python爬虫系列——拉勾网
小白入门——拉勾网的爬取与分析
文章目录
- 小白入门——拉勾网的爬取与分析
- 实现的内容
- 准备工作
- 分析拉勾网
- 存储数据
- 拉沟数据爬取与存储完整代码
- 拉勾网爬取及数据存储截图
- 拉勾网爬取错误解决
- 邮件发送
- 邮箱发送效果展示
- 数据分析与画图
- 数据画图效果图
- 个人总结
实现的内容
我的拉勾网爬取实现了四个部分:
- 根据特定城市(可为全国)及职位搜索有关工作信息
- 信息存到excel中通过邮箱发送给多个人
- 信息存到csv中展示及绘图分析
- 爬取的信息进行数据分析
准备工作
需要导入的库函数:
- requests库:用于网络请求
- json库:用于解码JSON对象,如果请求成功则数据解析为字典
- lxml库:用里面的etree中的xpath爬取详细界面的信息
- time库:爬取一个网页的界面后需要休息一下
- xlsxwriter库:用里面的BookWriter对象创建sheet把爬取的内容存到excel中
- pandas库:用里面的DataFrame数据结构把爬取的内容存为csv或者excel,方便展示及绘图
- matplotlib库中的pylab及pyplot库:pylab用于中文的显示,pyplot用于绘制柱状图,饼图,直方图等
- wordcloud库:用于绘制工作薪资的词云
- jieba库:把字符串剪切为单词
- pyecharts:用于绘制全国地图及城市地图岗位的分布
这些第三方库都可以直接在cmd命令行用
pip install xxx 导入
或者直接到http://www.lfd.uci.edu/~gohlke/pythonlibs/
下载需要的库后 pip install 路径+刚才下载的包名,然后再复制到python的lib文件夹下面
分析拉勾网
首先进入拉勾网网页界面,搜索python,我们就可以看到很多与python有关的职位


然后我们右击–>查看网页源代码,然后
任意复制有关工作,在刚才网页源代码界面ctrl+F然后ctrl+v搜索该职位
emmm~~发现没有该职位信息

说明职位信息并不是我们在请求那个网页的url时候一起返回过来的,而是通过ajax请求另一个接口,请求回来后再通过json把信息装在我们请求的那个url界面
那么我们开始分析数据是从哪里来的:
F12后刷新网页,可获取当前请求页面的所有信息,然后我们搜索一下json,可以看到一个positionAjax.json

展开后可以清楚的看到:

继续展开:

可以清楚的看到我们要爬取的所有内容
然后我们来看一下Headers


那么我们就可以开始写代码了
import requests
def request_list_page():
url = 'https://www.lagou.com/jobs/positionAjax.json?city=%E6%88%90%E9%83%BD&needAddtionalResult=false'
headers = {
'Cookie': '_ga=GA1.2.2101330740.1538397506; user_trace_token=20181001203828-e5f6c644-c576-11e8-a884-525400f775ce; LGUID=20181001203828-e5f6ca9b-c576-11e8-a884-525400f775ce; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%22166bd8c1893be-05de032d74790c-8383268-1327104-166bd8c18941dc%22%2C%22%24device_id%22%3A%22166bd8c1893be-05de032d74790c-8383268-1327104-166bd8c18941dc%22%7D; index_location_city=%E6%88%90%E9%83%BD; LG_LOGIN_USER_ID=84b4472d8a08799f4a267d9036e1bbd17060526c54974cf38f7355f84eceea94; showExpriedIndex=1; showExpriedCompanyHome=1; showExpriedMyPublish=1; hasDeliver=0; WEBTJ-ID=20181201104916-16767ab926c193-0369c48aea69e8-8383268-1327104-16767ab926dc9; _gid=GA1.2.584755814.1543632557; LGSID=20181201104918-b294f2cc-f513-11e8-8850-525400f775ce; _putrc=4C83FA4867F6CC19123F89F2B170EADC; JSESSIONID=ABAAABAAADEAAFI17A098919E7E1868242B81BDB95A0C0D; login=true; unick=%E7%8E%8B%E4%BA%91%E5%80%A9; _gat=1; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1543632557,1543633278,1543634699,1543634962; gate_login_token=645b9ef09fbb80ea283a99868ede6b367404ca7a3f8a661bc32d75e0edbb4faa; TG-TRACK-CODE=index_navigation; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1543634987; LGRID=20181201112948-5adc2724-f519-11e8-8ca7-5254005c3644; SEARCH_ID=c4709190d9844b1883a0b566c5c467e9',
'Referer': 'https://www.lagou.com/jobs/list_python?city=%E6%88%90%E9%83%BD&cl=false&fromSearch=true&labelWords=&suginput=',
'Origin': 'https: // www.lagou.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36',
'X-Anit-Forge-Code': '0',
'X-Anit-Forge-Token': 'None',
'X-Requested-With': 'XMLHttpRequest'
}
data = {
'first': 'false',
'pn': '1',
'kd': 'python'
}
response = requests.post(url,headers=headers,data=data)
print(response.json())
def main():
request_list_page()
if __name__=='__main__':
main()
![]()

