复习之路之JAVA多线程基础面试题
我自己总结的,我觉得很全了,本篇章针对多线程基础,不包括JUC
有几种实现线程的方法?
从不同的角度看有不同的答案,通常来说,可以分为两类,继承和实现的两种方式。
准确的讲,实现线程只有一种方式,那就是构造Thread类,但是在Thread类里面,他的run方法有两种情况。
第一种,实现一个runnable接口,重写他的run方法,然后再把这个实例传给Thread类,再让Thread类执行这个run方法。
第二种 直接重写Thread类的run方法,两种方法精确地来讲,就是构造线程的执行单元(run)的两种方式。
其实在 Executor 框架中还有一种方法可以实现异步,那就是实现 Callable 接口并重写call方法。虽然是实现 Callable,但是在 Executor 实际运行时,会将 Runnable 的实例或 Callable 的实例转化为 RunnableFuture
的实例,而 RunnableFuture 继承了 Runnable 和 Future 接口。
实现接口和类哪种方式更好?
如果实现thread类来实现线程,执行任务的时候必须new一个这样的一个类。我们需要新建一个线程,之后还要销毁,这样子做的损耗比较大。如果我们采用另外一个方法,传入runnable接口实例的方法。我们就可以反复的利用这同一个线程,比如说线程池就是这么做的。(java不支持多继承,如果未来有需求要继承一个公共的继承,但那是这样就办不到了,这是非常可怕的事情。)
线程的start和run区别?
start启动的时候回首先检查现成的状态是否为0 线程初始化的时候状态都是0 如果不是为0 说明已经启动过了,就会抛出异常。如果没有启动过,就会加入线程组,然后通知jvm准备开启一个线程,开启线程成功后,调用线程的run方法。
run方法就是一个普通的方法,根据是否重写的情况,有不同的区别。如果传入的是接口实例,就会执行接口实例的方法,否则执行的是重写的方法。如果同时传入了接口实例和重写了方法,执行的仍然是重写的方法。
所以说调用start的方法,才是真正意义上开辟了一个线程,会经历线程的生命周期,run只是一个普通的方法。
如何正确的停止线程
普通情况下停止线程
public class RightWayStopThreadWithoutSleep implements Runnable {
@Override
public void run() {
int num=0;
while (num<=Integer.MAX_VALUE/2){
if (num % 10000==0){
System.out.println(num+"是10000的倍数");
}
num++;
}
System.out.println("任务结束");
}
public static void main(String[] args) throws InterruptedException {
Thread thread=new Thread(new RightWayStopThreadWithoutSleep());
thread.start();
Thread.sleep(500);
//只是通知了 改变了标志位 线程不会停止 while循环会执行完
thread.interrupt();
}
}
public class RightWayStopThreadWithoutSleep implements Runnable {
@Override
public void run() {
int num=0;
while (num<=Integer.MAX_VALUE/2){
//通过结合标志位来停止循环
if (num % 10000==0&&!Thread.currentThread().isInterrupted()){
System.out.println(num+"是10000的倍数");
}
num++;
}
System.out.println("任务结束");
}
public static void main(String[] args) throws InterruptedException {
Thread thread=new Thread(new RightWayStopThreadWithoutSleep());
thread.start();
Thread.sleep(500);
//只是通知了 改变了标志位 线程不会停止
thread.interrupt();
}
}
你看了上米娜的代码,可能会有疑惑,既然通过interrupt停止不了,那么还要他干嘛?不要急,后面会说。
阻塞情况下停止线程
public static void main(String[] args) {
Runnable runnable=new Runnable() {
@Override
public void run() {
int num=0;
while (num<=300&&!Thread.currentThread().isInterrupted()){
if (num %100==0){
System.out.println(num+"是100的倍数");
}
num++;
}
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
};
Thread thread=new Thread(runnable);
thread.start();
try {//此时线程还在睡眠
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
thread.interrupt();
}
}
结果:
0是100的倍数
100是100的倍数
200是100的倍数
300是100的倍数
java.lang.InterruptedException: sleep interrupted
at java.lang.Thread.sleep(Native Method)
at syn.RightWayStopThreadWithSleep$1.run(RightWayStopThreadWithSleep.java:20)
at java.lang.Thread.run(Thread.java:748)
停止线程的错误方法
被弃用的stop ,suspend和resume
stop会导致线程突然停止,没办法完成一个基本单位的操作。事务不能回滚。造成脏数据
