卡顿和卡死监控
卡顿原因
主要是主线程阻塞。在开发过程中,遇到的造成主线程阻塞的原因可能是:
- 主线程在进行大量I/O操作:为了方便代码编写,直接在主线程去写入大量数据
- 主线程在进行大量计算:代码编写不合理,主线程进行复杂计算
- 大量UI绘制:界面过于复杂,UI绘制需要大量时间
- 主线程在等锁:主线程需要获得锁A,但是当前某个子线程持有这个锁A,导致主线程不得不等待子线程完成任务。
- …
业界调研
微信团队(Matrix)
卡顿检测流程图

主线程卡顿表现
- FPS降低
- CPU占用率非常高
- 主线程RunLoop执行时间过长
监控方法
Matrix 卡顿监控在 RunLoop 的起始最开始和结束最末尾位置添加 Observer,从而获得主线程的开始和结束状态。卡顿监控起一个子线程定时检查主线程的状态,当主线程的状态运行超过一定阈值则认为主线程卡顿,从而标记为一个卡顿。
采用两个准则:
- 单核CPU 占用超过了80%
- 主线程 RunLoop 执行了超过2秒
微信公开使用的卡顿监控中,主程序 Runloop 超时的阈值是 2 秒,子线程的检查周期是 1 秒,每隔 1 秒,子线程检查主线程的运行状态
如果检查到主线程 Runloop 运行超过 2 秒则认为是卡顿,并获得当前的线程快照。同时,微信团队也认为 CPU 过高也可能导致应用出现卡顿,所以在子线程检查主线程状态的同时,如果检测到 CPU 占用过高,会捕获当前的线程快照保存到文件中
目前微信应用中认为,单核 CPU 的占用超过了 80%,此时的 CPU 占用就过高了
检测策略
- 内存 dump:每1秒检查一次,如果检查到主线程卡顿,就将所有线程的函数调用堆栈 dump 到内存中
- 文件 dump:如果内存 dump 的堆栈跟上次捕捉到的不一样,则 dump 到文件中;否则按照斐波那契数列将检查时间递增(1,1,2,3,5,8…)直到没有遇到卡顿或卡顿堆栈不一样。这样能够避免同一个卡顿写入多个文件的情况,也能避免检测线程围着同一个卡顿空转的情况
退火算法
为了降低检测带来的性能损耗,为检测线程增加了退火算法:
- 每次子线程检查到主线程卡顿,会先获得主线程的堆栈并保存到内存中(不会直接去获得线程快照保存到文件中);
- 将获得的主线程堆栈与上次卡顿获得的主线程堆栈进行比对:
- 如果堆栈不同,则获得当前的线程快照并写入文件中;
- 如果相同则会跳过,并按照斐波那契数列将检查时间递增直到没有遇到卡顿或者主线程卡顿堆栈不一样。
这样,可以避免同一个卡顿写入多个文件的情况;避免检测线程遇到主线程卡死的情况下,不断写线程快照文件。
耗时堆栈提取
子线程检测到主线程 Runloop 时,会获得当前的线程快照当做卡顿文件,但当前的主线程堆栈不一定是最耗时的堆栈,不一定是导致主线程超时的主要原因。Matrix 卡顿监控通过主线程耗时堆栈提取来解决这个问题
卡顿监控定时获取主线程堆栈,并将堆栈保存到内存的一个循环队列中。如下图,每间隔时间 t 获得一个堆栈,然后将堆栈保存到一个最大个数为 3 的循环队列中。有一个游标不断的指向最近的堆栈
微信的策略是每隔 50 毫秒获取一次主线程堆栈,保存最近 20 个主线程堆栈。这个会增加 3% 的 CPU 占用,内存占用可以忽略不计
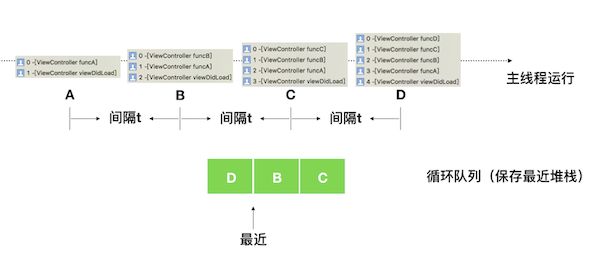
当主线程检测到卡顿时,通过对保存到循坏队列中的堆栈进行回溯,获取最近最耗时堆栈
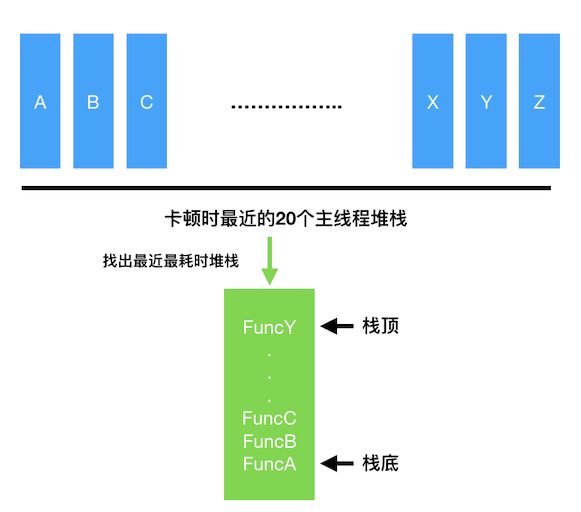
如下图,检测到卡顿时,内存的循环队列中记录了最近的20个主线程堆栈,需要从中找出最近最耗时的堆栈。Matrix 卡顿监控用如下特征找出最近最耗时堆栈:
- 以栈顶函数为特征,认为栈顶函数相同的即整个堆栈是相同的;
- 取堆栈的间隔是相同的,堆栈的重复次数近似作为堆栈的调用耗时,重复越多,耗时越多;
- 重复次数相同的堆栈可能很有多个,取最近的一个最耗时堆栈。
