java面试总结(6)之JVM
1.为什么说java是跨平台语言
这里所谓平台通常指操作系统,java可以在不同的操作系统上运行
跨平台原理:java针对不同的操作系统开发了不同的JVM也就是虚拟机,而我们的java程序是其实是运行在虚拟机上的,因此可以说java程序可以运行在不同的虚拟机上,不同的虚拟机又运行在不同的操作系统上
因此说java是跨平台语言
2.执行一个简单的Helloworld程序,都会经历哪些步骤
javac Helloworld.java 编译Helloworld.java生成一个Helloworld.class文件
java Helloworld 调用执行命令,执行Helloworld程序
首先加载jvm.cfg虚拟机的配置文件,根据配置启动JVM
通过jvm.cfg文件中的配置找到jvm.dll文件,jvm.dll文件是JVM运行的核心文件,JVM通过jvm.dll运行
jvm装载Helloworld.class文件
找到main方法运行main函数
3.谈谈你对JVM的理解
3.1JVM结构原理图
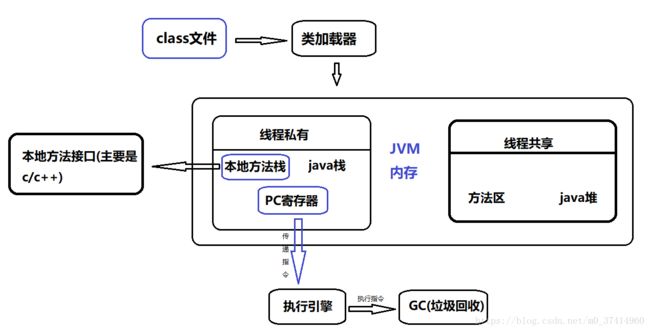
3.2名称解释
*方法区
方法区内存的是常量,静态变量,和类的详细信息(包括类名,修饰符,属性名,方法等等)
*java堆
堆中存储的是对象本身和数组,对象和数组引用是存储在栈中的,当然对象的成员也随对象存储在堆中了
*java栈
java中的栈是线程私有的,线程调用一个方法时会向栈中压入一个栈帧(先进后出),里面存储的是局部变量和对象的引用
*本地方法栈
本地方法栈当中运行的是本地方法(通常是C/C++)函数,因此这个栈是不受JVM管控的
大致过程是 : java栈中某个方法调用本地方法,本地方法调用本地方法(或java方法)
*PC寄存器
PC寄存器是线程私有的,java中线程启动的时候会创建一个PC寄存器,里面存储的始终是下一步指令的地址,或者说是指针。
*执行引擎
拿到寄存器指针指向的指令,去执行这些指令,也就是运行程序指令
4.简述JVM装载一个类的过程
加载→连接(验证→准备→解析)→初始化→使用→卸载
1.加载
JVM通过类加载器(ClassLoader)根据class文件的路径,读取class文件二进制流,解析里面的元数据(如常量,静态变量等)存储到方法区,把类对应的class对象存储到java堆区
2.连接(又包括三个步骤)
*验证:验证类中的元数据是否合法,以及该类创建时的版本是否低于当前jdk版本等等
*准备:主要进行一些变量的初始化操作
*解析:通过符号引用(包名)找到某个对象在内存中的地址,建立直接引用。
3.初始化
调用构造,为静态变量赋值(准备阶段是初始默认值,该阶段是执行代码中的赋值操作),运行静态代码块等。
当然如果有父类会先初始化其父类
5.ClassLoader有什么用
*ClassLoader的具体实例会把类的class文件加载到JVM中去,同时也可以加载网络中的字节码
