神经网络算法详解 03:竞争神经网络(SONN、SOFM、LVQ、CPN、ART)
本文介绍了与竞争神经网络的相关知识,包括自组织神经网络(SONN)、自组织特征映射网络(SOFM)、学习向量量化神经网络(LVQ)、对偶传播神经网络(CPN)、自适应共振理论网络(ART)。
系列文章:
- 【神经网络算法详解 01】-- 人工神经网络基础
- 【神经网络算法详解 02】 – 感知神经网络与反向传播算法(BP)
- 【神经网络算法详解 03】 – 竞争神经网络【SONN、SOFM、LVQ、CPN、ART】
- 【神经网络算法详解 04】 – 反馈神经网络 【Hopfield、DHNN、CHNN、BAM、BM、RBM】
- 【神经网络算法详解 05】-- 其它类型的神经网络简介【RBF NN、DNN、CNN、LSTM、RNN、AE、DBN、GAN】
文章目录
- 系列文章:
- 1. 竞争学习原理与策略
- 1.1 MLP存在的问题
- 1.2 生物神经网络的特点
- 1.3 自组织神经网络(SONN)
- 1.4 竞争学习
- 1.5 竞争学习原理:胜者为王
- 2. 自组织特征映射网络(SOFM)
- 2.1 Kohonen 算法
- 2.1.1 Kohonen算法步骤
- 2.1.2 Kohonen 算法步骤
- 3. 学习向量量化神经网络(LVQ)
- 3.1 量化的定义
- 3.2 LVQ神经网络
- 3.3 LVQ算法流程
- 4. 对偶传播神经网络(CPN)
- 4.1 CPN工作原理
- 4.2 CPN改进:双获胜神经元
- 5. 自适应共振理论网络(ART)
- 5.1 神经网络常见的问题
- 5.2 ART网络结构
- 5.2.1 网络结构功能说明
- 5.3 ART网络运行原理
- 5.4 ART网络学习算法
- 5.5 ART网络特点
1. 竞争学习原理与策略
1.1 MLP存在的问题
我们在之前的文章中学习了多层感知器(MLP),MLP网络存在一系列的问题,具体来说有如下几点:
- 学习过程中,所有权重的值都要调整。存在两个问题:训练过程中计算量过大,并且会存在权重不稳定的可能。
- 误差曲面复杂有起伏时,MLP容易陷入局部极小,即局部最优值,或者其他训练参数(学习率,初始化权重等)选择不合适,引发损失震荡,不会收敛到一个固定的值,最终结果可能不理想。
- 误差准则(权重更新的依据)是固定的,或者在种程度上来讲是固定的,不能随着环境的变化而进行相应的调整或改变。
- 更适用于平稳的环境,各种对象、对象间关系及观察结果具有统计平稳性,各项统计特性不会随着时间的变化而变化。
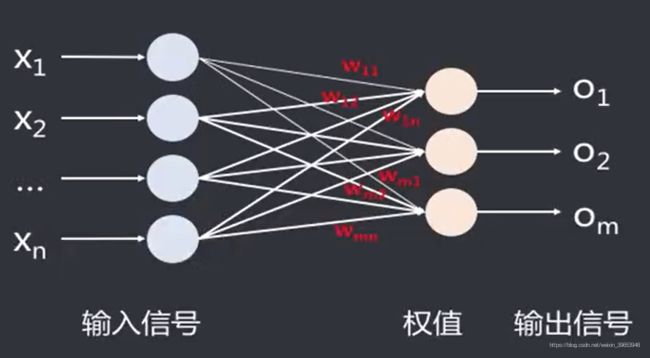
1.2 生物神经网络的特点
对于述问题,生物神经系统的情况主要由如下几点。
- 人脑的学习是自主式的:可以应对一个非常复杂的、不平稳的、有干扰的环境,辨识学习目标并习得到知识。属于没有导师的自学模式。
- 人脑的工作方式及信息的存储和检索方式都非固定模式的,而是更接近自组织的:人通过学习积累经验,对外界的环境做出响应,响应对了得到奖励,响应错了受到惩罚,在这个过程中根据反馈结果不断的修正、调整自己的响应策略和方式,以便得到更好的结果。
- 人的学习能力和记忆能力有弹性、可塑性·常用的知识会学好、记牢,不常用的会逐渐忘掉。
- 据研究,脑神经元中存在抑制作用,不但接收外界环境刺激、其他神经元的刺激,也会受到周围神经元的抑制
- 人在响应外界环境时,既能由底向上(根据外界输入对其进行分类、识别),又能从顶向下(既能集中注意力,又能忽略一些非重要信息)
1.3 自组织神经网络(SONN)
【自组织神经网络(Self Organization Neural Network,SONN)】,又称自组织竞争神经网络,通过自动寻找样本中的内在规律和本质属性,自组织、自适应地改变网络参数与结构。通常自组织通过竞争学习(CompetitiveLearning)实现。
- 自组织神经网络属于前馈神经网络;
- 自组织神经网络采用无监督学习算法;
- 其思路为:竟争层的神经元通过竟争(与输入模式进行匹配),选出一个获胜者,其输出就代表了对输入模式的分类;
- 常见的:自适应共振理论网络ART、自组织特征映射网络SOM、对偶传播网络CPN等
- 适合解决模式分类和识别方面的问题
1.4 竞争学习
在学习算法上,自组织神经网络模拟生物神经系统依靠神经元之间的兴奋、协调与抑制、竟争的作用来进行信息处理的原理指导网络的学习与工作,而不像大多数神经网络那样以网络的误差或者能量函数(比如Hopfield)作为算法的准则。
竟争学习是自组织网络中最常用的一种学习策略。
【竞争学习(CompetitionLearning)】是人工神经网络的一种学习方式,指网络单元群体中所有单元相互竞争对外界刺激模式响应的权利。竟争取胜的单元的连接权重向着对这一刺激有利的方向变化,相对来说竞争取胜的单元抑制了竞争失败单元对刺激模式的响应。属于自适应学习,使网络单元具有选择接受外界刺激模式的特性。竟争学习的更一般形式是不仅允许单个胜者出现,而是允许多个胜者出现,学习发生在胜者集合中各单元的连接权重上。
1.5 竞争学习原理:胜者为王
【胜者为王学习规则(Winner-Take-All)】:网络对输入做出响应,其中具有最大响应的神经元被激活,该神经元获得修改权重的机会。