可以看出我们的结果和response结果一样,说明第一页内容获取成功!!!
值得注意的是拉勾网反爬虫很厉害,所以我们尽量把headers中的所有内容都复制进去,比如我有此就只复制了User-Agent及Reference
import requests
def request_list_page():
url = 'https://www.lagou.com/jobs/positionAjax.json?city=%E6%88%90%E9%83%BD&needAddtionalResult=false'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36',
'Referer': 'https://www.lagou.com/jobs/list_python?city=%E6%88%90%E9%83%BD&cl=false&fromSearch=true&labelWords=&suginput='
}
data = {
'first': 'false',
'pn': '1',
'kd': 'python'
}
response = requests.post(url,headers=headers,data=data)
print(response.json())
def main():
request_list_page()
if __name__=='__main__':
main()
就会显示下面内容,emmm…其实不是操作频繁,就是拉勾的反爬虫机制


所以我们每次请求3页,4页我们就修改pn就可以了,然后first直接全部修改为false,因为如果我们从第二页回到第一页的话,那么第一页也就是false了,第一页

呜呜呜呜~~直接这个样子一次性爬取是有问题的,就是因为这个原因,我的ip号被拉沟网拉进了黑名单,花了我整整10个人民币才解放出来,5555555…如下图:

因为for循环走的很快,基本1s就会发送好几个请求,所以请求的太快拉沟网就会提示我们操作的太频繁,所以我们请求一个页面后要稍微停一下。

要爬取所有页面我们首先要知道总共的页数:

在preview中我们可以知道他的总职位的个数及每一页都只有15个职位,所以直接用totalCount/15向上取整就可以得到总页数,值得注意的是,拉勾网最多只显示30页的招聘信息,所以代码如下:
def get_page_num(counts):
nums=math.ceil(counts/15)
if(nums>30):
return 30
else:
return nums
好了,现在我们就可以开始爬取职位的详细页面了

在这个界面我们就可以爬取公司名,公司简称,公司规模,融资阶段,城市,区域,职位名称,职位链接,工作经验,学历要求,薪资,职位福利就都可以爬取了,但这个界面没有职位诱惑等信息,所以我们需要跳转到每个职位的详细界面,然后我们看到这个界面的第0个里面的positionID为5151256