*需要了解的几种ClassLoader:
Bootstrap ClassLoader 启动类加载器
我们所使用的所有java类库,例如集合,IO等等都是由该启动类加载器加载的,简单来说就是,jre/lib 目录下的rt.jar包等等都会被该启动类加载
Extension ClassLoader 扩展类加载器
jre/lib/ext 目录下的扩展类库,是由该类加载器加载的,例如sun公司提供的一些扩展类库,当然了我们也可以自定义一些类库,放在该目录下面,那么程序中就不需要引入这些类库的jar文件了
Application ClassLoader 应用类加载器
顾名思义,我们的应用程序中,引入的一些外部类库,是由该类加载器加载的
6.java类加载机制的双亲委派模式
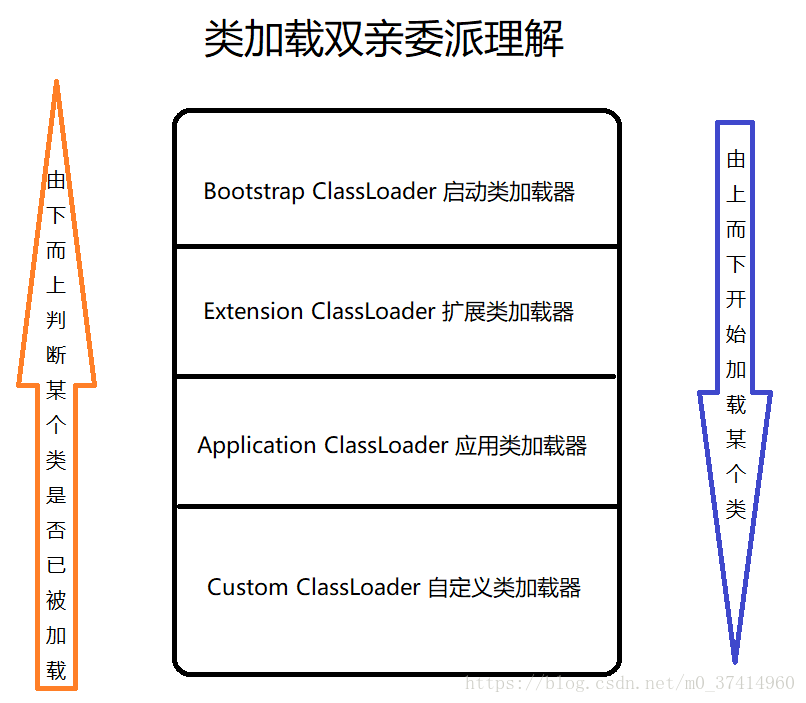
双亲委派是指类加载器加载类的时候,首先判断该类是否已被加载过,如果否,交由父类加载器判断,直至启动类加载器,如果还是否,则由启动类加载器加载该类,如果该类没有在启动类加载器加载的范围内,则交由子类加载器,直至最后用户自定义的类加载器。
7.描述JMM(Java Memory Model)
其实根本就没有什么所谓JMM,但是java内存模型当然是有的,显然JMM抽象出来的意思并不是为了把JVM结构图再重复一边,但是面试不能这么答。
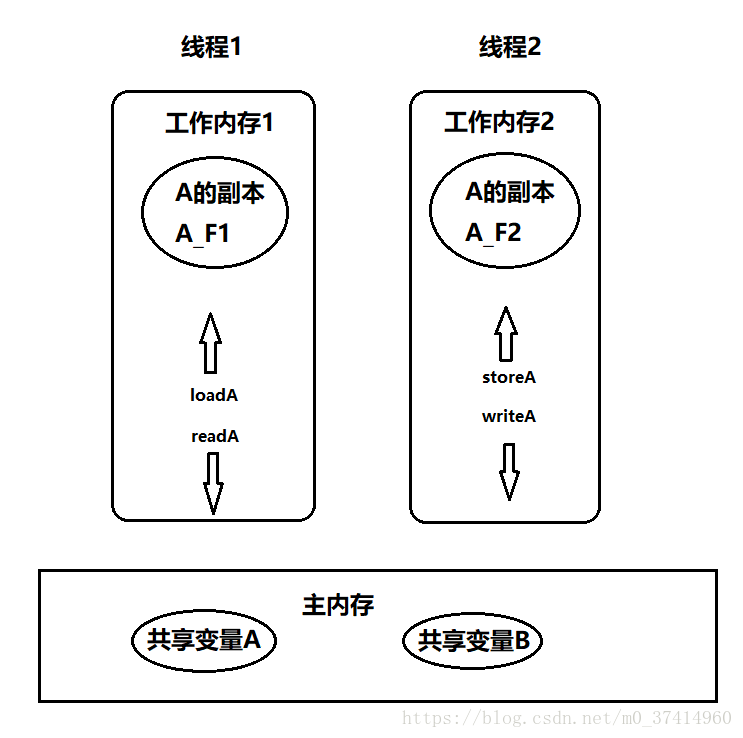
JMM,Java内存模型用来描述多线程与JVM内存之间的关系,多线程操作一个变量的原理:
线程1从主内存中拷贝变量A的一个副本到线程1的工作内存中变量A_F1,
线程2从主内存中拷贝变量A的一个副本到线程2的工作内存中变量A_F2,
因此各个线程其实操作的是一个变量副本,最后把变量副本的值刷新到主内存得变量中。
8.可见性和重排序
所谓可见性主要是指java中的这个修饰符volatile,其原理就是,被volatile修饰的共享变量,可以理解为,各个线程是直接操作主内存中的该变量的,因此,各个线程对volatile修饰的变量的操作是相互可见的,但不具备写的原子性
所谓重排序
在单线程环境下,JVM会对不影响代码逻辑的一些指令进行重排序以优化程序,称为java指令重排序
例如:int a = 0,x=1; 先执行a =0 和先执行x = 1 没有影响,因此可能会发生重排序
例如:int b = 0, y = b; 这样重排序逻辑就会不一样
看下面代码示例:
volatile static int a = 0, b = 0, x = 0, y = 0;
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread() {
@Override
public void run() {
a = 1;
x = b;
}
};
Thread t2 = new Thread() {
