Python爬虫使用selenium爬取淘宝商品信息并保存到MongoDB中
一、前期准备
需要首先安装好以下的软件
1.chrome浏览器
2.chromedriver (和浏览器的版本要对应)
3.selenium浏览器自动化测试框架
4.MongoDB数据库 (可以的话安装可视化工具Robo 3T)
Mac电脑下没有安装好的话可以看我的其他博客,我使用的IDE是Pycharm,python版本为3.7,chrome浏览器版本版本 75.0.3770.100
参考的视频教程来自b站,网址:https://www.bilibili.com/video/av53677037?from=search&seid=14296622930461546633
二、分析流程
这次要爬取的信息是淘宝的商品信息,这个爬虫的目的是根据用户的输入,爬取到相关商品的标题,价格,图片等信息。首先我们登录淘宝网,然后需要在搜索框内输入关键词并点击搜索。之后会要求登录,因为只需要登录一次,所以可以使用扫码登录。登录之后会跳出相关商品信息,根据相关的id,xpath等可以找到对应的元素然后获取,本页信息收集完之后进行分页信息收集,之后将收集到的信息保存到我们的MongoDB数据库中就好。
三、代码编写
(一)搜索登录
首先我们使用selenium来模拟我们人为输入信息,登录的一个过程。比如这次我们想要搜索有关java的相关信息,首先我们需要打开淘宝网,然后填入java,模拟点击的按钮。使用chrome浏览器按F12可以检查页面,按左上角的小图标,这样就可以找到相关元素的id,class等信息。
from selenium import webdriver # 获取数据 解析数据
driver = webdriver.Chrome() # 模拟使用的浏览器
driver.get('http://www.taobao.com') # 打开url指向的网页
driver.find_element_by_id('q').send_keys(keyword) # 根据id找到输入框并自动填入信息
driver.find_element_by_class_name('btn-search').click() # 根据classname找到搜索按钮并点击之后跳到登录页面,我们选择扫码登录,这边可以导入time,让程序停止10s等待我们扫码,之后我们就能跳到相关商品的页面
进入这个页面后,我们首先要获取的是这个商品总共有多少页的信息,可以看到有100页信息

然后我们根据xpath可以获取到共100页这个字符串,再导入re,使用正则表达式将总页数提取出来。
time.sleep(10) # 程序等待10秒,扫码登录
pages = driver.find_element_by_xpath('//*[@id="mainsrp-pager"]/div/div/div/div[1]').text #获取总页数信息
pages = int(re.compile('\d+').search(pages).group(0) )# 使用正则表达式找到
return pages # 返回总页数我们可以把这部分内容统一放到一个叫search的方法中
def search():
driver.find_element_by_id('q').send_keys(keyword) # 根据id找到输入框并自动填入信息
driver.find_element_by_class_name('btn-search').click() # 根据classname找到搜索按钮并点击
time.sleep(10) # 程序等待10秒,扫码登录
pages = driver.find_element_by_xpath('//*[@id="mainsrp-pager"]/div/div/div/div[1]').text #获取总页数信息
pages = int(re.compile('\d+').search(pages).group(0) )# 使用正则表达式找到
return pages(二)获取相关信息
检查页面元素,我们可以发现所有的商品信息都在一个class为items的div下面,我们首先根据xpath找到这个div,然后进行遍历,再在各个元素中根据xpath找到相关的信息。