suspend带锁挂起,很容易造成死锁问题。resume是他的配套方法,自然废弃。
用volatile设置标志位 错误
在生产者消费者模式中,阻塞队列,生产速度快,消费速度慢。在循环体里用volatile标志位不可取,线程会阻塞在阻塞队列的put方法上。
public class WrongWayVolationCantStop {
public static void main(String[] args) throws InterruptedException {
ArrayBlockingQueue blockingQueue=new ArrayBlockingQueue<>(10);
Producer producer=new Producer(blockingQueue);
Thread producerThread=new Thread(producer);
producerThread.start();
Thread.sleep(1000);
Consumer consumer=new Consumer(blockingQueue);
while (consumer.needMoreNums()){
System.out.println(consumer.storage.take()+"被消费了");
Thread.sleep(100);
}
System.out.println("消费者不需要数据了");
producer.canceled=true;
}
}
class Producer implements Runnable{
public volatile boolean canceled =false;
BlockingQueue storage;
public Producer(BlockingQueue storage) {
this.storage = storage;
}
@Override
public void run() {
int num=0;
try {
while (num <= 100000&&!canceled){
if (num%100==0){
//会阻塞在这里
storage.put(num);
System.out.println(num+"是100的倍数。放到仓库中");
}
num++;
}
}catch (InterruptedException e) {
e.printStackTrace();
}finally {
System.out.println("生产者停止运行");
}
}
}
class Consumer{
BlockingQueue storage;
public Consumer(BlockingQueue storage) {
this.storage = storage;
}
public boolean needMoreNums(){
if (Math.random()>0.95){
return false;
}
return true;
}
}
上面的代码,生产快,消费慢,所以队列很快就会满,就会出现这样的情况,其实队列已经满了,生产者阻塞在PUT方法上 ,并不会循环了,这个时候你就是改变了volatile标记,也没有用。
正确的办法应该是用过interrupt通知线程总断
package volatileDemo;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
/**
* @Author:FuYouJie
* @Date Create in 2020/2/8 15:30
*/
public class WrongWayVolationCantStopFixed {
public static void main(String[] args) throws InterruptedException {
WrongWayVolationCantStopFixed body=new WrongWayVolationCantStopFixed();
ArrayBlockingQueue blockingQueue=new ArrayBlockingQueue<>(10);
Producer producer=body.new Producer(blockingQueue);
Thread producerThread=new Thread(producer);
producerThread.start();
Thread.sleep(1000);
Consumer consumer=body.new Consumer(blockingQueue);
while (consumer.needMoreNums()){
System.out.println(consumer.storage.take()+"被消费了");
Thread.sleep(100);
}
System.out.println("消费者不需要数据了");
producerThread.interrupt();
}
class Producer implements Runnable{
BlockingQueue storage;
public Producer(BlockingQueue storage) {
this.storage = storage;
}
@Override
public void run() {
int num=0;
try {
while (num <= 100000&&!Thread.currentThread().isInterrupted()){
if (num%100==0){
storage.put(num);
System.out.println(num+"是100的倍数。放到仓库中");
}
num++;
}
}catch (InterruptedException e) {
e.printStackTrace();
}finally {
System.out.println("生产者停止运行");
}
}
}
class Consumer{
BlockingQueue storage;
public Consumer(BlockingQueue storage) {
this.storage = storage;
}
public boolean needMoreNums(){
if (Math.random()>0.95){
return false;
}
return true;
}
}
}
以上代码读者可以复制下去运行试试。
如何正确的停止线程?
