MongoDB之高级命令语句
MongoDB之高级命令语句
一、MongoDB Mapreduce
Map-Reduce是一种计算模型,简单的说就是将大批量的工作(数据)分解(MAP)执行,然后再将结果合并成最终结果(REDUCE)。
MongoDB提供的Map-Reduce非常灵活,对于大规模数据分析也相当实用。

1. MapReduce 命令
以下是MapReduce的基本语法:
- 一条语句
db.collection_name.mapReduce(
function() {emit(key,value);}, //map 函数
function(key,values) {return reduceFunction}, //reduce 函数
{
out: collection,
query: document,
sort: document,
limit: number
}
)
- 多条语句
var map1=function() {emit(key,value);}
var reduce1=function(key, values) {return ruduceFuction;}
var options1={out:"new_collection_name"}
db.collection_name.mapReduce(map1,reduce1,options1)
2. 参数说明

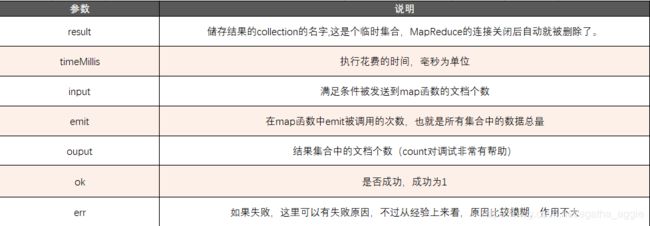
3. 文件引入(举例 .csv 文件引入)
- 引入 Windows MongoDB 中
mongoimport --db test --collection employee --type csv --headerline --ignoreBlanks --file D:\\xxx\\xxx.csv
其中: test 是使用的数据库,employee为将要创建的集合名称,type CSV 代表引入的文件的类型,headerline代表将文件的第一列作为新集合的列名,ignoreBlanks代表忽略单元格中的空格,file后使用本机的文件的地址
- 引入 Linux MongoDB 中
- 将文件传入虚拟机的某个地址
- 引入
mongoimport --db test --collection employee --type csv --headerline --ignoreBlanks --file /xxx/xxx/xxx.csv
- 引入 Navicat链接的MongoDB 中
- 点击 import Wizard

- 选择要导入的类型

- 选择要引入的文件







4. 实例
此处运用这个表格(已经引入了)
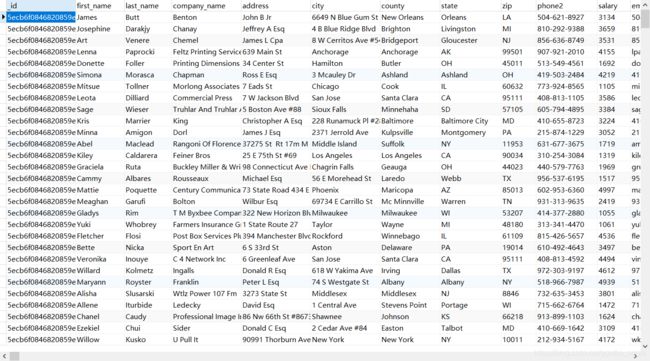
实现将各个state分类统计
var map1=function() {emit(this.state,1);}
var reduce1=function(map, values) {return Array.sum(values);}
var options1={out:"outcoll"}
db.emp.mapReduce(map1,reduce1,options1)
db.outcoll.find()
或者
db.emp.mapReduce(
function() {emit(this.state,1);}, //map 函数
function(key,values) {return Array.sum(values)}, //reduce 函数
{
out: "outcoll2",
}
)
db.outcoll2.find()

用类似的方式,MapReduce可以被用来构建大型复杂的聚合查询。
Map函数和Reduce函数可以使用 JavaScript 来实现,使得MapReduce的使用非常灵活和强大。
二、MongoDB 固定集合(Capped Collections)
MongoDB 固定集合(Capped Collections)是性能出色且有着固定大小的集合,对于大小固定,我们可以想象其就像一个环形队列,当集合空间用完后,再插入的元素就会覆盖最初始的头部的元素。
1. 创建固定集合
我们通过createCollection来创建一个固定集合,且capped选项设置为true:
db.createCollection("cappedLogCollection",{capped:true,size:10000})
还可以指定文档个数,加上max:1000属性:
db.createCollection("cappedLogCollection",{capped:true,size:10000,max:1000})
2. 判断集合是否为固定集合:
db.cappedLogCollection.isCapped()
如果需要将已存在的集合转换为固定集合可以使用以下命令:
db.runCommand({"convertToCapped":"emp",size:10000})
以上代码将我们已存在的 posts 集合转换为固定集合。
3. 固定集合查询
固定集合文档按照插入顺序储存的,默认情况下查询就是按照插入顺序返回的,也可以使用$natural调整返回顺序。
db.cappedLogCollection.find().sort({$natural:-1})
4. 固定集合的功能特点
1)可以插入及更新,但更新不能超出collection的大小,否则更新失败,不允许删除,但是可以调用drop()删除集合中的所有行,但是drop后需要显式地重建集合。
2)在32位机子上一个cappped collection的最大值约为482.5M,64位上只受系统文件大小的限制。
5. 固定集合属性及用法
1)属性
- 属性1:对固定集合进行插入速度极快
- 属性2:按照插入顺序的查询输出速度极快
- 属性3:能够在插入最新数据时,淘汰最早的数据
2)用法 - 用法1:储存日志信息
- 用法2:缓存一些少量的文档
三、MongoDB GridFS
1.概念
1)GridFS 用于存储和恢复那些超过16M(BSON文件限制)的文件(如:图片、音频、视频等)。
2)GridFS 也是文件存储的一种方式,但是它是存储在MonoDB的集合中。
3)GridFS 可以更好的存储大于16M的文件。
4)GridFS 会将大文件对象分割成多个小的chunk(文件片段),一般为256k/个,每个chunk将作为5)MongoDB的一个文档(document)被存储在chunks集合中。
6)GridFS 用两个集合来存储一个文件:fs.files与fs.chunks。
7)每个文件的实际内容被存在chunks(二进制数据)中,和文件有关的meta数(filename,content_type,还有用户自定义的属性)将会被存在files集合中。
2.GridFS 添加文件
现在我们使用 GridFS 的 put 命令来存储 mp3 文件。 调用 MongoDB 安装目录下bin的 mongofiles.exe工具。
打开命令提示符,进入到MongoDB的安装目录的bin目录中,找到mongofiles.exe,并输入下面的代码:
mongofiles.exe -d gridfs put D:\\mongo\\song.mp3
song.mp3 是音频文件名,之前的路径是音乐在本机的地址

未完继续。。。。。。。。。。。。。。。