sql学习--网安基础细节过开发
初来乍到,在到明年全面投入到考研之前这段时间,我将在此记录我的学习历程,大致方向:Web 安全-->渗透测试-->红蓝对抗,将近一年的时间,每天学习记录,每周总结更新。
第二周:学习 MySQL 数据库的基础操作
- MySQL 数据类型
- MySQL 修改表
- 数据库的 CURD 操作
- 函数查询加强
- MySQL 查询加强
- MySQL 复杂查询:多表查询
- MySQL 表内连接和外连接
- MySQL 的约束
适合人群:初次接触数据库以及巩固网安基础
关系型数据库和非关系型数据库
关系型数据库通过外键关联来建立表与表之间的关系,非关系型数据库通常指数据以对象的形式存储在数据库中,而对象之间的关系通过每个对象自身的属性来决定 。

https://uule.iteye.com/blog/2429681 https://www.cnblogs.com/wanghongyun/p/6193912.html https://www.cnblogs.com/lina520/p/7919551.html
MySQL数据类型
整型
用于保存整数,常见的有 tinyint ,smallint ,mediumint ,int ,bigint
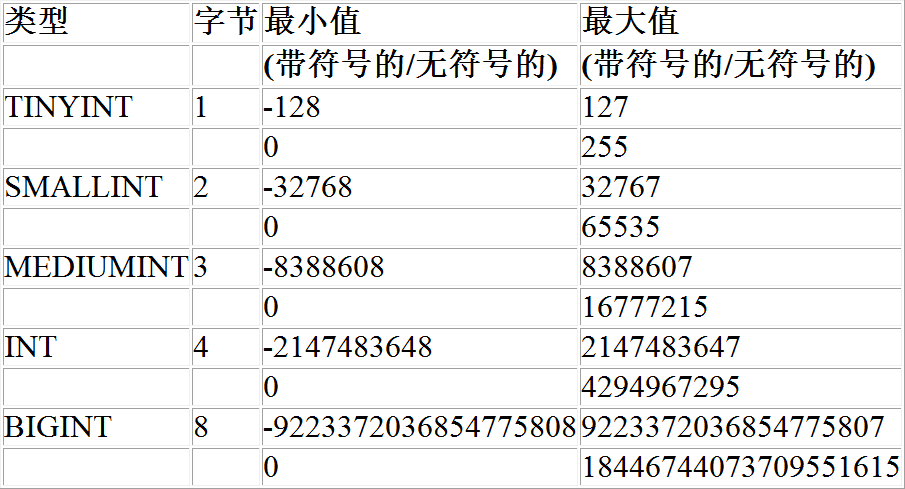
- tinyint( 1 个字节) < smallint( 2 个字节)
- 整型分为有符号和无符号
MariaDB [test]> create table people( - > name varchar(32) not null default '' comment '用户名', - > age tinyint unsigned not null default 0 comment '年龄' - > )charset=utf8 engine=myisam;Query OK, 0 rows affected (0.013 sec)- 如果不写 unsigned ,默认是有符号的
- 有符号和无符号能表示的范围是不同的,有符号要把二进制最左一位拿出来表示符号正负
关于 zerofill 的说明
zerofill 叫做0填充
举例说明:
MariaDB [test]> create table test( -> num int, -> num2 int(4) zerofill, -> num3 int(4) unsigned zerofill);Query OK, 0 rows affected (0.014 sec)当 int(4) zerofill 使用,如果添加的整数不够 4 位,则数值的左边使用 0 进行填充.
