SQL MySQL和Sql Server的留存率及留存人数计算查询语句
#SQL MySQL和Sql Server留存率及留存人数计算
本文作者:
第一作者:负责MySQL的赵芮萱(下文称赵老师)
第二作者:负责Sql Server的叶嘉浩(下文称叶同学)
目前在墙外的Stackoverflow和墙内的CSDN BLOGs上都有不少实现留存率计算的文章,但是绝大部分此类文章存在3个问题:
1)查询语句思路单一,缺乏多个实现方法总结。
2)内容只涵盖了MySQL或者Sql Server,缺乏对两种Sql 工具的查询语句总结或者通用查询语句。
3)查询语句只能满足业务需求,无法满足效率需求,缺乏优化代码的思考。
下文将针对此3个问题展示留存率及留存人数查询语句。
数据表简介:
数据表名称为浏览明细表,该表有2个字段。
第1个字段为uid varchar(20),第2个字段为登陆日期时间(datetime)。
详细数据在文末。
一、留存人数计算
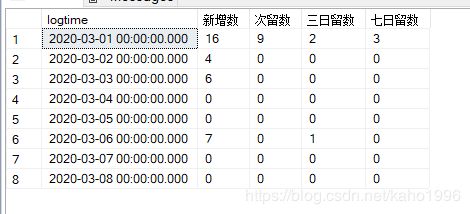
**1.1)第一种留存人数定义:**新增用户在第1天登录且在第N天登录。例如,3日留存用户数定义为在第1天作为新增用户登录且在第3天登录,至于第2天登录与否不考虑。
1.1.1)第1种写法,直接使用datediff函数=N。
CREATE VIEW a as
(select uid,min(logtime) as first_logtime from 浏览明细表 group by uid)
create view U as
(select distinct(logtime) from 浏览明细表)
select U.logtime,
count(distinct a.uid)as 新增数,
count(distinct b.uid)as 次留数,
count(distinct c.uid)as 三日留数,
count(distinct d.uid) as 七日留数
from U
left join a on U.logtime=a.first_logtime
left join 浏览明细表 b on datediff(dd,a.logtime,b.logtime)=1 and b.uid=a.uid
left join 浏览明细表 c on datediff(dd,a.logtime,b.logtime)=2 and c.uid=a.uid
left join 浏览明细表 d on datediff(dd,a.logtime,b.logtime)=6 and d.uid=a.uid
group by U.logtime
1.1.2)第2种写法,使用datetime+N的写法。
CREATE VIEW a as
(select uid,min(logtime) as first_logtime from 浏览明细表 group by uid)
create view U as
(select distinct(logtime) from 浏览明细表)
select U.logtime,
count(distinct a.uid)as 新增数,
count(distinct b.uid)as 次留数,
count(distinct c.uid)as 三日留数,
count(distinct d.uid) as 七日留数
from U
left join a on U.logtime=a.first_logtime
left join 浏览明细表 b on b.logtime=a.first_logtime+1 and b.uid=a.uid
left join 浏览明细表 c on c.logtime=a.first_logtime+2 and c.uid=a.uid
left join 浏览明细表 d on d.logtime=a.first_logtime+6 and d.uid=a.uid
group by U.logtime
用上述两种算法写出来的答案应该如下:
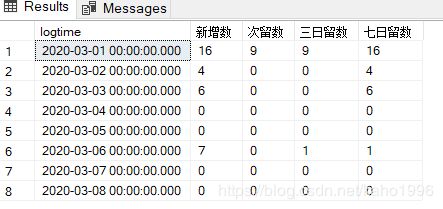
**1.2)第二种留存人数定义:**新增用户在第1天登录且在第2到N天之间任意一天登录。例如,3日留存用户数定义为在第1天作为新增用户登录且在第2或第3天任意一天登录。此种写法和上述2种写法不同之处在于每句left join语句结合了2句datediff函数语句。
CREATE VIEW a as
(select uid,min(logtime) as first_logtime from 浏览明细表 group by uid)
create view U as
(select distinct(logtime) from 浏览明细表)
select U.logtime,
count(distinct a.uid)as 新增数,
count(distinct b.uid)as 次留数,
count(distinct c.uid)as 三日留数,
count(distinct d.uid) as 七日留数
from U
left join a on U.logtime=a.first_logtime
left join 浏览明细表 b on (datediff(dd,a.first_logtime,b.logtime)=1 and b.uid=a.uid)
left join 浏览明细表 c on (datediff(dd,a.first_logtime,c.logtime)>=1 and datediff(dd,a.first_logtime,c.logtime)<=2 ) and c.uid=a.uid