将网络的某一层设置为竟争层,对于输入 X X X 竟争层的所有 p p p 个神经元均有输出响应,响应值最大的神经元在竞争中获胜,即:
W m T X = m a x i = 1 , 2 , . . . , p ( W i T X ) W^T_mX = max_{i = 1,2,...,p} (W^T_iX) WmTX=maxi=1,2,...,p(WiTX)
获胜的神经元才有权调整其权向量 W m W_m Wm,调整量为:
Δ W m = α ( X − W m ) , 其 中 α ∈ ( 0 , 1 ] , 随 着 学 习 而 减 小 \Delta W_m=\alpha(X-W_m),其中 \alpha \in (0,1] ,随着学习而减小 ΔWm=α(X−Wm),其中α∈(0,1],随着学习而减小
在竟争学习过程中,竟争层的各神经元所对应的权向量逐渐调整为输入样本空间的聚类中心。注意“()”中的差不是网络误差(期望输出与实际输出的差值),而是输入X与权重的差值。
在实际应用中,通常会定义以获胜神经元为中心的邻域。所在邻域内的所有神经元都进行权重调整。
2. 自组织特征映射网络(SOFM)

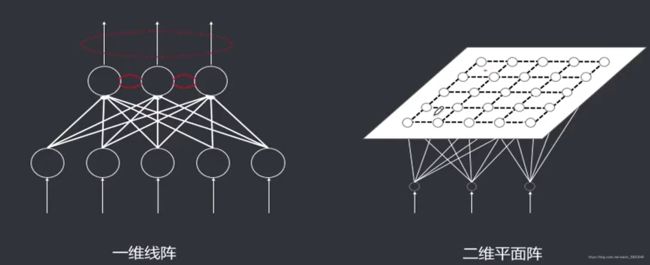
2.1 Kohonen 算法
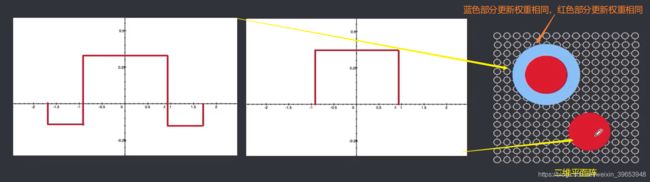
【Kohonen算法】类似于胜者为王算法,主要区别在于调整权向量和抑制的方式不同。胜者为王中只有获胜的唯一的神经元得到调整向量的机会,其他神经元被抑制。Kohonen算法对邻近神经元的影响是由中心到边缘逐渐变弱的,即邻近区域的神经元都有机会调整权向量,不过调整的程度不同,通过激活函数实现。
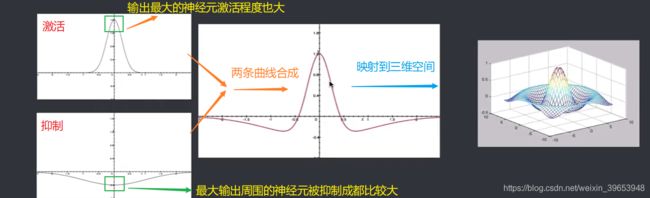
由上图可以看出,最大输出的神经元的权重调整程度最大,以此为中心向周围的调整力度逐渐降低。在三维空间中的图形很像墨西哥帽,所以这种激活函数也叫作墨西哥帽。再看另外两种(“大礼帽”、“厨师帽”)。
2.1.1 Kohonen算法步骤
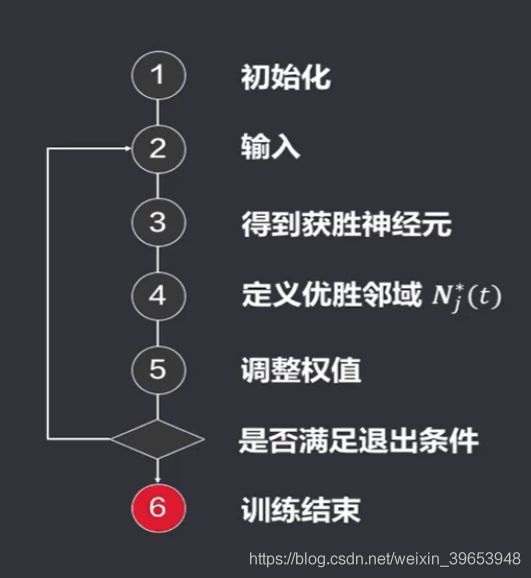
针对以上的流程,具体细节如下:
- 对各参数进行初始化,包括:
- 对输出层各权向量赋值:赋一些小的随机数 W j W_j Wj
