GAN生成对抗网络入门篇
笔记整理:王小草
时间:2019年1月
一、GAN简介
1 背景
全称:generative adversarial network 生成式对抗网络(不一定是深度学习)
论文:https://arxiv.org/abs/1406.2661
提出者:Ian Goodfellow(也是深度学习花园书的作者)
2 Gan能做什么?
2.1 生成图片
下图,第一张图是真实图片,第二张是使用MSE为损失的监督模型生成的图片,第三张是使用GAN生成的图片,很明显,GAN生成的图片更加完整与清晰。

图片来自论文: W., Kreiman, G., and Cox, D. (2015). Unsupervised learning of visual structure using predictive generative networks.
2.2 超分辨率补全图片
再如下图,假设将第一张图片resize成原来的1/4,然后要用一定的技术将其拉伸到原来的大小,那么拉伸的过程必然需要去将丢失掉的像素给补回来。第二张图是用插值法补全的像素,比较模糊;第三张图片是利用一个有监督的神经网络模型SRResNet在MSE损失函数基础之上训练,并预测的图片,比前者要好很多;第四张图片是用GAN生成的,分辨率更高。

图片来自论文:Photo-realistic single image super-resolution using a generative adversarial.
2.3 画画
如下图,随便画一个线条或图像,GAN可以根据它绘制出对应的风景与事物
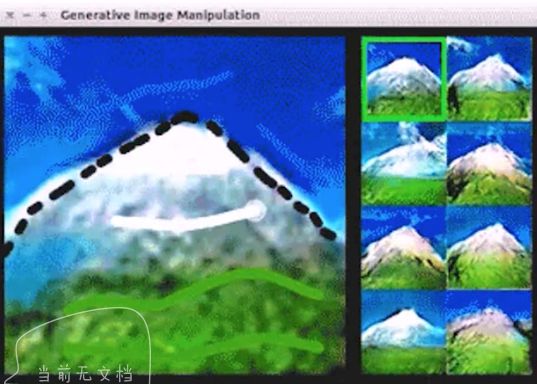
2.4 图像恢复
如下图,左边是GAN根据分割图回复街景;右边是通过简笔画回复真是的包包照片,虽然和真实的包有一点差异,但不难看出恢复能力惊为天人。

来自论文:image-to-image translation adversarial network
2.5 根据图片预测视频
给定一下给图片,GAN会去将图片生成一个有关的视频

2.6 根据照片生成事物的3D图

2.7 表情生成
给一个人脸的照片,GAN可生成人脸的各种表情与造型,虽然很牛逼但我有点瘆得慌。

二、GAN预备知识–深度学习
预备知识主要是深度学习,虽然GAN不一定要用深度学,但是最近的研究都是聚焦于表现比较好的神经网络的。由于深度学习是另一个大的知识点,各种博客、课程、教程遍地都是,并且我相信知道并想要学习GAN的同学必定是有了深度学习基础的,因此本文不再班门弄斧。
三、GAN网络实战分析–生成手写字体
1 思路
1.1 流程概述
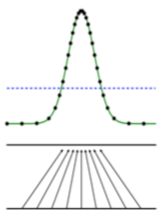
先看下图,绿线是生成样本的概率分布;黑点线是真实样本的概率分布;紫色线是一个判决器,用来判断样本是真的还是假的;z是噪声。
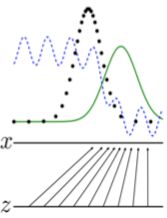
第一步,要做的是要把判别器判断准,使得求得一个阈值,在阈值左边是判断为真实样本,右边判断为生成样本。
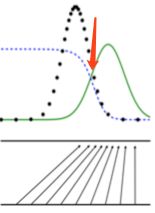
第二步,就要使生成的样本去尽量拟合真实的样本,从而去误导判决器
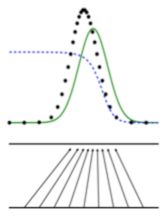
最终,如果生成的样本分布与真实的样本分布一致了,判决器就痴呆了
1.2 同款栗子
上面的讲述若略有抽象,这里来看一个直观的例子。GAN有两个部分组成,一个是生成器,去生成样本用的;一个是判别器,去判别是真实样本还是生成样本。

