了解实现一个高并发的内存池——TLS Memmory Pool
为什么需要内存池?
1.效率问题:如果我们直接向系统申请内存,当我们需要频繁的申请释放内存时,就需要频繁的与系统层产生交互,多次切换用户态和内核态,而用户态和内核态之间的切换的消耗是非常大的,因此申请内存的消耗就会很大,程序效率也就随之降低了。
2.内存碎片问题:如果我们频繁的申请和释放小块的内存,系统的内存就会因此被碎片化,虽然总的内存被占用并不多,但是却没有了连续的大块内存,这个时候如果我们需要使用大内存的空间时,就无法申请了。
实现一个高并发的内存
现在大部分的开发环境都是多核多线程,在申请内存的场景下,必然存在激烈的锁竞争问题。要实现一个高并发的内存池,必须要考虑以下几个问题:
- 内存碎片问题
- 性能问题
- 多线程场景下,锁竞争问题
高并发内存池设计
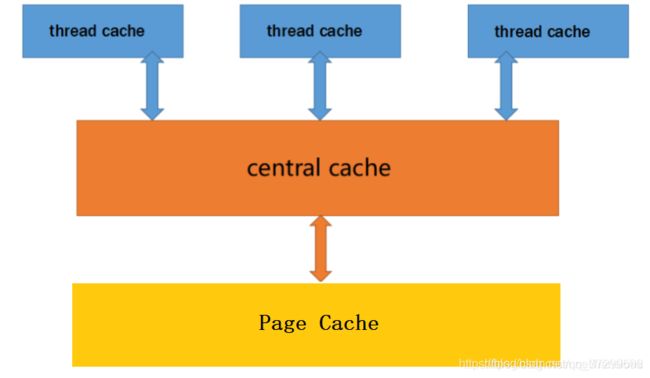
主要由三部分组成:
- thread cache:
线程缓存,是每一个线程独有的,用于小于64k的内存的分配,线程从这里申请内存不需要加锁,每个线程独享一个cache,这也就是这个并发高效的地方 - Central cache:
中心缓存是所有线程所共享,thread cache是按需要从Central cache中获取的对象。 Central cache周期性的回收thread cache中的对象,避免一个线程占用了太多的内存,而其他线程的内存吃紧。达到内存分配在多个线程中更均衡的按需调度的目的。Central cache是存在竞争的,所以从这里取内存对象是需要加锁 - Page cache:
页缓存是在Central cache缓存上面的一层缓存,存储的内存是以页为单位存储及分配 的,Central cache没有内存对象(Span)时,从Page cache分配出一定数量的page,并切割成定长大小的小块内存,分配给Central cache。Page cache会回收Central cache满足条件的Span(使用计数为0)对象,并且合并相邻的页,组成更大的页,缓解内存碎片的问题。
**怎么实现每个线程都拥有自己唯一的线程缓存?**⭐⭐⭐
为了避免加锁带来的效率,在Thread Cache中使用thread local storageTLS保存每个线程本地的ThreadCache的指针,这样Thread Cache在申请释放内存时是不需要锁的,因为每一个线程都拥有了自己唯一的全局变量。
第一层:ThreadCache类
class ThreadCache
{
public:
void* Allocate(size_t size);//分配内存
void Deallocate(void* ptr, size_t size);//释放内存
//从中心缓存中获取内存对象
void* FetchFromCentralCache(size_t index, size_t size);
//当自由链表中的对象超过一次分配给threadcache的数量,则开始回收
void ListTooLong(FreeList* freelist, size_t byte);
private:
FreeList _freelist[NLISTS];// 创建了一个自由链表数组
};
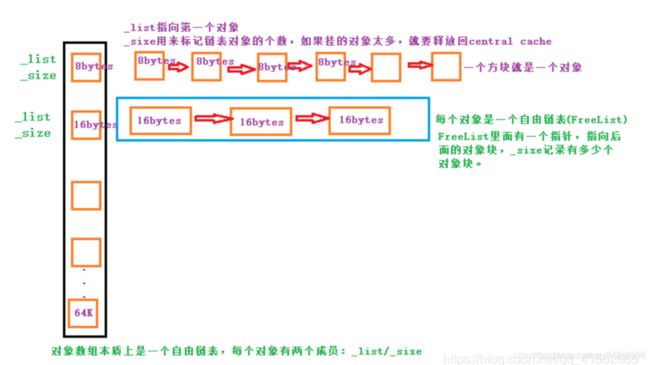 从ThreadCache申请内存:
从ThreadCache申请内存:
当内存申请size<=64时2在ThreadCache中申请,计算size在自由链表中的位置,如果自由链表中有内存对象直接从FreeList[i]中pop一下对象,时间复杂度时O(1),且没有锁竞争;当Freelist[i]中没有对象时则批量从CentralCache中获取一定数量的对象,插入到自由链表并返回一个对象(剩余的n-1个对象插入到自由链表并返回一 个对象)
