centos中redis的主从复制 哨兵模式 集群搭建
话就不多说了,直接来。
一:centos安装redis
1.下载redis安装包
下载地址:https://redis.io/download
我下载的是:redis-3.0.0-rc2.tar.gz
2.通过Xftp将压缩包放到指定目录,我是放在:/usr/local/ 目录下
3.解压到当前目录:tar -zxvf redis-3.0.0-rc2.tar.gz 压缩文件
4.进入到解压后的redis-3.0.0-rc2目录,进行编译:make
5.make报错:装上gcc才能编译源码:yum install gcc
6.进入到redis-3.0.0-rc2目录下的src目录进行安装:make install
7.我习惯将可执行文件和配置文件移动到bin和etc目录下,而redis本身是没有这两个目录的,所以我新建了一个与redis-3.0.0-rc2同级的redis目录
(1)mkdir -p /usr/local/redis/bin
(2)mkdir -p /usr/local/redis/etc
新建完成后cp对应的执行文件和配置文件到bin和etc下
(3)cd /usr/local/redis-3.0.0-rc2/src
(4)mv mkreleasehdr.sh redis-benchmark redis-check-aof redis-check-dump redis-cli redis-server redis-sentinel /usr/local/redis/bin
(5)cd /usr/local/redis-3.0.0-rc2/
mv ./redis.conf /usr/local/redis/etc
执行到这里基本上已经算安装完成了,看个人需要配置bin的环境变量(我配好了后面就直接使用了)。
二:启动与关闭redis
我当前的路径为:/usr/local/redis/etc
启动之前改一下redis.conf:vim redis.conf
主要三个地方:
1.原daemonize no 改为:daemonize yes 意思是redis启动为后台启动,否则会一直占用界面。
2.logfile 日志文件,可以自己定义一个redis的日志文件方便日后好查找
3.dbfilename 后的dir建议把这个路径改为我的当前etc目录下(也就是redis.conf同级,这里不是/etc目录下),这是redis数据库存在磁盘上的文件,因为毕竟redis是属于缓存数据库,如果突然断电啥的数据岂不是全部都丢失了如果没有存到磁盘,怎么存我们不用管,自己会存。如果删了这个rdb文件的话,你的数据库启动的时候是查询不到数据的
ok,开始启动吧
我现状:我定义了bin的环境变量,而且当前路径:/usr/local/redis/etc
1.命令:redis-server ./redis.conf
好像这里不用指定配置文件也可以启动,不过最好指定吧
2.命令:ps -ef | grep redis 查看端口是否打开如果看到了6379端口说明ok了
3.命令:redis-cli
4.自己使用:set/get命令玩两下,没问题就ok
5.quit 退出redis的客户端
6.退出服务器
(1) pkill redis-server
(2) 通过 ps -ef | grep redis 得到进程id,然后kill id
(3) redis-cli shutdown ( 完整:/usr/local/redis/bin/redis-cli shutdown )
三.主从复制
开始搭建集群,用的是本地三个虚拟机搭建的集群
我后面的两个虚拟机直接复制的第一个虚拟机,关机第一个虚拟机右击:管理->克隆->完整克隆
克隆后的虚拟机物理地址跟被克隆的相同,需要重新生成,请先关闭虚拟机。
