后 ,如果你想测试模型。运行session1目录下的test.sh,设置数据路径、源/目标字典路径、训练好的模型路径等等参数。本质上是运行session1目录下的translate.py
3、深入解析 se2seq
这里,我将分2部分进行源码的解析,分别包括训练部分train和测试部分test。
3.1 训练部分train :
3.1.1 首先阅读nmt.py脚本的def train()函数
最终训练调用路径如下:
train.sh –> train_nmt.py –> nmt.py
train_nmt.py中几个关键的参数
'model': 存储训练模型的路径
'dim_word': 词向量的维度,也就是把输入x,数字单词转成dim_word维数的词向量word vertor。
'dim': GRU单元数的数目,也就是Encoder和Decoder隐藏层的数目
'n-words': 源字典和目标字典的大小,不在该字典的单词,为unk,对应数字1。
'optimizer': 更新参数选择'adadelta'算法,当然你也可以采用较为简单的'SGD'随机梯度下降算法。
'decay-c': 正则化惩罚项,这么暂时不考虑
'use-dropout': dropout机制防止过拟合,提高模型泛化能力,暂时不考虑
'learning-rate': 学习率,只有更新参数算法采用'SGD',才会用到学习率。
'reload':这个参数值得重视。reload建议设置为True,训练模型的过程中,即使机器崩溃了,下次训练可以接着上次的断点继续训练。
3.1.2 nmt.py脚本中的train()函数
数据真正开始驱动的地方! 代码如下:
def train(dim_word=100, # word vector dimensionality
dim=1000, # the number of GRU units
encoder='gru',
decoder='gru_cond_simple',
patience=10, # early stopping patience
max_epochs=5000,
finish_after=10000000, # finish after this many updates
dispFreq=100,
decay_c=0., # L2 regularization penalty
alpha_c=0., # not used
lrate=0.01, # learning rate
n_words_src=100000, # source vocabulary size
n_words=100000, # target vocabulary size
maxlen=100, # maximum length of the description
optimizer='rmsprop',
batch_size=16,
valid_batch_size=16,
saveto='model.npz',
validFreq=1000,
saveFreq=1000, # save the parameters after every saveFreq updates
sampleFreq=100, # generate some samples after every sampleFreq
datasets=[
'/data/lisatmp3/chokyun/europarl/europarl-v7.fr-en.en.tok',
'/data/lisatmp3/chokyun/europarl/europarl-v7.fr-en.fr.tok'],
valid_datasets=['../data/dev/newstest2011.en.tok',
'../data/dev/newstest2011.fr.tok'],
dictionaries=[
'/data/lisatmp3/chokyun/europarl/europarl-v7.fr-en.en.tok.pkl',
'/data/lisatmp3/chokyun/europarl/europarl-v7.fr-en.fr.tok.pkl'],
use_dropout=False,
reload_=False,
overwrite=False):
# Model options
model_options = locals().copy()
# load dictionaries and invert them
worddicts = [None] * len(dictionaries)
worddicts_r = [None] * len(dictionaries)
for ii, dd in enumerate(dictionaries):
with open(dd, 'rb') as f:
worddicts[ii] = pkl.load(f)
worddicts_r[ii] = dict()
for kk, vv in worddicts[ii].iteritems():
worddicts_r[ii][vv] = kk
# reload options
if reload_ and os.path.exists(saveto):
print 'Reloading model options'
with open('%s.pkl' % saveto, 'rb') as f:
model_options = pkl.load(f)
print 'Loading data'
train = TextIterator(datasets[0], datasets[1],
dictionaries[0], dictionaries[1],
n_words_source=n_words_src, n_words_target=n_words,
batch_size=batch_size,
maxlen=maxlen)
valid = TextIterator(valid_datasets[0], valid_datasets[1],
dictionaries[0], dictionaries[1],
n_words_source=n_words_src, n_words_target=n_words,
batch_size=valid_batch_size,
maxlen=maxlen)
print 'Building model'
params = init_params(model_options)
# reload parameters
if reload_ and os.path.exists(saveto):
print 'Reloading model parameters'
params = load_params(saveto, params)
tparams = init_tparams(params)
trng, use_noise, \
x, x_mask, y, y_mask, \
opt_ret, \
cost = \
build_model(tparams, model_options)
inps = [x, x_mask, y, y_mask]
print 'Building sampler'
f_init, f_next = build_sampler(tparams, model_options, trng, use_noise)
# before any regularizer
print 'Building f_log_probs...',
f_log_probs = theano.function(inps, cost, profile=profile)
print 'Done'
cost = cost.mean()
# apply L2 regularization on weights
if decay_c > 0.:
decay_c = theano.shared(numpy.float32(decay_c), name='decay_c')
weight_decay = 0.
for kk, vv in tparams.iteritems():
weight_decay += (vv ** 2).sum()
weight_decay *= decay_c
cost += weight_decay
# un used, attention weight regularization
if alpha_c > 0. and not model_options['decoder'].endswith('simple'):
alpha_c = theano.shared(numpy.float32(alpha_c), name='alpha_c')
alpha_reg = alpha_c * (
(tensor.cast(y_mask.sum(0)//x_mask.sum(0), 'float32')[:, None] -
opt_ret['dec_alphas'].sum(0))**2).sum(1).mean()
cost += alpha_reg
# after all regularizers - compile the computational graph for cost
print 'Building f_cost...',
f_cost = theano.function(inps, cost, profile=profile)
print 'Done'
print 'Computing gradient...',
grads = tensor.grad(cost, wrt=itemlist(tparams))
print 'Done'
# compile the optimizer, the actual computational graph is compiled here
lr = tensor.scalar(name='lr')
print 'Building optimizers...',
f_grad_shared, f_update = eval(optimizer)(lr, tparams, grads, inps, cost)
print 'Done'
print 'Optimization'
best_p = None
bad_counter = 0
uidx = 0
estop = False
history_errs = []
# reload history
if reload_ and os.path.exists(saveto):
rmodel = numpy.load(saveto)
history_errs = list(rmodel['history_errs'])
if 'uidx' in rmodel:
uidx = rmodel['uidx']
if validFreq == -1:
validFreq = len(train[0])/batch_size
if saveFreq == -1:
saveFreq = len(train[0])/batch_size
if sampleFreq == -1:
sampleFreq = len(train[0])/batch_size
for eidx in xrange(max_epochs):
n_samples = 0
for x, y in train:
n_samples += len(x)
uidx += 1
use_noise.set_value(1.)
print "---------------"
print x
x, x_mask, y, y_mask = prepare_data(x, y, maxlen=maxlen,
n_words_src=n_words_src,
n_words=n_words)
if x is None:
print 'Minibatch with zero sample under length ', maxlen
uidx -= 1
continue
ud_start = time.time()
# compute cost, grads and copy grads to shared variables
cost = f_grad_shared(x, x_mask, y, y_mask)
# do the update on parameters
f_update(lrate)
ud = time.time() - ud_start
# check for bad numbers, usually we remove non-finite elements
# and continue training - but not done here
if numpy.isnan(cost) or numpy.isinf(cost):
print 'NaN detected'
return 1., 1., 1.