然后我们点进拉勾网界面的第一个招聘工作

所以我们找详细界面就通过positonID来跳转

成功爬取

所以现在我们进入详细页面,F12

好了,到这里你就可以根据自己心情随意爬取啦,嘿嘿嘿嘿嘿。。。可以用etree.xpath通过class=job_bt然后text()来简单获取职位描述
存储数据
- 数据存到excel中:
(1)先在D盘创建一个名为caogao的文件夹,引入与excel有关的头文件xlsxwriter先在D盘创建一个名为caogao的文件夹,引入与excel有关的头文件xlsxwriter
(2)创建一个Workbook对象
(3)用add_worksheet()添加一个sheet
(4)用write_row或write_colum往sheet中添加数据
(5)关闭掉sheet
import xlsxwriter
def save_excel(file_name): # 将抓取到的招聘信息存储到excel当中
job = xlsxwriter.Workbook(r'D:\caogao\%s.xls' % file_name)
tmp = job.add_worksheet()
row_num = len(fin_result)
for i in range(1, row_num):
if i == 1:
tag_pos = 'A%s' % i
tmp.write_row(tag_pos, tag_name)
else:
con_pos = 'A%s' % i
content = fin_result[i - 1] # -1是因为被表格的表头所占
tmp.write_row(con_pos, content)
job.close()
- 存到csv中:直接用pandas中的DataFrame(DataFrame就是一个表格型数据结构),然后df.to_csv就可以把数据存在csv中了,当然也可以直接用df.to_excel把数据存到excel中,和上面那种用xlswriter.Workbook实例来add_worksheet()方法来创建一个sheet方法,用pandas更方便啦,一步到位,还不用关闭sheet对象哦。
到这里数据爬取就算完成啦(但我的爬取界面是默认为成都),那么如果我想要爬取输入的城市的对应工作职位呢?

from urllib.parse import quote
a='成都'
print(quote(a))

