【百面】损失函数和优化算法笔记
参考文献
1.《百面机器学习》
2.确定不收藏?机器学习必备的分类损失函数速查手册
机器学习算法=模型表征+模型评估+优化算法
【1】模型表征:各种机器学习模型
【2】模型评估:各种损失函数;
【3】优化算法:各种优化算法;优化算法所做的事情就是在模型表征空间中找到模型评估指标最好的模型。
问题背景(矛盾):
传统优化理论:基于全量数据、凸优化;
实际场景:大规模、高度非凸的优化问题;
一.损失函数(7个)
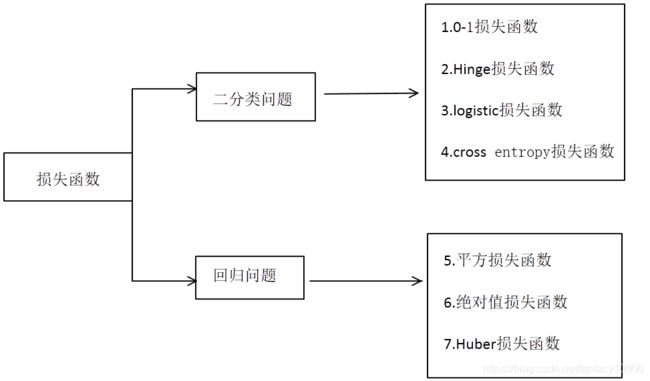

1.1针对二分类问题的损失函数
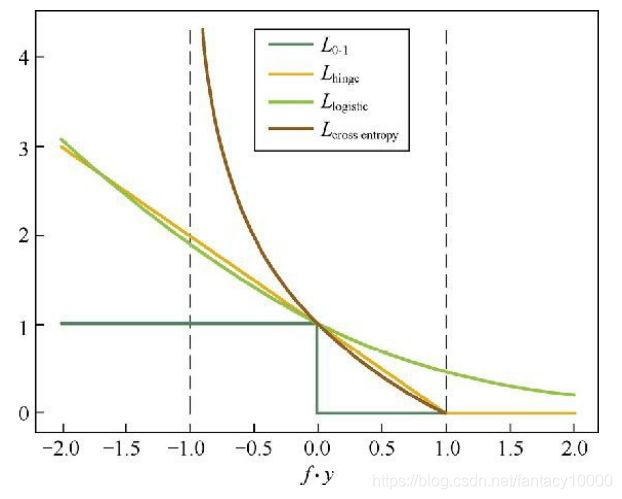
1.0-1损失函数
优点:可以直观刻画错误率
缺点:非凸、非光滑,很难用算法进行优化
直观表示:

统一表示:
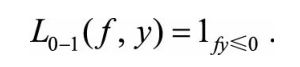
2.Hinge损失函数(合页损失函数)
Hinge是0-1损失函数的相对紧的凸上界
缺点:在fy=1的地方不可导,无法用梯度下降法来优化
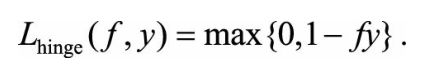
3.Logistic损失函数
优点:可以用梯度下降法进行优化
缺点:对所有的样本点都有所惩罚,因此对异常值更为敏感一些
直观表示:
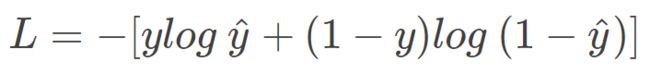
统一表示:(推导参见参考文献)
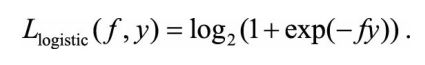
4.cross entropy损失函数
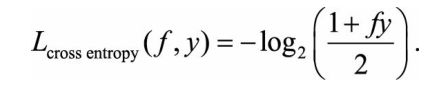
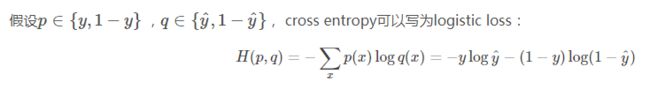
1.2针对回归问题的损失函数
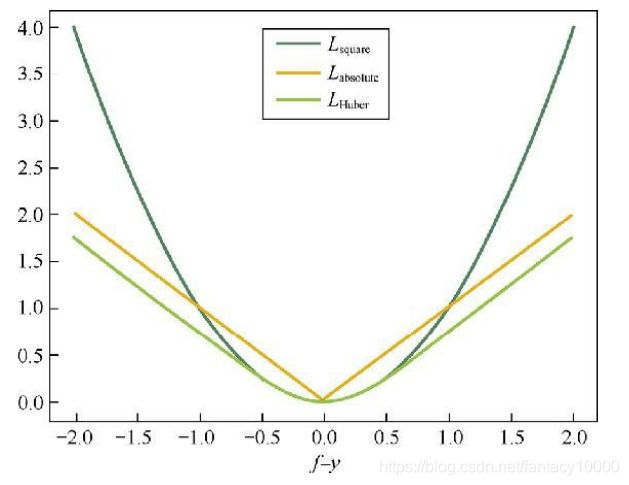
5.平方损失函数
优点:是光滑函数,可以使用梯度下降法进行优化
缺点:当预测值与真实值越远,则惩罚力度越大(因为是差值平方嘛),因此对于异常点较为敏感
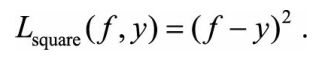
6.绝对值损失函数
优点:相较平方损失函数,对于异常点更为鲁棒
缺点:在f=y处无法求导
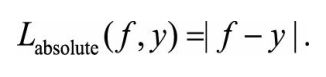
7.Huber损失函数
属于平方损失函数和绝对值损失函数的结合体
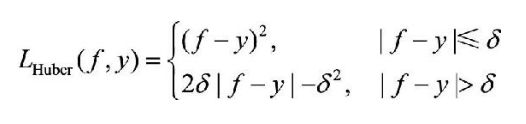
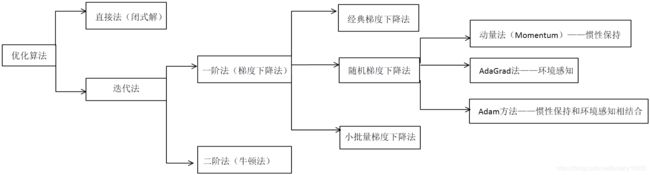
二.机器学习中的优化算法
2.1.凸优化的定义
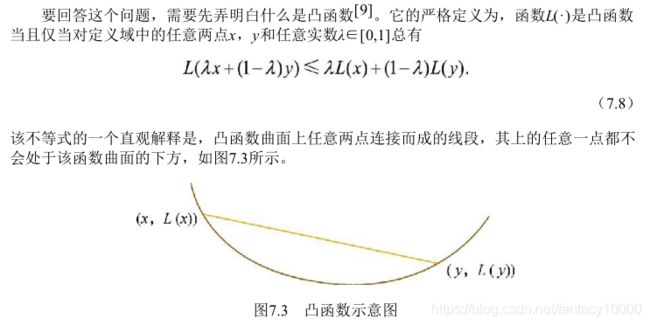
凸优化问题示例模型:SVM、线性回归等
非凸优化问题示例模型:矩阵分解、深度神经网络等
2.2.经典优化算法
【1】直接法(闭式解法):
顾名思义,就是可以直接给出优化问题最优解的方法。
需要目标函数满足两个条件:(1)是凸函数;(2)函数梯度为0有闭式解;
因为这两个条件限制了直接法的适用范围,所以应用范围很小;
【2】迭代法:
顾名思义,就是迭代地修正对最优解的估计。迭代法又可分为一阶法和二阶法两类。
【2.1】一阶法(梯度下降法)

【2.2】二阶法(牛顿法)

2.3.梯度下降法细分(3种)