# verbose
if numpy.mod(uidx, dispFreq) == 0:
print 'Epoch ', eidx, 'Update ', uidx, 'Cost ', cost, 'UD ', ud
# save the best model so far, in addition, save the latest model
# into a separate file with the iteration number for external eval
if numpy.mod(uidx, saveFreq) == 0:
print 'Saving the best model...',
if best_p is not None:
params = best_p
else:
params = unzip(tparams)
numpy.savez(saveto, history_errs=history_errs, uidx=uidx, **params)
pkl.dump(model_options, open('%s.pkl' % saveto, 'wb'))
print 'Done'
# save with uidx
if not overwrite:
print 'Saving the model at iteration {}...'.format(uidx),
saveto_uidx = '{}.iter{}.npz'.format(
os.path.splitext(saveto)[0], uidx)
numpy.savez(saveto_uidx, history_errs=history_errs,
uidx=uidx, **unzip(tparams))
print 'Done'
# generate some samples with the model and display them
if numpy.mod(uidx, sampleFreq) == 0:
# FIXME: random selection?
for jj in xrange(numpy.minimum(5, x.shape[1])):
stochastic = True
sample, score = gen_sample(tparams, f_init, f_next,
x[:, jj][:, None],
model_options, trng=trng, k=1,
maxlen=30,
stochastic=stochastic,
argmax=False)
print 'Source ', jj, ': ',
for vv in x[:, jj]:
if vv == 0:
break
if vv in worddicts_r[0]:
print worddicts_r[0][vv],
else:
print 'UNK',
print
print 'Truth ', jj, ' : ',
for vv in y[:, jj]:
if vv == 0:
break
if vv in worddicts_r[1]:
print worddicts_r[1][vv],
else:
print 'UNK',
print
print 'Sample ', jj, ': ',
if stochastic:
ss = sample
else:
score = score / numpy.array([len(s) for s in sample])
ss = sample[score.argmin()]
for vv in ss:
if vv == 0:
break
if vv in worddicts_r[1]:
print worddicts_r[1][vv],
else:
print 'UNK',
print
# validate model on validation set and early stop if necessary
if numpy.mod(uidx, validFreq) == 0:
use_noise.set_value(0.)
valid_errs = pred_probs(f_log_probs, prepare_data,
model_options, valid)
valid_err = valid_errs.mean()
history_errs.append(valid_err)
if uidx == 0 or valid_err <= numpy.array(history_errs).min():
best_p = unzip(tparams)
bad_counter = 0
if len(history_errs) > patience and valid_err >= \
numpy.array(history_errs)[:-patience].min():
bad_counter += 1
if bad_counter > patience:
print 'Early Stop!'
estop = True
break
if numpy.isnan(valid_err):
ipdb.set_trace()
print 'Valid ', valid_err
# finish after this many updates
if uidx >= finish_after:
print 'Finishing after %d iterations!' % uidx
estop = True
break
print 'Seen %d samples' % n_samples
if estop:
break
if best_p is not None:
zipp(best_p, tparams)
use_noise.set_value(0.)
valid_err = pred_probs(f_log_probs, prepare_data,
model_options, valid).mean()
print 'Valid ', valid_err
params = copy.copy(best_p)
numpy.savez(saveto, zipped_params=best_p,
history_errs=history_errs,
uidx=uidx,
**params)
return valid_err
代码解析:
第147行: 从这句代码开始,才真正有数据开始驱动! for x in train 首先调用了第54行TextIterator,即data_iterator.py脚本中的 next()函数,此时返回了x的实例化数据,for example(这里取batch=2):
x=
[[64 103]
[2 40 ]
[2 41 ]
[2 42 ]
[3 43 ]
[2 0]
[2 0]
[65 0 ]
[66 0 ]
[67 0]
[0 0]]
第153行: 调用了nmt.py脚本中的prepare_data()函数,返回了x和x_mask。for example:
x=
[[64 103]
[2 40 ]
[2 41 ]
[2 42 ]
[3 43 ]
[2 0]
[2 0]
[65 0 ]
[66 0 ]
[67 0]
[0 0]]
x_mask=
[[1 1]
[1 1]
[1 1]
[1 1]
[1 1]
[1 1]
[1 0]
[1 0]
[1 0]
[1 0]
[1 0]]
第165行: 计算cost,调用流畅如下:
其中,第120行 optimizer参数更新优化器选用的是adadelta,当然你也可以选用adam、rmsprop或者比较耳熟能详的sgd。 所以最终cost计算是在build_model函数中定义的,so, 我们迫不及待地去看看nmt.py脚本中的build_model()函数吧!!!
第168行: f_update(lrate) ,其中lrate为学习率。因为这里选用更新优化参数为adadelta,该算法与学习率无关。若采用SGD,则更新参数与学习率有关。调用流程如下:
到此,一次batch样本更新了一次权重参数。
第179行: 每迭代dispFreq次数batch样本,打印一次结果。
第184行:每迭代saveFreq次数batch样本,保存一次模型参数,模型放置的路径为saveto
第205行: 每迭代sampleFreq次数batch样本,显示5个源句子翻译的结果,这里调用了gen_sample()函数,也就是开始进行测试输出结果了,看看系统训练得好不好。 因此,我们赶紧去nmt.py脚本中的gen_sample()函数瞧个究竟,到底测试的时候是如何输出一个单词一个单纯蹦出来,最终组合成一个目标句子的。
第216-222行: 打印源句子x
第224-231: 打印 Ground True句子y
第234-246: 因为这里采用随机采样的方式生成目标单词,所以,sample变量便是生成的目标句子。 然后,打印生成的目标句子。
第249-270行: 输出验证集的cost。如果验证集的cost一直掉不下来,也就没必要继续训练下去了。因为验证集和测试集通常具有相同的数据分布。因此,可以通过验证集cost的最低点,找到最好的model参数。
3.1.3 data_iterator.py脚本中的 next()函数
实现字母单词到数字单词的转换!,并返回batch个源句子和目标句子
代码如下:
while True:
# read from source file and map to word index
try:
ss = self.source_buffer.pop()
except IndexError:
break
ss = [self.source_dict[w] if w in self.source_dict else 1 for w in ss]
if self.n_words_source > 0:
ss = [w if w < self.n_words_source else 1 for w in ss]
# read from source file and map to word index
tt = self.target_buffer.pop()
tt = [self.target_dict[w] if w in self.target_dict else 1
for w in tt]
if self.n_words_target > 0:
tt = [w if w < self.n_words_target else 1 for w in tt]
if len(ss) > self.maxlen and len(tt) > self.maxlen:
continue
source.append(ss)
target.append(tt)
if len(source) >= self.batch_size or \
len(target) >= self.batch_size:
break代码解析:
第4行: 每次弹出一个句子赋给ss变量;
第7行:将句子的单词变成其相对于的数字,即判断句子的每一个单词,若字典中存在对应的数字,则用该数字替代,反之则为1。其中,数字1对应‘UNK’,数字0对应‘EOS’。
该句子代码可以按如下理解:
for w in ss:
if w in self.source_dict:
self.source_dict[w]
else:
1第9行:判断该数字值是否超过的源字典的大小,若小于说明该字母对应的数字在字典内;否则不在字典内,则修改为1,即为 ‘unk’。为什么要进行这一步操作呢,而不把源字典设置得足够大呢,避免unk的出现?
原因有以下2点:
1) 这是因为源字典设置的太大,W权重的维数增加,操作大维数的矩阵是非常耗时间的,通常字典大小设置在万数量级。
2)超过源字典大小的数字,一般在train集出现的频次较低,所以设置维1影响不会太大。因为字典是根据train集合单词出现频次从小到大排列的。
第21、22行:把单词替换成数字的句子添加到source和target列表对象中。
第24行:如果source或者target里面有self.batch_size个句子,则break,即每次return 回去的source和target都包含batch_size个由数字组成的句子。
假设batch_size的大小为2,则return回去的source的格式为
[ [64,2,2,2,3,2,2,65,66,67,],[103,40,41,42,43] ]
继续返回nmt.py脚本中的train()函数吧!
3.1.4 nmt.py脚本中的prepare_data()函数
给x和y分别准备x_mask和y_mask层,目的是防止padding 0带来的误差影响。为什么要进行这一步准备mask的操作?
为了提高运行速度同时防止梯度波动太大,梯度更新采用了batch_size的方式。此时,就必须保证batch_size句子的长度相等。因此,选取了最长句子的长度作为标准,其他句子补0与之对齐。
正因为其他句子进行了补0对齐操作,然而在实际GRU计算中,在每个timestep,这些填充的0仍然会喂给网络的隐藏层,引发错误操作。因此,需要加入mask层来剔除,过滤那些填充0所带来的影响。
这里不妨假设seqs_x=[ [64,2,2,2,3,2,2,65,66,67,],[103,40,41,42,43] ],即batch_size设置为2.