通过这个代码我们就可以把用户输入的中文转换为编码并且传给请求头的url中。到这里,我们就可以根据不同城市请求不同的工作职位的信息啦~~
拉沟数据爬取与存储完整代码
from urllib.parse import quote
import requests
from lxml import etree
import math
import time
import xlsxwriter
import pandas as pd
tag_name = ['公司名称', '公司简称','公司规模','融资阶段','城市','区域','职位名称','职位链接', '工作经验', '学历要求','兼职/全职' ,'薪资','职位福利','职位详述']
fin_result = [[] for i in range(30)]
headers = {
'Cookie': '_ga=GA1.2.2101330740.1538397506; user_trace_token=20181001203828-e5f6c644-c576-11e8-a884-525400f775ce; LGUID=20181001203828-e5f6ca9b-c576-11e8-a884-525400f775ce; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%22166bd8c1893be-05de032d74790c-8383268-1327104-166bd8c18941dc%22%2C%22%24device_id%22%3A%22166bd8c1893be-05de032d74790c-8383268-1327104-166bd8c18941dc%22%7D; index_location_city=%E6%88%90%E9%83%BD; LG_LOGIN_USER_ID=84b4472d8a08799f4a267d9036e1bbd17060526c54974cf38f7355f84eceea94; showExpriedIndex=1; showExpriedCompanyHome=1; showExpriedMyPublish=1; hasDeliver=0; WEBTJ-ID=20181201104916-16767ab926c193-0369c48aea69e8-8383268-1327104-16767ab926dc9; _gid=GA1.2.584755814.1543632557; LGSID=20181201104918-b294f2cc-f513-11e8-8850-525400f775ce; _putrc=4C83FA4867F6CC19123F89F2B170EADC; JSESSIONID=ABAAABAAADEAAFI17A098919E7E1868242B81BDB95A0C0D; login=true; unick=%E7%8E%8B%E4%BA%91%E5%80%A9; _gat=1; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1543632557,1543633278,1543634699,1543634962; gate_login_token=645b9ef09fbb80ea283a99868ede6b367404ca7a3f8a661bc32d75e0edbb4faa; TG-TRACK-CODE=index_navigation; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1543634987; LGRID=20181201112948-5adc2724-f519-11e8-8ca7-5254005c3644; SEARCH_ID=c4709190d9844b1883a0b566c5c467e9',
'Referer': 'https://www.lagou.com/jobs/list_python?city=%E6%88%90%E9%83%BD&cl=false&fromSearch=true&labelWords=&suginput=',
'Origin': 'https: // www.lagou.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36',
'X-Anit-Forge-Code': '0',
'X-Anit-Forge-Token': 'None',
'X-Requested-With': 'XMLHttpRequest'
}
def request_list_page(city_name,keyword,num):
city_code=quote(city_name)
if(city_name=='全国'):
url='https://www.lagou.com/jobs/positionAjax.json?px=default&needAddtionalResult=false'
else:
url='https://www.lagou.com/jobs/positionAjax.json?px=default&city=%s&needAddtionalResult=false'%city_code
# print(url)
data={
'first':'false',
'pn':num,
'kd':keyword
}
response=requests.post(url,headers=headers,data=data)
response.raise_for_status()
response.encoding='utf-8'
result=response.json()
# print(result.text)
return result
def get_page_num(counts):
nums=math.ceil(counts/15)
if(nums>30):
return 30
else:
return nums
def get_page_info(city,keyword,num):
job = xlsxwriter.Workbook(r'D:\caogao\%s.xls' % keyword)
tmp=job.add_worksheet()
tmp.write_row('A1',tag_name)
ind = 2
total_inf=[]
for x in range(1,num+1):
page=request_list_page(city,keyword,x)
positions = page['content']['positionResult']['result']
page_info_list=[]
for position in positions:
page_info = []
page_info.append(position['companyFullName'])
page_info.append(position['companyShortName'])
page_info.append(position['companySize'])
page_info.append(position['financeStage'])
page_info.append(position['city'])
page_info.append(position['district'])
page_info.append(position['positionName'])
position_id = position['positionId']
position_url = 'https://www.lagou.com/jobs/%s.html' % position_id
page_info.append(position_url)
page_info.append(position['workYear'])
page_info.append(position['education'])
page_info.append(position['jobNature'])
page_info.append(position['salary'])
page_info.append(position['positionAdvantage'])
page_info.append(position_detail(position_url))
con_pos='A%s'%ind
tmp.write_row(con_pos,page_info)
ind+=1
page_info_list.append(page_info)
time.sleep(1)
if(x==4):
break
print("第{}页已经抓取完成".format(x))
total_inf += page_info_list
time.sleep(4)
df = pd.DataFrame(data=total_inf,columns=tag_name)
df.to_excel(city+'_'+keyword+'.xls')
df.to_csv(city+'_'+keyword+'.csv',index=False)
print("已保存为csv文件")
job.close()
def position_detail(url):
response=requests.get(url,headers=headers)
text=response.text
html=etree.HTML(text)
desc="".join(html.xpath("//dd[@class='job_bt']//text()")).strip()
return desc
if __name__ == '__main__':
city=input("请输入你要查找的城市:")
keyword = input('请输入您要搜索的语言类型:')
page_1=request_list_page(city,keyword,1)
total_page = page_1['content']['positionResult']['totalCount']
num = get_page_num(total_page)
print("共找到:{}条招聘信息,显示为{}页".format(total_page, num))
result=get_page_info(city,keyword,num)
拉勾网爬取及数据存储截图


![]()

拉勾网爬取错误解决
- 拉勾网有反爬虫机制,所以我们一定要有一个请求头,如果怕出错和不知道应该拿去头中的那些内容,就把Headers中的所有内容写在请求头中。不然会报下面错误:

- 请求每个界面和工作的时候必须time.sleep几秒,因为for循环走的很快,每秒都会发送好几个请求,所以请求的太快拉沟网就会提示我们操作的太频繁,和上图一样。这一个一定要注意,如果这样不暂停请求你的IP可能会被拉黑。当你发现你连拉勾网的网页都进不去的时候,恭喜你,被拉勾网拉黑了,那么你现在就只能去淘宝花费10RMB买个代理IP或者等候拉勾网心情好的时候把你放出来。。。
- 用DateFrame中的df.read_csv时,读取的csv文件名不能含有中文,否则会报错:

如果非要含中文,就必须用df=pd.read_csv(open(csv文件名,‘rb’),encoding=‘utf-8’)
邮件发送
说到图片发送简直是一把辛酸泪啊,从头弄到尾,整整历经了2个星期,基本把邮件发送各部分的错误都挨个犯完了,55555。。。。