@Override
public void run() {
b = 1;
y = a;
}
};
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println("x = " + x + " y = " + y);
}当打印出x=0;y=0的时候就是发生了指令重排
线程1先执行了x=b ,此时b=0,所以x=0.
紧接着线程2又执行了y=a,此时a=0,所以y=0.
然后执行a=1或b=1已经不影响结果了
9.JVM参数设置
eclipse中可以在eclipse.ini中对以下参数的配置,或者直接在Run>Configuration >Arguments>VM arguments中配置
windows下配置在tomcat的catalina.bat文件中
linux下配置在tomcat的catalina.sh文件中
1.跟踪类参数
-XX:+PrintGCDetails ##开启打印GC日志详情
-Xloggc:gc.log ##GC日志输出到文件gc.log
-XX:+TraceClassLoading ##打印加载的所有类的信息
2.堆分配参数
-Xms256m ##最小堆256MB 注意必须先配置最小堆,这个参数必须在最大堆的前面
-Xmx1024m ##最大堆1024MB
-Xmn50m ##PSYoungGen(新生代)50MB
-XX:NewRatio=2 ##新生代和ParOldGen(老年代)的比率是1:2
-XX:SurvivorRatio=9 ##Survivor区与eden区比率为1:9
注意点:
新生代=eden区+Survivor区
Survivor区=from区+to区
from区=to区
官方默认:新生代占堆的大小为3/8,Survivor区占新生代区的大小为1/10
3.方法区(jdk8以后改为元数据区)分配参数
jdk8以前
--XX:PermSize
-XX:MaxPermSize
jdk8以后
-XX:MetaspaceSize
注意点:
jdk8以前方法区(又叫永久区)其实是一片连续的堆空间,由JVM分配,大量的实践告诉我们,该区的大小非常不可控,也就是说经常变动。
jdk8以后,通常我们不手动指定元数据区的大小了,因为该区所占内存被移到了本地堆内存中,也就是操作系统中,这样元数据区的大小其实只受操作系统中剩余可使用内存的大小限制,比较方便
4.栈分配参数
-Xss
通常都比较小,几百KB,如果超出会抛java.lang.StackOverflowError错误
10.垃圾回收器的种类
并行垃圾回收器、CMS垃圾回收器、G1垃圾回收器
以下是一些垃圾回收器参数配置总结
-XX:+UseSerialGC:在新生代和老年代使用串行收集器
-XX:+UseParNewGC:在新生代使用并行收集器
-XX:+UseParallelGC :新生代使用并行回收收集器,更加关注吞吐量
-XX:+UseParallelOldGC:老年代使用并行回收收集器