代码如下:
def prepare_data(seqs_x, seqs_y, maxlen=None,
n_words_src=30000, n_words=30000):
# x: a list of sentences
lengths_x = [len(s) for s in seqs_x]
lengths_y = [len(s) for s in seqs_y]
# filter sequences according to maximum sequence length
if maxlen is not None:
new_seqs_x = []
new_seqs_y = []
new_lengths_x = []
new_lengths_y = []
for l_x, s_x, l_y, s_y in zip(lengths_x, seqs_x, lengths_y, seqs_y):
if l_x < maxlen and l_y < maxlen:
new_seqs_x.append(s_x)
new_lengths_x.append(l_x)
new_seqs_y.append(s_y)
new_lengths_y.append(l_y)
lengths_x = new_lengths_x
seqs_x = new_seqs_x
lengths_y = new_lengths_y
seqs_y = new_seqs_y
if len(lengths_x) < 1 or len(lengths_y) < 1:
return None, None, None, None
n_samples = len(seqs_x)
maxlen_x = numpy.max(lengths_x) + 1
maxlen_y = numpy.max(lengths_y) + 1
# pad batches and create masks
x = numpy.zeros((maxlen_x, n_samples)).astype('int64')
y = numpy.zeros((maxlen_y, n_samples)).astype('int64')
x_mask = numpy.zeros((maxlen_x, n_samples)).astype('float32')
y_mask = numpy.zeros((maxlen_y, n_samples)).astype('float32')
for idx, [s_x, s_y] in enumerate(zip(seqs_x, seqs_y)):
x[:lengths_x[idx], idx] = s_x
x_mask[:lengths_x[idx]+1, idx] = 1.
y[:lengths_y[idx], idx] = s_y
y_mask[:lengths_y[idx]+1, idx] = 1.
return x, x_mask, y, y_mask代码解析:
第5行: lengths_x=[10,5]
第15-19行:过滤掉单词长度大于maxlen的句子,这里maxlen设置为50。因为不带attention机制的GRU或者LSTM,端对端翻译模型随着源句子单词数的增加,翻译效果急剧下降。因为,随着句子长度的增加,会丢失很多语义之间的信息。
第29行: maxlen_x=max(10,5)+1,即为11。为了提高运行速度同时防止梯度波动太大,梯度更新采用了batch_size的方式。此时,就必须保证batch_size句子的长度相等。因此,选取了最长句子的长度10作为标准,其他句子补0与之对齐。加1,是为了在每个句子末尾添加一个0,表示‘eos’,即句子结束标识符。
第33、35行: x和x_mask均初始化为11*2的二维数组,并全部赋值为0,之所以x_mask数据类型为float32,是因为其后面需要参与theano共享变量的运算,而theano共享变量需要设置为float32的类型,才能在GPU进行加速计算。
第37-42行: 最终x值如下,即句子最后末尾添加了一个句子结束标识符0,代表‘eos
x=
[[64 103]
[2 40 ]
[2 41 ]
[2 42 ]
[3 43 ]
[2 0]
[2 0]
[65 0 ]
[66 0 ]
[67 0]
[0 0]]
x_mask的值如下,即有数字的地方均为1(提醒:包括‘eos’所对应的数字0),其他padding 为0,后面两者相乘(即,x_mask * 隐藏层的状态)就可以把padding为0喂给系统的影响消除。
x_mask=
[[1 1]
[1 1]
[1 1]
[1 1]
[1 1]
[1 1]
[1 0]
[1 0]
[1 0]
[1 0]
[1 0]]
第43行:返回x和x_mask。其中,x添加了eos句子结束标识符,x_mask根据最长句子长度进行了padding 0的操作。
继续返回nmt.py脚本中的train()函数吧!
3.1.5 nmt.py脚本中的build_model()函数
Encoder-Decoder的核心部分,代码如下:
def build_model(tparams, options):
opt_ret = dict()
trng = RandomStreams(1234)
use_noise = theano.shared(numpy.float32(0.))
# description string: #words x #samples
x = tensor.matrix('x', dtype='int64')
x_mask = tensor.matrix('x_mask', dtype='float32')
y = tensor.matrix('y', dtype='int64')
y_mask = tensor.matrix('y_mask', dtype='float32')
n_timesteps = x.shape[0]
n_timesteps_trg = y.shape[0]
n_samples = x.shape[1]
# word embedding (source)
emb = tparams['Wemb'][x.flatten()]
emb = emb.reshape([n_timesteps, n_samples, options['dim_word']])
# pass through encoder gru, recurrence here
proj = get_layer(options['encoder'])[1](tparams, emb, options,
prefix='encoder',
mask=x_mask)
# last hidden state of encoder rnn will be used to initialize decoder rnn
ctx = proj[0][-1]
ctx_mean = ctx
# initial decoder state
init_state = get_layer('ff')[1](tparams, ctx_mean, options,
prefix='ff_state', activ='tanh')
# word embedding (target), we will shift the target sequence one time step
# to the right. This is done because of the bi-gram connections in the
# readout and decoder rnn. The first target will be all zeros and we will
# not condition on the last output.
emb = tparams['Wemb_dec'][y.flatten()]
emb = emb.reshape([n_timesteps_trg, n_samples, options['dim_word']])
emb_shifted = tensor.zeros_like(emb)
emb_shifted = tensor.set_subtensor(emb_shifted[1:], emb[:-1])
emb = emb_shifted
# decoder - pass through the decoder gru, recurrence here
proj = get_layer(options['decoder'])[1](tparams, emb, options,
prefix='decoder',
mask=y_mask, context=ctx,
one_step=False,
init_state=init_state)
# hidden states of the decoder gru
proj_h = proj
# we will condition on the last state of the encoder only
ctxs = ctx[None, :, :]
# compute word probabilities
logit_lstm = get_layer('ff')[1](tparams, proj_h, options,
prefix='ff_logit_lstm', activ='linear')
logit_prev = get_layer('ff')[1](tparams, emb, options,
prefix='ff_logit_prev', activ='linear')
logit_ctx = get_layer('ff')[1](tparams, ctxs, options,
prefix='ff_logit_ctx', activ='linear')
logit = tensor.tanh(logit_lstm+logit_prev+logit_ctx)
logit = get_layer('ff')[1](tparams, logit, options, prefix='ff_logit',
activ='linear')
logit_shp = logit.shape
probs = tensor.nnet.softmax(
logit.reshape([logit_shp[0]*logit_shp[1], logit_shp[2]]))
# cost
y_flat = y.flatten()
y_flat_idx = tensor.arange(y_flat.shape[0]) * options['n_words'] + y_flat
cost = -tensor.log(probs.flatten()[y_flat_idx])
cost = cost.reshape([y.shape[0], y.shape[1]])
cost = (cost * y_mask).sum(0)
return trng, use_noise, x, x_mask, y, y_mask, opt_ret, cost代码解析:
提醒,这里dim_word=300,即每个词向量的维度为1*300;dim=500,即GRU单元的数目;n-words=1000,即源字典和目标字典的大小为1000;batch_size=2,即n_sample2=2,每次并行处理2个句子;Wemb的维度为n_word_src*dim_word,即1000*300
第18行:首先,将x通过flatten换成1D的向量,接着通过对Wemb矩阵的索引,将x换成对应的词向量矩阵2D;
第19行:最后,reshape成[step,batch,dim_word]的3D矩阵;
第22行:这里‘encoder’=gru,因此,这里调用了nmt.py脚本的gru_layer()函数,这里返回了proj,是Encoder部分所有隐藏层的状态。不妨移步nmt.py脚本中的gru_layer()函数瞧个究竟。
第27行: ctx和ctx_mean均等于encoder最后一个隐藏层 ht
ctx = proj[0][-1]
ctx_mean = ctx第31行: 初始化decoder的隐藏层状态,即初始化 s0 , s0 的维数为2D, s0 =[batch,dim]
s0=tanh(ctx_mean∗ff_state_W)+ff_state_b
第38行:首先,将y通过flatten换成1D的向量,接着通过对Wemb_dec矩阵的索引,将y换成对应的词向量矩阵2D;
第39行:最后,reshape成[step,batch,dim_word]的3D矩阵;
第41行: emb[:-1]:表示emb矩阵从第0行到倒数第2行。 emb_shifted[1:] :表示emb_shifted矩阵从第一行到最后一行 。即,emb_shifted矩阵第0行的元素全为0,从第一行到最后一行由emb[:-1]元素的值替换。
第42行: 即最终emb矩阵跟原来的emb矩阵发生了如下变化:每一行向下挪动了一行。如,第0行的元素,跑到了第1行…第n-1行的元素跑到了第n行。此外,第0行的元素全部为0。 为什么做如此操作?因为,decoder的时候,第一个timestep喂给隐藏层的输入是全0,然后产生了第一个单词,用第一个单词作为输入,产生第二个单词,直到最终输出‘eos’,整个过程才结束。
第45-49行: 这里‘decoder’=gru_cond_simple,因此,这里调用了gru_cond_simple_layer()函数,这里返回了proj,是decoder部分所有隐藏层的状态。不妨移步nmt.py脚本中gru_cond_simple_layer()函数瞧个究竟。
第51行: proj_h=proj 包括了decoder所有的隐藏层状态。proj_h的维数为3D, proj_h=[n_step,batch,dim]
第54行: 因为ctx是2D向量(batch,dim),需扩展为3D向量,方便后面并行计算。
第57行:
其中, ff_logit_lstm_W=[dim,dim_word] ,是2D向量。
因此, logit_lstm=[n_step,batch,dim] ,是3D向量。
第59行:
其中, emb=[n_step,batch,dim_word] , ff_logit_prev_W=[dim_word,dim_word] 。
因此, logit_prev=[n_step,batch,dim_word] ,是3D向量。
第61行:
其中, txs=[None,batch,dim] , ff_logit_ctx=[dim,dim_word] 。
因此, logit_ctx=[None,batch,dim_word] ,是3D向量。
第63行:
可见,最终产生的目标单词主要由三部分组成。
第一部分, logit_lstm 是decoder的隐藏层的贡献;
第二部分, logit_prev 是 yt−1 ,也就是前一个单词的贡献;
第三部分, logit_ctx 是 encoder的贡献,此时encoder的最后一个隐藏层 ht 包含了encoder所以输入的信息。
第64行:
logit∗ff_logit_W=[n_step,batch,dim_word]∗[dim_word,n_words]=[n_step,batch,n_words]
第66行: logit_shp=[n_step,batch,n_word]
第67行:将目标单词的输出值进行softmax操作,转变为目标单词的输出概率。其中,probs=[n_step*batch,n_word],是2D向量。列向量n_words,表示输出目标字典单词的概率,即每一个tempstep,每一个batch输出一个维数为n_word的向量,对应目标字典每一个单词的概率。
再次啰嗦一下,一个值得思考的关键点: train每一个timestep,每一个batch都输出了一个维数为n_word的1D向量,我们训练的目标应该使得,目标单词在n_word中所对应的位置输出概率最大。如此,测试的时候我们才可以取输出n_word中概率最大的单词作为输出(贪心算法的思想,很容易想象,取每一个时刻输出概率最高的单词组成的句子,不一定得是整个句子输出概率最高的!),当然也可以采用beam search取整个句子输出概率最大的句子(语言模型更好,输出的句子更加流畅通顺)!