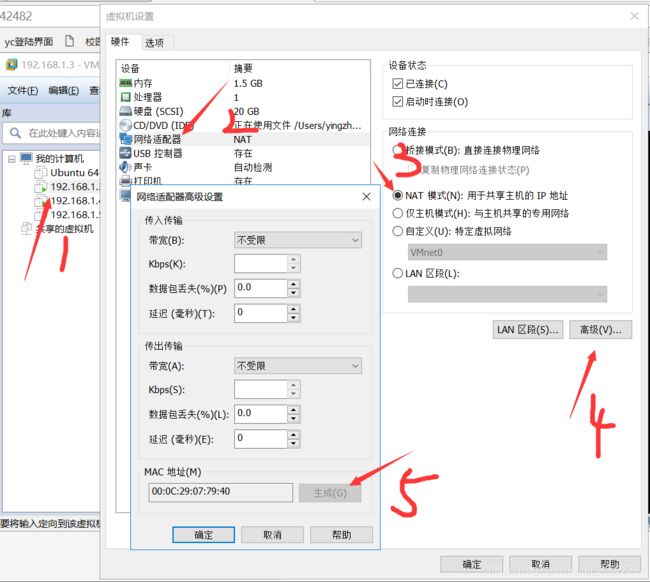
克隆两个虚拟机后开机ifconfig得到ip地址建议使用Xshell去连接你的虚拟机。
如果ifconfig得不到ip还请麻烦看我博客,有一篇专门解决ip找不到的。
ok,能同时连在一个网段就ok了,不在一个网段应该是网络连接没选择NAT模式的原因了,当然也可以使用桥连接,自行想办法解决吧,这里不多说了。
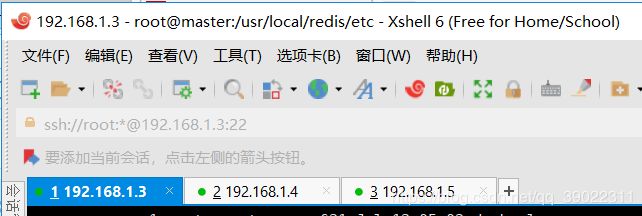
这里我把 192.168.1.3设置为主节点,其他两个设置为从节点
克隆过去的里面应该有我们已经配置好的redis,不过还需要再两个从节点里面修改下/usr/local/redis/etc/redis.conf 文件vim 进去:
输入:/slaveof 找到 #slaveof masterip masterport
在它下面写上:slaveof 主节点ip 主节点端口
例如我的:slaveof 192.168.1.3 6379
意思大概就是:为该节点的奴隶(从节点)
同理,第二太从节点虚拟机也是如此
多说一句:如果虚拟机不是克隆过去的,又不想重新安装一遍怎么办:
scp -r 文件 192.168.1.4:/usr/local/
直接发送文件过去就可以了192.168.1.4是目标虚拟机,后面指定复制的目录
最后,三台虚拟机都redis-server ./redis.conf一下开启redis然后redis-cli进入客户端输入:info
主节点显示role:master当前节点为主节点
connected_slaves:2连接两个从节点
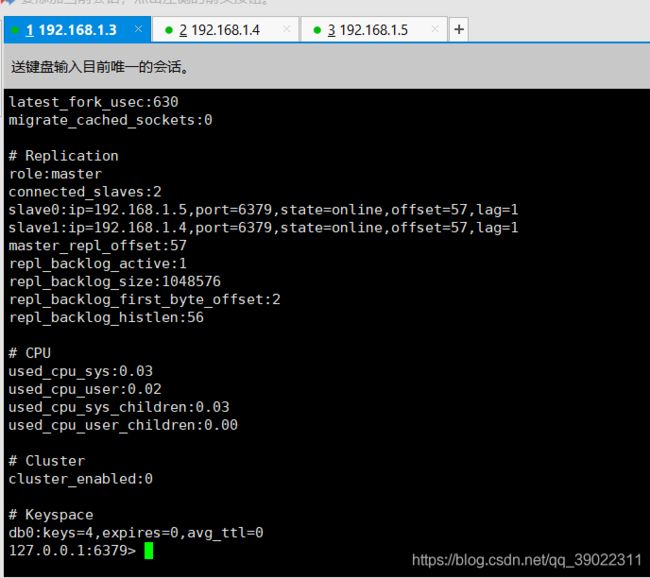
其中一个从节点信息
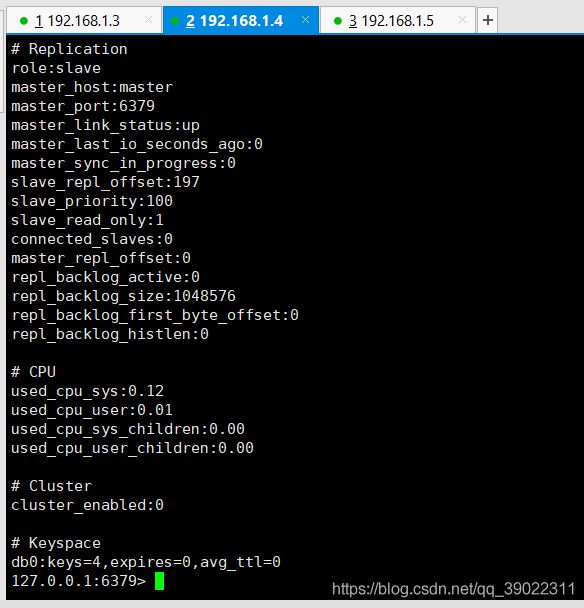
自己在主从节点 set/get 一下,数据会是同步的。
稍微值得注意的是:主节点主要用来写,从节点主要用来读。从节点不可以用来写,因为默认的配置文件是这样的,如果需要修改,很简单,去redis.conf配置文件找对应的地方改一下就可以了。所以说,redis集群搭建好了之后也算的上实现了数据库的读写分离了吧。
四.哨兵模式
既然是集群,那么就会有主服务器,那么如果主服务器突然崩掉了怎么办呢,那它下面的节点岂不是都跟着一起崩了,这样是非常危险的。
我们需要一个二十四小时实时监控redis集群状态的人,它可以实时监控到主节点的状态,并进行处理,这个人就是哨兵,如果主节点突然崩了,ok,那么哨兵就会对它的从节点进行处理,或者像zookeeper那样进行从节点内部的投票,亦或者其他的算法之类的,我也不太清楚,应该是投票吧,我看哨兵发出来的消息里面看到了有关投票的信息。
redis3以后好像都支持哨兵模式而且比较完善了。并且自带有对应的配置文件的,好的,下面我们使用下哨兵模式。
配置好集群后,随便找个从节点服务器吧,比如说我的从节点服务器192.168.1.4举个例子。
(1)将/usr/local/redis-3.0.0-rc2/目录下的sentinel.conf复制到/usr/local/redis/etc/中
(2)修改sentinel.conf文件:
sentinel monitor mymaster 192.168.1.3(主服务器ip) 6379 1 #名称,ip,端口.投票选举数
sentinel down-after-milliseconds mymaster 5000 #默认1s检测一次,这里配置超时5000毫秒为宕机
sentinel failover-timeout mymaster 900000
sentinel parallel-syncs mymaster 2
(3)启动sentinel哨兵