MariaDB [test]> insert into test values(1,23,345);Query OK, 1 row affected (0.010 sec)MariaDB [test]> select * from test;+------+------+------+| num | num2 | num3 |+------+------+------+| 1 | 0023 | 0345 |+------+------+------+1 row in set (0.000 sec)int(4) 不能理解成最大只能是 4 位的数,而应该理解成是 0填充的宽度
MariaDB [test]> insert into test values(1,23456,34567);Query OK, 1 row affected (0.004 sec)MariaDB [test]> select * from test;+------+-------+-------+| num | num2 | num3 |+------+-------+-------+| 1 | 0023 | 0345 || 1 | 23456 | 34567 |+------+-------+-------+2 rows in set (0.000 sec)当一个字段被 zerofill 修饰时,那么这个字段就自动成为 unsigned
MariaDB [test]> insert into test values(1,-1,34567);ERROR 1264 (22003): Out of range value for column 'num2' at row 1- int 如果不规定大小,默认是 10
MariaDB [test]> create table test2(id int zerofill,age int);Query OK, 0 rows affected (0.040 sec)MariaDB [test]> insert into test2 values(1,18);Query OK, 1 row affected (0.005 sec)MariaDB [test]> select * from test2;+------------+------+| id | age |+------------+------+| 0000000001 | 18 |+------------+------+1 row in set (0.000 sec)数值类型 - bit
bit 类型就是位类型
- 基本使用案例
MariaDB [test]> create table test10(id int,a bit(7));Query OK, 0 rows affected (0.005 sec)MariaDB [test]> insert into test10 values(1,64);Query OK, 1 row affected (0.010 sec)MariaDB [test]> select * from test10;+------+------+| id | a |+------+------+| 1 | @ |+------+------+1 row in set (0.000 sec)这里有一个困惑:a 这个字段,bit 位数为 7 的时候刚好,小了不行解惑:bit(1) 这里 1 呢 就是一个 bit 位,意思是只能有 1 位来表示你的数据,就只能表示 0 和 1可见,bit 字段在显示时,按照对应的 ascii 码对应的字符显示
MariaDB [test]> select * from test10 where a=64;+------+------+| id | a |+------+------+| 1 | @ |+------+------+1 row in set (0.000 sec)MariaDB [test]> select * from test10 where a='@';Empty set, 1 warning (0.001 sec)- 查询的时候仍然可以用数值
- 位类型。默认值是 1 ,范围是 1-64,bit(1-64) , 可以通过 bit(M) M值来控制我们填充数据的大小
- 如果一个值只有一个 0 , 1,可以考虑使用bit(1),可以节约空间,其实实际分配的是一个字节,不能分配一个位
- bit 类型, 不能手动指定 unsigned ,其实它本身就会是无符号的
数值类型--小数
- 在 MySQL 中使用的最多的是 float , decimal
float(4,2)表示的范围是 -99.99~99.99float(4,2) unsigned 表示的范围是 0-99.99decimal(5,2)表示的范围是 -999.99~999.99decimal(5,2) unsigned 表示的范围是 0-999.99指定长度,指定小数点位数数据类型--字符串
- 最主要的有三种, 分别是 char,varchar, text
MariaDB [test]> create table `user300`( -> id int unsigned not null default 0, -> name varchar(64) not null default '', -> post_code char(6) not null default '' -> )charset=utf8 engine=myisam;Query OK, 0 rows affected (0.013 sec)MariaDB [test]> insert into user300 values(100,'你好','hello');Query OK, 1 row affected (0.010 sec)MariaDB [test]> select * from user300;+-----+--------+-----------+| id | name | post_code |+-----+--------+-----------+| 100 | 你好 | hello |+-----+--------+-----------+1 row in set (0.002 sec)注意:
- char(n) 这个 n 范围是 1-255
- varchar(n) 这个 n 的范围和表的字符集有关,如果是utf8,那么n最大是 (65535-3)/3 = 21844;如果是 gbk,n最大是 (65535-3)/2 = 32766;
- n 指的都是字符数而不是字节数,与表的编码无关
- varchar 最大是有 65535 个字节,要有 3 个预留字节
- 因为utf8一个汉字占 3 个字节;gbk 一个汉字占两个字节
char(4) 是定长 这里既是插入的是 'aa' ,也是占用分配的4个字节varchar(4) 是变长,如果插入了 'aa' ,实际占用空间大小是L+1L:实际数据的长度加的一个字节用来记录长度 - char 会将存入的最后的空格自动删除,而varchar会保留。
- 存放文本时,也可以使用text数据类型,不需要规定大小,text 不能有默认值,可以将 text 视为 varchar 列,可以存放 varchar 最大的范围。
