深度强化学习(8)Proximal Policy Optimization(PPO)
1. Trust region policy optimization(TRPO)
我们先来介绍TRPO。TRPO是英文单词Trust region policy optimization的简称,翻译成中文是置信域策略优化。
根据策略梯度方法,参数更新方程式为:
θ n e w = θ o l d + α ∇ θ J \theta_{new}=\theta_{old}+\alpha\nabla_{\theta}J θnew=θold+α∇θJ
策略梯度算法的硬伤就在更新步长 α \alpha α ,当步长不合适时,更新的参数所对应的策略是一个更不好的策略,当利用这个更不好的策略进行采样学习时,再次更新的参数会更差,因此很容易导致越学越差,最后崩溃。所以,合适的步长对于强化学习非常关键。
什么叫合适的步长?
所谓合适的步长是指当策略更新后,回报函数的值不能更差。如何选择这个步长?或者说,如何找到新的策略使得新的回报函数的值单调增,或单调不减。这是TRPO要解决的问题。
用 τ \tau τ 表示一组状态-行为序列 s 0 , u 0 , ⋯ , s H , u H s_0,u_0,\cdots ,s_H,u_H s0,u0,⋯,sH,uH ,强化学习的回报函数为:
η ( π ~ ) = E τ ∣ π ~ [ ∑ t = 0 ∞ γ t ( r ( s t ) ) ] \eta\left(\tilde{\pi}\right)=E_{\tau |\tilde{\pi}}\left[\sum_{t=0}^{\infty}{\gamma^t\left(r\left(s_t\right)\right)}\right] η(π~)=Eτ∣π~[∑t=0∞γt(r(st))]
这里,我们用 π ~ \tilde{\pi} π~ 表示策略。
刚才已经说过,TRPO是找到新的策略,使得回报函数单调不减,一个自然地想法是能不能将新的策略所对应的回报函数分解成旧的策略所对应的回报函数+其它项。只要新的策略所对应的其它项大于等于零,那么新的策略就能保证回报函数单调不减。其实是存在这样的等式,这个等式是2002年Sham Kakade提出来的。TRPO的起点便是这样一个等式:
η ( π ~ ) = η ( π ) + E s 0 , a 0 , ⋯ π ~ [ ∑ t = 0 ∞ γ t A π ( s t , a t ) ] \eta\left(\tilde{\pi}\right)=\eta\left(\pi\right)+E_{s_0,a_0,\cdots ~\tilde{\pi}}\left[\sum_{t=0}^{\infty}{\gamma^tA_{\pi}\left(s_t,a_t\right)}\right] η(π~)=η(π)+Es0,a0,⋯ π~[∑t=0∞γtAπ(st,at)] (1-1)
这里我们用 π \pi π 表示旧的策略,用 π ~ \tilde{\pi} π~ 表示新的策略。其中,
A π ( s , a ) = Q π ( s , a ) − V π ( s ) = E s ′ P ( s ′ ∣ s , a ) [ r ( s ) + γ V π ( s ′ ) − V π ( s ) ] A_{\pi}\left(s,a\right)=Q_{\pi}\left(s,a\right)-V_{\pi}\left(s\right) \\ =E_{s'~P\left(s'|s,a\right)}\left[r\left(s\right)+\gamma V^{\pi}\left(s'\right)-V^{\pi}\left(s\right)\right] Aπ(s,a)=Qπ(s,a)−Vπ(s)=Es′ P(s′∣s,a)[r(s)+γVπ(s′)−Vπ(s)]
称为优势函数。
(1-1)式可以展开为:
η ( π ~ ) = η ( π ) + ∑ t = 0 ∞ ∑ s P ( s t = s ∣ π ~ ) ∑ a π ~ ( a ∣ s ) γ t A π ( s , a ) \eta\left(\tilde{\pi}\right)=\eta\left(\pi\right)+\sum_{t=0}^{\infty}{\sum_s{P\left(s_t=s|\tilde{\pi}\right)}}\sum_a{\tilde{\pi}\left(a|s\right)\gamma^tA_{\pi}\left(s,a\right)} η(π~)=η(π)+∑t=0∞∑sP(st=s∣π~)∑aπ~(a∣s)γtAπ(s,a)