- 对输出层各权向量进行归一化处理 W j ^ \hat{W_j} Wj^
- 建立初始优胜邻域 N j ∗ ( 0 ) N^*_j(0) Nj∗(0)
- 对学习率进行赋值 η \eta η
- 从训练集输入数据,并进行归一化处理,得到 X p ^ , p ∈ { 1 , 2 , . . . , P } \hat{X_p},p \in \lbrace 1,2,...,P\rbrace Xp^,p∈{1,2,...,P}
- 根据输入,得到当前获胜的神经元。计算 W j ^ \hat{W_j} Wj^ 与 X p ^ \hat{X_p} Xp^ 的点积,找到点积最大的神经元,即为获胜神经元。
- 以广为中心确定t时刻的权值调整域。一般情况下初始邻域 N j ∗ ( 0 ) N^*_j(0) Nj∗(0)较大,训练过程中 N j ∗ ( 0 ) N^*_j(0) Nj∗(0)随训练时间逐渐收缩。
- 调整优胜邻域中的所有的神经元权值。调整公式为:
w i j ( t 十 1 ) = w i j ( t ) + η ( t , N ) [ x i p − w i j ( t ) ] w_{ij}(t十1)= w_{ij}(t) + \eta(t,N)[x^p_i - w_{ij}(t)] wij(t十1)=wij(t)+η(t,N)[xip−wij(t)]
其中, η ( t , N ) \eta(t,N) η(t,N) 表示训练时间 t t t和邻域内第 j j j个神经元与获胜神经元 j ∗ j^* j∗之间的距离 N N N 的函数, η ( t , N ) \eta(t,N) η(t,N) 与 t , N t,N t,N 均成反比,即随着时间越来越小,并且 j j j神经元离获胜的 j ∗ j^* j∗神经元越远,权重变化越小。 - 通常根据学习率 η \eta η 是否衰减到某个事先约定的阈值判断。
2.1.2 Kohonen 算法步骤
已知一些动物属性,使用Kohonen网络对其进行聚类。
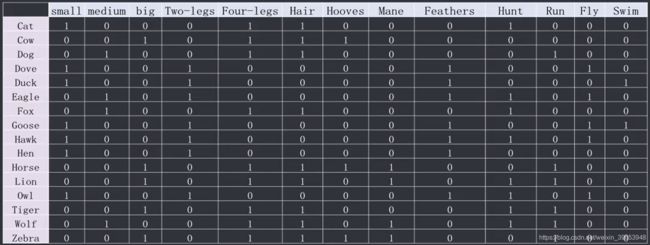
- 整理数据:将16种动物通过16个输入特征来表示,第一种将第一个特征设为1,其余为0,第二种将第二特征设为1,其余为0,依次类准,数据变为如下16行29个属性的数据。其实就是变为虚拟变量(哑变量),常用的one-hot编码就是这种格式。