- 一个表定义的所有字段加起来不能超过 65535 ,如果需求大于 65535,我们可以使用 text 来替代 varchar。
数据类型--时间和日期
date,datetime,timestamp
MariaDB [test]> create table `user901`( -> id int, -> birthday date, -> cardtime datetime, -> login_time timestamp -> )charset=utf8 engine=myisam;Query OK, 0 rows affected (0.010 sec)MariaDB [test]> insert into user901 values(100,'2019-8-3','2019-8-8 8:8:4','2011-1-11 11:22:33');Query OK, 1 row affected (0.009 sec)MariaDB [test]> select * from user901;+------+------------+---------------------+---------------------+| id | birthday | cardtime | login_time |+------+------------+---------------------+---------------------+| 100 | 2019-08-03 | 2019-08-08 08:08:04 | 2011-01-11 11:22:33 |+------+------------+---------------------+---------------------+1 row in set (0.001 sec)- 对于 date ,只接收日期
- datetime ,timestamp 均有日期和时间
- timestamp 在 insert 和 update 时会自动根据当前时间更新
数据类型--枚举 enum,集合 set
- 对于多选我们可以使用 set 数据类型
- 对于单选我们可以使用 enum 数据类型
MariaDB [test]> create table `user902`( -> id int unsigned not null default 1, -> hobby set('A','B','C','D') not null default 'A' comment '选项', -> sex enum('男','女') not null default '男' comment '性别' -> )charset=utf8 engine=myisam;Query OK, 0 rows affected (0.009 sec)MariaDB [test]> insert into user902 values(100,'A','男');Query OK, 1 row affected (0.000 sec)MariaDB [test]> insert into user902 values(200,'A,B','男');Query OK, 1 row affected (0.000 sec)MariaDB [test]> select * from user902;+-----+-------+-----+| id | hobby | sex |+-----+-------+-----+| 100 | A | 男 || 200 | A,B | 男 |+-----+-------+-----+2 rows in set (0.002 sec)- 在 enum 类型中,数字可以替代我们的选项,类似下标理解,第一个选项为 1,第二个选项为 2,以此类推
MariaDB [test]> insert into user902 values(300,'C',1);Query OK, 1 row affected (0.000 sec)MariaDB [test]> insert into user902 values(400,'D',2);Query OK, 1 row affected (0.000 sec)MariaDB [test]> select * from user902;+-----+-------+-----+| id | hobby | sex |+-----+-------+-----+| 100 | A | 男 || 200 | A,B | 男 || 300 | C | 男 || 400 | D | 女 |+-----+-------+-----+4 rows in set (0.000 sec)- set 中也可以使用数字来替代,标号为 1,2,4,6 ...偶数形式,最大 64
A B C D1 2 4 67 => 1+2+4- 对set中的值进行查询
要借助函数select * from user where find_in_set('A',hobby);find_in_set('A',hobby) 返回'A'在 hobby 集合中处于第几位图片电影音频数据应该如何存放?
通常不会直接存储在数据库汇中,实际开发中存放的是路径地址,然后通过地址去读取。
head_img varchar(64) //存储路径创建表练习
MariaDB [test]> create table employee( -> id int unsigned not null default 0 comment '雇员id', -> name varchar(64) not null default '' comment '姓名', -> sex enum('男','女','保密') not null default '保密' comment '性别', -> birthday date not null comment '生日', -> entry_date date not null comment '入职时间', -> job varchar(32) not null default '' comment '职位', -> salary decimal(10,2) not null default 0.0 comment '薪水', -> resume text not null comment '个人介绍' -> )charset=utf8 engine=myisam;Query OK, 0 rows affected (0.004 sec)- 插入数据
MariaDB [test]> insert into employee values(100,'小妖怪','男','2001-10-11','2012-11-11','巡山',2300.00,'大王.我来巡山');Query OK, 1 row affected (0.001 sec)MariaDB [test]> insert into employee values(200,'老妖怪','女','1999-10-11','2010-11-11','捶背',4300.00,'我给大王捶背');Query OK, 1 row affected (0.000 sec)- 查看数据表
