PaddlePaddle飞桨之深度学习7日入门 总结
目录
Day01 新冠疫情可视化
作业1:飞桨本地安装
作业2:新冠疫情可视化
Day02 手势识别
Day03 车牌识别
Day04 口罩分类
Day05 人流密度检测比赛
Day06 PaddleSlim模型压缩
图像分类模型量化教程
1、导入依赖
2、构建模型
3、定义输入数据
4、训练模型
5、量化模型
6、训练和测试量化后的模型
Day01 新冠疫情可视化
第一天的任务主要有两个,第一个是飞桨的本地安装,以及新冠疫情可视化。
作业1:飞桨本地安装
这门课程我感觉首先是可以给大家普及cv方面的知识,另一方面也是为了普及飞桨这个框架的使用,所以安装飞桨也必不可少。
飞桨的官网:https://www.paddlepaddle.org.cn/documentation/docs/zh/install/index_cn.html

作业2:新冠疫情可视化
作业2的话是 新冠疫情的可视化。这个作业的主要任务是 利用python的request模块和re正则化模块,爬取丁香园当天的新冠疫情数据,然后利用Echarts进行对数据可视化操作。Echarts 是一个由百度开源的数据可视化工具,凭借着良好的交互性,精巧的图表设计,得到了众多开发者的认可。而 Python 是一门富有表达力的语言,很适合用于数据处理。当数据分析遇上数据可视化时,pyecharts 诞生了。pyecharts api参考链接:https://pyecharts.org/#/zh-cn/chart_api
然后我们需要做的就是将面的可视化图片利用百度的pycharts 转为扇形可视化出来。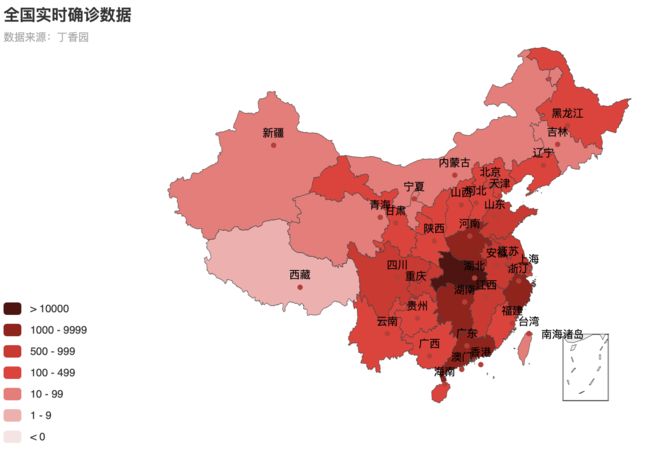
利用爬取到的数据转为扇形对的代码如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2020/3/31 22:17
# @Author : caius
# @Site :
# @File : test2.py
# @Software: PyCharm
import json
import datetime
from pyecharts.charts import Map
from pyecharts import options as opts
from pyecharts.charts import Pie
from pyecharts.faker import Faker
# 读原始数据文件
today = datetime.date.today().strftime('%Y%m%d') #20200315
datafile = 'data/'+ today + '.json'
with open(datafile, 'r', encoding='UTF-8') as file:
json_array = json.loads(file.read())
# 分析全国实时确诊数据:'confirmedCount'字段
china_data = []
for province in json_array:
china_data.append((province['provinceShortName'], province['confirmedCount']))
china_data = sorted(china_data, key=lambda x: x[1], reverse=True) #reverse=True,表示降序,反之升序
print(china_data)
# 全国疫情地图
# 自定义的每一段的范围,以及每一段的特别的样式。
pieces = [
{'min': 10000, 'color': '#540d0d'},
{'max': 9999, 'min': 1000, 'color': '#9c1414'},
{'max': 999, 'min': 500, 'color': '#d92727'},
{'max': 499, 'min': 100, 'color': '#ed3232'},
{'max': 99, 'min': 10, 'color': '#f27777'},
{'max': 9, 'min': 1, 'color': '#f7adad'},
{'max': 0, 'color': '#f7e4e4'},
]
labels = [data[0] for data in china_data]
counts = [data[1] for data in china_data]
# m = Map()
# m.add("累计确诊", [list(z) for z in zip(labels, counts)], 'china')
c = Pie()
c.add("", [list(z) for z in zip(labels, counts)] ,center=["50%", "70%"],radius=["2%", "40%"])
["50%", "50%"]
c.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
c.set_global_opts(title_opts=opts.TitleOpts(title='全国实时确诊数据 -caius',
subtitle='数据来源:丁香园'),
legend_opts=opts.LegendOpts(is_show=False)
) #是否显示视觉映射配置
# c = (
# Pie()
# .add("",[list(z) for z in zip(labels, counts)])
# # .set_colors(["blue", "green", "yellow", "red", "pink", "orange", "purple"])
# .set_global_opts(title_opts=opts.TitleOpts(title="Pie-设置颜色"))
# .set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
# .render("pie_set_color.html")
# )
#系列配置项,可配置图元样式、文字样式、标签样式、点线样式等
# m.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{c}"),is_show=False)#
# m.set_series_opts(label_opts=opts.LabelOpts(font_size=12),is_show=False)
#全局配置项,可配置标题、动画、坐标轴、图例等