正确的停止线程的方法应该是使用interrupt方法,但是使用这个也是需要三方配合的。请求放通过调用interrupt方法来告诉线程你该停止了,而需要停止的线程需要在每次循环或者适当的地方判断interrupt标志。并且在可能抛出interruptedException的地方处理这个信号。每一个线程都应该做这样的事情以此保证他是可以被停止的。作为此方法,优先抛出异常让上层方法知道。避免吞异常导致线程不能及时正确的响应。只要3方配合合理,就可以停止线程。
而stop方法停止线程的方法虽然可以立刻停止线程,但是正是因为如此,这回导致线程不能完成一个基本单位的操作,例如在事务中,不能给线程时间使其正确的回滚。
suspend方法在挂起线程的时候,不会释放锁。在唤醒线程或者其他线程也需要这把锁的时候,很有可能造成死锁的问题。
另外还有很多人喜欢用volatile来设置标志位,其实这也是不对的。在生产者消费者模式中,线程往往会阻塞在添加或者消费的时候,此时就算使用了volatile,也不能停止线程,线程会一直阻塞。
JAVA线程有哪6个状态?生命周期是什么
其实这里用文字写不好,可以看看网上的图。
1.New
线程开始创建还没有start
**2.Runnable **(可运行/运行中)
调用start方法后,属于此状态。
New (start)–>Runnable
Blocked (获取锁)–>Runnable
Timed Waiting/Waiting (Object.notify() Object.notifyAll() LockSupport.unpark() 超时----> Runnable
3.Blocked
当一个线程进入被synchronized修改的代码块,并且锁已经被其他线程获取,当前线程处于Blocked
还有当线程处于wait被唤醒却没有得到锁,也是blocked状态
4.Waiting
Runnable (Object.wait) (Thread.join) LockSupport.park() —>Waiting
5.Timed Waiting
Runnable Thread.sleep(time) Object.wait(time) Thread.join(time) LockSupport.parkNanos/parkUntils(time) ->Timed Waiting
6.Terminated
public class NewRunnableTerminate implements Runnable {
@Override
public void run() {
for (int i = 0; i <1000 ; i++) {
System.out.println(i);
}
}
public static void main(String[] args) throws InterruptedException {
Thread thread=new Thread(new NewRunnableTerminate());
//New
System.out.println(thread.getState());
thread.start();
Thread.sleep(10);
//Runnable
System.out.println(thread.getState());
Thread.sleep(2000);
//Terminate
System.out.println(thread.getState());
}
}
public class BlockWaitingTimedWaiting implements Runnable {
public static void main(String[] args) throws InterruptedException {
BlockWaitingTimedWaiting runnable=new BlockWaitingTimedWaiting();
//传入的同一个Runnable 所以是同一把锁
Thread thread1=new Thread(runnable);
Thread thread2=new Thread(runnable);
thread1.start();
thread2.start();
Thread.sleep(500);
//TIMED_WAITING
System.out.println(thread1.getState());
//WAITING
Thread.sleep(1000);
System.out.println(thread1.getState());
//BLOCKED
System.out.println(thread2.getState());
}
@Override
public void run() {
syn();
}
//注意这里有一个锁
private synchronized void syn(){
try {
//time waiting 条件
Thread.sleep(1000);
//waiting 条件
wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
通俗来讲,阻塞指的是blocked(阻塞),waiting(等待) ,timed waiting(计时等待)
交替打印奇数偶数
public class Syn {
private volatile static int count=0;
private static Object lock=new Object();
public static void main(String[] args) {
new Thread(new Runnable() {
@Override
public void run() {
while (count <= 100){
if((count&1) == 0){
synchronized (lock){
System.out.println(Thread.currentThread().getName()+count++);
}
}
}
}
},"偶数").start();
new Thread(new Runnable() {
@Override
public void run() {
while (count <= 100){//两个线程不停的轮询 浪费了CPU资源
if((count&1) == 1){
synchronized (lock){
System.out.println(Thread.currentThread().getName()+count++);
}
}
}
}
},"奇数").start();
}
}
public class WaitNotify {
private static Object lock=new Object();
private static int count=0;
static class Runner implements Runnable{
@Override
public synchronized void run() {
while (count <=100){
synchronized (lock){
System.out.println(count++);
//唤醒他人
lock.notify();
if (count <=100){
try {//休眠自己
lock.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
}
}
public static void main(String[] args) {
new Thread(new Runner()).start();
new Thread(new Runner()).start();
}
}
为什么wait需要在同步代码块使用,而sleep不需要?
为了让通信变得可靠,防止死锁或者永久等待的发生,如果不把wait notify放在同步代码块里面,执行wait之前,线程突然切过去了,切换到另外一个执行notify的线程,因为没有代码块保护,随时都可以切换。这样对面的一个线程把notify的代码执行完毕了,执行完毕之后再来执行wait,可是他们本身设计逻辑不是这样,应该是先执行完wait之后,再去执行notify去唤醒他,可是如果没有了同步的保护,notify的代码已经执行完毕了,这样会导致进入wait的线程永远没有人去唤醒他。导致永久等待或者死锁。所以在java设计的时候,考虑到这样的问题,就把线程间互相配合的方式就放在同步代码块里面去做了。
而Sleep,他只是本身自己单独线程的,和其他线程关系并不大。
为什么wait notify定义在Object里面,而Sleep定义在Thread里面?
wait notify是一个锁级别的操作,锁是属于某个对象的,每一个对象他的对象头中都有几位来保存锁的状态,所以锁是保存在对象中,而不是线程中,同样道理,假设把wait notify定义在线程中,会造成很大大的局限性,这样一来每个线程确实可以休眠等待,但是我们会经常有这种情况,每个线程持有多个锁,并且锁之前是相互配合的。这样一来某一个线程可以持有多把锁,如果不把wait定义在Object里面,就没有办法实现这样灵活的逻辑(多把锁)。
wait是属于Object的,那么调用Thread.wait()会怎么样?