MariaDB [test]> select * from employee;+-----+-----------+-----+------------+------------+--------+---------+-----------------------+| id | name | sex | birthday | entry_date | job | salary | resume |+-----+-----------+-----+------------+------------+--------+---------+-----------------------+| 100 | 小妖怪 | 男 | 2001-10-11 | 2012-11-11 | 巡山 | 2300.00 | 大王叫我来巡山 || 200 | 老妖怪 | 女 | 1999-10-11 | 2010-11-11 | 捶背 | 4300.00 | 我给大王捶背 |+-----+-----------+-----+------------+------------+--------+---------+-----------------------+2 rows in set (0.002 sec)- 小技巧:如何对齐数据
登录 MySQLMySQL -u root -p --dafault-character-set=latin1进入 MySQL 之后 set names gbk;MySQL修改表
基本介绍
修改表,就是指,当我们的表创建好了,根据业务逻辑的需要, 我们要对表进行修改(比如 修改表名, 增加字段,删除字段,修改字段长度,修改字段类型)。
基本语法
- alter table tablename add column datatype [...];
- alter table tablename modify column datatype [...];
- alter table tablename drop column;
- 修改表的名称: rename table 表名 to 新表名;
- 修改表的字符集: alter table tablename character set utf8;
- 查看表的结构: desc tablename;
案例

1.在上面员工表增加一个 image 列(要求在 resume 后面) alter table employee add image varchar(64) not null default '' after resume;2.修改 job 列,将其长度改为 60 alter table employee modify job varchar(60) not null default ''; 其实就是重写字段将原来的覆盖3.删除 sex 列 alter table employee drop sex;4.表名修改为 worker rename table employee to worker;5.修改表的字符集 alter table worker character set utf8;6.将列名 name 修改为 user_name alter table worker change name user_name varchar(64) not null default '';- modify 不能修改字段名字,要使用 change
注意
- 如果我们删除了某个字段,那么表的该字段内容就被删除,找不回,所以要小心。
- 如果我们把一个字段的长度减小 varchar(64) ==> varchar(32) , 如果你当前这个字段没有任何数据,是可以 ok,但是如果已经有数据则看实际情况,就是如果有数据超过 32 了,则会提示错误。
- 对字段类型的修改, 比如 varchar ==> int 那么要看你的varchar 的内容是否可以转成 int, 'hello'=>int 就不能成功。
数据库的 CURD 操作
基本概念
crud 操作,表示是增删改查. c[create] / r[read] / u[update] /d[delete]
insert 语句
- 将数据添加到表中
- 基本语法
insert into tablename [(column1 [,column2,,...])]values (value1 [,value2...]);- 添加数据时,可以一次添加多条数据
- 可以选择字段添加部分字段数据
字段 id name priceinsert into goods values(10,'可口可乐',3.0);insert into goods (id,name,price) values(20,'小小酥',2.5);insert into goods (id,name) values(30,'红牛');- 插入空值的前提是该字段允许为空,还要注意字段是否有默认值
update 语句
update tablename set col_name1=expr1 [,col_name2=expr2...] [where expr];将老妖怪的薪水在原有基础上增加 1000 元update worker set salary=(select salary from worker where user_name='老妖怪')+1000 where user_name='老妖怪';-------------------update worker set salary = salary + 1000 where user_name='老妖怪';delete 语句
delete from tablename where expr;- delete 语句不能删除某一列,可以使用 update 将该字段设置为 null
- delete 会返回删除的记录数
小技巧:快速的复制一张表
create table worker2 like worker; //会创建一张空表,结构与 worker 相同insert into worker2 select * from worker;select 语句
select [distinct] *|{column1,column2,column3..} from tablename;如果我们希望过滤重复的数据,则加上 distinct* 号表示将所有的字段都检索出来,一般来说我们开发中不会使用 select * 语句,这种语句会返回所有字段,效率较低如果我们只希望检索某几列,则写清楚字段名就可以我们的使用原则是,需要什么字段,就取回什么字段select distinct * from student;- select 语句可以对列进行运算
select *|{column1 | expression,column2..} from tablename;别名写法select name,chinese+english+math from student;select name,chinese+english+math as totalgrade from student;MariaDB [test]> select name,(chinese+english+math)totalgrade from student;+-----------+------------+| name | totalgrade |+-----------+------------+| 韩顺平 | 257.00 || 宋江 | 242.00 || 关羽 | 276.00 || 赵云 | 233.00 || 欧阳锋 | 185.00 || 黄蓉 | 170.00 |+-----------+------------+6 rows in set (0.000 sec)where 子句常用运算符