# m.set_global_opts(title_opts=opts.TitleOpts(title='全国实时确诊数据',
# subtitle='数据来源:丁香园'),
# legend_opts=opts.LegendOpts(is_show=False),
# visualmap_opts=opts.test2.pytest2.py(pieces=pieces,
# is_piecewise=True, #是否为分段型
# is_show=True)) #是否显示视觉映射配置
# #render()会生成本地 HTML 文件,默认会在当前目录生成 render.html 文件,也可以传入路径参数,如 m.render("mycharts.html")
c.render(path='./data/全国实时确诊数据.html') 
Day02 手势识别
第二天的任务是手势识别任务,其实也就是一个多分类的任务。课程要求是用DNN来做,然后我使用的是Alexnet来进行多分类的任务,但是效果不是很好。在此过程中我学到了课程中的小伙伴的一个图像增强的一个技巧mixup。它一般是用在图像分类上面的,我想把它用在语义分割或者目标检测上面,但是我并没有找到相关的代码。
def mixup(X, y):
'''
功能:图像增强,mixup
参数:
X:batch imgs
y: batch labels
超参:
beta: beta分布的alpha和beta参数,这个可以自己设置,并观察结果
引用:
mixup: Beyond Empirical Risk Minimization(https://arxiv.org/abs/1710.09412)
'''
mixup_alpha = 0.1
seed = np.random.beta(mixup_alpha, mixup_alpha)
index = np.arange(X.shape[0])
np.random.shuffle(index)
images_a, images_b = X, X[index]
labels_a, labels_b = y, y[index]
mixed_images = seed * images_a + (1 - seed) * images_b
return mixed_images, labels_a, labels_b, seed他的github链接如下:https://github.com/mmmmmmiracle/paddle_seven_days
完整的代码如下:
import os
import time
import random
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
import paddle
import paddle.fluid as fluid
import paddle.fluid.layers as layers
from multiprocessing import cpu_count
from paddle.fluid.dygraph import Pool2D,Conv2D,CosineDecay,BatchNorm,CosineDecay
from paddle.fluid.dygraph import Linear
# 生成图像列表
data_path = '/home/aistudio/data/data23668/Dataset'
character_folders = os.listdir(data_path)
# print(character_folders)
if(os.path.exists('./train_data.list')):
os.remove('./train_data.list')
if(os.path.exists('./test_data.list')):
os.remove('./test_data.list')
for character_folder in character_folders:
with open('./train_data.list', 'a') as f_train:
with open('./test_data.list', 'a') as f_test:
if character_folder == '.DS_Store':
continue
character_imgs = os.listdir(os.path.join(data_path,character_folder))
count = 0
for img in character_imgs:
if img =='.DS_Store':
continue
if count%10 == 0:
f_test.write(os.path.join(data_path,character_folder,img) + '\t' + character_folder + '\n')
else:
f_train.write(os.path.join(data_path,character_folder,img) + '\t' + character_folder + '\n')
count +=1
print('列表已生成')
def mixup(X, y):
'''
功能:图像增强,mixup
参数:
X:batch imgs
y: batch labels
超参:
beta: beta分布的alpha和beta参数,这个可以自己设置,并观察结果
引用:
mixup: Beyond Empirical Risk Minimization(https://arxiv.org/abs/1710.09412)
'''
mixup_alpha = 0.1
seed = np.random.beta(mixup_alpha, mixup_alpha)
index = np.arange(X.shape[0])
np.random.shuffle(index)
images_a, images_b = X, X[index]
labels_a, labels_b = y, y[index]
mixed_images = seed * images_a + (1 - seed) * images_b
return mixed_images, labels_a, labels_b, seed
# 定义训练集和测试集的reader
def data_mapper(sample):
img, label = sample
img = Image.open(img)