其中 P ( s t = s ∣ π ~ ) π ~ ( a ∣ s ) P\left(s_t=s|\tilde{\pi}\right)\tilde{\pi}\left(a|s\right) P(st=s∣π~)π~(a∣s) 为 (s,a) 的联合概率, ∑ a π ~ ( a ∣ s ) \sum_{a} \tilde{\pi}(a | s) ∑aπ~(a∣s)为求对动作 a 的边际分布,也就是说在状态s对整个动作空间求和; ∑ s P ( s t = s ∣ π ~ ) \sum_s{P\left(s_t=s|\tilde{\pi}\right)} ∑sP(st=s∣π~) 为求对状态 s 的边际分布,即对整个状态空间求和。
定义 ρ π ( s ) = P ( s 0 = s ) + γ P ( s 1 = s ) + γ 2 P ( s 2 = s ) + ⋯ \rho_{\pi}\left(s\right)=P\left(s_0=s\right)+\gamma P\left(s_1=s\right)+\gamma^2P\left(s_2=s\right)+\cdots ρπ(s)=P(s0=s)+γP(s1=s)+γ2P(s2=s)+⋯
则:
η ( π ~ ) = η ( π ) + ∑ s ρ π ~ ( s ) ∑ a π ~ ( a ∣ s ) A π ( s , a ) \eta\left(\tilde{\pi}\right)=\eta\left(\pi\right)+\sum_s{\rho_{\tilde{\pi}}\left(s\right)\sum_a{\tilde{\pi}\left(a|s\right)A^{\pi}\left(s,a\right)}} η(π~)=η(π)+∑sρπ~(s)∑aπ~(a∣s)Aπ(s,a)
如图所示: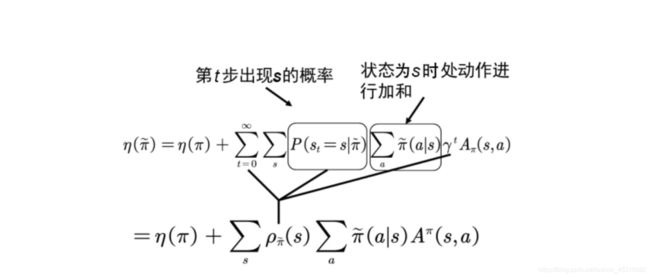
注意这里s是由新分布产生的,对新分布有很强的依赖性。这个公式其实在应用中完全无法达到,因为我们是为了得到新的策略,所以这里的其他项完全无从所知,为此,TRPO采取了一些技巧来解决这个问题。
TRPO第一个技巧
这时,我们引入TRPO的第一个技巧对状态分布进行处理。我们忽略状态分布的变化,依然采用旧的策略所对应的状态分布。这个技巧是对原代价函数的第一次近似。其实,当新旧参数很接近时,我们将用旧的状态分布代替新的状态分布也是合理的。这时,原来的代价函数变成了:
L π ( π ~ ) = η ( π ) + ∑ s ρ π ( s ) ∑ a π ~ ( a ∣ s ) A π ( s , a ) L_{\pi}\left(\tilde{\pi}\right)=\eta\left(\pi\right)+\sum_s{\rho_{\pi}\left(s\right)\sum_a{\tilde{\pi}\left(a|s\right)A^{\pi}\left(s,a\right)}} Lπ(π~)=η(π)+∑sρπ(s)∑aπ~(a∣s)Aπ(s,a)
我们再看上式的第二项策略部分,这时的动作a是由新的策略 π ~ \tilde{\pi} π~ 产生。可是新的策略 π ~ \tilde{\pi} π~ 是带参数 θ \theta θ 的,这个参数是未知的,因此无法用来产生动作。这时,我们引入TRPO的第二个技巧。
TRPO第二个技巧
TRPO的第二个技巧是利用重要性采样对动作分布进行的处理。
∑ a π ~ θ ( a ∣ s n ) A θ o l d ( s n , a ) = E a q [ π ~ θ ( a ∣ s n ) q ( a ∣ s n ) A θ o l d ( s n , a ) ] \sum_a{\tilde{\pi}_{\theta}\left(a|s_n\right)A_{\theta_{old}}\left(s_n,a\right)=E_{a~q}\left[\frac{\tilde{\pi}_{\theta}\left(a|s_n\right)}{q\left(a|s_n\right)}A_{\theta_{old}}\left(s_n,a\right)\right]} ∑aπ~θ(a∣sn)Aθold(sn,a)=Ea q[q(a∣sn)π~θ(a∣sn)Aθold(sn,a)]
通过利用两个技巧,我们再利用 1 1 − γ E s ρ θ o l d [ ⋯ ] \frac{1}{1-\gamma}E_{s~\rho_{\theta_{old}}}\left[\cdots\right] 1−γ1Es ρθold[⋯] 代替 ∑ s ρ θ o l d ( s ) [ ⋯ ] \sum_s{\rho_{\theta_{old}}\left(s\right)}\left[\cdots\right] ∑sρθold(s)[⋯] ;取 q ( a ∣ s n ) = π θ o l d ( a ∣ s n ) q\left(a|s_n\right)=\pi_{\theta_{old}}\left(a|s_n\right) q(a∣sn)=πθold(a∣sn) ;
替代回报函数变为:
L π ( π ~ ) = η ( π ) + E s ρ θ o l d , a π θ o l d [ π ~ θ ( a ∣ s ) π θ o l d ( a ∣ s ) A θ o l d ( s , a ) ] L_{\pi}\left(\tilde{\pi}\right)=\eta\left(\pi\right)+E_{s~\rho_{\theta_{old}},a~\pi_{\theta_{old}}}\left[\frac{\tilde{\pi}_{\theta}\left(a|s\right)}{\pi_{\theta_{old}}\left(a|s\right)}A_{\theta_{old}}\left(s,a\right)\right] Lπ(π~)=η(π)+Es ρθold,a πθold[πθold(a∣s)π~θ(a∣s)Aθold(s,a)]
将 L π ( π ~ ) , η ( π ~ ) L_{\pi}\left(\tilde{\pi}\right)\textrm{,}\eta\left(\tilde{\pi}\right) Lπ(π~),η(π~) 都看成是策略 π ~ \tilde{\pi} π~ 的函数,则 L π ( π ~ ) , η ( π ~ ) L_{\pi}\left(\tilde{\pi}\right)\textrm{,}\eta\left(\tilde{\pi}\right) Lπ(π~),η(π~) 在策略 π θ o l d \pi_{\theta_{old}} πθold 处一阶近似。
在 θ o l d \theta_{old} θold 附近,能改善L的策略也能改善原回报函数。问题是步长多大呢?
再次引入第二个重量级的不等式:
η ( π ~ ) ⩾ L π ( π ~ ) − C D K L max ( π , π ~ ) w h e r e C = 2 ε γ ( 1 − γ ) 2 \eta\left(\tilde{\pi}\right)\geqslant L_{\pi}\left(\tilde{\pi}\right)-CD_{KL}^{\max}\left(\pi ,\tilde{\pi}\right) \\ where\ C=\frac{2\varepsilon\gamma}{\left(1-\gamma\right)^2} η(π~)⩾Lπ(π~)−CDKLmax(π,π~)where C=(1−γ)22εγ (1-2)
其中 D K L ( π , π ~ ) D_{KL}\left(\pi ,\tilde{\pi}\right) DKL(π,π~) 是两个分布的KL散度。我们在这里看一看,该不等式给了我们什么启示。
首先,该不等式给了 η ( π ~ ) \eta\left(\tilde{\pi}\right) η(π~) 的下界,我们定义这个下界为
M i ( π ) = L π i ( π ) − C D K L max ( π i , π ) M_i\left(\pi\right)=L_{\pi_i}\left(\pi\right)-CD_{KL}^{\max}\left(\pi_i,\pi\right) Mi(π)=Lπi(π)−CDKLmax(πi,π)
下面利用这个下界,我们证明策略的单调性。
证明:
η ( π i + 1 ) ⩾ M i ( π i + 1 ) \eta\left(\pi_{i+1}\right)\geqslant M_i\left(\pi_{i+1}\right) η(πi+1)⩾Mi(πi+1)且 η ( π i ) = M i ( π i ) \eta\left(\pi_i\right)=M_i\left(\pi_i\right) η(πi)=Mi(πi)
则: η ( π i + 1 ) − η ( π i ) ⩾ M i ( π i + 1 ) − M ( π i ) \eta\left(\pi_{i+1}\right)-\eta\left(\pi_i\right)\geqslant M_i\left(\pi_{i+1}\right)-M\left(\pi_i\right) η(πi+1)−η(πi)⩾Mi(πi+1)−M(πi)
如果新的策略 π i + 1 \pi_{i+1} πi+1 能使得 M i M_i Mi 变大,那么有不等式 M i ( π i + 1 ) − M ( π i ) ⩾ 0 M_i\left(\pi_{i+1}\right)-M\left(\pi_i\right)\geqslant 0 Mi(πi+1)−M(πi)⩾0 ,则 η ( π i + 1 ) − η ( π i ) ⩾ 0 \eta\left(\pi_{i+1}\right)-\eta\left(\pi_i\right)\geqslant 0 η(πi+1)−η(πi)⩾0,这个使得 M i M_i Mi 变大的新的策略就是我们一直在苦苦找的要更新的策略。那么这个策略如何得到呢?
