ThreadLocal
1、为什么有ThreadLocal
多线程并发访问同一个共享变量的时候特别容易出现问题,为了保证线程安全,一般我们都要在访问共享变量的时候进行适当的同步,同步的措施一般就是可以加锁,但是呢加锁的话需要我们使用者对锁有一定的了解,而且加锁的话某一时刻只能有一个线程能够访问到共享变量,其他线程都会被阻塞挂起,影响了性能。那么是否有一种方式可以做到,创建一个变量A之后每个线程都能将其复制一份到自己的线程内存空间上,对该变量A进行修改都不会影响到其他线程上的变量A。其实ThreadLocal就可以做到这件事情。ThreadLocal是JDK包提供的,它提供了线程本地变量,也就是如果你创建了一个ThreadLocal变量,那么访问这个变量的每个线程都会复制一份副本到自己的线程中,也就是说多个线程操作这个变量的时候都是在操作自己本地内存里面的变量,这样就避免了线程安全问题。这里同时也涉及到了一个java内存模型的知识,我们放在后面的章节讲解。
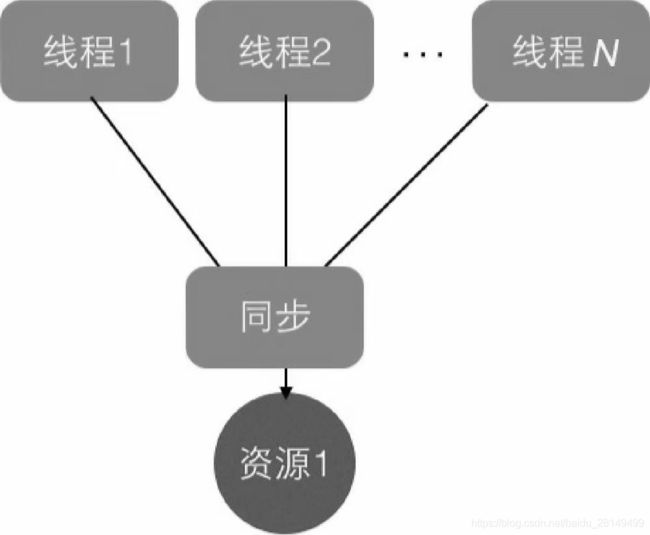
图1. 锁机制
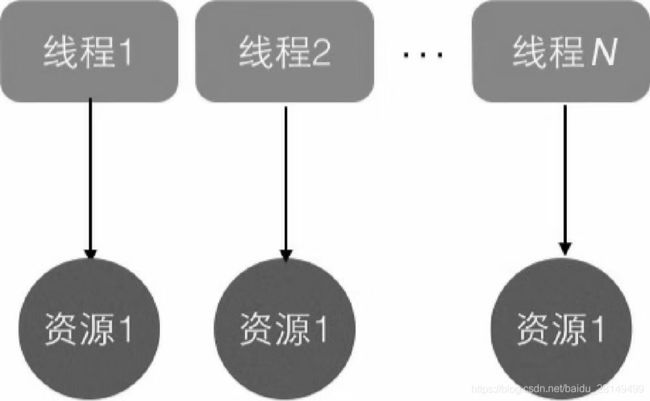
图2.ThreadLocal
2、ThreadLocal使用示例
我们下面将用一个实例来说明一下使用的场景,都知道请求后台其实每一个请求就会开一个线程,如果请求过多就会导致并发量大服务器崩溃。我们模拟一下后台请求数据的时候,过滤器会拦截这个请求并判断是否已经登录,若是已登录则把用户信息存储到ThreadLocal修饰的变量中,然后此次请求(该线程)的过程中就可以随时的从ThreadLocal变量中取出用户信息,而不需要把用户信息一层一层的传递下去。
public class RequestHolder {
//保存着用户信息,一个线程有一份副本,互不干扰,ThreadLocal其实是一个Map,它的key是当前的线程ID,value是值
private static final ThreadLocal requestHolder = new ThreadLocal<>();
public RequestHolder(){}
//拦截器在后台拦截到请求之前,把用户信息放到ThreadLocal中
public static void add(Long id){
requestHolder.set(id);
}
//在此次请求过程中,可以随时随地的取出用户信息
public static Long getId(){
return requestHolder.get();
}
//在此次请求之后,需要主动删除ThreadLocal信息,否则除非重新启动系统,不然信息不会消失
public static void remove(){
requestHolder.remove();
}
} public class HttpFilter implements Filter {
@Override
public void init(FilterConfig filterConfig) throws ServletException {
}
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
HttpServletRequest httpServletRequest = (HttpServletRequest)servletRequest;
System.out.println("do filter:"+ Thread.currentThread().getId() + " " + httpServletRequest.getServletPath());
//获取此次请求是否已经登录,若是登录则取出登录信息放到ThreadLocal里面,否则跳转到登录页面