left join 浏览明细表 d on (datediff(dd,a.first_logtime,d.logtime)>=1 and datediff(dd,a.first_logtime,d.logtime)<=6 ) and d.uid=a.uid
group by U.logtime
用上述算法写出来的答案应该如下:
二、留存率计算
留存率计算只需要在上述3种写法前添加1段查询语句即可,下文将用上述3种写法的其中1种作为例子,展示如何计算留存率,如果希望用其他写法来计算留存率,只需要直接套用即可。
select *,
concat(round(100*次留数/新增数,2),'%') as 次日留存率,
concat(round(100*三日留数/新增数,2),'%') as 三日留存率,
concat(round(100*七日留数/新增数,2),'%') as 七日留存率
from
(select U.logtime,
count(distinct a.uid)as 新增数,
count(distinct b.uid)as 次留数,
count(distinct c.uid)as 三日留数,
count(distinct d.uid) as 七日留数
from U
left join a on U.logtime=a.first_logtime
left join 浏览明细表 b on (datediff(dd,a.first_logtime,b.logtime)=1 and b.uid=a.uid)
left join 浏览明细表 c on (datediff(dd,a.first_logtime,c.logtime)>=1 and datediff(dd,a.first_logtime,c.logtime)<=2 ) and c.uid=a.uid
left join 浏览明细表 d on (datediff(dd,a.first_logtime,d.logtime)>=1 and datediff(dd,a.first_logtime,d.logtime)<=6 ) and d.uid=a.uid
group by U.logtime)as P
三、优化思路
第一部分的三种查询语句虽然略有不同,但是本质上是利用left join实现多表连接,但是在数据量较大和表数量多的时候,该做法会导致低运算效率,因此,可以用另一种写法提升运行效率。
select U.logtime,
sum(case when byday=0 then 1 else 0 end) as new,
sum(case when byday=1 then 1 else 0 end) as _2days,
sum(case when byday=2 then 1 else 0 end) as _3days,
sum(case when byday=6 then 1 else 0 end) as _7days
from U
left join (select distinct a.uid, logtime, first_logtime,datediff(dd,first_logtime,logtime) as byday
from 浏览明细表 x left join a on x.uid=a.uid) as sub on
U.logtime=sub.first_logtime
group by U.logtime
原写法测速语句:
Declare @d Datetime Set @d=GetDate()
select U.logtime,
count(distinct a.uid)as 新增数,
count(distinct b.uid)as 次留数,
count(distinct c.uid)as 三日留数,
count(distinct d.uid) as 七日留数
from U
left join a on U.logtime=a.first_logtime
left join 浏览明细表 b on datediff(dd,a.logtime,b.logtime)=1 and b.uid=a.uid
left join 浏览明细表 c on datediff(dd,a.logtime,b.logtime)=2 and c.uid=a.uid
left join 浏览明细表 d on datediff(dd,a.logtime,b.logtime)=6 and d.uid=a.uid
group by U.logtime
Select [语句执行花费时间(毫秒)]=DateDiff(ms,@d,GetDate())

*备注:虽然此处显示用时3毫秒,但是经过多次重复执行查询语句测试,实际上可能会返回0-14秒之间的任意数值,但是其中以3毫秒出现的频次最多和频率最高,所以,我们取众数3毫秒作为此段查询语句的运行时间。此处只测速第一部分3段语句的其中1种写法,但实际上此3段语句速度均为3毫秒。
优化写法测速语句:
Declare @d Datetime Set @d=GetDate()
select U.logtime,
sum(case when byday=0 then 1 else 0 end) as new,
sum(case when byday=1 then 1 else 0 end) as _2days,
sum(case when byday=2 then 1 else 0 end) as _3days,
sum(case when byday=6 then 1 else 0 end) as _7days
from U