代码如下:
def get_product(): # 获取数据
lis = driver.find_elements_by_xpath('//div[@class="items"]/div[@class="item J_MouserOnverReq "]')
# 根据xath获取关于商品的多个div中的数据
for li in lis:
title = li.find_element_by_xpath('.//div[@class="row row-2 title"]').text # 获取标题的有关信息
price = li.find_element_by_xpath('.//a[@class="J_ClickStat"]').get_attribute('trace-price') # 获取价格信息
shop = li.find_element_by_xpath('.//div[@class="shop"]/a/span[2]').text # 店铺信息
image = li.find_element_by_xpath('.//div[@class="pic"]/a/img').get_attribute('src') # 图片信息
print(title + '| ¥' + price + ' | ' +shop + '|' + image)(三)下拉功能实现
我们之前获取信息的话,很多的图片其实没有被加载出来,那我们只会获取到https://g.alicdn.com/s.gif数据,所以在获取数据前,我们需要模拟使用下拉页面,加载出全部数据后再进行获取。这边可以使用js代码来实现,用selenimu调用相关的代码
def drop_down(): # 模拟人手向下滑,加载出图片
for x in range(1,11,2):
time.sleep(0.75) # 下拉之间有时间间隔
j = x /10;
js = 'document.documentElement.scrollTop = document.documentElement.scrollHeight * %f' % j # 获取页面的滚动条位置
driver.execute_script(js) #selenium 调用js(四)翻页功能实现
获取完当前页面的信息后,我们就需要翻到下一页,首先我们分析一下不同页面的url,下面是1,2,3三个页面的url
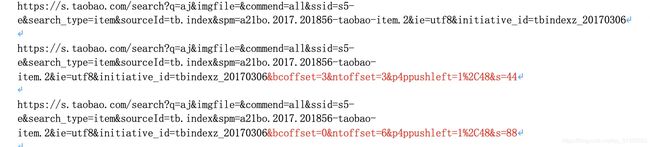
发现在最后是同的,第一页是0,第二页是44,第三页是88,那我们吧之前的信息都删除了,只留下下面的url
https://s.taobao.com/search?q=java&s=0
https://s.taobao.com/search?q=java&s=44
https://s.taobao.com/search?q=java&s=88
发现都可以跳转到相关的页面,所以在翻页这边,我们就可以使用selenium打开不同的url进行翻页,之前我们收集到的总页数也在这边可以使用,总共100页,那我们翻99次就可以到最后一页,翻页之后我们再执行下拉,再获取数据,代码如下:
def next_page():
pages = search()
num = 0
while num != pages-1:
driver.get('https://s.taobao.com/search?q=java&s={}'.format(num * 44))
driver.implicitly_wait(10) # 隐式等待
num += 1
drop_down()
get_product()(五)存入数据库
我们这边使用的是MongoDB数据库,在使用之前首先要启动服务。
首先连接数据库
import pymongo
client = pymongo.MongoClient(host='localhost', port=27017) # 传入参数连接数据库
# 也可以 client = MongoClient('mongo://localhost:27017')
# 指定数据库
db = client.local
# 指定表
collection = db.Taobao在get_product方法中加入添加数据的代码
info = {
'title': title,
'price': price,
'shop': shop,
'img': image
}
result = collection.insert_one(info) # insert 方法插入三、运行结果
可以看到ide下方有打印出相关信息

数据库中也已经进行了存储

四、代码总结
我们对代码再进行一些小修改,我们不可能每次搜索商品都在代码中修改,所以可以加入一个keyword,根据输入的不同来爬取不同的信息。最后完整代码如下:
from selenium import webdriver # 获取数据 解析数据
import time # 导入时间模块,进行等待
import re
import pymongo
def search():
driver.find_element_by_id('q').send_keys(keyword) # 根据id找到输入框并自动填入信息
driver.find_element_by_class_name('btn-search').click() # 根据classname找到搜索按钮并点击
time.sleep(10) # 程序等待10秒,扫码登录
pages = driver.find_element_by_xpath('//*[@id="mainsrp-pager"]/div/div/div/div[1]').text #获取总页数信息
pages = int(re.compile('\d+').search(pages).group(0) )# 使用正则表达式找到
return pages
def next_page():
pages = search()
num = 0
while num != pages-1:
driver.get('https://s.taobao.com/search?q={}&s={}'.format(keyword,num * 44))
driver.implicitly_wait(10) # 隐式等待
num += 1
drop_down()
get_product()
def drop_down(): # 模拟人手向下滑,加载出图片
for x in range(1,11,2):
time.sleep(0.75) # 下拉之间有时间间隔
j = x /10;
js = 'document.documentElement.scrollTop = document.documentElement.scrollHeight * %f' % j # 获取页面的滚动条位置
driver.execute_script(js) #selenium 调用js
def get_product(): # 获取数据的函数
lis = driver.find_elements_by_xpath('//div[@class="items"]/div[@class="item J_MouserOnverReq "]')
# 根据xath获取关于商品的多个div中的数据
for li in lis:
title = li.find_element_by_xpath('.//div[@class="row row-2 title"]').text # 获取标题的有关信息
price = li.find_element_by_xpath('.//a[@class="J_ClickStat"]').get_attribute('trace-price') # 获取价格信息
shop = li.find_element_by_xpath('.//div[@class="shop"]/a/span[2]').text # 店铺信息
image = li.find_element_by_xpath('.//div[@class="pic"]/a/img').get_attribute('src') # 图片信息
info = {
'title': title,
'price': price,
'shop': shop,
'img': image
}
result = collection.insert_one(info) # insert 方法插入
print(title + '| ¥' + price + ' | ' +shop + '|' + image)
if __name__ == '__main__':
keyword = input("输入想要的商品信息:")
client = pymongo.MongoClient(host='localhost', port=27017) # 传入参数连接数据库
# 也可以 client = MongoClient('mongo://localhost:27017')
# 指定数据库
db = client.local
# 指定表
collection = db.Taobao
driver = webdriver.Chrome() # 模拟使用的浏览器
driver.get('http://www.taobao.com') # 打开url指向的网页
next_page()