img = img.resize((100, 100), Image.ANTIALIAS)
img = np.array(img).astype('float32')
# print(img.shape)
img = img.transpose((2, 0, 1))
img = img/255.0
return img, label
def data_reader(data_list_path):
def reader():
with open(data_list_path, 'r') as f:
lines = f.readlines()
for line in lines:
img, label = line.split('\t')
yield img, int(label)
return paddle.reader.xmap_readers(data_mapper, reader, cpu_count(), 512)
# 用于训练的数据提供器
train_reader = paddle.batch(reader=paddle.reader.shuffle(reader=data_reader('./train_data.list'), buf_size=1024), batch_size=32)
# 用于测试的数据提供器
test_reader = paddle.batch(reader=data_reader('./test_data.list'), batch_size=32)
#定义DNN网络
class MyDNN(fluid.dygraph.Layer):
def __init__(self, name_scope, num_classes=10):
super(MyDNN, self).__init__(name_scope)
name_scope = self.full_name()
self.conv1 = Conv2D(num_channels=3, num_filters=96, filter_size=11, stride=4, padding=5, act='relu')
self.pool1 = Pool2D(pool_size=2, pool_stride=2, pool_type='max')
self.conv2 = Conv2D(num_channels=96, num_filters=256, filter_size=5, stride=1, padding=2, act='relu')
self.pool2 = Pool2D(pool_size=2, pool_stride=2, pool_type='max')
self.conv3 = Conv2D(num_channels=256, num_filters=384, filter_size=3, stride=1, padding=1, act='relu')
self.conv4 = Conv2D(num_channels=384, num_filters=384, filter_size=3, stride=1, padding=1, act='relu')
self.conv5 = Conv2D(num_channels=384, num_filters=256, filter_size=3, stride=1, padding=1, act='relu')
self.pool5 = Pool2D(pool_size=2, pool_stride=2, pool_type='max')
self.fc1 = Linear(input_dim=2304, output_dim=4096, act='relu')
self.drop_ratio1 = 0.5
self.fc2 = Linear(input_dim=4096, output_dim=4096, act='relu')
self.drop_ratio2 = 0.5
self.fc3 = Linear(input_dim=4096, output_dim=num_classes)
def forward(self, x):
x = self.conv1(x)
x = self.pool1(x)
x = self.conv2(x)
x = self.pool2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.conv5(x)
x = self.pool5(x)
x = fluid.layers.reshape(x, [x.shape[0], -1])
# print(x.shape)
x = self.fc1(x)
# 在全连接之后使用dropout抑制过拟合
x= fluid.layers.dropout(x, self.drop_ratio1)
x = self.fc2(x)
# 在全连接之后使用dropout抑制过拟合
x = fluid.layers.dropout(x, self.drop_ratio2)
x = self.fc3(x)
return x
#用动态图进行训练
with fluid.dygraph.guard():
model=MyDNN('Alexnet') #模型实例化
model.train() #训练模式
opt = fluid.optimizer.Momentum(learning_rate=0.001,momentum=0.9,parameter_list=model.parameters())
epochs_num=50 #迭代次数
for pass_num in range(epochs_num):
for batch_id,data in enumerate(train_reader()):
images=np.array([x[0].reshape(3,100,100) for x in data],np.float32)
labels = np.array([x[1] for x in data]).astype('int64')
labels = labels[:, np.newaxis]
image=fluid.dygraph.to_variable(images)
label=fluid.dygraph.to_variable(labels)
predict=model(image)#预测
loss=fluid.layers.softmax_with_cross_entropy(predict,label)
avg_loss=fluid.layers.mean(loss)#获取loss值