- 比较运算符
,<, <,=, >,=, =, <> ,!= betwween ... and ... in(set) like not like is null
- 逻辑运算符
and,or,not
order by 子句
用于排序
select name,math from student order by math desc;select name,math from student order by math asc; //默认升序select name,math from student order by math desc,name asc; 函数查询加强
合计/聚合函数-- count
count 函数是进行统计满足条件的记录数有多少条, 是按照分组的形式统计
1.统计班里共有多少学生 select count(*) from student;select count(*) from student where math > 90;- count() count(列名) 区别count(列名) 会忽略空值进一步理解:count() 是统计记录,而 count(列名)而是依据指定的字段去统计,空值不统计在内。
聚合函数--sum
Sum 函数返回满足 where 条件的记录的总和
select sum(math) from student; //返回的结果是班级所有同学数学成绩总和select sum(math)+sum(chinese)+sum(english) from student; //这种写法是一定正确的select sum(math+chinese+english) from student; //这种写法要求所求记录中不能包含空值,数值会出错select sum(chinese)/count(*) from student;- 当使用 sum ,如果有数据为 null 时
- 当我们对单列进行统计时,是正确的,不会出错的
- 如果是多列,同一记录多个字段 : null 值加任何数据均为空
- 解决方案
- 分开统计
- 使用 ifnull 函数
ifnull函数 ifnull(expr1,expr2), 如果 expr1 为 null ,则取 expr2 的值 如果 expr1 不为空,就取第一个表达式的值select sum(ifnull(math,0.0)+ifnull(chinese,0.0)+ifnull(english,0.0)) from student where id >= 100;聚合函数-- avg
AVG函数返回满足 where 条件的列的平均值
select avg(math) from student;聚合函数-- Max/Min
返回满足 where 条件的列的最大/最小值也需要保证每个字段中不能包含空值
聚合函数 group by
group by 就是对数据(列)进行分组统计, 如果我们需要对分组的结果进行过滤则可以使用关键字 having
select max(salary),min(salary),deptno from emp group by deptno;- 可以对多列进行分组
dual
亚元表,可以作为一个测试表,可以当做一个空表,没有表用的时候可以拿来用,补位的意思
MySQL> select now() from dual;+---------------------+| now() |+---------------------+| 2019-08-07 01:29:06 |+---------------------+1 row in set (0.01 sec)MySQL 的日期函数
- current_date() 当前日期
- current_time() 当前时间
- current_timestamp() 当前时间戳
- date(datetime) 返回 datetime 的日期部分
- now() 当前时间
字符串函数
- charset(str) 返回字串字符集
MySQL> select charset('nihao');+------------------+| charset('nihao') |+------------------+| gbk |+------------------+1 row in set (0.01 sec)- concat(string[,string2...]) 连接字串
MySQL> select concat('name:',name,' year:',year) as info from user;+---------------------+| info |+---------------------+| name:huahua year:4 |+---------------------+1 row in set (0.00 sec)- inser(string,substring) 返回 substring 在 string 中出现的位置,没有返回 0
- ucase(string) 转换成大写
- lcase(string) 转换成小写
MySQL> select ucase('abc'),lcase('DEF');+--------------+--------------+| ucase('abc') | lcase('DEF') |+--------------+--------------+| ABC | def |+--------------+--------------+1 row in set (0.00 sec)- left(string,length) 从 string 左边起取 length 个字符
MySQL> select left('nihao',3);+-----------------+| left('nihao',3) |+-----------------+| nih |+-----------------+1 row in set (0.01 sec)- length(string) string 长度(按照字节)
MySQL> select length('nihao');+-----------------+| length('nihao') |+-----------------+| 5 |+-----------------+1 row in set (0.00 sec)- replace(str,searchstr,replecestr) 在 str 中用 replacestr 替换 searchstr
如图,全部查找,全部替换MySQL> select replace('nihaoyyyyyy','y','!');+--------------------------------+| replace('nihaoyyyyyy','y','!') |+--------------------------------+| nihao!!!!!! |+--------------------------------+1 row in set (0.00 sec)- strcmp(string1,string2) 逐字符比较两个字串大小,不区分大小写