这一损失函数刻画了当参数为θ时,模型在在所有数据上的平均损失。我们希望找到平均损失最小的模型参数,也就是求解优化问题:
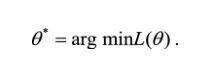
1.经典梯度下降法
经典梯度下降法采用所有训练数据的平均损失来近似目标函数,因此经典的梯度下降法在每次对模型参数进行更新时,需要遍历所有的训练数据。当训练数据规模很大时,这需要耗费很大的计算时间,在实际应用中基本不可行。
2.随机梯度下降法
为解决计算量的问题,随机梯度下降法用单个训练样本的损失来近似平均损失,因此随机梯度下降法用单个训练数据就可对模型参数进行一次更新,这样大大加快了收敛速率。这一方法也非常适用于数据源源不断到来的在线更新场景。
3.小批量梯度下降法
小批量梯度下降法属于经典梯度下降法和随机梯度下降法的折中产物,一方面为了降低随机梯度的方差,使得迭代算法更稳定,另一方面也为了充分利用高度优化的矩阵运算操作,在实际操作中会同时处理一个小批次的数据。
相应的衍生问题包括:
(1)训练数据的个数m怎么取?(2)这m个训练数据按什么规则取?(3)学习速率α怎么取?
2.4.随机梯度下降法的加速
形象的比喻:批量梯度下降法(BGD)就好比正常下山;而随机梯度下降法(SGD)就好比蒙着眼睛下山;
最致命的场景:
直观上,深度学习作为非凸优化问题,存在诸多的局部最优点,但是对于随机梯度下降法来说,局部最优点并不可怕,因为随机梯度下降法本身较高的收敛不稳定性使得它有较大机会跳出局部最优点,真正可怕的是“山谷”和“鞍点”。
山谷:
在山谷中,准确的梯度方向是沿山道向下,稍有偏离就会撞向山壁,而粗糙的梯度估计使得它在两山壁间来回反弹震荡,不能沿山道方向迅速下降,导致收敛不稳定和收敛速度慢。
鞍点:
在梯度近乎为零的区域,随机梯度下降法无法准确察觉出梯度的微小变化,结果就停滞下来。
解决方法:(惯性保持和环境感知)实际上就是采用了高中物理中的加速度思想!
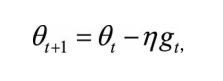
【方法1】动量方法(Momentum)—惯性保持
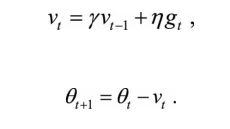
具体来说,前进步伐 −vt 由两部分组成:一是学习速率 η 乘以当前估计的梯度gt;二是带衰减的前一次步伐vt−1 。这里,惯性就体现在对前一次步伐信息的重利用上。
类比中学物理知识(加速运动公式),当前梯度就好比当前时刻受力产生的加速度,前一次步伐好比前一时刻的速度,当前步伐好比当前时刻的速度。为了计算当前时刻的速度,应当考虑前一时刻速度和当前加速度共同作用的结果,因此 vt 直接依赖于 vt−1 和 gt,而不仅仅是gt 。另外,衰减系数 γ 扮演了阻力的作用。
【方法2】AdaGrad方法—环境感知
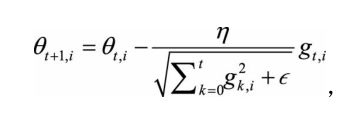
随机梯度下降法对环境的感知是指在参数空间中,根据不同参数的一些经验性判断,自适应地确定参数的学习速率,不同参数的更新步幅是不同的。
在应用中,我们希望更新频率低的参数可以拥有较大的更新步幅,而更新频率高的参数的步幅可以减小。
AdaGrad方法采用“历史梯度平方和”来衡量不同参数的梯度的稀疏性,取值越小表明越稀疏,具体的更新公式如上所示。其中θt+1,i 表示(t+1)时刻的参数向量θt+1 的第i个参数,gk,i 表示 k 时刻的梯度向量 gk 的第 i 个维度(方向)。另外,分母中求和的形式实现了退火过程,这是很多优化技术中常见的策略,意味着随着时间推移,学习速率越来越小,从而保证了算法的最终收敛。
【方法3】Adam方法—惯性保持和环境感知相结合
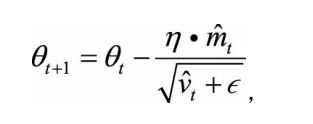
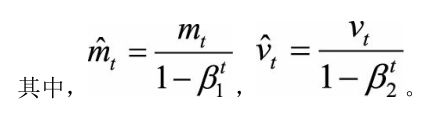
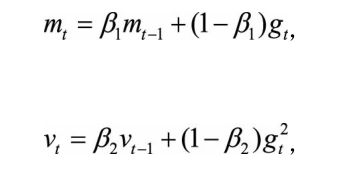
一方面,Adam记录梯度的一阶矩(first moment),即过往梯度与当前梯度的平均,这体现了惯性保持;
另一方面,Adam还记录梯度的二阶矩(second moment),即过往梯度平方与当前梯度平方的平均。
一阶矩和二阶矩采用类似于滑动窗口内求平均的思想进行融合,即当前梯度和近一段时间内梯度的平均值,时间久远的梯度对当前平均值的贡献呈指数衰减。
如何理解一阶矩和二阶矩:
一阶矩相当于估计E[gt]:由于当下梯度 gt 是随机采样得到的估计结果,因此更关注它在统计意义上的期望;
二阶矩相当于估计E[gt^2] ,这点与AdaGrad方法不同,不是gt2 从开始到现在的加和,而是它的期望。
它们的物理意义是:
【1】当||mt||大且 vt 大时,梯度大且稳定,这表明遇到一个明显的大坡,前进方向明确;
【2】当||mt||趋于零且 vt 大时,梯度不稳定,表明可能遇到一个峡谷,容易引起反弹震荡;
【3】当||mt||大且 vt 趋于零时,这种情况不可能出现;
【4】当||mt||趋于零且 vt 趋于零时,梯度趋于零,可能到达局部最低点,也可能走到一片坡度极缓的平地,此时要避免陷入平原(plateau);
其他的方法:
Nesterov Accelerated Gradient
AdaDelta和RMSProp
AdaMax
Nadam