Thread也是属于一个对象,继承Object.但是Thread类比较特殊,线程在退出的时候,会自动执行Notify,这样会使我们设计的流程,受到干扰。所以我们一般不使用Thread创建锁对象。
唤醒所有线程后,如果某线程抢夺锁失败后会怎么样。?
只不过是回到了最初始的状态,最开始也是多个线程在抢夺同一把锁,就会进入等待。等待持有者去释放锁,再去抢夺。或者是再接收线程调度器的的调度去拿到这把锁。
用suspend和 resume来阻塞线程可以吗?
不可以,谢谢
Sleep方法 详解
让线程在预期的时候执行,其他的时候不占用Cpu资源。不释放锁,包括synchronized和lock.
sleep期间被中断,会抛出InterruptedException异常并且清除中断状态
wait notify sleep异同?
wait必须在同步代码块,释放锁。再结合前面的设计思想
join方法
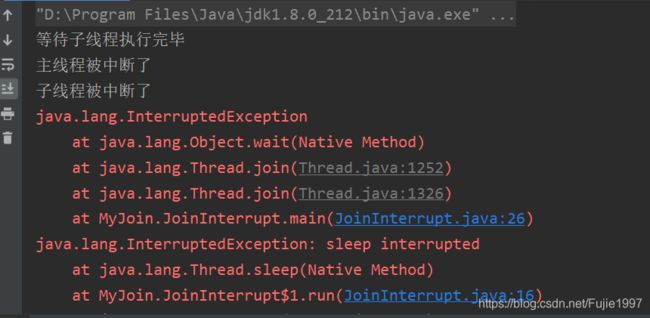
主线程我那个等待子线程执行完毕的时候,主线程被中断,子线程并不会中断,所以主线程要正确的传递中断给子线程。join时属于waiting
public static void main(String[] args) {
Thread mainThread=Thread.currentThread();
Thread thread1=new Thread(new Runnable() {
@Override
public void run() {
//中断主线程
mainThread.interrupt();
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
System.out.println("子线程被中断了");
e.printStackTrace();
}
}
});
thread1.start();
System.out.println("等待子线程执行完毕");
try {
thread1.join();
} catch (InterruptedException e) {
System.out.println("主线程被中断了");
thread1.interrupt();
e.printStackTrace();
}
}
yield方法
作用:释放我的CPU时间片,不会释放锁。但是立刻参与竞争。依然是runnable(JAVA里面把ready 和running整合成 runnablle)状态。
JVM不保证遵循这原则。开发时一般不使用。但是工具包里面很多
守护线程和普通线程的区别?
整体上没区别,惟一的区别在于是否能影响JVM到的离开。用户线程会影响到JVM的退出,守护线程则不会。守护线程告诉JVM,你不需要等待我执行完毕后退出。用户线程是执行我们的逻辑的,守护 线程是服务我们的。
不应该把自己的线程设置成守护线程,会导致JVM的退出了,而导致我们的操作被终止。
线程未捕获异常如何处理?UncaughtException
为什么需要使用UncaughtExceptionHandler?