left join (select distinct a.uid, logtime, first_logtime,datediff(dd,first_logtime,logtime) as byday
from 浏览明细表 x left join a on x.uid=a.uid) as sub on
U.logtime=sub.first_logtime
group by U.logtime
Select [语句执行花费时间(毫秒)]=DateDiff(ms,@d,GetDate())

*备注:虽然此处显示用时0毫秒,但是经过多次重复执行查询语句测试,实际上可能会返回0-4秒之间的任意数值,但是其中以0毫秒出现的频次最多和频率最高,所以,我们取众数0毫秒作为此段查询语句的运行时间。
结论:优化后的查询语句写法大约能提高运行效率3倍。
四、主表数据:
Create table 浏览明细表
(logtime datetime,
uid varchar(20))
insert into 浏览明细表(logtime,uid) values
('2020/3/1','a1001'),
('2020/3/1','a1002'),
('2020/3/1','a1003'),
('2020/3/1','a1004'),
('2020/3/1','a1005'),
('2020/3/1','a1006'),
('2020/3/1','a1007'),
('2020/3/1','a1008'),
('2020/3/1','a1009'),
('2020/3/1','a1010'),
('2020/3/1','a1011'),
('2020/3/1','a1012'),
('2020/3/1','a1013'),
('2020/3/1','a1014'),
('2020/3/1','a1015'),
('2020/3/1','a1016'),
('2020/3/2','a1001'),
('2020/3/2','a1002'),
('2020/3/2','a1003'),
('2020/3/2','a1003'),
('2020/3/2','a1004'),
('2020/3/2','a1005'),
('2020/3/2','a1006'),
('2020/3/2','a1007'),
('2020/3/2','a1008'),
('2020/3/2','a1009'),
('2020/3/2','a1020'),
('2020/3/2','a1019'),
('2020/3/2','a1018'),
('2020/3/2','a1017'),
('2020/3/3','a1021'),
('2020/3/3','a1022'),
('2020/3/3','a1023'),
('2020/3/3','a1024'),
('2020/3/3','a1025'),
('2020/3/3','a1026'),
('2020/3/3','a1001'),
('2020/3/3','a1002'),
('2020/3/4','a1001'),
('2020/3/4','a1002'),
('2020/3/4','a1003'),
('2020/3/4','a1004'),
('2020/3/4','a1005'),
('2020/3/4','a1006'),
('2020/3/4','a1007'),
('2020/3/4','a1008'),
('2020/3/4','a1009'),
('2020/3/4','a1009'),
('2020/3/5','a1010'),
('2020/3/5','a1011'),
('2020/3/5','a1012'),
('2020/3/5','a1013'),
('2020/3/5','a1014'),
('2020/3/5','a1015'),
('2020/3/5','a1016'),
('2020/3/5','a1017'),
('2020/3/6','a1018'),
('2020/3/6','a1019'),
('2020/3/6','a1020'),
('2020/3/6','a1021'),
('2020/3/6','a1022'),
('2020/3/6','a1023'),
('2020/3/6','a1024'),
('2020/3/6','a1025'),
('2020/3/6','a1026'),
('2020/3/6','a1027'),
('2020/3/6','a1028'),
('2020/3/6','a1029'),
('2020/3/6','a1030'),
('2020/3/6','a1031'),
('2020/3/6','a1032'),
('2020/3/6','a1033'),
('2020/3/7','a1001'),
('2020/3/7','a1002'),
('2020/3/7','a1003'),
('2020/3/7','a1023'),
('2020/3/7','a1024'),
('2020/3/7','a1018'),
('2020/3/7','a1019'),
('2020/3/7','a1020'),
('2020/3/8','a1001'),
('2020/3/8','a1002'),
('2020/3/8','a1003'),
('2020/3/8','a1012'),
('2020/3/8','a1013'),
('2020/3/8','a1014'),
('2020/3/8','a1015'),
('2020/3/8','a1030')
特别鸣谢:赵老师,吴磊二人为第三部分优化写法的贡献。
2020年5月23日早上6:22 于北京