string1>string2 返回1
string1string1=string2 返回0
MySQL> select strcmp('a','a');+-----------------+| strcmp('a','a') |+-----------------+| 0 |+-----------------+1 row in set (0.00 sec)MySQL> select strcmp('a','A');+-----------------+| strcmp('a','A') |+-----------------+| 0 |+-----------------+1 row in set (0.00 sec)------------------------------------------------MySQL> select strcmp('a','b');+-----------------+| strcmp('a','b') |+-----------------+| -1 |+-----------------+1 row in set (0.00 sec)- substring(str,position[,length]) 从 str 的 position 开始取 length 个字符
下图可见,如果省略 length ,返回其后所有
MySQL> select substring('nihao world',6,6);+------------------------------+| substring('nihao world',6,6) |+------------------------------+| world |+------------------------------+1 row in set (0.00 sec)MySQL> select substring('nihao world',6);+----------------------------+| substring('nihao world',6) |+----------------------------+| world |+----------------------------+1 row in set (0.00 sec)- ltrim(string) rtrim(string) trim(string) 去除前端或后端或两端空格
MySQL> select length(' nihao! ');+----------------------------+| length(' nihao! ') |+----------------------------+| 16 |+----------------------------+MySQL> select length(trim(' nihao! '));+----------------------------------+| length(trim(' nihao! ')) |+----------------------------------+| 6 |+----------------------------------+1 row in set (0.00 sec)数值函数
- abs(num) 绝对值
- bin(decimal_num) 十进制转二进制
- ceiling(num) 向上取整
- conv(num,frombase,tobase) 进制转换
MySQL> select conv(10,10,2);+---------------+| conv(10,10,2) |+---------------+| 1010 |+---------------+1 row in set (0.00 sec)MySQL> select conv(10,10,16);+----------------+| conv(10,10,16) |+----------------+| A |+----------------+1 row in set (0.00 sec)- floor(num) 向下取整
- format(num,decimal_places) 保留小数位数
- hex(decimal_num) 转十六进制
- least(num1,num2...) 求最小值
- mod(num,denominator) 求余
- rand([seed])
流程控制函数
- if(expr1,expr2,expr3)
- ifnull(expr1,expr2)
- select case
select casewhen expr1 then expr2when expr3 then expr4else expr5end;其他函数
- user() 查询用户
- database() 数据库名称
- md5(str) 为字符串算出一个 md5 128 比特检查和,通常用于对应用程序使用到的表的某个字段加密
- password(str) 从原文密码 str 计算并返回密码字符串,通常用于对 MySQL 数据库的用户密码加密
MySQL> select md5('nihao');+----------------------------------+| md5('nihao') |+----------------------------------+| 194ce5d0b89c47ff6b30bfb491f9dc26 |+----------------------------------+1 row in set (0.01 sec)MySQL> select password('nihao');+-------------------------------------------+| password('nihao') |+-------------------------------------------+| *364870DF09C7E82F6A8ED19ED529F3375E57B3CF |+-------------------------------------------+1 row in set (0.00 sec)MySQL 查询加强
查看表结构
desc 表名;show create table 表名;
使用算术表达式加强
计算每个雇员的年薪select (ifnull(sal,0.0)+ifnull(comm,0.0)) * 12 as 年薪 from emp;where 子句的加强
select * from emp where sal between 2000 and 3000;select * from emp where sal>=2000 and sal<=3000;
显示首字符为 SS 的员工姓名和工资select ename,sal from emp where 'S'=left(ename,1);select ename,sal from emp where ename like 'S%';
显示第三个字符为大写 o 的所有员工的姓名和工资select ename,sal from emp where ename like '__O%';