-
主线程可以轻松发现异常 ,子线程却不行
-
子线程无法用传统方法捕获
public class CantCatchDirectly implements Runnable {
public static void main(String[] args) throws InterruptedException {
try {
new Thread(new CantCatchDirectly(),"MyThread-1").start();
Thread.sleep(300);
new Thread(new CantCatchDirectly(),"MyThread-2").start();
Thread.sleep(300);
new Thread(new CantCatchDirectly(),"MyThread-3").start();
Thread.sleep(300);
new Thread(new CantCatchDirectly(),"MyThread-4").start();
}catch (RuntimeException e){
//抓不到子线程的异常 执行看看,你会发现这里屁事没有
System.out.println("Caught Exception");
}
}
@Override
public void run() {
throw new RuntimeException();
}
}
- 解决 方案1 :
(不推荐)手动在每个run方法里面加入try catch
public class CantCatchDirectly implements Runnable {
public static void main(String[] args) throws InterruptedException {
new Thread(new CantCatchDirectly(),"MyThread-1").start();
Thread.sleep(300);
new Thread(new CantCatchDirectly(),"MyThread-2").start();
Thread.sleep(300);
new Thread(new CantCatchDirectly(),"MyThread-3").start();
Thread.sleep(300);
new Thread(new CantCatchDirectly(),"MyThread-4").start();
}
@Override
public void run() {
try {
throw new RuntimeException();
}catch (RuntimeException e){
System.out.println("子线程Caught Exception");
}
}
}
解决方法2:
实现自己UncaughtExceptionHandler
给程序统一设置
给每个线程单独设置
给线程池设置
设置自己的捕获器
public class MyUncaughtExceptionHandler implements Thread.UncaughtExceptionHandler {
private String name;
@Override
public void uncaughtException(Thread t, Throwable e) {
Logger logger=Logger.getAnonymousLogger();
logger.log(Level.WARNING,"线程异常!"+ t.getName(),e.toString());
System.out.println(name+"捕获了异常");
}
public MyUncaughtExceptionHandler(String name) {
this.name = name;
}
}
使用自己的捕获器
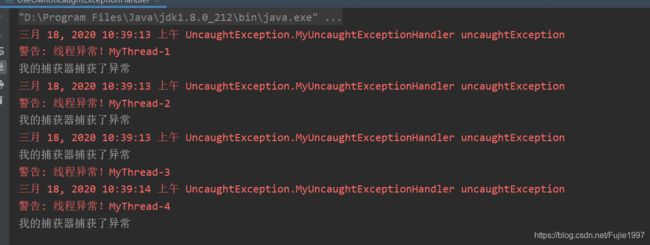
public class UseOwnUncaughtExceptionHandler implements Runnable {
public static void main(String[] args) throws InterruptedException {
//使用捕获器
Thread.setDefaultUncaughtExceptionHandler(new MyUncaughtExceptionHandler("我的捕获器"));
new Thread(new UseOwnUncaughtExceptionHandler(),"MyThread-1").start();
Thread.sleep(300);
new Thread(new UseOwnUncaughtExceptionHandler(),"MyThread-2").start();
Thread.sleep(300);
new Thread(new UseOwnUncaughtExceptionHandler(),"MyThread-3").start();
Thread.sleep(300);
new Thread(new UseOwnUncaughtExceptionHandler(),"MyThread-4").start();
}
@Override
public void run() {
throw new RuntimeException();
}
}
run方法是否可以抛出异常?
run方法在方法层面不可以向外抛出异常了,只能自己做try catch处理。对于try catch里面,如果是向runtimeException,又没有提前对他做异常的捕获,那么就会抛出一个异常,并且线程会终止。打出异常堆栈
线程如何处理某个未处理异常?
前面说了,定义一个全局异常处理器 实现UnCaughtExceptionHandler 实现里面的方法。
什么是线程安全?
不管在业务中遇到怎样的多个线程访问某对象或者某方法的清况,而在编程这个业务逻辑的时候,都不需要额外的做任何额外的处理,程序也可以正确的运行,就可以称为线程安全。(会降低运行速度,增加设计成本)
不安全情况举例子:get的时候set 需要额外的同步保证
所有依赖时序的操作,及时每一步的操作是线程安全的,但是仍然存在安全问题。读取-修改-写 、检查-执行、不同的数据之间存在绑定关系 ,任何一个除了问题,其他的都不能用了。比如ip和端口号。
为什么多线程会带来性能问题?
1.调度:上下文切换
什么是上下文?
保存的现场信息就是上下文
什么是上下文切换?
CPU阻塞某个线程,并保存他的现场信息,然后调度另一个线程,使其进入Runnable状态。(开销特别大,某时候超过了线程执行的时间)。通常一次上下文切换,会消耗5000到10000个CPU时钟周期, 大约是几微秒,对于CPU而言,是一个非常大的性能开销。
缓存开销
程序有很大概率会访问之前已经访问过的数据,比如说FOR循环啊,所以说CPU为了加快执行速度,做一个预测 ,吧不同的结果缓存到CPU里面。这样下次使用的时候,直接读取缓存就行了。但是上下文切换的时候,原来的缓存就会没有价值,执行其他代码的时候,CPU又要重新缓存,导致线程在调度之后,一开始的执行比较慢,因为原先的缓存大部分都失效了。所以CPU为了防止这种过于频繁的上下文切换,带来过于大的缓存开销,通常会设置一个最小执行时间,也就是说两次上下文切换时间不得小于这个最小执行时间。
何时会导致密集的上下文切换
程序频繁的竞争锁,经常去IO读写或者其他原因导致的线程阻塞。
2.协作:内存同步
编译器对程序做的优化,指令重排序等等,让缓存利用的机会多一些。对锁进行优化,JVM发现某些锁是没有必要的,他就把锁给自动的删除了。或者在内存方面,由于JMM规定是有主内存以及各个CPU自己的缓存的,使用缓存能够加快执行速度,不必要每次去和主内存进行同步。但是呢,在多线程下,经常用syn和volatile这些关键字让缓存失效,这样会由于内存同步的问题带来性能的开销。
为什么会有可见性问题?