- 设计网络结构:输入为29个节点,输出到一个1010的二维平面上。虽然有16类,但是每一类的可能映射不止一种,所以设置为1010。
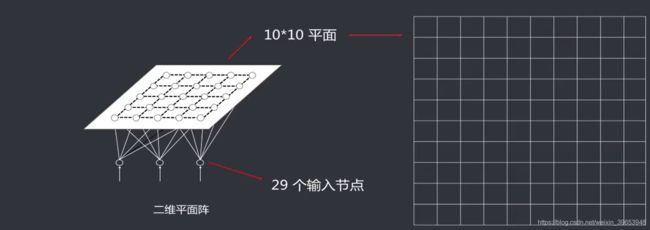
- 初始化参数:输入为29个节点,输出到一个1010 的二维平面上。
权向量初始化:权重向量为一个2910*10的数组 W W W,对其赋予一系列的0-1之间的随机数。
权向量归一化:将向量数组 W W W归一化。
建立初始邻域:将初始邻域距离设置为2,即距离获胜神经元欧氏距离 ≤ 2 \le 2 ≤2的神经元均划在邻域内,邻域随着训练次数的增加而逐渐减小。
学习率:初始值设为 η ( t ) = 0.3 t \eta(t) = \frac{0.3}{t} η(t)=t0.3,随着训练次数增加,学习率按照 η ′ = η ∗ e − N \eta'=\eta*e^{-N} η′=η∗e−N衰减, N N N 距离获胜神经元的距离。
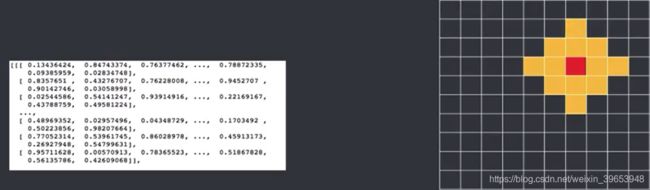
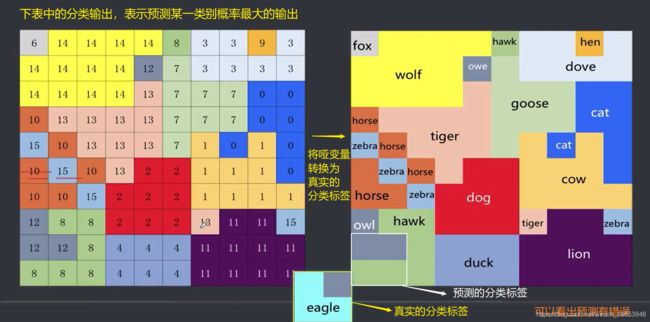
- 得到获胜神经元及邻域:将输入数据逐一输入,和权重数组相乘,映射到1010的输出节点上,值最大的即为获胜者。以第一条数据为例,输入后,和当前权重数组相乘。得到一个1010的输出,映射到输出节点如下:

上图中,白色区域表示初始邻域,这些神经元得到了输出机会。 - 将获胜神经元邻域内输出节点对应的权重数组按公式 w i j ( t 十 1 ) = w i j ( t ) + η ( t , N ) [ x i p − w i j ( t ) ] w_{ij}(t十1)= w_{ij}(t) + \eta(t,N)[x^p_i - w_{ij}(t)] wij(t十1)=wij(t)+η(t,N)[xip−wij(t)]进行调整。

- 是否满足结束条件:学习率衰减到一个小于阈值的值,或者训练次数达到约定的值。
本例对16条记录的数据集,进行了1000次的练。输出结果如下:
3. 学习向量量化神经网络(LVQ)
不知道是不是用了霸王洗发水。
【学习向量量化神经网络(Learning Vector Quantization,LVQ)】,在竟争网络的基础上,由Kohonen提出其核心为将竟争学习与有监督学习相结合,学习过程中通过教师信号对输入样本的分配类别进行规定,克服了自组织网络采用无监督学习算法带来的缺乏分类信息的弱点。
3.1 量化的定义
【量化】:在数字信号处理领域,是指将信号的连续取值(或者大量可能的离散取值)近似为有限多个(或较少的)离散值的过程,简单来说就是将连续值进行离散化。向量量化是对标量量化的扩展,更适用于高维数据。
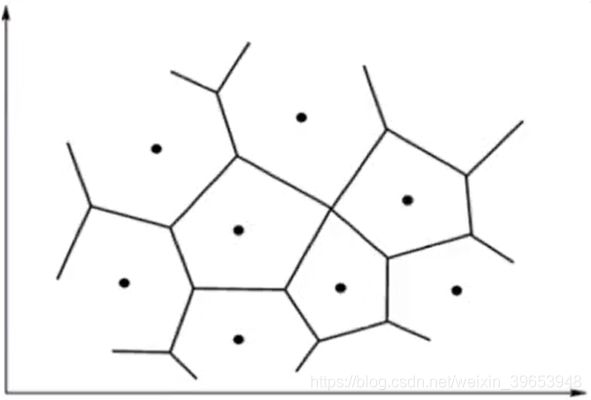
通常情况下,向量量化的思路是:在高维空间,把它分成多个不同的区域,对每个区域指定一个中心向量,这里可以类比于聚类问题中的聚类中心。当输入数据映射到这个区域中时,可以用中心向量与距离中心来代表这个数据。最终结果就形成了以中心向量为中心的集合。这就是LVQ的中心思想。
3.2 LVQ神经网络
将高维数据映射到二维输入平面上,之前的Winner-Take-All和SOFM算法都是类似的向量量化算法,都能用少量的聚类中心表示原始数据。但SOFM的各相邻聚类中心对应的向量具有某种相似的特征,而一般向量量化的中心不具备这种特点。
- 第一步,聚类;通过自组织映射进行聚类。
- 第二步,学习向量量化;通过有监督方法,利用教师信号作为分类信息对权值进行调整,并指定输出神经元的的类别。
网络结构特点:
- 由三层组成:输入层、竟争层、输出层;
- 输入层和竞争层之间是全连接;
- 一组竞争层节点对应一个输出节点;
- 输入层到竞争层的权重可调整;
- 竟争层到输出层的权重通常为固定值1;
- 竟争层的学习规则为胜者为王(WTA);
- 竟争层的胜者输出为1,其余为0。
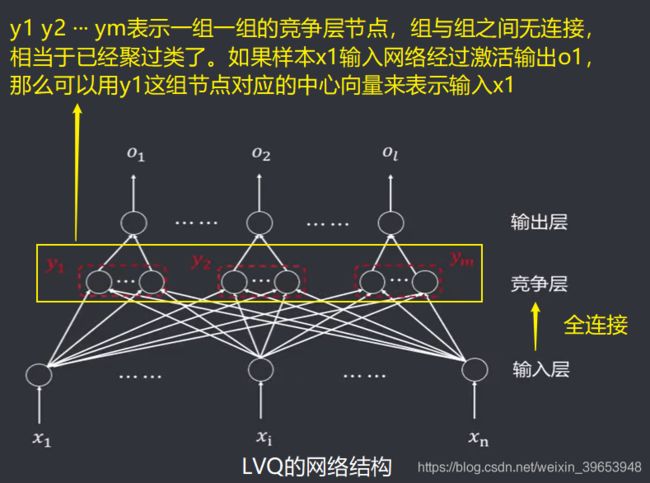
y 1 , y 2 , . . . , y m y_1,y_2,...,y_m y1,y2,...,ym 表示竞争层中每组节点的输出。
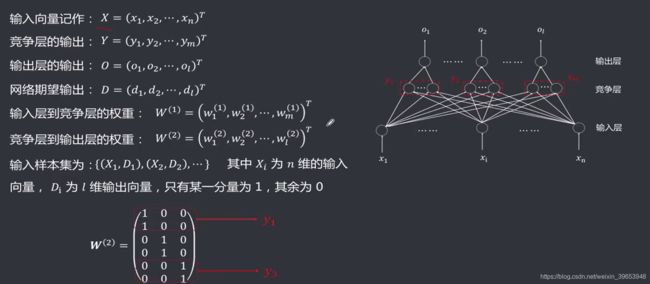
标记说明:
3.3 LVQ算法流程