获得的最近最耗时堆栈会附带到卡顿文件中。
卡死检测流程如下
应该是以前 Facebook 的做法,使用排除法
堆栈分类方法
卡顿监控需要仔细定义自己的分类规则。可以是从调用堆栈的最外层开始归类,或者是取中间一部分归类,或者是取最里面一部分归类。各有优缺点:
- 最外层归类:能够将同一入口的卡顿归类起来。缺点是层数不好定,可能外面十来层都是系统调用,也有可能第一层就是微信的函数了。
- 中间层归类:能够根据事先划分好的“特征值”来归类。缺点是“特征值”不好定,如果要做到自动学习生成的话,对后台分析系统要求太高了。
- 最内层归类:能够将同一原因的卡顿归类起来。缺点是同一分类可能包含不同的业务。
微信采用了最内层归类的优化版,亦即进行二级归类。
第一级按照最内倒数2层归类,这样能够将同一原因的卡顿集中起来;
第二级分类是从第一级点击进来,然后从最内层倒数4层进行归类,这样能够将同一原因的不同业务分散归类起来。
可运营
灰度收集到的结果是用户平均每天会产生30个 dump 文件,压缩上传大约要 300k 流量。预计正式发布的话会对后台有比较大的压力,对用户也有一定流量损耗。所以必须进行抽样上报。
- 抽样上报:每天抽取不同的用户进行上报,抽样概率是5%。
- 文件上传:被抽中的用户1天仅上传前20个堆栈文件,并且每次上报会进行多文件压缩上传。
- 白名单:对于需要跟进问题的用户,可以在后台配置白名单,强制上报。
另外,为了减少对用户存储空间的影响,卡顿文件仅保存最近7天的记录,过期删除。
美团Hertz
卡顿检测方法
很容易想到通过检测FPS就可以知道App是否发生了卡顿,也能够通过一段连续的FPS帧数计算丢帧率来衡量当前页面绘制的质量。
然而实践发现FPS的刷新频率非常快,并且容易发生抖动,因此直接通过比较通过FPS来侦测卡顿是比较困难的。而检测主线程消息循环执行的时间就要容易的多了,这也是业内常用的一种检测卡顿的方法
因此,Hertz在实践中采用的就是检测主线程每次执行消息循环的时间,当这一时间大于阈值时,就记为发生一次卡顿。
解决卡顿连续性耗时策略
有的卡顿连续性耗时较长,例如打开新页面时的卡顿;而有的卡顿连续性耗时相对较短但频次较快,例如列表滑动时的卡顿。
因此,采用了“N次卡顿超过阈值T”的判定策略,即一个时间段内卡顿的次数累计大于N时才触发采集和上报:例如卡顿阈值T=2000ms、卡顿次数N=1,可以判定为单次耗时较长的卡顿;而卡顿阈值T=300ms、卡顿次数N=5,可以判定为频次较快的卡顿。
dump堆栈和运行日志
-
第一个问题是堆栈抓取的时机。抓取堆栈的时机必须是在卡顿发生当时,而不是之后,否则不能准确抓到造成卡顿的代码,因此在子线程中当卡顿还没有结束时抓取堆栈
-
第二个问题是堆栈如何归类,卡顿堆栈的归类和Crash堆栈不同,以最内层代码归类显然是不合适的,因为外层不同的业务逻辑代码在最内层的调用堆栈有可能是相同的。以最外层代码归类也是不合适的,因为最外层代码有可能是业务逻辑代码,也有可能是系统调用。采用最内层归类的原则,并匹配一些简单的规则,以命中规则的类名来归类
Bugly
检查卡顿的依据和上报时机(https://bugly.qq.com/docs/user-guide/faq-ios/?v=20180709165613#2)
依据是监控主线程 Runloop 的执行,观察执行耗时是否超过预定阀值(默认阀值为3000ms) ,如果监控到卡顿时会立即记录线程堆栈到本地,在App从后台切换到前台时,执行上报。
Wedjat
如何监控卡顿
- FPS 监控:这是最容易想到的一种方案,如果帧率越高意味着界面越流畅,上文也给出了计算 FPS 的实现方式,通过一段连续的 FPS 计算丢帧率来衡量当前页面绘制的质量。
- 主线程卡顿监控:这是业内常用的一种检测卡顿的方法,通过开辟一个子线程来监控主线程的 RunLoop,当两个状态区域之间的耗时大于阈值时,就记为发生一次卡顿。
同样是采用主线程卡顿监控方案。