CPU有多级缓存,导致读的数据可能会过期。高速缓存的容量比主内存小,但是速度仅次于寄存器,所以在CPU和主存之间就多了Cache层。线程之间的对于共享变量的可见性并不是直接由多核引起的,而是由多层缓存引起的,如果所有的核心都只用一个缓存,那么也就不存下内存可见性问题。

每个核心都会将自己需要的数据读到独占缓存中,数据修改后也是写到缓存中,然后等待刷入到主存中,所以会导致有些核心读取到的是一个过期的值。
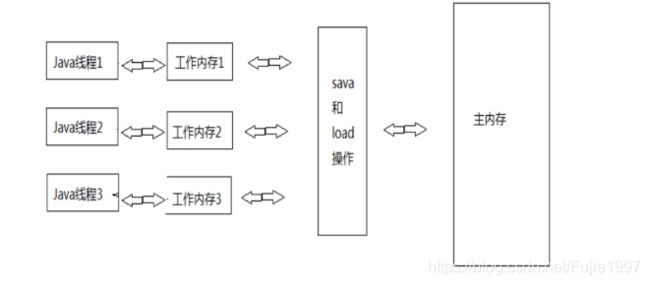
JMM内存抽象
JMM定义了一套读写数据的规范,抽象了主内存本地内存的概念。这里的本地内存不是指给每个线程分配的内存,而是将寄存器,一级缓存,二级缓存等的抽象。
什么是Happens-before 原则?
1.)Happens-before 规则是用来解决可见性问题的:在时间上,动作A发生在动作B之前,B保证能看见A,这就是Happens-before 原则。
2.)如果一个操作Happens-before 第二个操作,那么我们就说第一个操作对于第二个操作是可见的。
happens-before规则有哪些?
1.)单线程规则
后面的语句一定能看见前面的代码的操作
2.)锁操作
A线程解锁了,B线程获得了同样的锁,那么B一定能看到A的所有操作
3.)volatile变量
多线程之间读取到volatile变量的所有操作。且与volatile变量有关的变量也能保证可见,volatile写入之前的操作,其余变量的可见。
4.)线程启动
子线程能看见主线程的所有操作
5.)线程的join
在B中执行A.join();A happens-before B 同4
6.) 具有传递性
hb(AB),hb(B,C),那么A hb C
7.)中断
一个线程被中断,其他线程一定能感知
8.) 并发工具类的happens-before 原则
a. 线程安全的容器get一定能看见在此之前的put操作。
b.CountDownLatch
c.Semaphore 获取许可证之前必须有人释放
d.CyclicBarrier 必须达到释放的条件
e. future get方法一定是拿到执行完后的结果
f.线程池中提交的任务,每一个任务都可以看到提前之前的所有结果。
volatile关键字
volatile 是一种比锁更加轻量的同步操作,仅仅是刷回主内存这个操作,不会发生上下文切换这种开销。如果一个变量被volatile修饰,JVM便会知道这个变量是可能被并发修改的,会进行一系列操作,比如进制重排序等等。
volatile开销小,责任也小,volatile做不到锁的原子性。
不使用的场景 a++
/**
* @author FuYouJ
* @date 2020-02-15 11:52
* volatile 不适合A++
*/
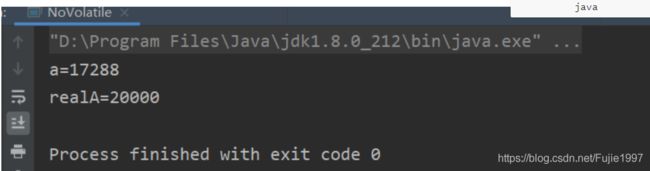
public class NoVolatile implements Runnable {
volatile int a=0;
AtomicInteger realA=new AtomicInteger();
@Override
public void run() {
for (int i = 0; i <10000 ; i++) {
a++;
realA.incrementAndGet();
}
}
public static void main(String[] args) throws InterruptedException {
Runnable r=new NoVolatile();
Thread thread1=new Thread(r);
Thread thread2=new Thread(r);
thread1.start();
thread2.start();
thread1.join();
thread1.join();
//小于200000
System.out.println("a="+((NoVolatile)r).a);
System.out.println("realA="+((NoVolatile)r).realA);
}
}
适合的场景1
类似于boolean flag 单纯的赋值操作不依赖原先的值(不适合消费者生产者模式)
这样的代码是可行的
flag=true;
a=6;
这样的代码是不可行的
flag=!flag;
a=a+1;
boolean的复制并不是一般的先读取,再改写,再回写3步操作,而是原子性的1步操作。
适合的场景2 作为刷新之前变量的触发器
那么以下代码在执行的时候,是所有线程可见的。
int a=1;
int ab=2;
volatile b=3;
总结一下,volatile的两点作用:
1.可见性:
读取一个变量之前,需要先使本地的缓存失效,这样就必须到主内存读取最新值,写一个volatile属性,会立即刷回到主内存。
2.禁止指令重排序:解决单例模式双重锁的乱序问题
volatile 和synchronized的关系?