显示 empno 为 123 , 234 , 800 的雇员情况select * from emp where empo in (123,234,800);显示没有上级的雇员情况select * from emp where mgr is null;
逻辑操作符的加强
select * from emp where (sal>500 or job='MANAGER') and ename like 'J%';
使用 order by 子句
按照工资从高到低的顺序显示select * from emp order by sal;按照部门号升序而雇员的工资降序排序select * from emp order by deptno,sal desc;
MySQL 的分页查询
实际查询时,不可能把所有的记录都返回,而是一页一页返回,这是我们就会使用分页查询 (limit)
- 分页查询有两个重要的参数, \$pageSize 表示一页显示几条记录分页查询有两个重要的参数 $pageNow 表示显示第几页
select 列名 from 表名 limit ($pageNow-1)*$pageSize,$pageSize;
- 索引从 0 开始,所以下图是查询第一条记录
select chinese from student limit 0,1;
聚合函数的加强 - max,min,avg,sum,count
select avg(sal),deptno from emp where deptno=20;显示工资最高的员工和其工作岗位select * from emp where sal=(select max(sal) from emp)显示工资高于平均工资的员工信息select * from emp where sal>(select avg(sal) from emp);
group by 和 having 子句的加强
显示每个部门的平均工资和最高工资select avg(sal),max(sal) from emp group by deptno;显示每个部门的每种岗位的平均工资和最低工资select avg(sal),max(sal) from emp group by deptno,job;显示平均工资低于 2000 的部门号和它的平均工资select avg(sal) as myavg,deptno from emp group by deptno having myavg<2000;
数据分组关键字顺序
同时出现书写顺序 group by、having、order by统计各个部门的平均工资,并且是大于 2000 ,按照平均工资从高到低排序select avg(sal) as myavg from emp group by deptno having myavg>2000 order by myavg desc;
MySQL 复杂查询--多表查询
多表查询
多表查询是指基于两个和两个以上的表或是视图的查询.在实际应用中,查询单个表可能不能满足你的需求,(如显示 sales 部门位置和其员工的姓名),这种情况下需要使用到( dept 表和 emp 表)
- 如果直接对两个表联查,将会得到结果=>笛卡尔积
select * from emp,dept; - 笛卡尔积当我们对多表进行联查时,我们就会得到的表 1 记录数 * 表 2 的记录数
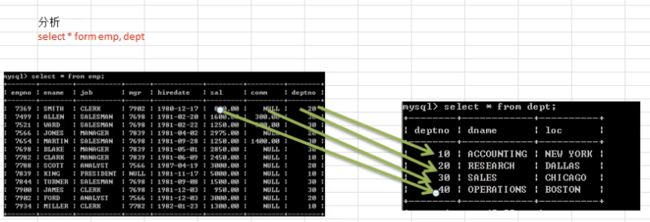
- 在多表查询中,由于笛卡尔积的原理,重要的是要找到多表关联的字段
select * from emp,dept where emp.deptno=dept.deptno;若两表中关联的字段名称不相同,也可以不加表名限制select ename,sal,dname,dept.deptno from emp,dept where emp.deptno=dept.deptno;显示emp所有字段加dept表中的dnameselect emp.*,dept.dname from emp,dept where emp.deptno=dept.deptno; - 多表查询的条件是至少不能少于表的个数 -1
select dept.dname,emp.dname,emp.sal from emp,dept where emp.deptno=dept.deptno and emp.deptno=10;- 关键在于 where 语句对笛卡尔集的规避,对表的关系要搞清楚
自连接
自连接是指在同一张表的连接查询
select * from emp where empno=(select mgr from emp where ename='ford');
- 将同一张表看做两张表

select worker.ename,boss.ename from emp as worker,emp as boss where worker.mgr = boss.empno;子查询
子查询是指嵌入在其它 sql 查询语句中的 select 语句,也叫嵌套查询
单行子查询
单行子查询是指只返回一行数据的子查询语句select * from emp where deptno=(select deptno from emp where ename='smith');
多行子查询
多行子查询指返回多行数据的子查询 使用关键字 in
如何查询和 10 号部门的工作相同的雇员的信息,但是不含 10 号部门的雇员。select * from emp where job in (select distinct job from emp where deptno=10)and deptno <>10;多列子查询
如果我们的一个子查询,返回的 结果是多列,就叫做列子查询
查询和宋江数学,英语,语文完全相同的学生select * from student where (math,english,chinese) = (select math,english,chinese from student where name='宋江');from 子句中使用子查询
- 将一个查询结果看做一个临时表案例:显示高于自己部门平均工资的员工的信息
select ename, sal, temp. myavg,emp.deptno from emp, (select avg(sal) as myavg , deptno from emp group by deptno) as tempwhere emp.deptno = temp.deptno ANDemp.sal > temp. myavg;合并查询
合并多个 select 语句的结果,可以使用集合操作符 union,union all
union 合并查询
select 语句1 union select 语句2;两个 sql 语句结果合并返回,而且会去掉重复的记录union all 和 union 唯一的区别就是 union all 不去重
MySQL 表内连接和外连接
MySQL 表的内连接
内连接实际上就是利用 where 子句对多表形成的笛卡尔积进行筛选前面我们使用的那种语法都属于内连接select 列名 from 表1 inner join 表2 inner join 表3 ON 条件 ....