MTHawkeye
MTHawkeye是美图开源的卡顿监控,看了源码设计思想跟微信的Matrix差不多,不过有很多技术的沉淀,应该是为美图定制,设计很值得研究。
调研结论
业界大部分的监控方案大同小异,基于监听RunLoop的通知状态,开启常驻子线程定时检测主线程的RunLoop状态切换是否存在超时,超时则记为一次卡顿,当卡顿时长超过设定的阈值dump堆栈,进行相关策略处理之后在合适的时间上报。Matrix为腾讯最新的开源库,其堆栈处理策略较好,目前备受欢迎。
方案对比
FPS
FPS(Frames Per Second)表示页面每秒的帧数,FPS越高表明页面越流畅,值50~60之间是比较流畅的,反之低于会卡顿。FPS通过借助CADisplayLink在一个周期的计数间接表示
例外,根据可滑动界面在滑动状态RunLoop由kCFRunLoopDefaultMode切换成UITrackingRunLoopMode可以区分页面不流畅产生的场景是否在滚动过程
CADisplayLink是以跟IOS设备相同屏幕刷新频率(每秒60帧)的定时器,通过添加一个target和绑定selector,以NSRunLoopCommonModes模式将该定时器注册到RunLoop,屏幕收到每一帧的刷屏通知同时调用target绑定的selector计数操作,获取时间戳大于1秒的计数为当前页面的FPS。
Ping-Pong
实现原理:ping常用于测试网络测试数据包能否到达ip地址进而测试网络应答。当然用来监控卡顿监控,主要的核心思想是开启子线程维护一个ping定时器,通过固定时间片段ping主线程(发送一个通知),如果主线程不是繁忙状态会收到通知并pong回应(回送一个通知给子线程),否则子线程超过设定的pong定时阈值,没有收到主线程pong回复则判定为是卡顿了,然后dump堆栈下来。
监听RunLoop
实现原理:开启一个子线程,监听RunLoop的通知状态,如果在设定的卡顿阈值时间内没有收到RunLoop的通知状态,那么就判定为主线程卡顿了,然后dump堆栈,反之没有卡顿,可以记录卡顿的频次,到达一定的频次再上报。
Hook objc_msgSend方法
oc每个方法的调用最终都是转成objc_msgSend方式通知消息,通过维护一个数据结构统计每个方法的调用时长进行性能分析,但是这样非常损耗性能,维护成本比较高,不推荐使用。
最后,决定采取监听RunLoop的方式,参考Matrix和MTHawkeye。
方案实现
检测流程图

设计与实现
设计原理
在 RunLoop 的起始最开始和结束最末尾位置添加 Observer,从而获得主线程的开始和结束状态的耗时。卡顿监控起一个子线程定时检查主线程的状态(默认200ms),当主线程的状态运行耗时超过一定阈值(默认400ms)则认为主线程卡顿,从而标记为一个卡顿。如果卡顿时长超过8秒,则判定为卡死。卡顿阈值和检测线程的周期直接影响卡顿监控的能力和性能损耗。
堆栈快照
系统提供task_threads方法获取task的所有线程,每一个线程的信息可以通过thread_get_state方法获取到,信息填充在 _STRUCT_MCONTEXT 类型的参数中,通过这个参数可以取到当前线程的Stack Pointer和Frame Pointer,然后回溯整个函数的调用栈找到所有函数的地址,通过偏移计算出物理地址,最后再进行符号化取得函数名。
堆栈去重
采用了退火算法一部分过滤连续相同堆栈
ThreadBacktraceSnapshot *mainBacktraceSnapshot = [self generateBacktraceSnapshot:dumpType];
ThreadBacktraceSnapshot *preSnapshot = self.snapshotsArray.lastObject;
if (preSnapshot) {