第71行: y_flat是大小为n_step*batch的1D向量,代表ground true的目标句子,此时每个单词只是一个数字,对应字典的单词。
第72行: y_flat_idx 每一个目标单词用n_word来表示,即one-hot,也就是每个目标单词占据n_word的大小。
第73行: probs.flatten()[y_flat_idx] 表示每一个目标单词在n_word输出中对应的概率。
取负对数似然作为损失函数。你可以这样简单理解。如果目标单词在n_word输出中对应的概率趋近于1,此时,损失趋近于0;反之,目标单词在n_word输出中对应的概率趋近于0,此时,损失趋近于无穷大。
第74行: cost=[n_step,batch],方便与y_mask进行相乘,此时维度与y_mask一致,y_mask=[n_step,batch]
第75行: cost * y_mask,去掉padding 0 带来的误差影响,sum(0)是把矩阵的所有行累加起来,即把所有的timestep的误差累加起来。此时,cost=[batch],代表每一个输出句子与目标句子的误差。
继续返回nmt.py脚本中的train函数吧!
3.1.6 nmt.py脚本中的gru_layer()函数。
build_model()调用gru_layer()代码如下:
proj = get_layer(options['encoder'])[1](tparams, emb, options, prefix='encoder', mask=x_mask)这里,state_below即为x的emd,维数为[step,batch,dim_word],mask=x_mask,还记得x_mask的目的吗?为了屏蔽掉padding 0带来的误差,因为在每一个step中,padding 的0仍然会喂给Encoder的隐藏层。
gru_layer()是具体实现Encoder的代码。
def gru_layer(tparams, state_below, options, prefix='gru', mask=None,
**kwargs):
nsteps = state_below.shape[0]
if state_below.ndim == 3:
n_samples = state_below.shape[1]
else:
n_samples = 1
dim = tparams[_p(prefix, 'Ux')].shape[1]
if mask is None:
mask = tensor.alloc(1., state_below.shape[0], 1)
# utility function to slice a tensor
def _slice(_x, n, dim):
if _x.ndim == 3:
return _x[:, :, n*dim:(n+1)*dim]
return _x[:, n*dim:(n+1)*dim]
# state_below is the input word embeddings
# input to the gates, concatenated
state_below_ = tensor.dot(state_below, tparams[_p(prefix, 'W')]) + \
tparams[_p(prefix, 'b')]
# input to compute the hidden state proposal
state_belowx = tensor.dot(state_below, tparams[_p(prefix, 'Wx')]) + \
tparams[_p(prefix, 'bx')]
# step function to be used by scan
# arguments | sequences |outputs-info| non-seqs
def _step_slice(m_, x_, xx_, h_, U, Ux):
preact = tensor.dot(h_, U)
preact += x_
# reset and update gates
r = tensor.nnet.sigmoid(_slice(preact, 0, dim))
u = tensor.nnet.sigmoid(_slice(preact, 1, dim))
# compute the hidden state proposal
preactx = tensor.dot(h_, Ux)
preactx = preactx * r
preactx = preactx + xx_
# hidden state proposal
h = tensor.tanh(preactx)
# leaky integrate and obtain next hidden state
h = u * h_ + (1. - u) * h
h = m_[:, None] * h + (1. - m_)[:, None] * h_
return h
# prepare scan arguments
seqs = [mask, state_below_, state_belowx]
init_states = [tensor.alloc(0., n_samples, dim)]
_step = _step_slice
shared_vars = [tparams[_p(prefix, 'U')],
tparams[_p(prefix, 'Ux')]]
rval, updates = theano.scan(_step,
sequences=seqs,
outputs_info=init_states,
non_sequences=shared_vars,
name=_p(prefix, '_layers'),
n_steps=nsteps,
profile=profile,
strict=True)
rval = [rval]
return rval代码解析:
第9行: dim为GRU的单元数目,这里为1000。
第22行: 这句话是输入x到gate门之间的计算。
state_below_: tensor. dot( x , encoder_W)+encoder_b,这句话有点不太好理解,因此我会多费点口舌。 为什么要进行这一步操作呢???
主要是因为,RNN在每一个timestep中,都会计算更新隐藏层。其中,权重W与输入x是提前知道的,所以可以全部提前并行计算,这样大大提高了运行速度。
其中,x的维数是3D,x=[step,batch,dim_word] ; encoder_W的维数是2D.
encoder_W定义在nmt.py脚本param_init_gru()中,如下:
W = numpy.concatenate([norm_weight(nin, dim),
norm_weight(nin, dim)], axis=1)
params[_p(prefix, 'W')] = W
params[_p(prefix, 'b')] = numpy.zeros((2 * dim,)).astype('float32')为了解释上面两句代码,首先解释下numpy.concatenate(),能够一次完成多个数组的拼接。
a=numpy.array([1,2,3],[4,5,6])
b=numpy.array([11,22,33],[44,55,66])
numpy.concatenate((a,b),axis=0)
//axis=0 沿着列方向的轴进行拼接
//因此返回 [[ 1 2 3]
// [ 4 5 6]
// [11 22 33]
// [44 55 66 ]]
np.concatenate((a,b),axis=1)
//axis=1 沿着行方向的轴进行拼接
//因此返回 [[1,2,3,11,22,33]
// [4,5,6,44,55,66]]
按上面的理解,这里encoder_W的维度为(nin,2*dim)=(dim_word,2*dim)。这里,dim_word是word vector的维数,dim是GRU的数目。你一定满心疑惑了,为什么要进行拼接的操作呢??? 先透露一下,拼接是把更新门 ut 的W权重与复位门 rt 的W权重按行方向的轴拼到一起了。其实,最大的目的都是为了速度,并行计算提高运算速度!!!