实际上,可以将LVQ算法分成两部分。第一部分,寻找获胜神经元。其实寻找获胜神经单元的过程就是在找中心向量,通过不断地训练(寻找),中心向量会越来越明确,也就是说竞争层中组与组之间的区分会越来越明显,最终就会形成固定的几组(可以类比成聚类)。第二部分,通过监督学习的算法来进行权重调整。这个过程通过输入样本与权重的比较,不断地更新权重和学习率等参数。这两部分结合,能够达到很好的分类效果。
4. 对偶传播神经网络(CPN)
聪明绝顶警告!

【对偶传播神经网络(Counter-Propagation Network,CPN)】,1987年由美国学者Robert Hecht-NieIsen提出,最早用来实现样本选择匹配系统,能存储二进制或模拟值的模式对,可用于联想存储、模式分类、函数逼近、统计分析和数据压缩等。
网拓扑结构:共三层,各层之间为全连接,与三层 BP 网络相似。但其本质不同,实际上是由
自组织网络+外星网络构成,其隐藏层即为竞争层,采用竞争学习规则,输出层为 Grossberg 层,采用 Widrow-Hoff 或者 Grossberg 学习规则。

4.1 CPN工作原理
算法流程:
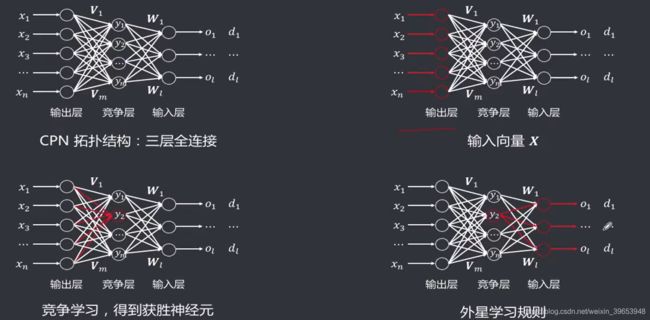
阶段一:输入层到竞争层权重调整

阶段二:竞争层到输出层的权重调整

至此,网络训练完成。
4.2 CPN改进:双获胜神经元
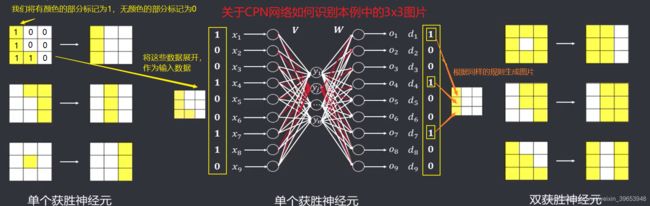
【双获胜神经元CPN网】:无获胜邻域念,可以改进为竞争层两个神经元获胜,更新两个神经元对应的权重。对于每个输入式,允许有两个竞争层神经元获胜,如果输入为由两个训练样本线性组合而成的新模式(复合模式),那么网络的输出就是与复合输入模式中包含的样本相对应的输出模式的组合。