// Long userId = (Long) httpServletRequest.getSession().getAttribute("user");
RequestHolder.add(Thread.currentThread().getId());
//拦截请求链放过此次请求,让他可以继续请求下去,别的拦截器可以继续拦截看是否处理
filterChain.doFilter(servletRequest, servletResponse);
}
@Override
public void destroy() {
}
}@SpringBootApplication
public class DemoApplication extends WebMvcConfigurerAdapter {
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class, args);
}
/**
* 注入过滤器
* @return
*/
@Bean
public FilterRegistrationBean httpFilter(){
FilterRegistrationBean registrationBean = new FilterRegistrationBean();
registrationBean.setFilter(new HttpFilter());
registrationBean.addUrlPatterns("/threadLocal/*");
return registrationBean;
}
/**
* 注入拦截器
* @param registry
*/
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(new HttpInterceptor()).addPathPatterns("/**");
}
}@Controller
@RequestMapping("/threadLocal")
public class ThreadLocalController {
@RequestMapping("/test")
@ResponseBody
public Long test(){
return RequestHolder.getId();
}
}运行结果:

其实这里我们也可以结合redis做处理,也就是说不把信息放在session里面而是放在redis里面,然后从redis取出来再放到ThreadLocal变量中去。大概思路就是写一个拦截器对请求方法进行拦截,拦截器会从请求的header中取出token信息,如果token信息不存在,则证明用户尚未登录,代码如下所示:
3、ThreadLocal的实现原理
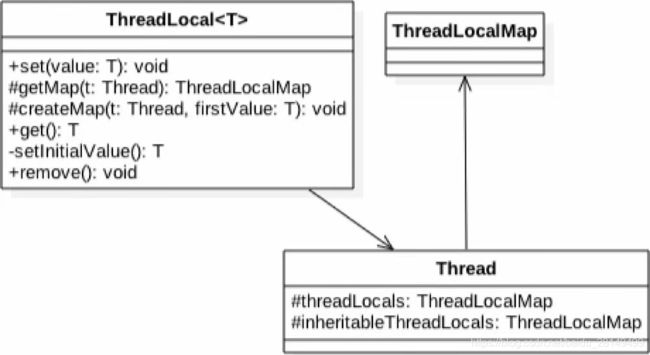
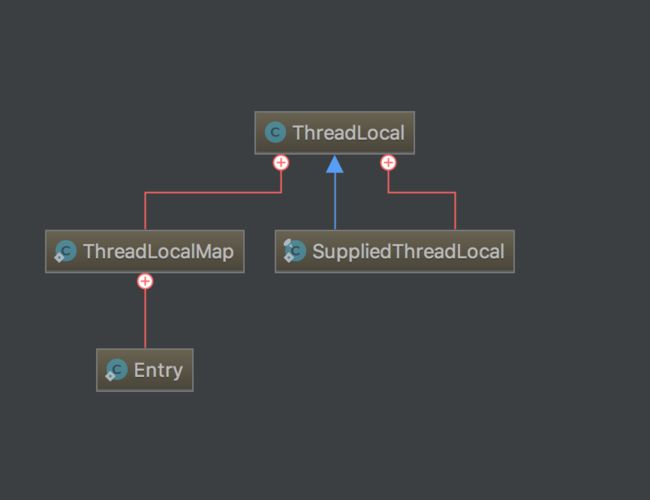
由该图可知Thread类中有一个threadLocals和一个inheritableThreadLocals,它们都是ThreadLocalMap类型的变量,而ThreadLocalMap是一个定制的hashMap(ThreadLocal.ThreadLocalMap.Entry),默认每个线程的这两个变量都是null,只有当前线程第一次调用了ThreadLocal的set或者get方法时候才会进行创建。其实每个线程的本地变量都不是存放在ThreadLocal实例里面的,而是存放在调用线程Thread的threadLocals变量里面,也就是说ThreadLocal类型的本地变量是存放到具体的线程内存空间的。ThreadLocal就是一个工具壳,它是通过set方法把value值放入该调用线程的threadLocals里面存放起来,当调用线程调用它的get方法时候再从当前线程的threadLocals变量里面拿出来使用。(具体的源码后面讲解)