向ThreadCache释放内存:
当释放内存小于64k时将内存释放回Thread Cache, 计算size在自由链表中的位置,将对象Push到FreeList[i]; 当链表的长度过长, 也就是超过一次最大限制数目时则回收一部分内存对象到Central Cache。
第二层:Central Cache(中心缓存
中心缓存要实现为单例模式,保证全局只有一份实例
- .central cache是内存池中的第二层缓存, 这一层缓存主要解决的问题就是内存分配不均的问题。
在设计thread cache时,我们利用TLS让每一个线程都独享了thread cache, 但是这样虽然解决另外内存碎片的问题??? 也导致了另一个问题,那就是内存资源分配不均衡的问题。当一个线程大量的开辟内存再释放的时候,这个线程中的thread cache势必会储存着大量的空闲内存资源,而这些资源是无法被其他线程所使用的,当其他的线程需要使用内存资源时,就可能没有更多的内存资源可以使用,这也就导致了其它线程的饥饿问题。为了解决这个问题,就有了central cache的设计。 - central cache的主要功能:周期性的回收thread cache中的内存资源,避免一个或多个线程占用大量内存资源,而其它线程内存资源不足的问题。让内存资源的分配在多个线程中更均衡。
- Central Cache是线程共享的,就是存在竞争的,所以在在这里取内存对象的时候是需要加锁的,但是锁的力度可以控制得很小。为了保证全局只有唯一的Central Cache,这个类被可以设计成了单例模式
单例模式采用饿汉模式,避免高并发下资源的竞争 - Central Cache起着承上启下的作用:对下,它既可以将内存对象分配给Thread Cache来的每个线程,又可以将线程归还回来的内存进行管理。 对上 它要把自身已经满了的内存块上交给页缓存 当自己有需要的时候,得向页缓存申请
- .Central Cache本质是由一个哈希映射的Span对象自由双向链表构成。一个span对象大小是恒定的4K大小,一个span是由多个页组成的(32位下4K 64位下8K ) 但是中心缓存数组每个元素指定了单个span划分成内存块的大小 (比如第一个8bytes 第二个16bytes等等),故他们能挂载的内存块数不一样
简言之:当thread cache中没有内存时,就会批量向Central cache申请一定数量的内存对象,Central cache也是一个哈希映射的Spanlist,Spanlist中挂着span,从span中取出对象给thread cache。比如线程申请一个16bytes的内存,但是此时thread cache 中16bytes往上的都没了 ,这个时候向cantral申请,central cache就到16bytes的地方拿下一个span 给thread cache
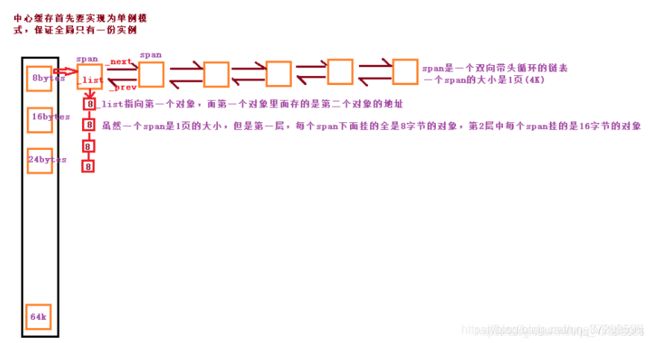
但是,当向Central Cache中申请发现16bytes往后的span节点全空了时,则将空的span链在一起,然后向Page Cache申请若干以页为单位的span对象,比如一个3页的span对象,然后把这个3页的span对象切成3个一页的span对象,放在central cache中16bytes位置, 再将这三个一页的span对象切成需要的内存块大小,这里就是16bytes,并链接起来,挂到span中 - 向central cache中释放内存:
当Thread Cache过长或者线程销毁,则会将内存释放回Central Cache中,比如Thread cache中16bytes部分链表数目已经超出最大限制了,则会把后面再多出来的内存块放到central cache的16bytes部分的他所归属的那个span对象上,此时那个span对象的usecount就减一位。当_usecount减到0时则表示所有对象都回到了span,则将Span释放回Page Cache,Page Cache中会对前后相邻的空闲页进行合并。

注意:由span对象划分出去的内存块和这个span对象是有归属关系的,所以由thread cache归还释放某个内存(比如16bytes)应该归还到central cache的16bytes部分的他所归属的那个span对象上
那么, 怎么才能将Thread Cache中的内存对象还给它原来的span呢?
答:可以在Page Cache中维护一个页号到span的映射。当Page Cache给Central Cache分配一个span时,将这个映射更新到unordered_map中去,这样的话在central cache中的span对象下的内存块都是属于某个页的 也就有他的页号,,同一个span切出来的内存块PageID都和span的PageID相同,这样就能很好的找出某个内存块属于哪一个span了。
//设计成单例模式
class CentralCache
{
public:
static CentralCache* Getinstence()
{
return &_inst;
}
//从page cache获取一个span
Span* GetOneSpan(SpanList& spanlist, size_t byte_size);
//从中心缓存获取一定数量的对象给threa cache
size_t FetchRangeObj(void*& start, void*& end, size_t n, size_t byte_size);
//将一定数量的对象释放给span跨度
void ReleaseListToSpans(void* start, size_t size);
private:
SpanList _spanlist[NLISTS];
private:
CentralCache(){}//声明不实现,防止默认构造,自己创建
CentralCache(CentralCache&) = delete;
static CentralCache _inst;
};
第三层:Page Cache 页缓存
Page cache是一个以页为单位的span自由链表;为了保证全局只有唯一的Page cache,这个类可以被设计成了单例模式,本单例模式采用饿汉模式
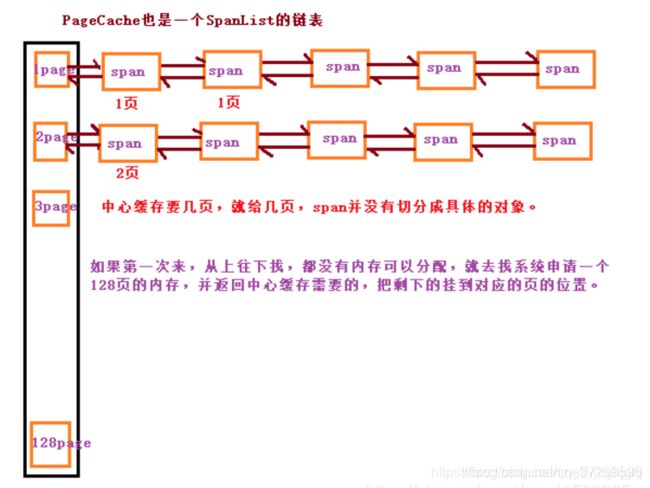
- page cache的主要功能就是回收central cache中空闲的span,并且对空闲的span进行合并,合并成更大的span,当需要更大内存时,就不需要担心因为内存被切小而无法使用大内存的情况了,缓解了内存碎片的问题。而当central cache中没有可用的span对象时,page cache也会将大的内存切成需要大小的内存对象分配给central cache。
page cache中的内存是以页为单位储存和分配的。 - 存储的是以页为单位存储及分配的(中心缓存数组每个元素表示链表中span的页数),中心缓存没有span时(所有的span链表都空了),从页缓存分配出一定数量的页,并切割成定长大小的小块内存(在中心缓存中对应的字节数 ),分配给Central Cache。Page Cache会回收Central Cache满足条件的Span(使用计数为0,即span结点满足一页)对象,并且合并相邻的页(根据页ID相邻),组成更大的页,缓解内存碎片的问题。