接着,你可能更疑惑了,3D的向量x,如何跟2D的向量encoder_W进行点乘呢??? 这是theano中广播(broadcast)的机制,对两个形状不同的阵列进行数学计算的处理机制。较小的阵列“广播”到较大阵列相同的形状尺度上,使它们对等以可以进行数学计算。具体广播细节,自行度娘或者Google。
tensor. dot( x , encoder_W)+encoder_b
//(n_step,batch,dim_word)点乘(dim_word,2*dim)=(n_step,batch,2*dim)第25行: 这句话是输入x到GRU的记忆单元 h˜t 。
state_belowx: tensor. dot( x , encoder_Wx)+encoder_bx,同理,state_belowx的维数为(n_step,batch,dim_word)点乘(dim_word,dim)=(n_step,batch,dim)
第59行: 返回值rval,包含了scan迭代的每一步的输出结果,也就是encoder的所有隐藏层的状态。
scan是theano中构建循环Graph的方法。函数原型如下:
theano.scan(fn, sequences=None, outputs_info=None, non_sequences=None, n_steps=None, truncate_gradient=-1, go_backwards=False, mode=None, name=None, profile=False, allow_gc=None, strict=False)fn: 可以是一个lambda表达式或者def函数,每执行一步scan操作,调用一次fn。其中,fn函数的参数为:(sequences,outputs_info,non_sequences);
sequences: scan进行迭代的变量;
outputs_info:它描述了输出的初始状态,和输出具有相同的维度,值得注意的是,没进行一步scan操作,outputs_info的数值会被上一次迭代的输出值更新替换掉;
non_sequences: scan进行迭代的常量,一般为theano的共享变量;
n_step:代表了scan操作的迭代次数,这里代表了该batch_size中,最长句子的单词个数+1(+1是因为每个句子添加了一个结束标志符‘eos’,即数字0);
strict:设置为True,用于检测fn函数用到的所有共享变量是否均包含在non_sequences中,若不满足则会Raise an error。
有一点特别需要强调注意: scan计算过程会将参数sequences中的矩阵按照axis=0(即纵向)进行切片,每次只取一个time_step的序列数据。这一点,从代码第54行和第61行也可以看出来,outputs_info的维度为2D(batch,dim)。
第30行: _step_slice函数,scan每扫一次(也就是每一个timestep,对应RNN喂了一个单词),_step_slice函数执行一次。
为了让大家有个更直观的理解,GRU encoder的公式如下:
参数如下:
m_ : x_mask
x_:state_below_
xx_:state_belowx
h_: ht−1 上一个时刻的隐藏层
U: encoder_U , 注意,这里U=[ Uz:Ur ]
Ux:encoder_Ux
第31、32行:实现了 W(z)xt+U(z)ht−1 和 W(r)xt+U(r)ht−1 的并行操作。此时,preact=[ W(r)xt+U(r)ht−1 : W(z)xt+U(z)ht−1 ]
第35、36行:将preact进行切割, , 注意这里 z就是代码里面的u,也就是更新门的意思。
_slice(preact, 0, dim) 为 [ W(r)xt+U(r)ht−1 ]
_slice(preact, 1, dim) 为 [ W(z)xt+U(z)ht−1 ]
//对应GRU公式二
r = tensor.nnet.sigmoid(_slice(preact, 0, dim))
//对应GRU公式一
u = tensor.nnet.sigmoid(_slice(preact, 1, dim))第39-44行: 对应GRU公式三
第47行:对应GRU公式四
第48行: 这一行特别有意思。目的就是用x_mask屏蔽掉padding 0带来的误差。(因为长度小于maxlen的句子,会进行padding 0的操作,但是,这些paddng 0 在每一个timestep都会喂给Encoder的隐藏层,显然这些误差得消除掉!)
因为,此时m_是1D的向量(batch),h是2D的向量(batch*dim),所以需要进行m_[:,None]扩展为2D的向量。
当m_[:,None]中为0的 时候,也就是timestep到了padding 0的时刻,这时候 ht 应该不能更新,继续保持上一个时刻 ht−1 的状态)。此时式子第一项为0,第二项为 ht−1 。
当m_[:,None]中为1的时候,也就是timestep还没进行到padding 0 的时刻,此时喂给系统仍然是有效的单词(包括‘eos’),此时应该继续更新 ht 。因此,式子第一项为 ht ,第二项为0。
第67、68行: 当进行了n_step次迭代后,也就是所有单词一步步喂给了系统结束后。因为,rval变量包含了每次迭代的输出结果,也就是rval=[rval]即是encoder全部隐藏层的状态,最后将rval变量 return回去。
继续返回nmt.py脚本中的build_model()函数吧!
3.1.7 nmt.py脚本中的gru_cond_simple_layer()函数
build_model()调用gru_cond_simple_layer()代码如下:
proj = get_layer(options['decoder'])[1](tparams, emb, options,
prefix='decoder',
mask=y_mask, context=ctx,
one_step=False,
init_state=init_state)其中,context=ctx是指Encoder最后一个隐藏层 ht 的状态;
init_state=init_state,是指Decoder隐藏层的初始状态 s0 ;
gru_cond_simple_layer()函数是具体实现Decoder的代码。
代码如下:
def gru_cond_simple_layer(tparams, state_below, options, prefix='gru',
mask=None, context=None, one_step=False,
init_state=None,
**kwargs):
assert context, 'Context must be provided'
if one_step:
assert init_state, 'previous state must be provided'
nsteps = state_below.shape[0]
if state_below.ndim == 3:
n_samples = state_below.shape[1]
else:
n_samples = 1
# mask
if mask is None:
mask = tensor.alloc(1., state_below.shape[0], 1)
dim = tparams[_p(prefix, 'Ux')].shape[1]
# initial/previous state
if init_state is None:
init_state = tensor.alloc(0., n_samples, dim)
assert context.ndim == 2, 'Context must be 2-d: #sample x dim'
# projected context to GRU gates
pctx_ = tensor.dot(context, tparams[_p(prefix, 'Wc')])
# projected context to hidden state proposal
pctxx_ = tensor.dot(context, tparams[_p(prefix, 'Wcx')])
def _slice(_x, n, dim):
if _x.ndim == 3:
return _x[:, :, n*dim:(n+1)*dim]
return _x[:, n*dim:(n+1)*dim]
# projected x to gates
state_belowx = tensor.dot(state_below, tparams[_p(prefix, 'Wx')]) + \
tparams[_p(prefix, 'bx')]
# projected x to hidden state proposal
state_below_ = tensor.dot(state_below, tparams[_p(prefix, 'W')]) + \
tparams[_p(prefix, 'b')]
# step function to be used by scan
# arguments | sequences |outputs-info| non-seqs
def _step_slice(m_, x_, xx_, h_, pctx_, pctxx_, U, Ux):
preact = tensor.dot(h_, U)
preact += x_
preact += pctx_
preact = tensor.nnet.sigmoid(preact)
r = _slice(preact, 0, dim)
u = _slice(preact, 1, dim)
preactx = tensor.dot(h_, Ux)
preactx *= r
preactx += xx_
preactx += pctxx_
h = tensor.tanh(preactx)
h = u * h_ + (1. - u) * h
h = m_[:, None] * h + (1. - m_)[:, None] * h_
return h
seqs = [mask, state_below_, state_belowx]
_step = _step_slice
shared_vars = [tparams[_p(prefix, 'U')],
tparams[_p(prefix, 'Ux')]]
if one_step:
rval = _step(*(seqs+[init_state, pctx_, pctxx_]+shared_vars))
else:
rval, updates = theano.scan(_step,
sequences=seqs,
outputs_info=[init_state],
non_sequences=[pctx_,
pctxx_]+shared_vars,
name=_p(prefix, '_layers'),
n_steps=nsteps,
profile=profile,
strict=True)
return rval代码解析:
代码几乎与encoder的部分一模一样。这也难怪,因为seq2seq主要由encoder和decoder两部分组成。而,这份源代码中,encoder和decoder部分均采用GRU实现的。
先贴出公式吧。GRU decoder的公式如下:
这里,Context即为encoder最后一个隐藏层的状态
唯一谈谈跟encoder不同的部分,也就是one_step这个参数。
one_step=False,是指在train的时候,调用scan函数,直接进行n_step次迭代,输出隐藏层的全部状态。
one_step=True,是指在test的时候,不调用scan函数,而是一个timestep改变一次隐藏层,蹦出一个单词。
因此,这部分代码你可以参考上述4个公式和encoder相对应的代码阅读,这里就不再赘述了。
顺便一提,最终 return rval ,rval包含了decoder全部时刻的隐藏层状态。
继续返回nmt.py脚本中的build_model()函数吧!