- 首先发送邮件方要设置一个授权码,我是用的163邮箱
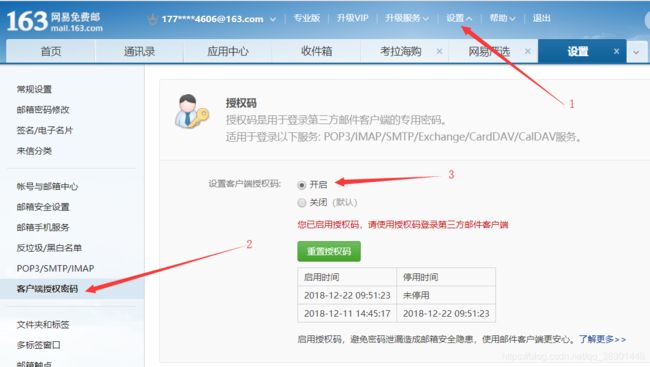
- 我用的是第三方SMTP服务规则发送的邮件,所有遵循他的规则。
(1) 第三方SMTP服务需要host:163邮箱的为:smtp.163.com;需要user:就是我们邮箱发件方的账号;需要密码:授权码;接收方:接受方的邮件
(2)邮件正文:message[‘From’],message[‘TO’],message[‘Subject’]三者缺一不可
(3)邮件正文内容:用attach
(4)带附件:设置MIMEMultipart为mixed,加入你的附件的类型和附件,然后attach就可以了
(5)最后就连接发送邮件
import smtplib
from email.mime.text import MIMEText
from email.mime.multipart import MIMEMultipart
from email.header import Header
sender = '[email protected]'
#发送给一个邮箱
receiver='[email protected]'
#接受邮件,可设置为你的QQ邮箱或者其他邮箱,多接收方
receivers = ['xxx','xxx']
# 第三方 SMTP 服务
mail_host = 'smtp.163.com'
mail_user = '[email protected]'
mail_pass = 'xxxxxxxxxxx'
to_mail = ['xxx', 'xxx']
# 创建一个带附件的实例
message = MIMEMultipart('mixed')
message['From'] = '[email protected]'
#接收方为一个
# message['To'] = 'xxx'
#接收方为多人
message['To'] = ','.join(to_mail)
subject = 'hello'
# message['Subject'] = Header(subject, 'utf-8')
# 邮件正文内容
message.attach(MIMEText('信息', 'plain', 'utf-8'))
# 构造附件1,传送当前目录下的 hello.txt 文件
att1 = MIMEText(open('hello.txt', 'rb').read(), 'base64', 'utf-8')
att1["Content-Type"] = 'application/octet-stream'
# 这里的filename可以任意写,写什么名字,邮件中显示什么名字
att1["Content-Disposition"] = 'attachment; filename="hello.txt"'
message.attach(att1)
smtpObj = smtplib.SMTP()
smtpObj.connect(mail_host, 25) # 25 为 SMTP 端口号
smtpObj.ehlo()
smtpObj.starttls()
smtpObj.login(mail_user, mail_pass)
smtpObj.sendmail(message['From'],
#发送给多分
message['To'].split(','), message.as_string())
#发送给一方
# smtpObj.sendmail(message['From'], message['To'], message.as_string())
print("邮件发送成功")
3.来说说辛酸史,邮件发送过程中各种错误:
(1)message['from']与message['to']这两个中不能直接写[email protected]这种形式,不然一直报错554:发件人和收件人信息不匹配。比如把qq邮箱前面的qq名字一起加上去,如下第二张图。然后
smtp.sendmail('[email protected]', '[email protected]', msg.as_string())
必须和
msg['From'] = '[email protected]'
msg['To'] = '[email protected]'
内容对应相同
![]()