- 当thread cache向Central Cache中申请,发现Central Cache16bytes往后的span结点全空了时,则将空的span链在一起,然后向Page Cache申请若干以页为单位的span对象,比如一个3页的span对象:Page Cache先检查3页的那个位置有没有span,如果没有则向更大页寻找一个span,如果找到则分裂成两个。比如:申请的是3page,3page后面没有挂span,则向后面寻找更大的span,假设在10page位置找到一个span,则将10page span分裂为一个3page span和一个7page span。如果找到128 page都没有合适的span,则向系统使用mmap、brk或者是VirtualAlloc等方式申请128page span挂在自由链表中,再重复2中的过程,然后把这个3页的span对象切成3个一页的span对象 放在central cache中的16bytes位置可以有三个结点,再把这三个一页的span对象切成需要的内存块大小 这里就是16bytes ,并链接起来,挂到span中
- 向page cache中释放内存
当Thread Cache过长或者线程销毁,则会将内存释放回Central Cache中的,
比如Thread cache中16bytes部分链表数目已经超出最大限制了 则会把后面再多出来的内存块放到central cache的16bytes部分的他所归属的那个span对象上.
此时那个span对象的usecount就减一位
当_usecount减到0时则表示所有对象都回到了span,则将Span释放回Page Cache,Page Cache中会依次寻找span的前后相邻pageid的span,看是否可以合并,如果合并继续向前寻找。这样就可以将切小的内存合并收缩成大的span,减少内存碎片。 - page cache中最重要的就是合并,在span结构中,有_pageid(页号)和_pagequantity(页的数量)两个成员变量,通过这两个成员变量,同时再利用unordered_map建立每一个页号到对应span的映射,就可以通过页号找到对应span进行合并了。
- 那么页号又是如何来的,当我们通过VirtualAlloc(Windows环境下是VirtualAlloc,Linux下使用brk或者mmap)直接向系统申请内存时,都是以页为单位,而在32位机器下,一页就是4k,所以从0开始每一页的起始地址都是4k的整数倍,那么只需要将申请到的内存地址左移12位就可以得到相应的页号了,而通过页号也可以计算每一页的起始地址,只需要将地址右移12位即可。???
class PageCache
{
public:
static PageCache* GetInstence()
{
return &_inst;
}
Span* AllocBigPageObj(size_t size);
void FreeBigPageObj(void* ptr, Span* span);
Span* _NewSpan(size_t n);
Span* NewSpan(size_t n);//获取的是以页为单位
//获取从对象到span的映射
Span* MapObjectToSpan(void* obj);
//释放空间span回到PageCache,并合并相邻的span
void ReleaseSpanToPageCache(Span* span);
private:
SpanList _spanlist[NPAGES];
//std::map _idspanmap;
std::unordered_map<PageID, Span*> _idspanmap;
std::mutex _mutex;
private:
PageCache(){}
PageCache(const PageCache&) = delete;
static PageCache _inst;
};
实现后补github地址==最近要开始复习巩固知识点了⛽