如果调用线程不终止的话,那么这个threadLocal变量会一直存放在调用线程的threadLocals变量里面,所以当不需要使用这个变量的时候可以通过调用threadLocal变量的remove方法,从当前线程的threadLocals里面删除该变量。然后为什么Thread里面的threadLocals要设计为Map结构呢?很明显是因为每个线程里面可以存储多个ThreadLocal变量啊。我们可以再次看下图: 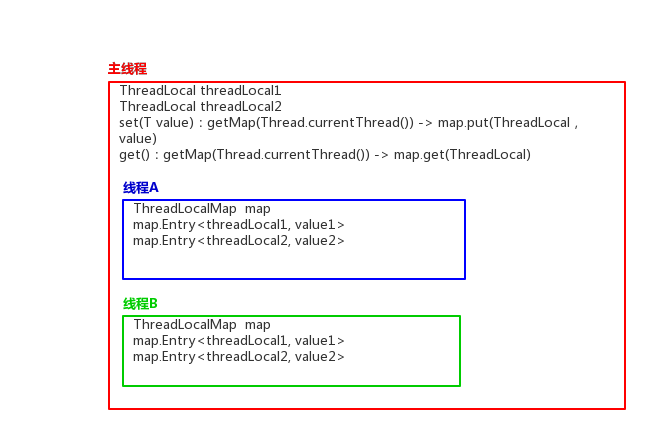
主线程定义了两个ThreadLocal变量和两个子线程--线程A和线程B。线程A和线程B分别持有两个ThreadLocalMap.Entry用于保存自己独立的副本。在线程A和线程B调用ThreadLocal的set方法会首先通过getMap(Thread.currentThread)获得线程A或者线程B持有的ThreadLocalMap(也就是那个threadLocals变量),再调用map.set()方法将当前的ThreadLocal变量作为key存放value值。get()方法和set()方法原理类似,也是先调用当前线程的ThreadLocalMap,再从map中获取value即可,依然将threadLocal变量作为key。
上面我们已经讲了ThreadLocal大概的一个思路,但是我们还是有很多地方不太明白的,接下来就让我们看下源码揭晓答案。【1】ThreadLocalMap结构究竟是长什么样?
我们首先看下ThreadLocalMap的源码
成员变量
/**
* 初始容量 —— 必须是2的冥
*/
private static final int INITIAL_CAPACITY = 16;
/**
* 存放数据的table,Entry类的定义在下面分析
* 同样,数组长度必须是2的冥。
*/
private Entry[] table;
/**
* 数组里面entrys的个数,可以用于判断table当前使用量是否超过负因子。
*/
private int size = 0;
/**
* 进行扩容的阈值,表使用量大于它的时候进行扩容。
*/
private int threshold; // Default to 0
/**
* 定义为长度的2/3
*/
private void setThreshold(int len) {
threshold = len * 2 / 3;
}存储结构--Entry
/**
* Entry继承WeakReference,并且用ThreadLocal作为key.如果key为null
* (entry.get() == null)表示key不再被引用,表示ThreadLocal对象被回收
* 因此这时候entry也可以从table从清除。
*/
static class Entry extends WeakReference> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal k, Object v) {
super(k);
value = v;
}
}
从上面的结构我们可以得知,一个Thread线程里面有一个threadlocals变量,该变量之前得知是一个ThreadLocalMap类型。而ThreadLocalMap里面有一个Entry结构,Entry可以看作是一个map,key就是threadLocal变量而值就是当前的value。这些entry都是存储在table里面的, table是一个Entry类型的数组。为什么是一个数组呢,因为这样一个线程就可以存储多个threadLocal类型的变量。
【2】value值是存放到ThreadLocalMap的哪个位置?