(2)主机强迫关闭了一个现有的连接

这时你需要在邮件登录前加上两句:
smtpObj.ehlo()
smtpObj.starttls()
(3)还是554,但是这个就是邮件中包含了某些信息被当做垃圾邮件处理了。特别注意的是我们的主题
message['Subject']
绝对不能为test,不然会一直554到死,呜呜呜呜~~
(4)553邮件发送方没有开始授权
(5)最气人的一点,感觉自己代码完全没错误了,但是还是554,我的心里毫无波折,甚至还有点想笑。。。听别人说用手机开热点就好了,然后自己开开心心用手机连上了热点,结果还是554,好吧,我能怎么办,我也很无奈啊。然后又找了一个星期,老师也被我烦了很多遍,好吧,还是没错误。好气哦,但是不能放弃啊,最后,我灵机一动,让室友给我开了一个wifi,然后,邮箱就发出去了,what???好吧,我只能说服自己是上天嫉妒我的美貌,然后为期两个星期的邮件终于发送出去了。。。所以,当你感觉自己完全没有错误的时候,让小伙伴给你开个wifi吧。
邮箱发送效果展示
qq邮箱接收方效果展示:



163邮箱接收方效果:





数据分析与画图
数据清洗
(1) 求工作薪资的时候要把实习的数据项去掉,用平均工资表示工资区间
(2) 画中国地图的时候,有些city为国外,要提前去除
展现matplotlib及wordcloud强大的时候到了
(1)用pandas读取存在csv中的数据
(2)由于csv文件内的数据是字符串形式,所以我们先用正则表达式将字符串转化为列表,再取区间的均值
(3)用matplotlib中的pylab的hist绘制直方图,用pie绘制饼图
(4)用jieba模块将字符串分割为单词,再用WordCloud加载词云
数据画图代码
import pandas as pd
import matplotlib.pyplot as plt
from wordcloud import WordCloud
import jieba
import matplotlib.pylab as mpl
from pyecharts import Map,Geo
def data_analysis(city,position):
#使matplotlib模块能显示中文
mpl.rcParams['font.sans-serif']=['SimHei'] # 指定默认字体
mpl.rcParams['axes.unicode_minus']=False # 解决保存图像是负号'-'显示为方块的问题
#读取数据
str=city+'_'+position+'.csv'
print(str)
# df=pd.read_csv(str)
df=pd.read_csv(open(str,'rb'),encoding='utf-8')
# df=pd.read_csv('php.csv',encoding='utf-8')
# #数据清洗,剔除实习岗位
df.drop(df[df['职位名称'].str.contains('实习')].index,inplace=True)
# print("=" * 40)
# print(df.describe())
# print("=" * 40)
# 由于CSV文件内的数据是字符串形式,先用正则表达式将字符串转化为列表,再取区间的均值
pattern = '\d+'
df['工作年限'] = df['工作经验'].str.findall(pattern)
avg_work_year = []
for i in df['工作年限']:
# 如果工作经验为'不限'或'应届毕业生',那么匹配值为空,工作年限为0
if len(i) == 0:
avg_work_year.append("不限")
# 如果匹配值为一个数值,那么返回该数值
elif len(i) == 1:
avg_work_year.append(int(''.join(i)))
# 如果匹配值为一个区间,那么取平均值
else:
num_list = [int(j) for j in i]
avg_year = sum(num_list) / 2
#num_temp=num_list[0]+'-'+num_list[1]
#print(num_temp)
avg_work_year.append(avg_year)
df['经验'] = avg_work_year
count = df['工作经验'].value_counts()
plt.pie(count, labels=count.keys(), labeldistance=1.4, autopct='%2.2f%%')
plt.axis('equal') # 使饼图为正圆形
plt.legend(loc='upper left', bbox_to_anchor=(-0.1, 1))
plt.savefig('pie_chart.jpg')
plt.show()
# 将字符串转化为列表,再取区间的前25%,比较贴近现实
df['salary'] = df['薪资'].str.findall(pattern)
avg_salary = []
for k in df['salary']:
int_list = [int(n) for n in k]
if(len(int_list)==1):
avg_wage=int_list[0]
else:
avg_wage = int_list[0] + (int_list[1] - int_list[0]) / 4
# avg_wage2=(int_list[0]+int_list[1])/2
avg_salary.append(avg_wage)
df['月工资']=avg_salary
# 将清洗后的数据保存,以便检查
df.to_csv('draft.csv', index=False)
#描述职位
print('php工资描述:\n{}'.format(df['月工资'].describe()))
# 绘制频率直方图并保存
plt.hist(df['月工资'], bins=12)
plt.xlabel('工资 (千元)')
plt.ylabel('频数')
plt.title("工资直方图")
plt.savefig('salary_histogram.jpg')
plt.show()
# 绘制饼图并保存
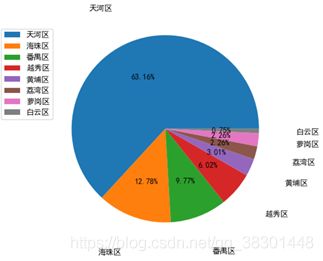
count = df['区域'].value_counts()
plt.pie(count, labels=count.keys(), labeldistance=1.4, autopct='%2.2f%%')
plt.axis('equal') # 使饼图为正圆形
plt.legend(loc='upper left', bbox_to_anchor=(-0.1, 1))
plt.savefig('pie_chart.jpg')
plt.show()
# 省地图 数据必须是省内放入城市名
map2 = Map("{}{}分布".format(city,position), city, width=1200, height=600)
data=df['区域'].value_counts()
citys=list(data.index)
values=list(data[data.index])
print("="*40)
print(citys)
print(values)
