一图看懂Policy Gradients深度强化学习算法
Policy Gradients 深度强化学习算法实现流程详解
- 前言
- 一、PG深度强化学习算法的产生动机?
- 二、算法原理
- 三、算法实现流程
- 四、与Q系列算法相比的优劣
- 五、总结
前言
基于Policy Gradients(策略梯度法,后文简称PG)的深度强化学习方法,思想上与基于Q-learning的系列算法有本质的不同,下面本博客争取用简洁的语言,清晰的图表对PG深度强化学习算法进行阐述,帮助初学者更好地理解算法。
一、PG深度强化学习算法的产生动机?
想要了解PG深度强化学习算法为什么会产生,需要知道在这之前诞生的Q-learning及其系列算法(如:DQN[参考这里],Double DQN等),Q系列算法在每一步做出行动(action)之后,都要计算收益(reward),而且一般需要计算两次,一次是估计收益,一次是现实收益,两者之间的差距(gap)被视为深度神经网络的loss值,从而用于更新神经网络的参数 θ \theta θ。
而现实生活中,很多决策的行动空间是高维甚至连续(无限)的,比如自动驾驶中,汽车下一个决策中方向盘的行动空间,就是一个从[-900°,900°](假设方向盘是两圈半打满)的无限空间中选一个值,如果我们用Q系列算法来进行学习,则需要对每一个行动都计算一次reward,那么对无限行动空间而言,哪怕是把行动空间离散化,针对每个离散行动计算一次reward的计算成本也是当前算力所吃不消的。这是对Q系列算法提出的第一个挑战:无法遍历行动空间中所有行动的reward值。
此外,现实中的决策往往是带有多阶段属性的,说白了就是:“不到最后时刻不知输赢”。以即时策略游戏(如:星际争霸,或者国内流行的王者荣耀)为例,玩家的输赢只有在最后游戏结束时才能知晓,谁也没法在游戏进行过程中笃定哪一方一定能够赢。甚至有可能发生:某个玩家的每一步行动看起来都很傻,但是最后却能够赢得比赛,比如,Dota游戏中,有的玩家虽然死了很多次,己方的塔被拆了也不管,但是却靠着偷塔取胜(虽然这种行为可能是不受欢迎的)。诸如此类的情形就对Q系列算法提出了第二个挑战,Agent每执行一个动作(action)之后的奖励(reward)难以确定,这就导致Q值无法更新。
那么,难道深度强化学习就不能处理诸如上述两类情形的问题了吗?答案当然是否定的,这就衍生出了基于PG的系列深度强化学习算法[1]。下面我将就最原始,最简单的PG深度强化学习算法进行介绍,了解之后就可以进阶更高级的算法了。
二、算法原理
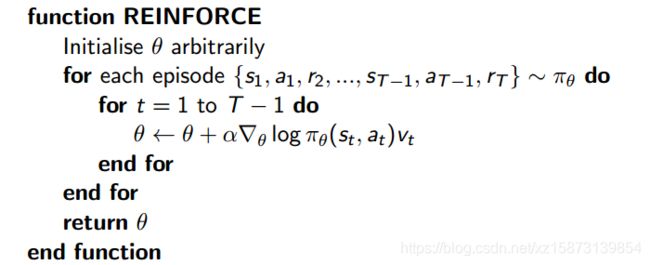
上图所示的就是最简单的PG强化学习算法原理了,最关键的部分其实就是神经网络更新梯度: α ∇ θ log π θ ( s t , a t ) v t \alpha {\nabla _\theta }\log {\pi _\theta }\left( {{s_t},{a_t}} \right){v_t} α∇θlogπθ(st,at)vt,该块又分为两个部分:
(a) α \alpha α: 这个很简单,就是学习率,决定神经网络更新的幅度;
(b) ∇ θ log π θ ( s t , a t ) v t {\nabla _\theta }\log {\pi _\theta }\left( {{s_t},{a_t}} \right){v_t} ∇θlogπθ(st,at)vt,这个是策略在 θ \theta θ上的梯度,又可以细分为两个部分:
- log π θ ( s t , a t ) \log {\pi _\theta }\left( {{s_t},{a_t}} \right) logπθ(st,at):在状态 s t {s_t} st下选择行动 a t {a_t} at的概率的Log值