if (![preSnapshot.backtraceDescription isEqualToArray:mainBacktraceSnapshot.backtraceDescription]) {
mainBacktraceSnapshot.capturedCount = self.annealingCount;
[self.snapshotsArray addObject:mainBacktraceSnapshot];
self.annealingCount = 1;
} else {
self.annealingCount += 1;
}
} else {
self.annealingCount = 1;
[self.snapshotsArray addObject:mainBacktraceSnapshot];
}
判定卡死
上述的实现方案可以记录到卡住的时间,业务可以定制卡顿多长时间则判定为卡死的时间。
记录卡住时间
当页面卡顿时长超过卡死的阈值,在这个阈值的基础上在计时,直到RunLoop进入下一个状态计时结束,否则会一直等到触发Watch
排除后台时间
实践过程会遇到这种 case ,在主线程执行一个方法,耗时可能要几秒,可能在执行中用户切到了后台,切回前台可能卡死会恢复了,如果不排除后台时间,就会有误判情况
排除的方法其实可以另外起一个定时器,每隔一个小段时间记录切后台前卡住的时间,当用户再切回来前台,如果还卡住,那接着计时,这样统计误差就不会比较大,可以减少误报
提供的API
/**
设定卡顿阈值和检测卡顿线程检测时间间隔启动监控
@param runloopTimeOut 卡顿阈值
@param checkRunLoopTimeOutThreshold 检测卡顿线程检测时间间隔
*/
- (void)startWithRunloopTimeOut:(useconds_t)runloopTimeOut andCheckPeriodTime:(unsigned)checkRunLoopTimeOutThreshold;
/**
采用默认值启动,卡顿阈值400ms,每隔200ms检查一次
*/
- (void)start;
- (void)stop;
上报的数据

性能损耗
CPU波动2%-4%
Dog监控阈值将APP杀死,用这种方式即使最终发生了闪退也可以逼近实际的卡死时间,误差暂未有结论。
优化
目前卡顿监控只是应用在demo中,没有在线上使用过,应该会有很多问题,例如性能瓶颈、堆栈过滤、退火算法优化等待。
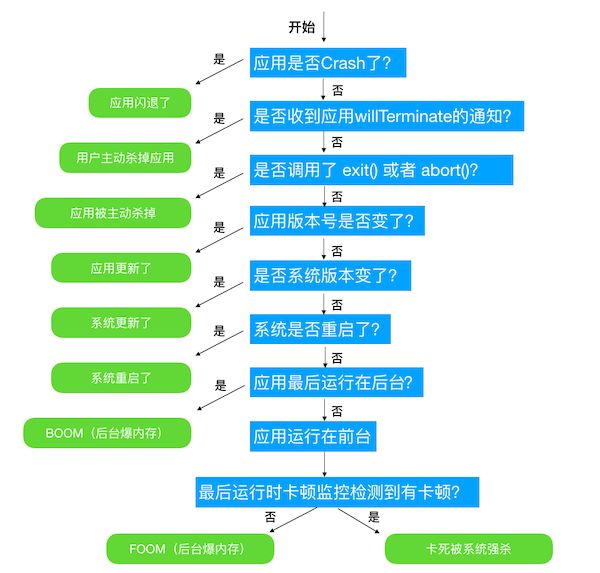
卡死
卡死是卡顿一种比较严重的情况,但这样理解并不严谨,因为卡顿一般情况是可以恢复,但卡死大概率不可恢复了,因此卡死对用户影响比较大,超过 10 秒左右进程会被系统 watchdog 杀死,而且每个 App 这类的问题应该都会比较多。
卡死监控原理
在 Runloop 的生命周期内,某个阶段的事件执行了较长事件,导致其他事件无法进行,就会引发卡死,根据这点我们可以大概给出卡死的监控思路, 基本同上述的卡顿监控方案
- 注册 Runloop 生命周期观察者
- 在Runloop 生命周期调用中检测每个阶段的耗时
- 抓取堆栈,在合适的时机将堆栈上报到监控平台
卡死治理
本人没有太多的治理经验,大概列举了下比较容易出现卡死的情况
- 死锁问题
- NSUserDefaults
参考资料
- https://mp.weixin.qq.com/s/M6r7NIk-s8Q-TOaHzXFNAw
- https://tech.meituan.com/2016/12/19/hertz.html
- http://mrpeak.cn/blog/ios-hard-stall-detection/
- https://github.com/aozhimin/iOS-Monitor-Platform
- https://github.com/meitu/MTHawkeye/blob/develop/MTHawkeye/