map2.add(city, citys, values, visual_range=[1, 4], maptype=city, is_visualmap=True, visual_text_color='#000')
# map2.show_config()
map2.render(path="04-02{}{}职位分布图.html".format(city,position))
# 绘制词云,将职位福利中的字符串汇总
text = ''
for line in df['职位福利']:
text += line
# 使用jieba模块将字符串分割为单词列表
cut_text = ' '.join(jieba.cut(text))
# print(cut_text)
color_mask = plt.imread('boy2.jpg') # 设置背景图
print('加载图片成功!')
cloud = WordCloud(
font_path='xingkai.ttf',
background_color='white',
mask=color_mask,
max_words=1000,
max_font_size=100,
)
word_cloud = cloud.generate(cut_text)
# 保存词云图片
word_cloud.to_file('word_cloud.jpg')
plt.imshow(word_cloud)
plt.axis('off')
plt.show()
def data_analysis_all(city,position):
# 使matplotlib模块能显示中文
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
str = city + '_' + position + '.csv'
# df=pd.read_csv(str)
df = pd.read_csv(open(str, 'rb'), encoding='utf-8')
df['salary'] = df['薪资'].str.findall("\d+")
avg_salary = []
for k in df['salary']:
int_list = [int(n) for n in k]
if(len(int_list)==1):
avg_wage=int_list[0]
else:
avg_wage = int_list[0] + (int_list[1] - int_list[0]) / 4
# avg_wage2=(int_list[0]+int_list[1])/2
avg_salary.append(avg_wage)
df['月工资']=avg_salary
group_by_city = df.groupby(['城市'])['月工资']
# print(group_by_city)
list_salary=[]
list_city=[]
for group in group_by_city:
salarys=group[1].values
sum=0
for k in salarys:
sum+=k
list_salary.append(sum/len(group[1]))
list_city.append(group[0])
print(list_salary)
# plt.bar(list_city[0:20],list_salary[0:20],width=0.3,facecolor='blue', edgecolor='white')
# plt.bar( list_city[0:20], list_salary[0:20],width=0.3, facecolor='blue', edgecolor='white')
plt.barh(list_city, list_salary,facecolor='lightskyblue', edgecolor='white')
plt.savefig('101全国城市工资')
plt.show()
# 工资柱状图
data = df['薪资'].value_counts()
print("=" * 40)
attr = list(data.index)
values = list(data[attr])
attr=attr[0:11]
values=values[0:11]
print(attr)
print(values)
plt.bar(attr, values, width=0.5, facecolor='lightskyblue', edgecolor='white', label='全国前十{}工资'.format(position))
plt.legend(loc='upper right')
plt.grid(axis=1)
plt.show()
# 学历折线图
data = df['学历要求'].value_counts()
print(data)
plt.plot(data)
plt.show()
#数据清洗
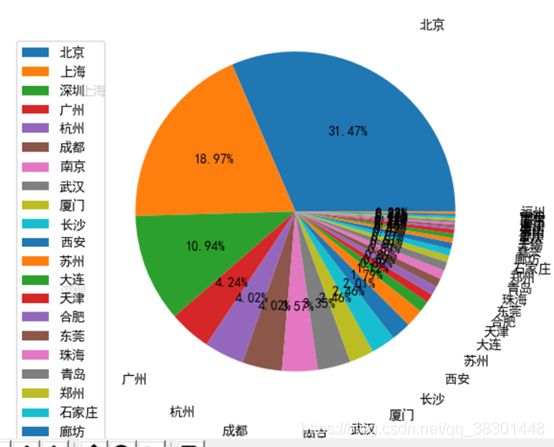
df.drop(df[df['城市'].str.contains('海外')].index, inplace=True)
data=df['城市'].value_counts()
# 绘制饼图并保存
print(data.keys())
plt.pie(data, labels=data.keys(), labeldistance=1.4, autopct='%2.2f%%')
plt.axis('equal') # 使饼图为正圆形
plt.legend(loc='upper left', bbox_to_anchor=(-0.1, 1))
plt.savefig('04全国工作分布pie_char.jpg')
plt.show()
attr=list(data.index)
print("=" * 40)
value = list(data[data.index])
print(attr)
geo=Geo('全国城市{}工作数分析'.format(position),'制作人:王云倩',title_color="#fff", title_pos="center", width=1200, height=600,background_color='#404a59')
print(value)
geo.add("", attr, value, visual_range=[0, 10], type='effectScatter', visual_text_color="#fff", symbol_size=15,
is_visualmap=True, is_roam=False)
# geo.add("", attr, value, visual_range=[0, 10], type='heatmap', visual_text_color="#fff", symbol_size=15,is_visualmap=True, is_roam=False)
geo.render(path="102拉沟职位全国{}分布图.html".format(position))
if __name__ == '__main__':
city = input("请输入你要分析的城市:")
position = input("请输入你要分析的职位名称:")
if(city=='全国'):
data_analysis_all(city,position)
else:
data_analysis(city,position)
数据画图效果图