acc=fluid.layers.accuracy(predict,label)#计算精度
if batch_id!=0 and batch_id%50==0:
print("train_pass:{},batch_id:{},train_loss:{},train_acc:{}".format(pass_num,batch_id,avg_loss.numpy(),acc.numpy()))
avg_loss.backward()
opt.minimize(avg_loss)
model.clear_gradients()
fluid.save_dygraph(model.state_dict(),'MyDNN')#保存模型
import matplotlib.pyplot as plt
%matplotlib inline
plt.figure(figsize=(16,5))
plt.subplot(121)
plt.plot(train_losses)
plt.title('loss')
plt.subplot(122)
plt.plot(train_accs)
plt.title('acc')
plt.savefig('32_64_256_mixup.png')
plt.show()这里面用的是paddle的动态图的结构,类似于pytorch以及tf2.0结构。

with fluid.dygraph.guard():
accs = []
model_dict, _ = fluid.load_dygraph('MyDNN')
model = MyDNN('Alexnet')
model.load_dict(model_dict) #加载模型参数
model.eval() #训练模式
for batch_id,data in enumerate(test_reader()):#测试集
images=np.array([x[0].reshape(3,100,100) for x in data],np.float32)
labels = np.array([x[1] for x in data]).astype('int64')
labels = labels[:, np.newaxis]
image=fluid.dygraph.to_variable(images)
label=fluid.dygraph.to_variable(labels)
predict=model(image)
acc=fluid.layers.accuracy(predict,label)
accs.append(acc.numpy()[0])
avg_acc = np.mean(accs)
print(avg_acc)#读取预测图像,进行预测
def load_image(path):
img = Image.open(path)
img = img.resize((100, 100), Image.ANTIALIAS)
img = np.array(img).astype('float32')
img = img.transpose((2, 0, 1))
img = img/255.0
print(img.shape)
return img
#构建预测动态图过程
with fluid.dygraph.guard():
infer_path = '手势.png'
model = MyDNN('Alexnet')
model_dict,_=fluid.load_dygraph('MyDNN')
model.load_dict(model_dict)#加载模型参数
model.eval()#评估模式
infer_img = load_image(infer_path)
infer_img=np.array(infer_img).astype('float32')
infer_img=infer_img[np.newaxis,:, : ,:]
infer_img = fluid.dygraph.to_variable(infer_img)
logits=model(infer_img)
result = fluid.layers.sigmoid(logits)
display(Image.open('手势.png'))
print(np.argmax(result.numpy()))
(3, 100, 100)
5

Day03 车牌识别
第三天的任务是车牌识别, 它主要是利用传统的一些cv算法,将车牌字符一一切割出来,然后送到神经网络去训练,本质上也是一个多分类的任务。这里面我使用的网络结是LeNet,代码如下:
#定义网络
class LeNet(fluid.dygraph.Layer):
def __init__(self, *, channels, num_class=56):
super(LeNet,self).__init__()
self.hidden1_1 = Conv2D(channels, 32, 5, padding=2)
self.bn1 = BatchNorm(32, act='relu')
self.hidden1_2 = Pool2D(2, 'avg', 2)
self.hidden2_1 = Conv2D(32, 64, 3, padding=1)
self.bn2 = BatchNorm(64, act='relu')
self.hidden2_2 = Pool2D(2, 'avg', 2)
self.hidden3 = Conv2D(64, 1024 ,1) # 第三个卷积层用 1*1 卷积, 相当于全链接层,但是参数要少的多
self.bn3 = BatchNorm(1024, act='relu')
self.hidden4 = Conv2D(256, 1024 ,1) # 第三个卷积层用 1*1 卷积, 相当于全链接层,但是参数要少的多
self.bn4 = BatchNorm(1024, act='relu')
self.global_avg_pool = Pool2D(pool_type='avg', global_pooling=True)
# stdv用来作为全连接层随机初始化参数的方差
import math
stdv = 1.0 / math.sqrt(2048 * 1.0)
# 创建全连接层,输出大小为类别数目
self.out = Linear(input_dim=1024, output_dim=num_class,
param_attr=fluid.param_attr.ParamAttr(
initializer=fluid.initializer.Uniform(-stdv, stdv)),act='softmax')