5. 自适应共振理论网络(ART)
这就是见识长头发短吧。

【 自适应共振理论(Adaptive Resonance Theory,ART)】,1976年由美国波斯顿大学学者GACarpenter提出,试图为人类的心理和认知活动建立统一的数学理论。随后又和S.Grossberg提出了ART网络。
5.1 神经网络常见的问题
-
有监督学习网络:通过反复输入样本数据,使其达到稳定记忆(得到可以接受的参数)后,再输入新样本继续洲练的话,前面的训练结果会受到影响。
-
无监督学习网络:新样本会对己训练的聚类进行修改,从学习的角度来理解,即新知识的学习,会导致对旧知识的遗忘。很多类型的网络,也会考虑对旧知识的保留,比如权重调整公式中考虑包含对数据的学习项及对旧数据的忘却项,通过控制学习系数和忘记系数的大小来平衡新旧知识的关系,但是这些系数的确定成为新的问题,很难有一般方法解决。
-
无/有监督学习网络:最终学习效果主要通过权重阵 W W W 来体现,但其能包含的信息终归有限,记忆的模式类别信息必然会被新输入产生的模式抵消(遗忘),影响分类结果。也不能无限扩大网络规模,因为随着规模的扩大,计算量会迅速上升,到一定程度,网络已经不可训练了。
针对以上问题,ART网络应用而生。
5.2 ART网络结构
ART网络由两层组成两个子系统,一个叫比较层C,一个叫识别层R,及三种控制信号:复位信号(Reset)、**逻辑控制信号(GI、G2)**组成。
5.2.1 网络结构功能说明
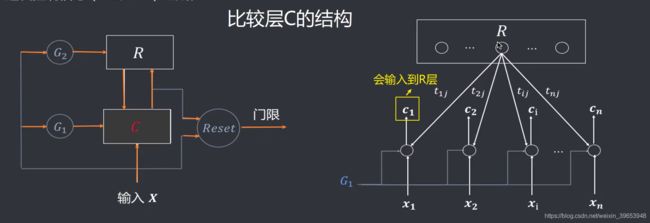
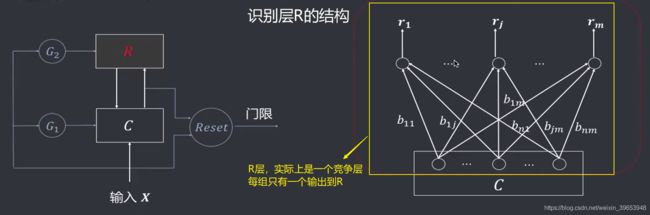

- 网络接受新的输入后,开始检输入和R层已有分类信息的匹配程度(竟争学习得到获胜单元)
- 对于相似程度高的(获胜神经元)需要继续考察其储存的模式与输入模式的相似程度(根据预先设定的参考门限评估)
- 如果相似度超过门限,则归于该类,调鼙权重,使其遇到与当前输入模式相似的样本时得到更大的相似度
- 如果相似度没有超过门限,则对匹配程度次高的神经元对应的模式进行相似度评估,如果超门限,返回上一步,否则继续本步查找匹配程度次次高的模式,返回操作还回到本步,则需要在输出端设立一个代表新模式的神经元,代表该模式,参与后续的匹配评估过程。
5.3 ART网络运行原理



5.4 ART网络学习算法


5.5 ART网络特点

- 非离线学习,即不是对输入集样本反复训练后才开始运行,而是采用了边学习边运行的方式;
- 每个输入样本,都被看成一类相近样本的代表,每次最多只有一个类别输出为1;
- 当输入样本距某一个内星权向量较近(由门限值 ρ \rho ρ 决定)时,代表它的输出神经元才会响应;
- 门限值影响到最终的分类精度,换言之,门限值 ρ \rho ρ 越小分类个数越少,反之分类越多;
- 只能处理输入类型为二进制或者双极型的情况。
ART还有两个扩展类型:
- ARTII:是ARTI的扩展形式,可以处理连续模拟信号;
- ARTIII:分级搜索模型,兼容ARTI与ARTII两种结构功能,并能将两层神经网络扩大为任意多层神经网络。
课程链接:https://edu.aliyun.com/course/1923