-XX:ParallelGCThreads:设置用于垃圾回收的线程数
-XX:+UseConcMarkSweepGC:新生代使用并行收集器,老年代使用CMS+串行收集器
-XX:ParallelCMSThreads:设定CMS的线程数量
-XX:+UseG1GC:启用G1垃圾回收器
11.JVM调优工具
11.1JVM调优会用到的linux命令:
*jps -l(查看当前运行的所有java进程)
pid 应用
2244 sun.tools.jps.Jps
1994 springboot1-0.0.1-SNAPSHOT.jar
*top -p [pid] (查看进程ID为pid的cpu及内存使用信息)
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1994 root 20 0 353m 79m 7768 S 0.3 7.9 0:13.11 java
*jstat -[option] [pid] (查看pid为pid的java进程的详情)
jstat -compiler 1994 ##查看已编译的类信息
jstat -gc 1994 ##查看堆详细信息,gc次数以及gc时间
jstat-gcutil 1994 2000 5 ##统计gc信息,查看JVM已使用的内存信息所占比例 2秒统计一次,统计5次
其他命令用的时候查一下,此处略......
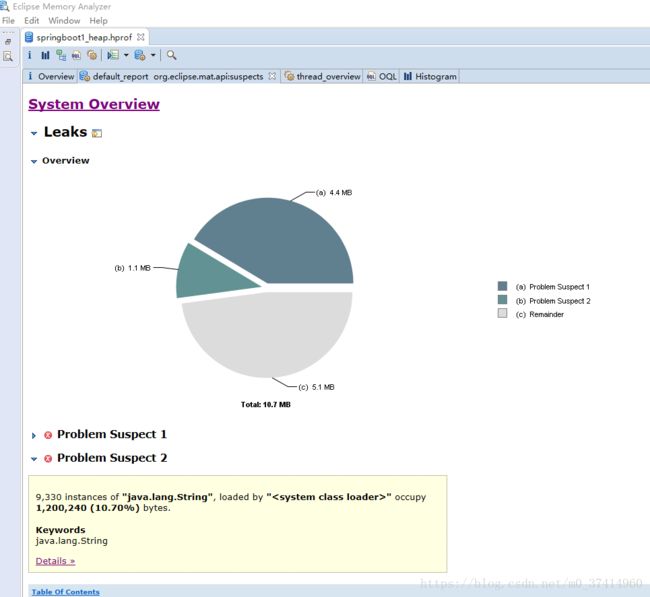
*jmap -dump:live,format=b,file=[filename].hprof [pid] (导出进程ID为pid的java进程的堆内存快照信息,堆内存文件名称为filename.hprof可以使用Mat堆内存分析工具分析)
例如:jmap -dump:live,format=b,file=springboot1_heap.hprof 1994
导出pid为1994的java进程的堆内存快照文件,文件名称为springboot1_heap.hprof,保存于该jar应用同级目录下
jmap -heap [pid] #查看某个服务的堆内存配置、已使用、空闲详情
11.2JVM常用的调优工具有:
Mat(Memory Analyzer) 用于分析堆内存(常用)
位于jdk的bin目录下的jvisualvm.exe是一个JVM性能监控工具
12 JVM调优的简单案例
第一步:使用jps查看当前服务器上运行的java进程的pid
第二步:如果我们要调优的java进程存在的话,使用top -p pid命令查看一下该java应用的cpu和内存使用情况
第三步:使用jmap -dump:live,format=b,file=filename.hprof pid命令,导出该java应用的堆内存快照
第四步:打开Mat工具导入从服务器上download下来的filename.hprof 文件