Python网络爬虫(六)关键词搜索百度图片并保存到本地
目录
- 一、解析百度图片搜索返回机制
- 1. 关键词搜索
- 2. 图片url解析
- 3. 错误机制
- 二、运行结果及源码
一、解析百度图片搜索返回机制
1. 关键词搜索
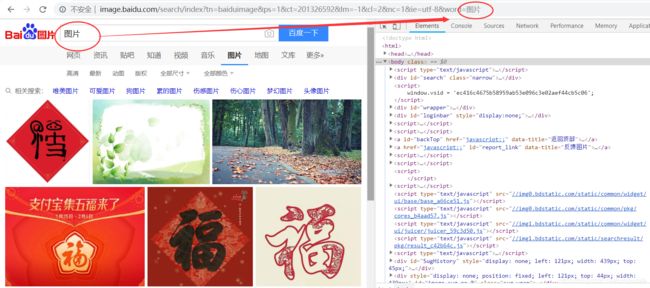
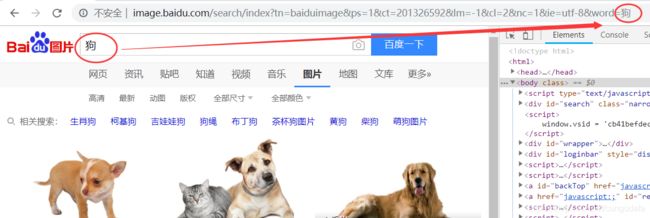
1 我们通过request关键词搜索
-
两次关键词
图片和狗搜索百度图片,在url中都有返回关键词http://image.baidu.com/search/index?tn=baiduimage&ps=1&ct=201326592&lm=-1&cl=2&nc=1&ie=utf-8&word=%E7%8B%97 -
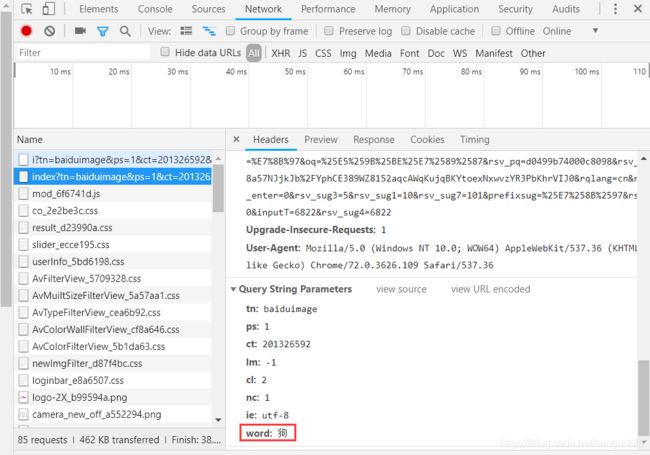
F12查看Network,也证实了关键字返回

2. 图片url解析
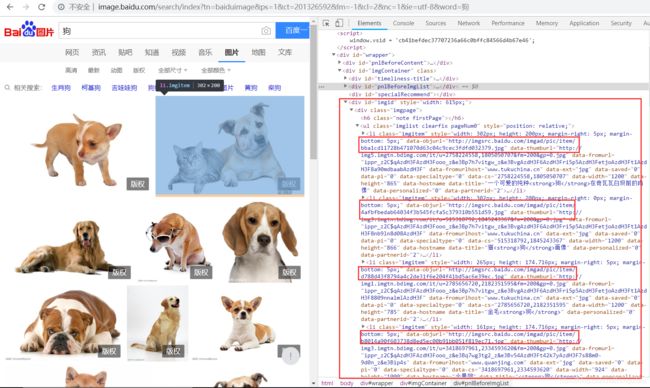
2 解析每张图片地址,并保存(比较简单,也是最关键的)
F12查看Element,找到图片url- 由图中可见所有图片在:
'data-objurl='后
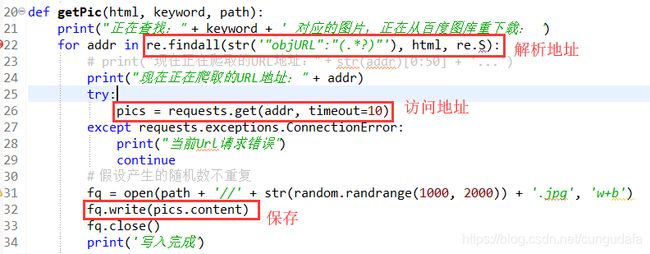
3. 错误机制
3 防止'data-objurl='后图片url解析有误程序中断,
- 设置了
continue;及10s后timeout; - 保存命名格式为(
1000~2000)不重复的随机数
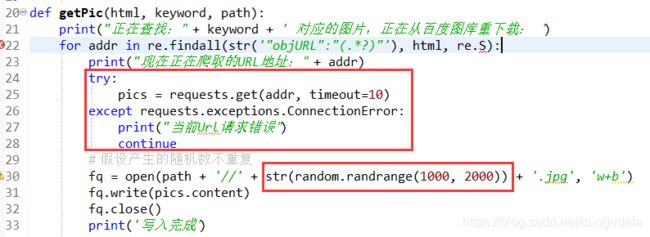
4 这里做一个文件夹是否存在的判断

二、运行结果及源码
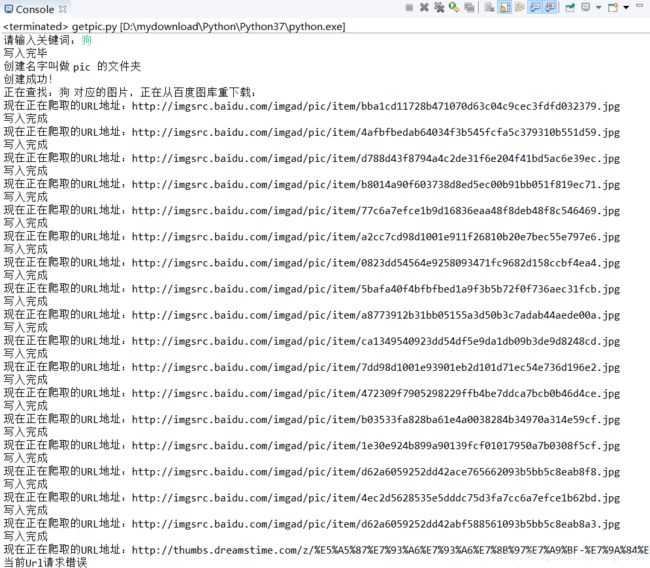
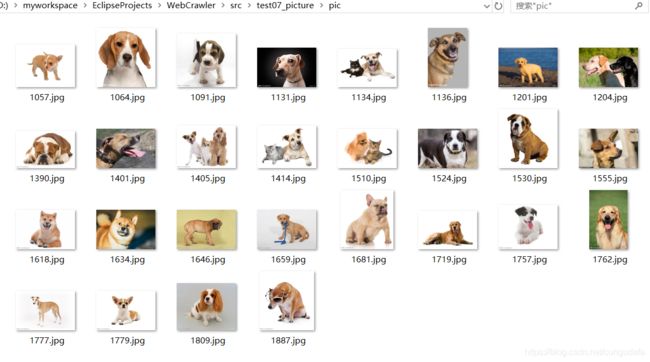
全部源码:
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
import requests # http客户端
import re # 正则表达式模块