/usr/local/redis/bin/redis-server /usr/local/redis/etc/sentinel.conf --sentinel &
如果有东西输出直接:Ctrl+C 就ok
(4)查看哨兵相关信息
/usr/local/redis/bin/redis-cli -h 162.168.1.4 -p 26379 info sentinel (本从ip节点的哨兵信息)
(5)验证一下,关闭主节点会怎样:
/usr/local/redis/bin/redis-cli -h 192.168.1.3 -p 6379 shutdown (主节点ip)
关闭主节点后输出:

当宕机的主从节点又重新上线的时候,都将会从从节点开始,然后找机会选举变成master。
输出的这个东东看起来很杂,实际上很容易看懂,确实看到了主节点宕机后,从节点去veto-for-leader投票选举领导者去了,每行最后面都有@mymaster 接ip地址的,看的出来,主服务器的作用不会一瞬间就消失了,而给我的感觉是参与了从节点之间选举的过程,等到选出合适的主节点之后@mymaster后的ip地址才改变的。纯属个人理解。
五.redis集群搭建
就算是使用了哨兵模式,有了主从切换,但如果由于某些原因比如网络突然断了,哨兵监控到了进行切换,那也需要零点几秒甚至一两秒钟的时间,而我们知道,只有主节点才可以写入,redis的写入性能又是非常的好,可能那一两秒中就丢失了二三十万的数据这都是很正常的。那么哨兵模式的不足点也就出来了。
redis3.0支持集群的容错功能,并且非常简单,下面搭建一下redis的集群。
集群的搭建:至少需要三个master,所以还需要配三个slave
正常对我们测试来讲,不会真的开六台电脑或者开六台虚拟机去搭建测试集群吧。都知道,redis服务的启动,需要执行redis-serve 后面接上我们的配置文件,实际上启动的是我们的配置文件。我的理解是,你有几个不同的配置文件就可以启动多少个不同的redis。
第一步:创建一个文件夹redis-cluster,然后在其下面分别创建六个文件夹如下:
(1)mkdir -p /usr/local/redis-cluster
(2)cd /usr/local/redis-cluster
(3)mkdir 7001,mkdir 7002,mkdir 7003,mkdir 7004,mkdir 7005,mkdir 7006
第二步:把之前的redis.conf配置文件分别copy到700x文件下(x表示的是1~6),并进行修改各个文件内容,也就是对700x下的每个copy的redis.conf文件进行修改!(可以先只修改一个,然后再把修改过后配置文件复制到剩下的文件目录下,这样只需要更改端口号,文件存放目录和nodes文件就可以了)如下:
(1) daemonize yes
(2) port 700x(分别对每个机器的端口号进行配置,我设置的是端口号与当前文件名相同)
(3) bind 192.168.1.3 (必须绑定当前机器的ip,不然会有悲剧。。。)
(4) dir /usr/local/redis-cluster/700x/ (指定数据文件存放的位置,必须指定不同的目录文件。不然会数据丢失)
(5) cluster-enabled yes (启动集群模式)
(6) cluster-config-file nodes700x.conf (这里700x最好是和port对应上)
(7) cluster-node-timeout 15000 (这里默认是被注释掉的,取消注释或者复制粘贴出来就行)
(8) appendonly yes
第三步:由于redis集群需要使用ruby命令,所以我们需要安装ruby
(1) yum install ruby
(2) yum install rubygems