- v t {v_t} vt: 在状态 s t {s_t} st下选择行动 a t {a_t} at所获得的reward(并不是实时的reward,而是一局游戏结束后,最后的reward对之前所有行动进行reward再分配)。
∇ θ log π θ ( s t , a t ) v t {\nabla _\theta }\log {\pi _\theta }\left( {{s_t},{a_t}} \right){v_t} ∇θlogπθ(st,at)vt并不是随意提出的,而是有着严格的数学推导,关于这部分的内容,就去读书吧[2],本博客内容主要是弄清楚算法实现流程,关于原理的部分,暂不细刨了(其实怕自己也说不清楚)。
三、算法实现流程
有图不写字,直接上图吧。
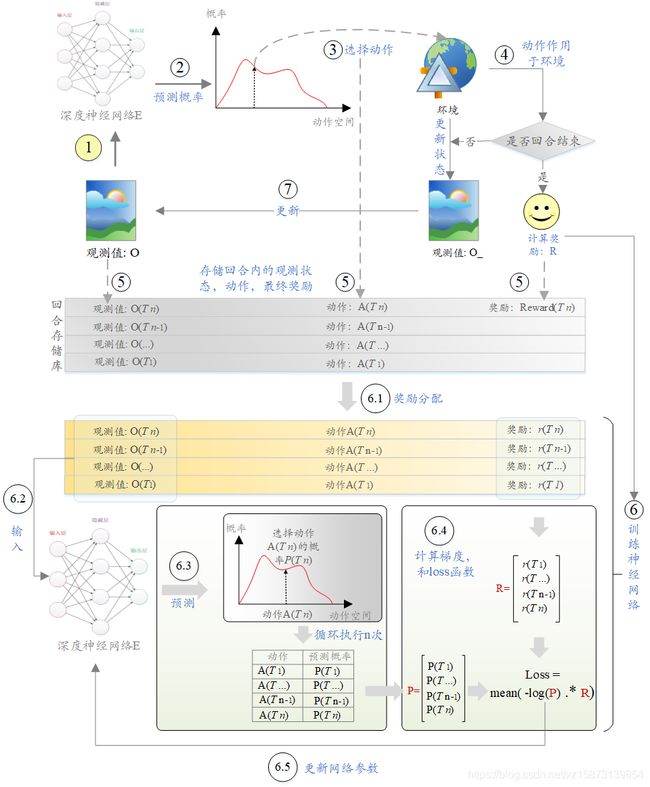
注意,神经网络设计过程中,最后一层,一般采用Softmax函数或者高斯函数激活,前者用于离散动作,后者用于连续动作。
关于奖励分配,直接上代码吧:
def _discount_and_norm_rewards(self):
##该函数将最后的奖励,依次分配给前面的回合,越往前,分配的越少。除此之外,还将分配后的奖励归一化为符合正太分布的形式。
discounted_ep_rs = np.zeros_like(self.ep_rs) #self.ep_rs就是一局中每一回合的奖励,一般前面回合都是0,只有最后一个回合有奖励(一局结束)
running_add = 0
for t in reversed(range(0, len(self.ep_rs))):
running_add = running_add * self.gamma + self.ep_rs[t] #self.gamma,是衰减系数,该系数越大,前面回合分配到的奖励越少(都衰减了嘛)
discounted_ep_rs[t] = running_add
discounted_ep_rs = discounted_ep_rs - np.mean(discounted_ep_rs)
discounted_ep_rs = discounted_ep_rs / np.std(discounted_ep_rs)
return discounted_ep_rs
四、与Q系列算法相比的优劣
PG深度强化学习算法与Q系列算法相比,优势主要有[2]:
- 可以处理连续动作空间或者高维离散动作空间的问题。
- 容易收敛,在学习过程中,策略梯度法每次更新策略函数时,参数只发生细微的变化,但参数的变化是朝着正确的方向进行迭代,使得算法有更好的收敛性。而价值函数在学习的后期,参数会围绕着最优值附近持续小幅度地波动,导致算法难以收敛。
缺点主要有:
- 容易收敛到局部最优解,而非全局最优解;
- 策略学习效率低;
- 方差较高:这个可谓是普通PG深度强化学习算法最不可忍受的缺点了,由于PG算法参数更新幅度较小,导致神经网络有很大的随机性,在探索过程中会产生较多的无效尝试。另外,在处理回合结束才奖励的问题时,会出现不一致的问题:回合开始时,同样的状态下,采取同样的动作,但是由于后期采取动作不同,导致奖励值不同,从而导致神经网络参数来回变化,最终导致Loss函数的方差较大。
五、总结
总的来说,普通的PG算法,只能用于解决一些小的问题,比如经典的让杆子竖起来,让小车爬上山等。如果想应用到更复杂的问题上,比如玩星际争霸,就需要更复杂的一些方法,比如后期出现的Actor Critic,Asynchronous Advantage Actor-Critic (A3C)等等,后面,我将在学习的过程中不断总结这些先进算法的思路。
[1] Policy gradient methods for reinforcement learning with function approximation. https://arxiv.org/pdf/1706.06643.pdf
[2] 陈仲铭,何明,深度强化学习原理与实践,pp.161-165.