3.1.8 nmt.py脚本中gen_sample()函数
值得注意的是,
当 stochastic=True的时候,采用的是随机采样选中下一个词;
当stochastic=False的时候,采用的是beam search获得目标句子,其中,k的值为Beam Size的大小(eg, k=5) 。
gen_sample()函数,主要完成测试输出目标句子的功能。
代码如下:
def gen_sample(tparams, f_init, f_next, x, options, trng=None, k=1, maxlen=30,
stochastic=True, argmax=False):
# k is the beam size we have
if k > 1:
assert not stochastic, \
'Beam search does not support stochastic sampling'
sample = []
sample_score = []
if stochastic:
sample_score = 0
live_k = 1
dead_k = 0
hyp_samples = [[]] * live_k
hyp_scores = numpy.zeros(live_k).astype('float32')
hyp_states = []
# get initial state of decoder rnn and encoder context
ret = f_init(x)
next_state, ctx0 = ret[0], ret[1]
next_w = [-1] # indicator for the first target word (bos target)
for ii in xrange(maxlen):
ctx = numpy.tile(ctx0, [live_k, 1])
inps = [next_w, ctx, next_state]
ret = f_next(*inps)
next_p, next_w, next_state = ret[0], ret[1], ret[2]
if stochastic:
if argmax:
nw = next_p[0].argmax()
else:
nw = next_w[0]
sample.append(nw)
sample_score -= numpy.log(next_p[0, nw])
if nw == 0:
break
else:
cand_scores = hyp_scores[:, None] - numpy.log(next_p)
cand_flat = cand_scores.flatten()
ranks_flat = cand_flat.argsort()[:(k-dead_k)]
voc_size = next_p.shape[1]
trans_indices = ranks_flat / voc_size
word_indices = ranks_flat % voc_size
costs = cand_flat[ranks_flat]
new_hyp_samples = []
new_hyp_scores = numpy.zeros(k-dead_k).astype('float32')
new_hyp_states = []
for idx, [ti, wi] in enumerate(zip(trans_indices, word_indices)):
new_hyp_samples.append(hyp_samples[ti]+[wi])
new_hyp_scores[idx] = copy.copy(costs[idx])
new_hyp_states.append(copy.copy(next_state[ti]))
# check the finished samples
new_live_k = 0
hyp_samples = []
hyp_scores = []
hyp_states = []
for idx in xrange(len(new_hyp_samples)):
if new_hyp_samples[idx][-1] == 0:
sample.append(new_hyp_samples[idx])
sample_score.append(new_hyp_scores[idx])
dead_k += 1
else:
new_live_k += 1
hyp_samples.append(new_hyp_samples[idx])
hyp_scores.append(new_hyp_scores[idx])
hyp_states.append(new_hyp_states[idx])
hyp_scores = numpy.array(hyp_scores)
live_k = new_live_k
if new_live_k < 1:
break
if dead_k >= k:
break
next_w = numpy.array([w[-1] for w in hyp_samples])
next_state = numpy.array(hyp_states)
if not stochastic:
# dump every remaining one
if live_k > 0:
for idx in xrange(live_k):
sample.append(hyp_samples[idx])
sample_score.append(hyp_scores[idx])
return sample, sample_score代码解析:
这里,我先从 stochastic=True (即采用的是随机采样选中下一个词) 讲起,稍后再来分析Beam search的过程。
首先介绍一下gen_sample()各个参数的含义。
f_init 和f_next 这两个函数定义在nmt.py脚本的buile_sample()函数中,是具体实现目标单词一个接一个蹦出来的代码。buile_sample()函数特别重要,建议先阅读,有助于理解gen_sample()。移步至去nmt.py脚本中build_sample()函数瞧个究竟吧!
第22行: ret = f_init(x) 调用f_init(x),完成encoder阶段。此时,ret=[init_state, ctx]
第24行: next_w = [-1] ,代表将输出第一个目标单词,也就是emb第一个timestep初始化为全0.
第26行:进行maxlen次timestep迭代,或者知道遇到’eos’,目标句子的生成过程才会结束。
第27行: 这句话在Beam search起作用,当采用随机采样的时候,这里 ctx = numpy.tile(ctx0, [1, 1]),相当于ctx0复制了一次,所以ctx=ctx0。
第29行: ret = f_next(*inps) ,调用f_next(),完成decoder阶段。此时,ret=[next_p, next_w, next_state]
第32-40行: 表示采用随机采样方式生成目标句子的过程。
首先,判断argmax是否等于True,若等于,则根据输出的next_p中挑出概率最大的单词作为下一个单词(贪心算法的思想)。反之,下一个单词的输出则是根据随机采样方式获得,则nw=next_w[0]。把每次timestep输出的目标单词添加保存到sample变量中,同时,将相对应的误差添加到sample_socre变量中。
第41-91行: 采用beam search方式生成目标句子的过程,后面会详细介绍,这里暂时先跳过。
第94行: 将包含目标单词的变量sample,及其所对应的误差变量sample_socre 返回去。
继续返回nmt.py脚本中的train()函数吧!
3.1.9 nmt.py脚本中build_sample()函数
build_sampler函数,主要完成测试阶段,decoder部分,目标单词一个接一个输出的具体实现
代码如下:
def build_sampler(tparams, options, trng, use_noise):
x = tensor.matrix('x', dtype='int64')
n_timesteps = x.shape[0]
n_samples = x.shape[1]
# word embedding (source)
emb = tparams['Wemb'][x.flatten()]
emb = emb.reshape([n_timesteps, n_samples, options['dim_word']])
# encoder
proj = get_layer(options['encoder'])[1](tparams, emb, options,
prefix='encoder')
ctx = proj[0][-1]
ctx_mean = ctx
init_state = get_layer('ff')[1](tparams, ctx_mean, options,
prefix='ff_state', activ='tanh')
print 'Building f_init...',
outs = [init_state, ctx]
f_init = theano.function([x], outs, name='f_init', profile=profile)
print 'Done'
# y: 1 x 1
y = tensor.vector('y_sampler', dtype='int64')
init_state = tensor.matrix('init_state', dtype='float32')
# if it's the first word, emb should be all zero
emb = tensor.switch(y[:, None] < 0,
tensor.alloc(0., 1, tparams['Wemb_dec'].shape[1]),
tparams['Wemb_dec'][y])
# apply one step of gru layer
proj = get_layer(options['decoder'])[1](tparams, emb, options,
prefix='decoder',
mask=None, context=ctx,
one_step=True,
init_state=init_state)
next_state = proj
ctxs = ctx
# compute the output probability dist and sample
logit_lstm = get_layer('ff')[1](tparams, next_state, options,
prefix='ff_logit_lstm', activ='linear')
logit_prev = get_layer('ff')[1](tparams, emb, options,
prefix='ff_logit_prev', activ='linear')
logit_ctx = get_layer('ff')[1](tparams, ctxs, options,
prefix='ff_logit_ctx', activ='linear')
logit = tensor.tanh(logit_lstm+logit_prev+logit_ctx)
logit = get_layer('ff')[1](tparams, logit, options,
prefix='ff_logit', activ='linear')
next_probs = tensor.nnet.softmax(logit)
next_sample = trng.multinomial(pvals=next_probs).argmax(1)
# next word probability
print 'Building f_next..',
inps = [y, ctx, init_state]
outs = [next_probs, next_sample, next_state]
f_next = theano.function(inps, outs, name='f_next', profile=profile)
print 'Done'
return f_init, f_next代码解析:
代码几乎与build_model()相似,build_model()是给训练模型的时候用的,build_sample()是为测试模型服务的。
第11行: 返回encoder阶段隐藏层的状态,proj
第13、14行: 将encoder阶段最后一个隐藏层 ht 作为decoder阶段的Context
第15行: 初始化decoder的隐藏层状态 s0
s0=tanh(ctx∗ff_state_W+ff_state_b)
第20行:f_init函数的定义,theano的内置函数function,输入为[x],输出为outs,其中outs=[init_state, ctx]。其中,ctx为encoder的最后一个隐藏层的状态,作为Context;init_state为初始化decoder的隐藏层状态 s0
第28行: switch函数原型为tensor.switch(Bool条件判断 ,True Operation,False Operation)。
即,若输出的目标单词是 y1 ,则emb初始化为全0;若不是则emb=( yt−1 的word vector)。
第33行: 注意与build_model不一样的地方,在于这里的参数 one_step=True,emb= yt−1 。因此,返回的proj只是一个timestep对应的隐藏层状态。 proj=[dim],是1D的向量
第34-51行:
参考build_model()对应的代码,这里就不再赘述了。其中,next_probs=[n_word],是1D的向量。
第52行: 采用随机采样的方式挑选目标单词
next_sample = trng.multinomial(pvals=next_probs).argmax(1)第58行: f_next函数的定义,theano的内置函数function,输入为[y,ctx,init_state],输出为[next_probs, next_sample,next_state]。
第59行: 最后将定义好计算公式的函数名 f_init,和f_next返回去供调用。 f_init对应encoder,f_next对应decoder。
继续返回nmt.py脚本中的gen_sample()函数吧!