从第一个问题我们可以得知实际上value值是放在Entry里面,而ThreadLocalMap有一个table数组(Entry类型),那么我们是怎么获取或者存放这个变量呢?我们可以看下ThreadLocal的set()和get()方法
ThreadLocal中的set方法
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocal.ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
ThreadLocal.ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}
void createMap(Thread t, T firstValue) {
t.threadLocals = new ThreadLocal.ThreadLocalMap(this, firstValue);
}ThreadLocalMap(ThreadLocal firstKey, Object firstValue) {
//初始化table
table = new ThreadLocal.ThreadLocalMap.Entry[INITIAL_CAPACITY];
//计算索引
int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
//设置值
table[i] = new ThreadLocal.ThreadLocalMap.Entry(firstKey, firstValue);
size = 1;
//设置阈值
setThreshold(INITIAL_CAPACITY);
}代码很简单,其实就是定义ThreadLocalEntry[] table中。
ThreadLocalMap中的set()
ThreadLocalMap使用线性探测法来解决哈希冲突问题,线性探测法地址增量是di=1,2,....m-1,其中i为探测次数。该方法一次探测下一个地址,直到有空的地址后插入,
若整个空间都找不到空余的地址,则产生溢出。假设当前table长度为16,也就是说如果计算出来key的hash值为14,如果table[14]上已经有值,并且其key与当前key不一致,那么就发生了hash冲突,这个时候将14加1得到15,取table[15]进行判断,这个时候如果还是冲突会回到0,取table[0],以此类推,直到可以插入。
先看一下线性探测相关的代码,从中也可以看出来table实际是一个环:
/**java
/**
* 获取环形数组的下一个索引
*/
private static int nextIndex(int i, int len) {
return ((i + 1 < len) ? i + 1 : 0);
}
/**
* 获取环形数组的上一个索引
*/
private static int prevIndex(int i, int len) {
return ((i - 1 >= 0) ? i - 1 : len - 1);
}ThreadLocalMap的set()及其set()相关代码如下:
private void set(ThreadLocal key, Object value) {
ThreadLocal.ThreadLocalMap.Entry[] tab = table;
int len = tab.length;
//计算索引,上面已经有说过。
int i = key.threadLocalHashCode & (len-1);
/**
* 根据获取到的索引进行循环,如果当前索引上的table[i]不为空,在没有return的情况下,
* 就使用nextIndex()获取下一个(上面提到到线性探测法)。
*/
for (ThreadLocal.ThreadLocalMap.Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
ThreadLocal k = e.get();
//table[i]上key不为空,并且和当前key相同,更新value
if (k == key) {
e.value = value;
return;
}
/**
* table[i]上的key为空,说明被回收了(上面的弱引用中提到过)。
* 这个时候说明改table[i]可以重新使用,用新的key-value将其替换,并删除其他无效的entry
*/
if (k == null) {
replaceStaleEntry(key, value, i);
return;
}
}
//找到为空的插入位置,插入值,在为空的位置插入需要对size进行加1操作
tab[i] = new ThreadLocal.ThreadLocalMap.Entry(key, value);
int sz = ++size;
/**
* cleanSomeSlots用于清除那些e.get()==null,也就是table[index] != null && table[index].get()==null
* 之前提到过,这种数据key关联的对象已经被回收,所以这个Entry(table[index])可以被置null。
* 如果没有清除任何entry,并且当前使用量达到了负载因子所定义(长度的2/3),那么进行rehash()
*/
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
}ThreadLocalMap中的getEntry()及其相关
public T get() {
//同set方法类似获取对应线程中的ThreadLocalMap实例
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
//为空返回初始化值
return setInitialValue();
}
/**
* 初始化设值的方法,可以被子类覆盖。
*/
protected T initialValue() {
return null;
}
private T setInitialValue() {
//获取初始化值,默认为null(如果没有子类进行覆盖)
T value = initialValue();
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
//不为空不用再初始化,直接调用set操作设值
if (map != null)
map.set(this, value);
else
//第一次初始化,createMap在上面介绍set()的时候有介绍过。
createMap(t, value);
return value;
} private ThreadLocal.ThreadLocalMap.Entry getEntry(ThreadLocal key) {
//根据key计算索引,获取entry
int i = key.threadLocalHashCode & (table.length - 1);
ThreadLocal.ThreadLocalMap.Entry e = table[i];
if (e != null && e.get() == key)
return e;
else
return getEntryAfterMiss(key, i, e);
}
/**
* 通过直接计算出来的key找不到对于的value的时候适用这个方法.