(3) gem install redis (安装redis和ruby的接口)
我安装这些的时候报错了,不知道为啥,跟着报错提示百度一个一个解决掉就好了。
第四步:分别启动6个实例,然后检查是否启动成功
(1) /usr/local/redis/bin/redis-server /usr/local/redis-cluster/700x/redis.conf (x表示1~6,所以一共要执行六次这行命令)
(2) netstat -tunpl | grep redis 查看是否启动成功,如下表示成功了
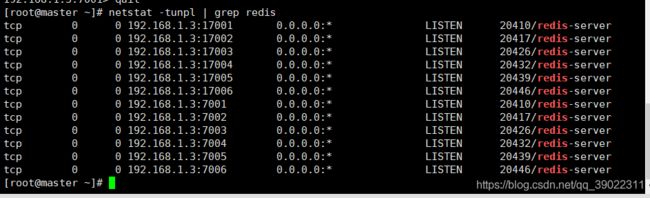
第六步:执行redis-trib.rb命令
(1) cd /usr/local/redis-3.0.0/src/ (cd到redis安装目录下的src目录下)
(2) ./redis-trib.rb create --replicas 1 192.168.1.3:7001 192.168.1.3:7002 192.168.1.3:7003 192.168.1.3:7004 192.168.1.3:7005 192.168.1.3:7006
create表示创建集群,replicas 后面的1,表示的是主节点/从节点的比例,前面的是主节点,后面的是从节点。因为我写的是1,而总共只有六台机器,所以像我这里,7001,7002,7003是主节点,7004,7005,7006是从节点,并且7001的从节点是7004,7002-7005,7003-7006这么对应来着的,我也不知道为啥,可能redis集群就是这么规定的吧。
直接输入命令./redis-trib.rb 可以看到它的用法:
(3)输入命令之后出现会出现:

从上图可以得到集群的信息:
集群成员,谁主节点master谁是slave,谁是谁的从节点。他们都有自己的id,前面很长的字符串。还有就是每个master都有属于它自己的slots-槽,用来操作数据的,比如7001它的槽标号从0-5460,其他的master槽标号是接上面一个的。
然后往下会出现个东西然你确定,你选择yes就OK!
然后开启redis-cli客户端进行查看,随便一个都ok,我这里开启的是7001节点的cli
值得注意的是,现在开启cli的格式是:redis-cli -c -h -p (-c:表示开启集群模式客户端,-h:指定ip,-p指定端口)
我这里输入的是:redis-cli -c -h 192.168.1.3 -p 7001
现在进入了客户端,输入cluster nodes 查看节点信息,命令:cluster info可以查看集群信息,节点信息结果如下: 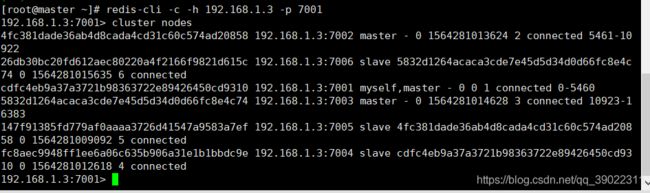
很明显的看的出不同端口的redis节点有对应的master和slave
(4)set/get 玩一下看看
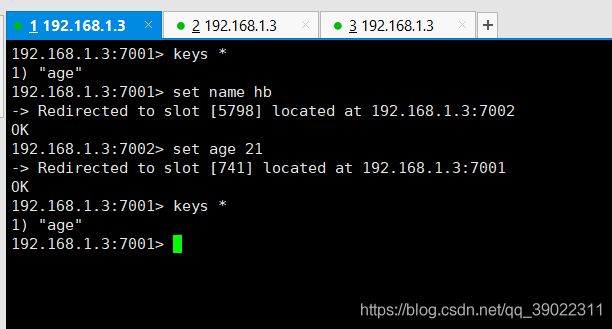
可以看到,我在7001节点 set name hb 的时候,它给我自动重定向到7002了,意思就是name这个数据被存储到了7002主节点上,并且存放在槽的5798这个位置上。然后我就在7002下 set age 21 的时候它又给我重定向到7001上,而且当我查看7001的所有键的时候只出现了 "age"这一个键,所以说不是说哪个主节点存储的数据,该数据就一定会被存储到哪个节点上,这个都是集群自己根据存储性能去自动分配存储的。但是不论是存储在哪个主节点的数据,任何一个主从节点都可通过get命令去得到该数据的值。所以说做到这里我们的redis集群已经搭建完成啦。
优点:当我们主节点突然崩掉的时候,我们还有另外的主节点去进行存储数据,这样就不会导致一个主节点掉线时,会损失期间数据的情况啦。