如果一个共享变量只是被各个线程单纯的赋值,而没有其他的操作,那么这个时候局可以用volatile代替synchronized或者代替原子变量,因为赋值一步操作是具有原子性的,而volatile又保证了可见性,所以足以保证线程安全而不必要花费太大的开销(上下文切换和获取锁等等)。
volatile 可以让long double的赋值是原子性的
synchronized 的可见性
synchronized 不仅仅有保证原子性,还保证可见性。
例如用 syncronized代码块执行a++却不用volatile修饰,同样可以保证a对其他线程可见。
int a=0;
synchronized (this){
for(;;){
a++;}
}
符合上面的原则2,A线程解锁了,B线程获得了同样的锁,那么B一定能看到A的所有操作。
//定义变量
int a,b,c,d;
//线程A执行
void change(){
a=2;
b=3;
c=4;
synchronized (this){
d=5;
}
}
//线程B执行
void read(){
synchronzied(this){int aa=a}
bb=b;
cc=c;
dd=d;
}
java中有哪些原子操作?
除了long double外的所有基本类型的赋值操作
int a=9;
所有引用的赋值操作,不管是32位的机器还是64位的机器。
原子类的原子操作。Atomic
JMM应用实例,单例模式8种写法,单例和并发的关系
为什么需要单例模式?
1.节省内存和计算
2.保证结果的正确
3.方便管理 工具类==
单例模式的适用场景
1.无状态的工具类:比如日志工具类,不管是在哪里使用,我们徐亚的是他帮我们记录日志信息,除此之外,并不需要他的实例对象存储任何的状态,这时候我们只需要一个实例对象。
2.全局信息类:比如我们记录一个网站的访问次数,我们不希望访问记录被分散的保存在多个对象上,这时候我们就让这个类成为单例。
单例模式的8种写法
参考我的另外博客,单例模式
讲一讲什么是JMM
CPU有多级缓存,导致读的数据可能会过期。高速缓存的容量比主内存小,但是速度仅次于寄存器,所以在CPU和主存之间就多了Cache层。线程之间的对于共享变量的可见性并不是直接由多核引起的,而是由多层缓存引起的,如果所有的核心都只用一个缓存,那么也就不存下内存可见性问题。

每个核心都会将自己需要的数据读到独占缓存中,数据修改后也是写到缓存中,然后等待刷入到主存中,所以会导致有些核心读取到的是一个过期的值。
java为了解决这个问题,提出了一种规范,规定了JVM CPU和代码之间的一些列转换关系帮助我们更容易开发程序。java内存模型是一种抽象模型。他抽象出主内存,线程本地工作内存的概念。这里的线程本地内存并不是给每个线程分配的内存,而是对CPU的寄存器,一级缓存,二级缓存,三级缓存的抽象。
JMM重要包含三个概念,重排序,可见性,原子性。
本来CPU编译器会对代码进行优化,进行执行顺序上的改变,使其执行更快。但是这也可能带来意想不到的结果,JMM规定的一些禁止重排序的规则,保证在并发情况下的结果正确。
JMM,规定了一些happend -before原则,其中重要的有volatile关键字和synchronized锁。
volatile保证了变量每次读取都是从主内存中读取,每次更新都要立刻回写。但是volatile不具备原子性,适合用于一些单纯的赋值操作。synchronized不仅仅保证可见性,还保证了原子性。由于hp原则,volatile和synchronized不仅仅保证了自己范围内的代码可见,还保证了附近代码的可见性。
关于原子性,在java中,基本类型中,除了double类型,long类型,其他基本类型单纯的赋值操作都是原子性的。其他实现原子性的方式有加锁,还有利用原子工具类。关于double类型和long类型,在32位JVM上可能不是原子性的。我们可以通过加锁或者用volatile修饰。
什么是原子操作,java中有哪些原子操作,生成对象的过程是不是原子操作?