3.2 测试部分test :
至此,train部分的代码已经解释完毕。下面继续分析test部分是如何根据训练好的模型,进行test测试的。还记得提前提醒过大家,test的时候采用的是Beam Search方式生成目标句子。
运行test.sh 脚本(./test.sh)即可以。test.sh代码如下:
export THEANO_FLAGS=device=cpu,floatX=float32
#cd $PBS_O_WORKDIR
python ./translate.py -k 5 -n -p 1 \
$HOME/2016_seq2seq/dl4mt-tutorial-master/session1/models/model_session1.npz \
$HOME/2016_seq2seq/dl4mt-tutorial-master/dataset/train_question_10.tok.pkl \
$HOME/2016_seq2seq/dl4mt-tutorial-master/dataset/train_answer_10.tok.pkl \
$HOME/2016_seq2seq/dl4mt-tutorial-master/dataset/test_question_10.tok\
$HOME/2016_seq2seq/dl4mt-tutorial-master/dataset/predict_test_answer_10.tok代码解析:
第一行: 配置代码运行是采用CPU还是GPU,训练的时候肯定要采用GPU,测试的时候选用CPU就足够了。这里,采用的是CPU。
运行translate.py 函数,同时包括7个输入参数。
1)-k 5:表示Beam search 的窗口大小为5。
2)-p 1:表示启动1个进程,这里运用了多进程的机制,你可以根据资源和测试集合的大小设置多个进程数目。
3)model存放的位置,也就是train阶段训练好的模型。
4)源句子字典的路径
5)目标句子的路径
6)待测试源句子的路径
7)系统根据模型生成目标句子的存放路径
接下来,马不停蹄继续去看translate.py脚本的代码吧!
3.2.1 translate.py 脚本
主要完成test集合的输出。7个初始化的参数分别如下:
1)-k 5:表示Beam search 的窗口大小为5。
2)-p 1:表示启动1个进程,这里运用了多进程的机制,你可以根据资源和测试集合的大小设置多个进程数目。
3)model存放的位置,也就是train阶段训练好的模型。
4)源句子字典的路径
5)目标句子的路径
6)待测试源句子的路径
7)系统根据模型生成目标句子的存放路径
代码如下:
'''
Translates a source file using a translation model.
'''
import argparse
import numpy
import cPickle as pkl
from nmt import (build_sampler, gen_sample_test, load_params,
init_params, init_tparams)
from multiprocessing import Process, Queue
def translate_model(queue, rqueue, pid, model, options, k, normalize):
from theano.sandbox.rng_mrg import MRG_RandomStreams as RandomStreams
from theano import shared
trng = RandomStreams(1234)
use_noise = shared(numpy.float32(0.))
# allocate model parameters
params = init_params(options)
# load model parameters and set theano shared variables
params = load_params(model, params)
tparams = init_tparams(params)
# word index
f_init, f_next = build_sampler(tparams, options, trng, use_noise)
def _translate(seq):
# sample given an input sequence and obtain scores
sample, score = gen_sample(tparams, f_init, f_next,
numpy.array(seq).reshape([len(seq), 1]),
options, trng=trng, k=k, maxlen=200,
stochastic=False)
# normalize scores according to sequence lengths
if normalize:
lengths = numpy.array([len(s) for s in sample])
score = score / lengths
sidx = numpy.argmin(score)
return sample[sidx]
while True:
req = queue.get()
if req is None:
break
idx, x = req[0], req[1]
print pid, '-', idx
seq = _translate(x)
rqueue.put((idx, seq))
return
def main(model, dictionary, dictionary_target, source_file, saveto, k=5,
normalize=False, n_process=5, chr_level=False):
# load model model_options
with open('%s.pkl' % model, 'rb') as f:
options = pkl.load(f)
# load source dictionary and invert
with open(dictionary, 'rb') as f:
word_dict = pkl.load(f)
word_idict = dict()
for kk, vv in word_dict.iteritems():
word_idict[vv] = kk
word_idict[0] = ''
word_idict[1] = 'UNK'
# load target dictionary and invert
with open(dictionary_target, 'rb') as f:
word_dict_trg = pkl.load(f)
word_idict_trg = dict()
for kk, vv in word_dict_trg.iteritems():
word_idict_trg[vv] = kk
word_idict_trg[0] = ''
word_idict_trg[1] = 'UNK'
# create input and output queues for processes
queue = Queue()
rqueue = Queue()
processes = [None] * n_process
for midx in xrange(n_process):
processes[midx] = Process(
target=translate_model,
args=(queue, rqueue, midx, model, options, k, normalize,))
processes[midx].start()
# utility function
def _seqs2words(caps):
capsw = []
for cc in caps:
ww = []
for w in cc:
if w == 0:
break
ww.append(word_idict_trg[w])
capsw.append(' '.join(ww))
return capsw
def _send_jobs(fname):
with open(fname, 'r') as f:
for idx, line in enumerate(f):
if chr_level:
words = list(line.decode('utf-8').strip())
else:
words = line.strip().split()
x = map(lambda w: word_dict[w] if w in word_dict else 1, words)
x = map(lambda ii: ii if ii < options['n_words'] else 1, x)
x += [0]
queue.put((idx, x))
return idx+1
def _finish_processes():
for midx in xrange(n_process):
queue.put(None)
def _retrieve_jobs(n_samples):
trans = [None] * n_samples
for idx in xrange(n_samples):
resp = rqueue.get()
trans[resp[0]] = resp[1]
if numpy.mod(idx, 10) == 0:
print 'Sample ', (idx+1), '/', n_samples, ' Done'
return trans
print 'Translating ', source_file, '...'
n_samples = _send_jobs(source_file)
trans = _seqs2words(_retrieve_jobs(n_samples))
_finish_processes()
with open(saveto, 'w') as f:
print >>f, '\n'.join(trans)
print 'Done'
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument('-k', type=int, default=5)
parser.add_argument('-p', type=int, default=5)
parser.add_argument('-n', action="store_true", default=False)
parser.add_argument('-c', action="store_true", default=False)
parser.add_argument('model', type=str)
parser.add_argument('dictionary', type=str)
parser.add_argument('dictionary_target', type=str)
parser.add_argument('source', type=str)
parser.add_argument('saveto', type=str)
args = parser.parse_args()
main(args.model, args.dictionary, args.dictionary_target, args.source,
args.saveto, k=args.k, normalize=args.n, n_process=args.p,
chr_level=args.c)
代码解析:
第89行-93行:
queue: 源句子的队列
rqueue: 翻译后的目标句子的队列
调用multiprocessing.Process函数(),支持多进程操作,可以大大体高运行速度。
target:调用的函数对象,即translate_model()函数;
args:为target调用的参数元祖
因此,translate_model()才是真正test的核心!!! 去瞧个究竟吧!!!
第46行: 只要queue(源句子的队列)有内容,便一直循环。
第47、51行: req = queue.get(), 每次弹出一个源句子,即x=req[1]。
第53行: seq = _translate(x),调用_translate(x)函数,最终返回seq,即翻译后的目标句子。
_translate()函数主要调用了nmt.py脚本中的gen_sample()函数。这里,stochastic=False,k=5,表示采用beam search方式生成目标句子。
最终gen_sample()函数返回2个变量sample, sample_score。其中,sample保存k个候选句子。sample_score保存k个句子对应的概率(经过log运算操作过的概率,概率越小,目标句子生成效果越好)。
_translate()根据返回来的sample,sample_score,选取平均概率最小的句子返回去(最终生成的目标句子)。
因此,请移步到nmt.py脚本中的gen_sample函数,瞧一瞧beam search的具体实现!