工作经验饼图







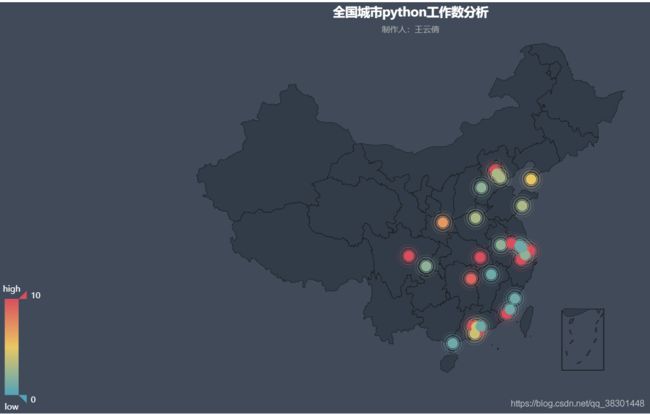
个人总结
这次拉勾网的爬取收获也颇多,也挺心累的,特别是邮件发送,搞得自己差点崩溃,该查的资料都查了,百度看了很多人的分析,但就是没有一个可以解决自己的问题。不过也挺开心的,学到了很多,数据分析方面感觉自己还差很多,不怎么会,都是看着别人的学的,不过最后可以画出一个帅哥的词云看着超级开心呢,然后还有画图,数据清理等也弄得我脑袋痛,不过最后看到画面展示,感觉挺有成就的,总算没有辜负自己的付出。嘿嘿嘿~~就算小白入门吧,希望自己以后可以更上一层楼,Fighting,python,请多指教啦!