不是,生成对象3个步骤。1.生成一个空的对象3.对象的地址指向这个引用。2.执行构造函数
3个步骤不是原子性
死锁
什么是死锁?
发生在并发中,当多个线程相互持有对方所需要的资源,又不主动释放,导致大家无法继续前行,导致程序进入无尽的阻塞,这就是死锁。或者是多个线程之间的依赖形成了环路。
死锁发生的四个必要条件
1.互斥条件
一个资源只能被一个线程使用
2.请求与保持条件
线程请求新资源的同事保留原有资源
3.不剥夺条件
4.循环等待条件
构成了环路
4个条件缺一不可
如何定位死锁
先查看java程序的ID,然后通过jstack命令 ID 可以定位到死锁。
或者使用ThreadMXBean在运行时检查,定期扫描,发现警告。
线上发生死锁应该怎么办?
1.保留现场信息,然后重启服务器。
2.暂时保证线上服务的安全,然后利用刚才 保存的信息,排查死锁,修改代码,重新发版。
常见修复死锁的策略
1.避免策略,哲学家就餐问题的换手,转账换序方案**(推荐)**
2.检测与恢复策略:一段时间来检测是是否有死锁,如果有就剥夺某一个资源,来打开死锁。
3.鸵鸟策略:如果发生策略的概率及其的低,我们可以等到死锁发生的时候再人工修复。
实际工程中如何避免死锁
1.设置超时时间
获取锁的时候,使用tryLock,获取失败的时候打日志,发警告邮件,再重启==
2.多使用并发类,而不是自己设计锁。多用并发集合少用同步集合。
3.尽量降低锁的使用粒度,用不同的锁而不是同一个锁。
4.使用同步代码块而不是方法,自己指定锁对象。提高掌控力
5.给线程起一个有意义的名字,调式的时候和排查的时候更加方便。
6.避免锁的嵌套
7.银行家算法 。分配资源前进行计算,看能不能回收回来
8.专锁专用。不要几个功能使用同一把锁
活锁,活跃性故障
什么是活锁?
线程没有阻塞,始终在运行,但是程序始终得不到进展,因为线程始终做重复的同样的事情。
public class LiveLock {
public static void main(String[] args) {
Diner husband=new Diner("牛郎");
Diner wife=new Diner("织女");
Spoon spoon=new Spoon(husband);
new Thread(new Runnable() {
@Override
public void run() {
husband.eatWith(spoon,wife);
}
}).start();
new Thread(new Runnable() {
@Override
public void run() {
wife.eatWith(spoon,husband);
}
}).start();
}
static class Spoon{
private Diner owner;
public synchronized void use(){
System.out.printf("%s has eaten!",owner.name);
}
public Diner getOwner() {
return owner;
}
public void setOwner(Diner owner) {
this.owner = owner;
}
public Spoon(Diner owner) {
this.owner = owner;
}
}
static class Diner{
private String name;
private boolean isHungry=true;
public void eatWith(Spoon spoon,Diner spouse){
while (isHungry){
if (spoon.owner!=this){
try {
Thread.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
continue;
}
if (spouse.isHungry){
System.out.println(name+":亲爱的"+spouse.name+"你先吃吧.");
spoon.setOwner(spouse);
continue;
}
spoon.use();
isHungry=false;
System.out.println(name+":Ok,我吃完了");
spoon.setOwner(spouse);
}
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Diner(String name) {
this.name = name;
}
}
}
如何解决活锁
以太网的指数退避算法
加入随机因素
工程中的活锁案例:消息队列,消息如果处理失败,就会在队列开头重试 。
如果依赖服务出了问题,处理该消息一直失败。如果消息优先级高,消息一直在队列头部,会导致程序无法进行下去。
解决:重试次数的限制,不是放在头部
生产中什么场景下发生死锁?
一个方法获取多个锁,
循环调用有锁的不同方法。