第134行:调用_send_jobs()函数,把源句子单词转换成数字,并存储在queue队列中。最终返回源句子的数目。 即n_samples=源句子的数目。
第135行: 首先调用_retrieve_jobs(),每进行10个Sample(源句子的样本)的翻译,则打印一次,最终返回数字目标句子的列表对象,最终翻译好的句子保存在rqueue队列中。。其次,调用_seqs2words(),把数字目标句子转化成单词目标句子,并返回单词目标句子的列表对象。
第138行: 存储单词目标句子到相对应的路径下。
3.2.2 nmt.py脚本中的gen_sample()函数
具体实现beam search操作的代码。
train和test都调用了gen_sample()函数,为什么呢?
train的时候采用了随机采样的方式。因为stochastic默认为True,即是用随机采样的方式选择Decoder的下一个单词,当然你也可以手动设置stochastic=False 和k的值,选用beam search)
test的时候采用了beam search的方式。
之所以Train的时候要调用gen_sample()函数,目的是为了让你看一下从Train集挑5个case,Decoder后的效果如何(主要是为了看看训的效果大体如何),这一步其实是多余的,因为从valid集看cost,才是最终确定best model参数的关键,因为valid集在train的时候是不可见的,valid集的cost低,才能保证test的效果好。
def gen_sample(tparams, f_init, f_next, x, options, trng=None, k=1, maxlen=30,
stochastic=True, argmax=False):
# k is the beam size we have
if k > 1:
assert not stochastic, \
'Beam search does not support stochastic sampling'
sample = []
sample_score = []
if stochastic:
sample_score = 0
live_k = 1
dead_k = 0
hyp_samples = [[]] * live_k
hyp_scores = numpy.zeros(live_k).astype('float32')
hyp_states = []
# get initial state of decoder rnn and encoder context
ret = f_init(x)
next_state, ctx0 = ret[0], ret[1]
next_w = [-1] # indicator for the first target word (bos target)
for ii in xrange(maxlen):
ctx = numpy.tile(ctx0, [live_k, 1])
inps = [next_w, ctx, next_state]
ret = f_next(*inps)
next_p, next_w, next_state = ret[0], ret[1], ret[2]
if stochastic:
if argmax:
nw = next_p[0].argmax()
else:
nw = next_w[0]
sample.append(nw)
sample_score -= numpy.log(next_p[0, nw])
if nw == 0:
break
else:
cand_scores = hyp_scores[:, None] - numpy.log(next_p)
cand_flat = cand_scores.flatten()
ranks_flat = cand_flat.argsort()[:(k-dead_k)]
voc_size = next_p.shape[1]
trans_indices = ranks_flat / voc_size
word_indices = ranks_flat % voc_size
costs = cand_flat[ranks_flat]
new_hyp_samples = []
new_hyp_scores = numpy.zeros(k-dead_k).astype('float32')
new_hyp_states = []
for idx, [ti, wi] in enumerate(zip(trans_indices, word_indices)):
new_hyp_samples.append(hyp_samples[ti]+[wi])
new_hyp_scores[idx] = copy.copy(costs[idx])
new_hyp_states.append(copy.copy(next_state[ti]))
# check the finished samples
new_live_k = 0
hyp_samples = []
hyp_scores = []
hyp_states = []
for idx in xrange(len(new_hyp_samples)):
if new_hyp_samples[idx][-1] == 0:
sample.append(new_hyp_samples[idx])
sample_score.append(new_hyp_scores[idx])
dead_k += 1
else:
new_live_k += 1
hyp_samples.append(new_hyp_samples[idx])
hyp_scores.append(new_hyp_scores[idx])
hyp_states.append(new_hyp_states[idx])
hyp_scores = numpy.array(hyp_scores)
live_k = new_live_k
if new_live_k < 1:
break
if dead_k >= k:
break
next_w = numpy.array([w[-1] for w in hyp_samples])
next_state = numpy.array(hyp_states)
if not stochastic:
# dump every remaining one
if live_k > 0:
for idx in xrange(live_k):
sample.append(hyp_samples[idx])
sample_score.append(hyp_scores[idx])
return sample, sample_score
代码解析:
其中,f_init()和f_next()的具体操作定义在build_sample()函数中。
第22行: 调用f_init(x),完成源句子encoder的过程,返回[decoder的 s0 ,Context]
第24行: next_w=[-1],代表emb初始化为全0,表示即将输出目标句子的第一个单词。
第26行: 迭代maxlen次操作,或者直到句子翻译结束。
第41行: 具体beam search的过程,这里k=5
第42行: 调用f_next,返回 |V|个词的概率(为了简单测试,我取|v|=1000),然后取log运算,,作为得分。概率越接近1,得分越趋近于0;反之,概率越趋近于0,得分趋于无穷大。
其中,cand_scores的维度大小随输出next_w个数变化。当输入为1个单词的时候,cand_scores是1D的向量,为|V|;当输入为n时,也就是并行输入n个单词,cand_scores=[n , n_word],这里n_word就是 |V|target
第44行: 每次是取Top (k-dead_k)概率值最低的索引(因为对概率值做了log运算,越接近1,值越小),argsort()返回的是索引,不是具体的概率值。有一点值得注意的是,并不是每次都取Top k个
第47行: trans_indices = ranks_flat / voc_size 表示上一个单词的索引。
第48行: word_indices = ranks_flat % voc_size 表示 |V|target 的索引。
第49行: 根据argsort()返回的是索引,找到对应的概率值(做了log运算处理)
第55-58行: new_hyp_samples保存所有的目标句子(包括翻译完成(句子结尾是0)和还未完成的句子)。
hyp_samples:保留那些还仍未完成的目标句子,即仍然是激活状态,需要继续驱动产生下一个单词的句子。
new_hyp_samples.append(hyp_samples[ti]+[wi])这句代码便是根据索引 trans_indices找到上一个单词,根据word_indices从|V个目标字典找到具体的单词,然后添加到 new_hyp_samples中。
第66-71行:
遍历new_hyp_samples:
如果new_hyp_samples中发现有结束的句子,也就是句末出现0,那么就把该句子添加到sample中。因此,sample变量是保存那些已经翻译完毕的目标句子。同时,dead_k=dead_k+1,当dead_k>=k,表示所有的句子均翻译完毕了。
反之,如果new_hyp_samples中句子没有结束,则进行如下操作:
1)new_live_k = new_live_k + 1,new_live_k表示处于激活状态的句子数目。如果new_like_k<1,表示翻译结束了。
2)将仍为翻译完毕的目标句子添加到hyp_samples中,继续操作。
第84行: 挑选所有未完成句子(hyp_samples)的最后一个词,最为下一次输入,即next_p。即第一次next_p是输入一个单词,第二次开始,next_p并行输入len(hyp_samples)个单词。
第94行: 最终迭代结束,sample里面的元素就是我们要的候选句子,sample_score便是对应候选句子经过log运算处理的概率。整个句子概率越低,表示翻译质量越好。
下图展示了迭代的过程。
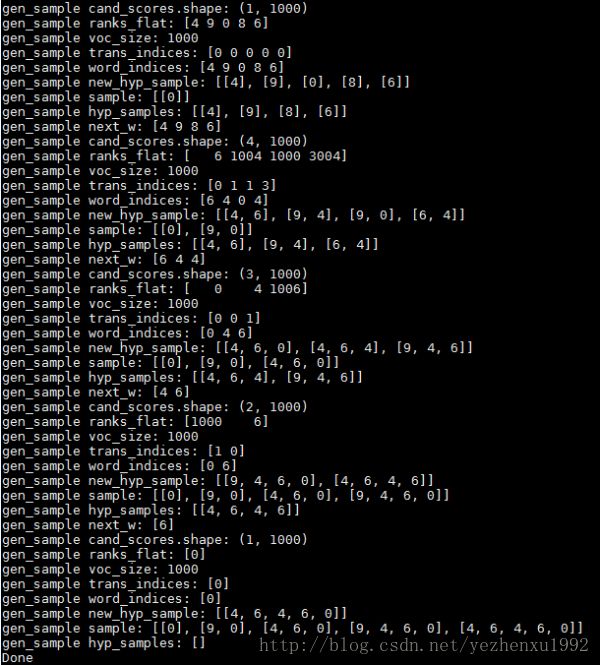
继续返回translate.py脚本吧!