*/
private ThreadLocal.ThreadLocalMap.Entry getEntryAfterMiss(ThreadLocal key, int i, ThreadLocal.ThreadLocalMap.Entry e) {
ThreadLocal.ThreadLocalMap.Entry[] tab = table;
int len = tab.length;
while (e != null) {
ThreadLocal k = e.get();
if (k == key)
return e;
if (k == null)
//清除无效的entry
expungeStaleEntry(i);
else
//基于线性探测法向后扫描
i = nextIndex(i, len);
e = tab[i];
}
return null;
} private void remove(ThreadLocal key) {
ThreadLocal.ThreadLocalMap.Entry[] tab = table;
int len = tab.length;
//计算索引
int i = key.threadLocalHashCode & (len-1);
//进行线性探测,查找正确的key
for (ThreadLocal.ThreadLocalMap.Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
if (e.get() == key) {
//调用weakrefrence的clear()清除引用
e.clear();
//连续段清除
expungeStaleEntry(i);
return;
}
}
}【3】Entry为什么是弱引用?
讲了这么多源码我们还可以发现其实ThreadLocalMap中的Entry是一个弱引用呢,我们讲一下什么是引用,什么是弱引用呢?
对象和引用的概念,在Java种万物皆对象,比如我们定义一个简单的动物类:
class Animal {
String count;
String weight;
....
}
Animal animal = new Animal();我们把创建对象语句这个动作细化为:
(1)右边的"new Animal"是以Animal类为模板,在堆空间里面创建一个Animal对象。
(2)末尾的"()"表示对象创建后调用Animal类的构造函数,对新生成的对象进行初始化
(3)左边的"Animal animal"在栈空间里面创建了一个Animal类的引用变量,以后可以用来指向Animal对象的对象引用。
(4)"="操作符使对象引用指向刚才创建的那个Animal对象。
引用变量相当于为数组或者对象起一个名字,以后就可以在程序中使用栈的引用变量来访问堆中的数组或者对象。将一个对象赋值给另一个对象,实际上是将引用从一个地方复制到另外一个地方。
接下来我们从三个方面讲下弱引用,什么是弱引用?为什么使用弱引用?如何使用弱引用?
(1)什么是弱引用
在Java里面当一个对象被创建得时候,它被放在内存堆里。当GC垃圾回收期运行得时候如果发现没有任何引用指向该对象,该对象就会被回收以腾出内存空间。或者换句话说,一个对象被回收,必须满足两个条件:1、没有任何的引用指向它 。2、GC被运行。
java相对简单的情况下,手动置空是不需要程序员来做的,因为在java中对于简单对象来说,当调用它的方法执行完毕后,指向它的引用会被GC回收,实际中我们写代码往往是通过把所有指向某个对象的referece置为null实现,如:
Person p = new Person("张三",18,"男");//强引用
...
p=null;//不再使用的时候置null很明显,手动置为null对象对于程序来说是一件繁琐且违背自动回收机制的。对此java中引入了弱引用,当一个对象仅仅被弱引用对象指向的时候,而且没有其他的强引用对象指向的时候,如果GC运行那么这个对象就会被回收。 如果存在强引用同时与之关联,则进行垃圾回收时也不会回收该对象。在对象被回收之后,会把弱引用对象也就是“引用”放入引用队列中,注意不是被弱引用的对象,被弱引用的对象(对象)已经被回收了。
(2)为什么使用弱引用
可以考虑下面的场景:现在有一个product的产品类,这个类就被设计为不可扩展的(final),而此时我们想要为每个产品增加一个编号。一种解决方案是使用HashMap
(3)如何使用弱引用?
拿上面介绍的场景举例,我们使用一个指向Product对象的弱引用对象来作为HashMap的key,只需这样定义这个弱引用对象:
productA = new Product(...);
WeakReference weakProductA = new WeakReference<>(productA); 现在弱引用对象weakProductA就指向了Product对象productA。那么我们怎么通过weakProduct获取它所指向的Product对象productA呢?很简单,只需要下面这句代码:
Product product = weakProductA.get();
实际上当produceA变为null时候(表明它所引用的Product已经无需存在于内存中),这时指向这个Product对象的就是弱引用对象weakProductA了,那么显然此时Product对象是弱可达的,指向它的弱引用会被清除,这个Product对象会被回收,指向它的弱引用对象会被引入引用队列中。
(4)为什么ThreadLocalMap中的entry的key要被设置为弱引用呢?
之所以设计为弱引用的目的就是为了更好的对ThreadLocal进行回收,当我们在代码中将ThreadLocal的强应用置为Null后,这时候Entry中的ThreadLocal理应被回收了,如果此时Entry中的key被设置为强引用的话则该ThreadLocal就不能被回收,这就是将其设置为弱引用的目的。