def forward(self,input):
x = self.bn1(self.hidden1_1(input))
x = self.hidden1_2(x)
x = self.bn2(self.hidden2_1(x))
x = self.hidden2_2(x)
x = self.bn3(self.hidden3(x))
x = self.global_avg_pool(x)
x = fluid.layers.flatten(x)
x = fluid.layers.dropout(x, 0.5)
y = self.out(x)
return y对车牌图片进行处理,分割出车牌中的每一个字符并保存的代码如下:
# 对车牌图片进行处理,分割出车牌中的每一个字符并保存
license_plate = cv2.imread('./车牌.png')
gray_plate = cv2.cvtColor(license_plate, cv2.COLOR_RGB2GRAY)
ret, binary_plate = cv2.threshold(gray_plate, 175, 255, cv2.THRESH_BINARY)
result = []
for col in range(binary_plate.shape[1]):
result.append(0)
for row in range(binary_plate.shape[0]):
result[col] = result[col] + binary_plate[row][col]/255
character_dict = {}
num = 0
i = 0
while i < len(result):
if result[i] == 0:
i += 1
else:
index = i + 1
while result[index] != 0:
index += 1
character_dict[num] = [i, index-1]
num += 1
i = index
for i in range(8):
if i==2:
continue
padding = (170 - (character_dict[i][1] - character_dict[i][0])) / 2
ndarray = np.pad(binary_plate[:,character_dict[i][0]:character_dict[i][1]], ((0,0), (int(padding), int(padding))), 'constant', constant_values=(0,0))
ndarray = cv2.resize(ndarray, (20,20))
cv2.imwrite('./' + str(i) + '.png', ndarray)
def load_image(path):
img = paddle.dataset.image.load_image(file=path, is_color=False)
img = img.astype('float32')
img = img[np.newaxis, ] / 255.0
return img
构建预测动态图过程
with fluid.dygraph.guard():
model=LeNet(channels=1, num_class=65)#模型实例化
model_dict,_=fluid.load_dygraph('MyLeNet')
model.load_dict(model_dict)#加载模型参数
model.eval()#评估模式
lab=[]
for i in range(8):
if i==2:
continue
infer_imgs = []
infer_imgs.append(load_image('./' + str(i) + '.png'))
infer_imgs = np.array(infer_imgs)
infer_imgs = fluid.dygraph.to_variable(infer_imgs)
result=model(infer_imgs)
lab.append(np.argmax(result.numpy()))
# print(lab)
display(Image.open('./车牌.png'))
print('\n车牌识别结果为:',end='')
for i in range(len(lab)):
print(LABEL[str(lab[i])],end='')
构建预测动态图过程
with fluid.dygraph.guard():
model=LeNet(channels=1, num_class=65)#模型实例化
model_dict,_=fluid.load_dygraph('MyLeNet')
model.load_dict(model_dict)#加载模型参数
model.eval()#评估模式
lab=[]
for i in range(8):
if i==2:
continue
infer_imgs = []
infer_imgs.append(load_image('./' + str(i) + '.png'))
infer_imgs = np.array(infer_imgs)
infer_imgs = fluid.dygraph.to_variable(infer_imgs)
result=model(infer_imgs)
lab.append(np.argmax(result.numpy()))
# print(lab)
display(Image.open('./车牌.png'))
print('\n车牌识别结果为:',end='')
for i in range(len(lab)):
print(LABEL[str(lab[i])],end='')

车牌识别结果为:鲁A686EJ
Day04 口罩分类
这次课的内容,是在 VGGNet类中补全代码,构造VGG网络,保证程序跑通。在VGG构造成功的基础上,可尝试构造其他网络。
任务描述:
口罩识别,是指可以有效检测在密集人流区域中携带和未携戴口罩的所有人脸,同时判断该者是否佩戴口罩。通常由两个功能单元组成,可以分别完成口罩人脸的检测和口罩人脸的分类。其实就是一个二分类的任务。给一张图片,判断这张图片是否带来口罩。在这里面我又学到一个ricap图像增强的技巧,可惜只能用在图像分类上面。
def ricap(X, y):
'''
功能:图像增强,Random Image Cropping and Patching
参数:
X:batch imgs