MySQL 的外连接
分两种:左外连接,右外连接
左外连接
- 如果左侧的表完全显示我们就说是左外连接
select 列名 表1 left join 表2 on 条件;
MySQL> select * from stu;+------+------+| id | name |+------+------+| 1 | name || 2 | jack || 3 | tom || 4 | kity |+------+------+4 rows in set (0.00 sec)MySQL> select * from exam;+------+-------+| id | grade |+------+-------+| 1 | 55 || 2 | 45 || 3 | 89 |+------+-------+3 rows in set (0.00 sec)- 显示所有人的成绩,如果没有成绩,也要显示该人的姓名和 id 号,成绩显示为空(这种情况使用内连接是无法实现的)
select * from stu left join exam on stu.id=exam.id;
MySQL> select stu.id,name,grade from stu left join exam on stu.id=exam.id;+------+------+-------+| id | name | grade |+------+------+-------+| 1 | name | 55 || 2 | jack | 45 || 3 | tom | 89 || 4 | kity | NULL |+------+------+-------+4 rows in set (0.00 sec)- 如果上述要求,如果某位同学没有分数,则置为零
select stu.id,name,ifnull(grade,0) as grade from stu left join exam on stu.id=exam.id;
右外连接
如果右侧的表完全显示我们就说是右外连接select 列名 from 表1 right join 表2 ON 条件
显示所有分数,没有对应人的分数对应的 name 置为无名MySQL> select stu.id,ifnull(name,'wuiming'),grade from stu right join exam on stu.id=exam.id;+------+------------------------+-------+| id | ifnull(name,'wuiming') | grade |+------+------------------------+-------+| 1 | name | 55 || 2 | jack | 45 || 3 | tom | 89 || NULL | wuiming | 99 |+------+------------------------+-------+4 rows in set (0.00 sec)MySQL 的约束
约束是用于维护数据的完整性, 所谓数据的完整性指的是,根据业务逻辑的需要,我们将表的某些字段设置成一种约束,从而保证数据的合理性和完整性,比如身份证编号就是唯一,我们就可以使用 unique 这个约束。
MySQL 的约束分类
- 主键约束: primary key
- 唯一约束: unique
- not null
- check :检查约束,很多数据库都有,但是 MySQL 支持语法,并没有实际作用
- 外键约束: foreign key
主键约束
- 主键约束一般在 int,字符型设置
- 一旦一个字段被设置成主键约束,则该字段不能重复,也不能为 null
- 一张表最多只能有一个主键,但是可以是复合主键(两个字段合起来当一个主键)
create table `user`( id int, name varchar(32) not null default '', email varchar(32) not null default '', primary key (id,name) )charset=utf8 engine=muisam;- 当 id , name 同时重复才会认为是重复冲突的1,'aaa','[email protected]' 可以插入1,'bbb','[email protected]' 也可以插入1,'aaa','[email protected]' 不可以插入
- not null 和 unique 的效果非常像 primary key
not null 约束
unique 约束(唯一约束)
当我们希望某个字段的值不能出现重复值时,我们就可以将该字段设置成 unique
- 如果我们将某个字段设置为 unique ,但是没有设置 not null, 那么该字段可以为 null ,并且可以有多个 null
- 如果你要某个字段不能重复,而且不能为 null , 我们可以这样定义字段字段名 字段类型 not null unique
- 一个表中,可以有多个 unique 约束.
外键约束
用于定义表和和从表之间的关系:外键约束要定义在从表上,主表则必须具有主键约束或是 unique 约束,当定义外键约束后,要求外键列数据必须在主表的主键列存在或是为 nullforeign key (外键(本表)字段) references 主表(字段);
- 外键字段是在本表定义的
- 外键字段是指向另外一张表的某个字段

- 先创建主表
MySQL> create table my_class( -> class_id int primary key, -> class_name varchar(64) not null unique, -> class_intro text not null -> )charset=utf8 engine=innodb;Query OK, 0 rows affected (0.02 sec)- 创建从表
MySQL> create table stu( -> id int primary key, -> name varchar(64) not null default '', -> class_id int, -> /*定义外键*/ -> foreign key (class_id) references my_class(class_id) -> )charset=utf8 engine=innodb;Query OK, 0 rows affected (0.02 sec)- 给 stu 表添加数据时,要求对应的 myclass 表的 classid 已经存在
- 如果外键没有设置 not null ,那么外键的值可以是 null ,而且可以有多个
`MySQL> insert into stu values(1,'张三',1); ERROR 1452 (23000): Cannot add or update a child row: a foreign key constraint fails (`test`.`stu`, CONSTRAINT `stu_ibfk_1` FOREIGN KEY (`class_id`) REFERENCES `my_class` (`class_id`))`- 由于刚刚创建的 myclass 表中没有 classid 值,不能直接向 stu 中添加数据
- 表的类型要 innodb ,这样的类型支持外键
- 外键字段的类型要和主键字段的类型一致(长度可以不同)
- 外键字段的值,必须在主键出现过,或者为 null
- 一旦建立了主外键的关系,数据不能随意删除和修改了
本文首发于 GitChat,未经授权不得转载,转载需与 GitChat 联系。
阅读全文: http://gitbook.cn/gitchat/activity/5d4e3283511b817a170e5a2a
您还可以下载 CSDN 旗下精品原创内容社区 GitChat App ,阅读更多 GitChat 专享技术内容哦。