(要找的更新策略其实就是使得不等式(1-2)下界最大的策略)
该问题可形式化为:
m a x i m i z e θ [ L θ o l d ( θ ) − C D K L max ( θ o l d , θ ) ] maximize_{\theta}\left[L_{\theta_{old}}\left(\theta\right)-CD_{KL}^{\max}\left(\theta_{old},\theta\right)\right] maximizeθ[Lθold(θ)−CDKLmax(θold,θ)]
如果利用惩罚因子 C C C则每次迭代步长很小,因此问题可转化为:
m a x i m i z e θ E s ρ θ o l d , a π θ o l d [ π θ ( a ∣ s ) π θ o l d ( a ∣ s ) A θ o l d ( s , a ) ] s u b j e c t t o D K L max ( θ o l d , θ ) ≤ δ maximize_{\theta}E_{s~\rho_{\theta_{old}},a~\pi_{\theta_{old}}}\left[\frac{\pi_{\theta}\left(a|s\right)}{\pi_{\theta_{old}}\left(a|s\right)}A_{\theta_{old}}\left(s,a\right)\right] \\ subject\ to\\D_{KL}^{\max}\left(\theta_{old},\theta\right)\le\delta maximizeθEs ρθold,a πθold[πθold(a∣s)πθ(a∣s)Aθold(s,a)]subject toDKLmax(θold,θ)≤δ
需要注意的是,因为有无穷多的状态,因此约束条件 D K L max ( θ o l d , θ ) D_{KL}^{\max}\left(\theta_{old},\theta\right) DKLmax(θold,θ) 有无穷多个。问题不可解。
TRPO第三个技巧
在约束条件中,利用平均KL散度代替最大KL散度,即:
s u b j e c t t o D ˉ K L ρ θ o l d ( θ o l d , θ ) ≤ δ subject\ to~~~\bar{D}_{KL}^{\rho_{\theta_{old}}}\left(\theta_{old},\theta\right)\le\delta subject to DˉKLρθold(θold,θ)≤δ
TRPO第四个技巧
s ∼ ρ θ o l d → s ∼ π θ o l d s~\sim\rho_{\theta_{old}}\rightarrow s~\sim\pi_{\theta_{old}} s ∼ρθold→s ∼πθold
最终TRPO问题化简为:
m a x i m i z e θ E s π θ o l d , a π θ o l d [ π θ ( a ∣ s ) π θ o l d ( a ∣ s ) A θ o l d ( s , a ) ] s u b j e c t t o E s π θ o l d [ D K L ( π θ o l d ( ⋅ ∣ s ) ∣ ∣ π θ ( ⋅ ∣ s ) ) ] ≤ δ maximize_{\theta}E_{s~\pi_{\theta_{old}},a~\pi_{\theta_{old}}}\left[\frac{\pi_{\theta}\left(a|s\right)}{\pi_{\theta_{old}}\left(a|s\right)}A_{\theta_{old}}\left(s,a\right)\right] \\ subject\ to\ E_{s~\pi_{\theta_{old}}}\left[D_{KL}\left(\pi_{\theta_{old}}\left(\cdot |s\right)||\pi_{\theta}\left(\cdot |s\right)\right)\right]\le\delta maximizeθEs πθold,a πθold[πθold(a∣s)πθ(a∣s)Aθold(s,a)]subject to Es πθold[DKL(πθold(⋅∣s)∣∣πθ(⋅∣s))]≤δ
2. PPO
PPO是基于Actor-Critic架构实现的一种策略算法, 属于TRPO的进阶版本。

PPO1
PPO1对应的 Policy 更新公式为:
L K L P E N ( θ ) = E ^ t [ π θ ( a t ∣ s t ) π θ old ( a t ∣ s t ) A ^ t − β K L [ π θ old ( ⋅ ∣ s t ) , π θ ( ⋅ ∣ s t ) ] ] L^{K L P E N}(\theta)=\hat{\mathbb{E}}_{t}\left[\frac{\pi_{\theta}\left(a_{t} | s_{t}\right)}{\pi_{\theta_{\text { old }}}\left(a_{t} | s_{t}\right)} \hat{A}_{t}-\beta \mathrm{KL}\left[\pi_{\theta_{\text { old }}}\left(\cdot | s_{t}\right), \pi_{\theta}\left(\cdot | s_{t}\right)\right]\right] LKLPEN(θ)=E^t[πθ old (at∣st)πθ(at∣st)A^t−βKL[πθ old (⋅∣st),πθ(⋅∣st)]]
在TRPO里,我们希望θ和θ’不能差太远,这并不是说参数的值不能差太多,而是说,输入同样的state,网络得到的动作的概率分布不能差太远。为了得到动作的概率分布的相似程度,可以用KL散度来计算。
PPO1算法的思想很简单,既然TRPO认为在惩罚的时候有一个超参数 β β β难以确定,因而选择了限制而非惩罚。因此PPO1通过下面的规则来避免超参数的选择而自适应地决定 β β β:
Compute d = E ^ t [ K L [ π θ o l d ( ⋅ ∣ s t ) , π θ ( ⋅ ∣ s t ) ] ] d=\hat{\mathbb{E}}_{t}\left[\mathrm{KL}\left[\pi_{\theta_{\mathrm{old}}}\left(\cdot | s_{t}\right), \pi_{\theta}\left(\cdot | s_{t}\right)\right]\right] d=E^t[KL[πθold(⋅∣st),πθ(⋅∣st)]]
If d < d t a r g / 1.5 , β ← β / 2 d
If d > d t a r g × 1.5 , β ← β × 2 d>d_{\mathrm{targ}} \times 1.5, \beta \leftarrow \beta \times 2 d>dtarg×1.5,β←β×2
PPO2
除此之外,原论文中还提出了另一种的方法来限制每次更新的步长,我们一般称之为PPO2,论文里说PPO2的效果要比PPO1要好,所以我们平时说PPO都是指的是PPO2,PPO2的思想也很简单,思想的起点来源于对表达式的观察。
首先做出如下定义:
r t ( θ ) = π θ ( a t ∣ s t ) π θ old ( a t ∣ s t ) , r_{t}(\theta)=\frac{\pi_{\theta}\left(a_{t} | s_{t}\right)}{\pi_{\theta_{\text { old }}}\left(a_{t} | s_{t}\right)}, rt(θ)=πθ old (at∣st)πθ(at∣st), so r ( θ old ) = 1 r\left(\theta_{\text { old }}\right)=1 r(θ old )=1
对应的 Policy 更新公式为:
L C L I P ( θ ) = E ^ t [ min ( r t ( θ ) A ^ t , clip ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ t ) ] L^{C L I P}(\theta)=\hat{\mathbb{E}}_{t}\left[\min \left(r_{t}(\theta) \hat{A}_{t}, \operatorname{clip}\left(r_{t}(\theta), 1-\epsilon, 1+\epsilon\right) \hat{A}_{t}\right)\right] LCLIP(θ)=E^t[min(rt(θ)A^t,clip(rt(θ),1−ϵ,1+ϵ)A^t)]
在这种情况下可以保证两次更新之间的分布差距不大,防止了 θ θ θ更新太快。
PPO算法流程

参考文献:
[1] Trust Region Policy Optimization
[2] Proximal Policy Optimization Algorithms
[3] https://zhuanlan.zhihu.com/p/26308073
[4] https://www.jianshu.com/p/f4d383b0bd4c