y: batch labels
超参:
beta: beta分布的alpha和beta参数,这个可以自己设置,并观察结果
引用:
Data Augmentation using Random Image Cropping and Patching for Deep CNNs(https://arxiv.org/abs/1811.09030v1)
'''
beta = 0.1
I_x, I_y = X.shape[2:]
w = int(np.round(I_x * np.random.beta(beta, beta)))
h = int(np.round(I_y * np.random.beta(beta, beta)))
w_ = [w, I_x - w, w, I_x - w]
h_ = [h, h, I_y - h, I_y - h]
cropped_images = {}
c_ = {}
W_ = {}
for k in range(4):
index = np.arange(X.shape[0])
np.random.shuffle(index)
x_k = np.random.randint(0, I_x - w_[k] + 1)
y_k = np.random.randint(0, I_y - h_[k] + 1)
cropped_images[k] = X[index][:, :, x_k:x_k + w_[k], y_k:y_k + h_[k]]
c_[k] = y[index]
W_[k] = w_[k] * h_[k] / (I_x * I_y)
patched_images = np.concatenate(
(np.concatenate((cropped_images[0], cropped_images[1]), 2),
np.concatenate((cropped_images[2], cropped_images[3]), 2)), 3)
return patched_images, y, W_, c_
在这里面我完成了VGG网络的定义, 在此基础之上,我突然想在paddle上自己实现resnet+senet 来锻炼一下自己的coding能力。然后调通花了两三个小时。
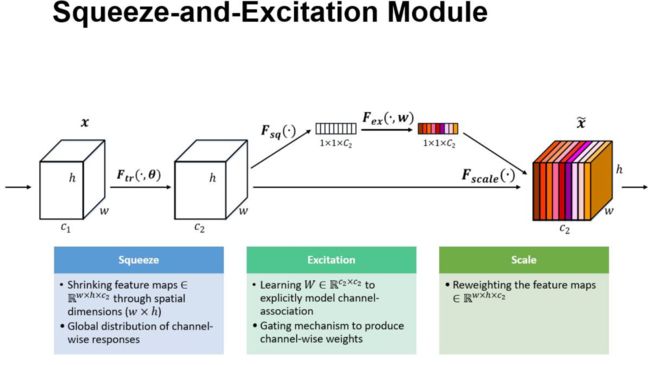
resnet18+ senet 注意力机制的代码如下:
class SELayer(fluid.dygraph.Layer):
def __init__(self, channel, reduction=16):
super(SELayer, self).__init__()
self.avg_pool = Pool2D(pool_type='avg',global_pooling=True)
self.fc1 = Linear(channel, channel // reduction)
self.fc2 = Linear(channel // reduction,channel)
def forward(self, x):
# print(x.shape)
# print(x.shape[0])
# b = x.shape
# exit()
b, c, _, _ = x.shape
# y = self.avg_pool(x).view(b, c)
y = fluid.layers.reshape(self.avg_pool(x), shape=[b, c])
y = self.fc1(y)
y = layers.relu(y)
y = self.fc2(y)
y = layers.sigmoid(y)
y = fluid.layers.reshape(y, shape=[b, c, 1, 1])
# # y = self.fc(y).view(b, c, 1, 1)
# # return x * y.expand_as(x)
# print('selay',y.shape)
return x *fluid.layers.expand_as(x=y, target_tensor=x)
#ResNet18
class Residual(fluid.dygraph.Layer):
#可以设定输出通道数、是否使用额外的1x1卷积层来修改通道数以及卷积层的步幅。
def __init__(self, in_channels, out_channels, use_1x1conv=False, stride=1):
super(Residual, self).__init__()
self.conv1 = Conv2D(in_channels, out_channels, 3, padding=1, stride=stride)
self.conv2 = Conv2D(out_channels, out_channels, 3, padding=1)
if use_1x1conv:
self.conv3 = Conv2D(in_channels, out_channels, 1, stride=stride)
else:
self.conv3 = None
self.bn1 = BatchNorm(out_channels, act='relu')
self.bn2 = BatchNorm(out_channels)
self.se = SELayer(out_channels, 16)
def forward(self, X):
# Y = layers.relu(self.conv1(X))
# Y = self.conv2(Y)
Y = self.bn1(self.conv1(X))
Y = self.bn2(self.conv2(Y))
# print('SE zhiqian',Y.shape)
# [12, 32, 56, 56]
Y= self.se(Y)
# print('SE zhihou',Y.shape)
# exit()
if self.conv3:
X = self.conv3(X)
return layers.relu(Y + X)
class ResBlock(fluid.dygraph.Layer):
def __init__(self, in_channels, out_channels, num_rediduals, first_block=False):
super(ResBlock, self).__init__()
if first_block:
assert in_channels == out_channels # 第一个模块的通道数同输入通道数一致
block = []