import random # 随机数
import os # 创建文件夹
def mkdir(path): # 创建文件夹
is_exists = os.path.exists(path)
if not is_exists:
print('创建名字叫做', path, '的文件夹')
os.makedirs(path)
print('创建成功!')
else:
print(path, '文件夹已经存在了,不再创建')
def getPic(html, keyword, path):
print("正在查找:" + keyword + ' 对应的图片,正在从百度图库重下载: ')
for addr in re.findall(str('"objURL":"(.*?)"'), html, re.S):
print("现在正在爬取的URL地址:" + addr)
try:
pics = requests.get(addr, timeout=10)
except requests.exceptions.ConnectionError:
print("当前Url请求错误")
continue
# 假设产生的随机数不重复
fq = open(path + '//' + str(random.randrange(1000, 2000)) + '.jpg', 'w+b')
fq.write(pics.content)
fq.close()
print('写入完成')
if __name__ == "__main__":
word = input("请输入关键词:")
result = requests.get(
"http://image.baidu.com/search/index?tn=baiduimage&ps=1&ct=201326592&lm=-1&cl=2&nc=1&ie=utf-8&word=" + word)
# print(result.text)
print("写入完毕")
path = 'pic' # 保存图片文件夹名称
mkdir(path)
getPic(result.text, word, path)
总结不足:
1、timeout设置没有确定下载图片具体数量
2、图片命名没有特定要求,采取的随机数