for i in range(num_rediduals):
block.append(Residual(in_channels, out_channels, use_1x1conv=not first_block, stride=2-int(first_block)))
in_channels = out_channels
self.resi_block = Sequential(*block)
def forward(self, X):
return self.resi_block(X)
class ResNet(fluid.dygraph.Layer):
def __init__(self, *, channels, fig_size, num_class):
super(ResNet, self).__init__()
self.conv = Sequential(
Conv2D(channels, 32, 7, 2, 3, act='relu'),
BatchNorm(32, act='relu'),
)
self.res_block_arch = [(32, 32, 2, True), (32, 64, 2), (64, 128, 2), (128, 256, 2)]
self.res_blocks = Sequential()
for i, arch in enumerate(self.res_block_arch):
self.res_blocks.add_sublayer(f'res_block_{i+1}', ResBlock(*arch))
self.global_avg_pool = Pool2D(pool_type='avg',global_pooling=True)
self.fc =Linear(256, num_class, act='softmax')
def forward(self, X):
conv_features = layers.pool2d(self.conv(X),2,'max',2)
res_features = self.res_blocks(conv_features)
global_avg_pool = self.global_avg_pool(res_features)
global_avg_pool = layers.flatten(global_avg_pool)
y = self.fc(global_avg_pool)
return y这里面用的优化方法是CosineDecay,余弦函数衰减学习率的功能。
paddle.fluid.dygraph.CosineDecay(learning_rate, step_each_epoch, epochs, begin=0, step=1, dtype='float32')
余弦衰减的计算方式如下。
decayed_learning_rate=learning_rate∗0.5∗(math.cos(global_step∗math.pistep_each_epoch)+1)decayed_learning_rate=learning_rate∗0.5∗(math.cos(global_step∗math.pistep_each_epoch)+1)
式中,
- decayed_learning_ratedecayed_learning_rate : 衰减后的学习率。
式子中各参数详细介绍请看参数说明。
参数:
- learning_rate (Variable | float) - 初始学习率。如果类型为Variable,则为shape为[1]的Tensor,数据类型为float32或float64;也可以是python的float类型。
- step_each_epoch (int) - 遍历一遍训练数据所需的步数。
- begin (int,可选) - 起始步,即以上公式中global_step的初始化值。默认值为0。
- step (int,可选) - 步大小,即以上公式中global_step的每次的增量值。默认值为1。
- dtype (str,可选) - 初始化学习率变量的数据类型,可以为"float32", "float64"。默认值为"float32"。
Day05 人流密度检测比赛
要求参赛者给出一个算法或模型,对于给定的图片,统计图片中的总人数。给定图片数据,选手据此训练模型,为每张测试数据预测出最准确的人数。这里面我用了两种方法分别是vgg 以及给的baseline跑的很差,以后再整理这个吧。
Day06 PaddleSlim模型压缩
PaddleSlim 是百度飞桨 (PaddlePaddle) 联合视觉技术部发布的模型压缩工具库,除了支持传统的网络剪枝、参数量化和知识蒸馏等方法外,还支持最新的神经网络结构搜索和自动模型压缩技术。这一天的任务就是熟悉PaddleSlim 的基本用法,参考的资料有PaddleSlim代码地址: https://github.com/PaddlePaddle/PaddleSlim
文档地址: https://paddlepaddle.github.io/PaddleSlim/
图像分类模型量化教程
1、导入依赖
PaddleSlim依赖Paddle1.7版本,请确认已正确安装Paddle,然后按以下方式导入Paddle和PaddleSlim:
import paddle
import paddle.fluid as fluid
import paddleslim as slim
import numpy as np2、构建模型
该章节构造一个用于对MNIST数据进行分类的分类模型,选用MobileNetV1,并将输入大小设置为[1, 28, 28],输出类别数为10。 为了方便展示示例,我们在paddleslim.models下预定义了用于构建分类模型的方法,执行以下代码构建分类模型:
use_gpu = fluid.is_compiled_with_cuda()
exe, train_program, val_program, inputs, outputs = slim.models.image_classification("MobileNet", [1, 28, 28], 10, use_gpu=use_gpu)
place = fluid.CUDAPlace(0) if fluid.is_compiled_with_cuda() else fluid.CPUPlace()3、定义输入数据
为了快速执行该示例,我们选取简单的MNIST数据,Paddle框架的paddle.dataset.mnist包定义了MNIST数据的下载和读取。 代码如下:
import paddle.dataset.mnist as reader
train_reader = paddle.batch(
reader.train(), batch_size=128, drop_last=True)
test_reader = paddle.batch(
reader.test(), batch_size=128, drop_last=True)
data_feeder = fluid.DataFeeder(inputs, place)4、训练模型
先定义训练和测试函数,正常训练和量化训练时只需要调用函数即可。在训练函数中执行了一个epoch的训练,因为MNIST数据集数据较少,一个epoch就可将top1精度训练到95%以上。
def train(prog):
iter = 0
for data in train_reader():
acc1, acc5, loss = exe.run(prog, feed=data_feeder.feed(data), fetch_list=outputs)
if iter % 100 == 0:
print('train iter={}, top1={}, top5={}, loss={}'.format(iter, acc1.mean(), acc5.mean(), loss.mean()))
iter += 1
def test(prog):
iter = 0
res = [[], []]
for data in test_reader():
acc1, acc5, loss = exe.run(prog, feed=data_feeder.feed(data), fetch_list=outputs)
if iter % 100 == 0:
print('test iter={}, top1={}, top5={}, loss={}'.format(iter, acc1.mean(), acc5.mean(), loss.mean()))
res[0].append(acc1.mean())
res[1].append(acc5.mean())
iter += 1
print('final test result top1={}, top5={}'.format(np.array(res[0]).mean(), np.array(res[1]).mean()))
调用train函数训练分类网络,train_program是在第2步:构建网络中定义的
train(train_program)
train iter=0, top1=0.125, top5=0.5546875, loss=2.60602283478
train iter=100, top1=0.9375, top5=1.0, loss=0.207247078419
train iter=200, top1=0.9765625, top5=1.0, loss=0.158098399639
train iter=300, top1=0.9609375, top5=0.9921875, loss=0.181878089905
train iter=400, top1=0.9609375, top5=1.0, loss=0.211138889194
调用test函数测试分类网络,val_program是在第2步:构建网络中定义的。
test(val_program)
test iter=0, top1=0.96875, top5=1.0, loss=0.0710430219769
final test result top1=0.968549668789, top5=0.998798072338
5、量化模型
按照配置在train_program和val_program中加入量化和反量化op.
place = exe.place
import paddleslim.quant as quant
#配置
quant_config = {
'weight_quantize_type': 'abs_max',
'activation_quantize_type': 'moving_average_abs_max',
'weight_bits': 8,
'activation_bits': 8,
'not_quant_pattern': ['skip_quant'],
'quantize_op_types': ['conv2d', 'depthwise_conv2d', 'mul'],
'dtype': 'int8',
'window_size': 10000,
'moving_rate': 0.9
}
build_strategy = fluid.BuildStrategy()
exec_strategy = fluid.ExecutionStrategy()
#调用api
quant_program = quant.quant_aware(train_program, place, quant_config, for_test=False) #请在次数添加你的代码
val_quant_program = quant.quant_aware(val_program, place, quant_config, for_test=True) #请在次数添加你的代码6、训练和测试量化后的模型
微调量化后的模型,训练一个epoch后测试。
train(quant_program)
train iter=0, top1=0.953125, top5=0.984375, loss=0.209631592035
train iter=100, top1=0.984375, top5=1.0, loss=0.0537333972752
train iter=200, top1=0.9765625, top5=1.0, loss=0.0834594219923
train iter=300, top1=0.984375, top5=0.9921875, loss=0.0935590267181
train iter=400, top1=0.96875, top5=1.0, loss=0.159391969442测试量化后的模型,和3.2 训练和测试中得到的测试结果相比,精度相近,达到了无损量化。
test(val_quant_program)
test iter=0, top1=1.0, top5=1.0, loss=0.0184555537999
final test result top1=0.977764427662, top5=0.999599337578