如上图,
首先画一张很丑的假币(生成一个样本),这个时候教小孩去判别真假币(训练判别器)
在不断模仿真币的过程中,做的假币越来越像真币了,生成了新的假币;此时小孩无法辨别真伪了,他通过学习终于学会了去根据水印判别,拥有了验钞器一样的识别能力。
接着生成器又通过不断学习,生成了更优秀的假币;小孩(判别器)再怎么学习都识别出来真伪了。
以上步骤,就是GAN的通俗解释,生成器在与判别器得对抗下,不断优化自己,最后能生成非常优秀的图片。
GoodFellow在论文中还阐述了GAN的全局最小点的充分必要条件,即生成器的概率分布=真实样本的概率分布。
![]()
2 GAN分析问题
2.1 目标函数如何设定
-
目标函数公式:
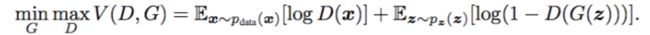
-
变量解释:
x:真实图片
z:输入G网络的噪声
G(z):G网络生成的图片
D(x):判别为D网络判断真实图片是否为真实的概率(越接近于1月好)
D(G(x)):判别为D网络判断G生成的图片是否为真实的概率 -
目标:
D的目的:求目标函数最大的D。D的能力越强,D(x)越大,D(G(x))越小,V(D,G)就越大,因此是求目标函数最大时的D。
G的目的:目标是使得生成的图片越接近真实图片越好,即V(D,G)最小时的G。 -
trick
为了加快训练,生成器的训练可以把log(1-D(G(z))) 换成-log(D(G(z))。
2.2 模型结构与训练过程
根据以上目标函数,可以看到目标函数的求解是分成两步:
(1)先固定住生成器G,通过目标函数最大化求得判别器D
(2)再固定住判别器D,通过目标函数最小化求的生成器G
如此迭代循环,最后得到杠杠的生成器G,使得判别器无力回天判别真假。
-
模型结构如下图:

-
现在来具体看看模型是如何运作的:
(1)首先有一批真实的样本(黄色柱),从中选出一组sample(mini-batch),我们将它标注为input1
(2)同时固定住判别器D(粉色方块),z是噪音,将它输入生成器G(蓝色方块),在目标函数最小的情况下由G生成一组sample,我们将它标注为input2。
(3)固定住生成器G,此时通过目标函数最大化来求解最优的判别器D,使得真实样本D(x)尽量=1, 生成样本D(G(z))尽量=0。
(4)固定住当前训练得到的最优的D,去训练最优的G,使得生成的样本与真实的样本尽可能地接近,从而混淆判别器。
(5)重复以上步骤,不断优化D和G,直到满足停止条件,得到最优的G和傻掉的D。 -
伪代码:

-
论文里提供的伪代码:

3 代码案例详解
以上通过结构图,文字,伪代码描述了GAN的逻辑与原理,现在来看看手写数字生成的完整的Python代码,参考自github上的一个项目,使用kares构建的模型。
代码地址:https://github.com/jacobgil/keras-dcgan/blob/master/dcgan.py
首先构建生成器的函数,是一个将随机生成的输入数据转换成一张图片的模型:
def generator_model():
model = Sequential() # 初始化模型,为一个序列
model.add(Dense(input_dim=100, output_dim=1024)) # 全连接层,将输入的100维转换成1024维
model.add(Activation('tanh'))
model.add(Dense(128*7*7)) # 全连接层,转换成128*7*7的图像形式
model.add(BatchNormalization()) # 很重要的BNM,不做的话会出问题
model.add(Activation('tanh'))
model.add(Reshape((7, 7, 128), input_shape=(128*7*7,))) # 转变形状
model.add(UpSampling2D(size=(2, 2))) # 插值为原来的两倍即14*14*128
model.add(Conv2D(64, (5, 5), padding='same')) # 过一个卷积,输出维度保持不变
model.add(Activation('tanh'))
model.add(UpSampling2D(size=(2, 2))) # 继续插值为原来的两倍,即28*28*128
model.add(Conv2D(1, (5, 5), padding='same')) # 过第三个卷积
model.add(Activation('tanh'))
return model # 返回生成模型
构建判别器的函数,属于一个二分类模型
def discriminator_model():
model = Sequential()
model.add(
Conv2D(64, (5, 5),
padding='same',
input_shape=(28, 28, 1))
)
model.add(Activation('tanh'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(128, (5, 5)))
model.add(Activation('tanh'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten()) # 拉平整个矩阵为一个一维向量
model.add(Dense(1024)) # 全连接层,输出长度1024
model.add(Activation('tanh'))
model.add(Dense(1)) # 经过全连接层,降维成1个数值
model.add(Activation('sigmoid')) # 最后一层接sigmoid函数输出一个概率
return model
绑定判别器,训练生成器的函数:
输入时生成器g,判别器d两个模型,输出为绑定了d的完整模型
def generator_containing_discriminator(g, d):
model = Sequential() # 初始化模型
model.add(g) # 将g加入模型中
d.trainable = False # 绑定d的参数不东
model.add(d) # 将绑定了的d加入模型中
return model # 返回完整模型
组合生成的图像:
因为预测的时候生成器会输出一批图片。
def combine_images(generated_images):
num = generated_images.shape[0]
width = int(math.sqrt(num))
height = int(math.ceil(float(num)/width))
shape = generated_images.shape[1:3]
image = np.zeros((height*shape[0], width*shape[1]),
dtype=generated_images.dtype)
for index, img in enumerate(generated_images):
i = int(index/width)
j = index % width
image[i*shape[0]:(i+1)*shape[0], j*shape[1]:(j+1)*shape[1]] = img[:, :, 0]
return image
以上写好了4个函数,现在可以开始训练了。封装一个训练的函数,使得每批数据上都进行一次判别器的训练和生成器的训练:
def train(BATCH_SIZE):
# 加载数据
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# 标准化像素到-1-1之间,弓60000个样本,每个样本28*28大小:(60000, 28, 28)
X_train = (X_train.astype(np.float32) - 127.5)/127.5
# 训练样本增加一个维度,以none填充:(60000, 28, 28, 1)
X_train = X_train[:, :, :, None]
# X_test = X_test[:, :, :, None]
# X_train = X_train.reshape((X_train.shape, 1) + X_train.shape[1:])
# 加载判别器模型
d = discriminator_model()
# 加载生成器模型
g = generator_model()
# 加载绑定了判别器的模型
d_on_g = generator_containing_discriminator(g, d)
# 判别器的优化函数
d_optim = SGD(lr=0.0005, momentum=0.9, nesterov=True)
# 生成器的优化函数
g_optim = SGD(lr=0.0005, momentum=0.9, nesterov=True)
# 生成器损失设置为二元交叉熵损失
g.compile(loss='binary_crossentropy', optimizer="SGD")
# 绑定判别器模型的损失为二元交叉熵损失
d_on_g.compile(loss='binary_crossentropy', optimizer=g_optim)
# 开启判别器模型的训练开关
d.trainable = True
# 生成器模型的损失设置为二元交叉熵损失
d.compile(loss='binary_crossentropy', optimizer=d_optim)
# 循环100个epoch
for epoch in range(100):
print("Epoch is", epoch)
print("Number of batches", int(X_train.shape[0]/BATCH_SIZE))
# 循环每批数据
for index in range(int(X_train.shape[0]/BATCH_SIZE)):
# # step 1: 训练判别器
# 生成随机的噪音数据,-1到1之间
noise = np.random.uniform(-1, 1, size=(BATCH_SIZE, 100))
# 获取真实的图像批数据
image_batch = X_train[index*BATCH_SIZE:(index+1)*BATCH_SIZE]
# 生成器根据噪音生成图片
generated_images = g.predict(noise, verbose=0)
# 每20批数据保存出生成的图片来看看
if index % 20 == 0:
image = combine_images(generated_images)
image = image*127.5+127.5
Image.fromarray(image.astype(np.uint8)).save(
str(epoch)+"_"+str(index)+".png")
# 将真实图片与生成图片拼接起来
X = np.concatenate((image_batch, generated_images))
# 设置label,真实图片为1,生成图片为0
y = [1] * BATCH_SIZE + [0] * BATCH_SIZE
# 计算损失(前面的步骤中已经编译了损失)
d_loss = d.train_on_batch(X, y)
print("batch %d d_loss : %f" % (index, d_loss))
# # step 2:训练生成器
# 继续生成噪音
noise = np.random.uniform(-1, 1, (BATCH_SIZE, 100))
# 关闭判别器的训练
d.trainable = False
# 计算损失
g_loss = d_on_g.train_on_batch(noise, [1] * BATCH_SIZE)
# 重新打开判别器的训练
d.trainable = True
print("batch %d g_loss : %f" % (index, g_loss))
# 定期保存两个模型的参数
if index % 10 == 9:
g.save_weights('generator', True)
d.save_weights('discriminator', True)
最后,训练好的模型可以用来做预测与生成:
def generate(BATCH_SIZE, nice=False):
# 加载训练好的模型
g = generator_model()
g.compile(loss='binary_crossentropy', optimizer="SGD")
g.load_weights('generator')
if nice:
d = discriminator_model()
d.compile(loss='binary_crossentropy', optimizer="SGD")
d.load_weights('discriminator')
noise = np.random.uniform(-1, 1, (BATCH_SIZE*20, 100))
generated_images = g.predict(noise, verbose=1)
d_pret = d.predict(generated_images, verbose=1)
index = np.arange(0, BATCH_SIZE*20)
index.resize((BATCH_SIZE*20, 1))
pre_with_index = list(np.append(d_pret, index, axis=1))
pre_with_index.sort(key=lambda x: x[0], reverse=True)
nice_images = np.zeros((BATCH_SIZE,) + generated_images.shape[1:3], dtype=np.float32)
nice_images = nice_images[:, :, :, None]
for i in range(BATCH_SIZE):
idx = int(pre_with_index[i][18])
nice_images[i, :, :, 0] = generated_images[idx, :, :, 0]
image = combine_images(nice_images)
else:
# 生成噪音
noise = np.random.uniform(-1, 1, (BATCH_SIZE, 100))
# 生成图片
generated_images = g.predict(noise, verbose=1)
# 组合图片
image = combine_images(generated_images)
# 复原图片像素范围
image = image*127.5+127.5
# 保存图片
Image.fromarray(image.astype(np.uint8)).save(
"generated_image.png")
运行整个程序:
def get_args():
parser = argparse.ArgumentParser()
parser.add_argument("--mode", type=str, default="train")
parser.add_argument("--batch_size", type=int, default=128)
parser.add_argument("--nice", dest="nice", action="store_true")
parser.set_defaults(nice=False)
args = parser.parse_args()
return args
if __name__ == "__main__":
args = get_args()
if args.mode == "train":
train(BATCH_SIZE=args.batch_size)
elif args.mode == "generate":
generate(BATCH_SIZE=args.batch_size, nice=args.nice)
输出结果:
epoch=0时生成图像:

epoch=5时生成图像:

epoch=9时生成图像:

epoch=19时生成图像:

epoch=86时生成图像:

啧啧啧,越来越好看了,时间问题我就不继续迭代了。
四、GAN优化与改进模型
1 CGAN
上面讲述的GAN生成图片是很随意的,但如果我就是想让生成器生成数字1,就需要CGAN出场了。下图是GAN与CGAN的结构对比,CGAN其实就是在进入生成器与判别器之前多了一个条件c

下面是目标函数的对比,区别就是加了一个y的条件:
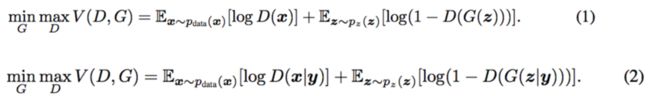
2 DCGAN
DCGAN全称:deep convolutional generative adversarial networks
论文:DCGAN:deep convolutional generative adversarial networks
贡献点:与GAN同年发表的论文,将GAN与卷积网络结合起来的经典论文,且提出了非常重要的有助于GAN稳定性的Tricks。
结构如下:

tricks:
- 所有pooling都用strided convolutions代替,pooling的下采样是损失信息的,strided convolutions可以让模型自己学习损失的信息
- 生成器G和判别器D都要用BN层,从而不需要dropout或l1,l2正则
- 把全连接层去掉,用全卷积层代替
- 生成器除了输出层,激活函数统一使用ReLU。输出层用Tanh。
- 判别器所有的层的激活函数统一用leaky-relu
论文中的一些结果:

具体请参看文献。
3 ACGAN
全称:Aixiliary Classifier GANs
特点:在GAN的基础之上,加上了一个类别。
结构:
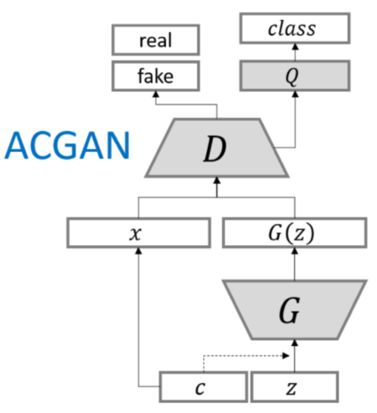
目标函数:

在原来的基础之上加了分类的损失。
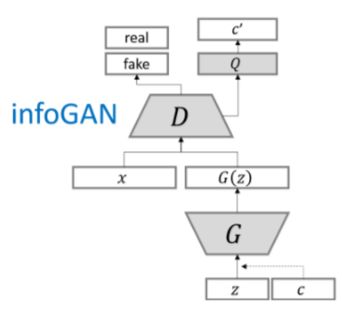
4 infoGAN
据说牛逼的很,是2016年Open AI的五大突破之一。
论文:InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets
参考资料:http://www.tk4479.net/hjimce/article/details/55657325
模型结构:
目标函数:
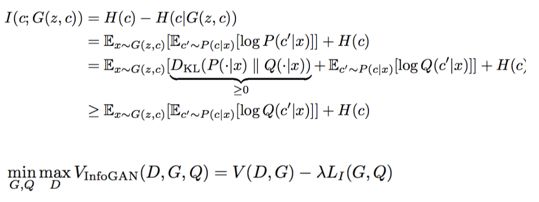
公式的具体推导可以看上面的参考资料链接
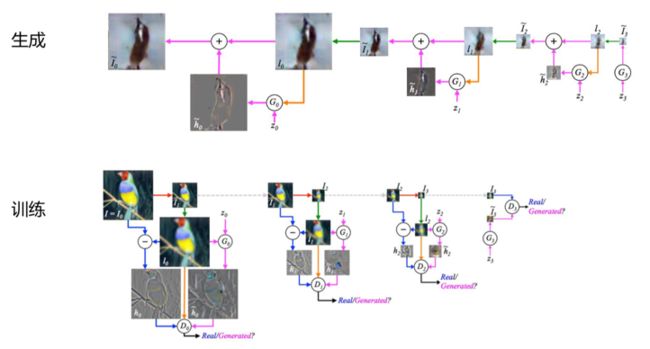
5 LAPGAN
生成步骤:
GAN的目标是如何通过噪音生成图片,但是不可控因素太多了,lAPGAN的做法是,我先用噪音生成一个小的图片,将这张图片进行拉伸,然后利用之前生成的GAN的网络去生成一个他的残差,将残差和拉伸的图片相加,得到一张新的图片。如此循环,一张小图就会准建变成一张大图
训练步骤:
先将原图进行压缩,然后再拉伸,拉伸后的图与原图做残差,同时生成器也会生成一张残差图,然后让判别器去判断两张残差图。不断循环往复,图片会越来越小。到最后会有一张真实图来的小图,和生成器生成的小图,再让判别器去判别这两张图。
两个过程的结构如下:
6 EBGAN
全称:Energy-based GAN
提出来一种新的思路,判别器抛弃了对和错的判断,而是加了一个能量的东西,将图片经过encoder与decoder,在做MSE,希望经过以上编码解码的真实图像与原图的损失尽量小,生成图与原图尽量大。
生成器与判别器的损失函数:
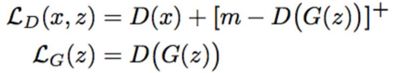
结构图:

五、GAN的注意点
- G,D迭代的方式能达到全局最优解么?大部分情况是局部最优解
- 不一定收敛,学习率不能高,G,D要共同成长,不能其中一个成长的过快
- 崩溃的问题,通俗说,G 找到D的漏洞,每次都生成一样的骗D
- 无需预先建模,模型过于自由,不可控
- 判别器训练得太好,生成器梯度消失,生成器loss降不下
- 判别器训练得不好,生成器梯度不准,四处乱跑
因此GNN需要解决三个核心问题:
- 稳定性
- 多样性
- 清晰度
为什么GAN会需要解决以上问题,因为GAN的目标函数最终会推导为KL散度问题,而KL散度就是有这些坑的:

那么有没有办法能规避掉KL存在的缺陷呢,有的,2017年提出了一篇里程碑式的论文,提出WGAN。用Wasserstein距离代替KL散度,训练网络稳定性大大增强,不用拘泥DCGAN的那些策略
- 判别器最后一层去掉sigmoid
- 生成器和判别器的loss不取log
- 每次更新判别器的参数之后把它们的绝对值截断到不超过一个固定常数c
- 不要用基于动量的优化算法(包括momentum和Adam),推荐RMSProp,SGD也行
GAN与WGAN的目标函数比较:
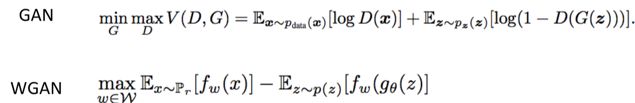
对WGAN的优化:WGAN with gradient penalty
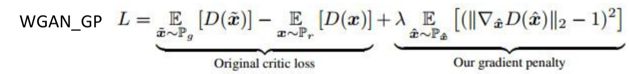
但是后来有人提出DRAGAN(deep regret analytic GAN)说,我直接在GAN上加gradient penalty,效果也和WGAN是一样的。以下是生成图片的比较:

说不出谁好谁坏。
六、比较
有一篇论文比较了各种GAN的模型:《Are GANs Created Equal? A Large-Scale Study》

比较结果:
指标FID

结论:特定的数据集说特定的事情,没有哪一种碾压其他。好的算法还得看成本,时间短的效果某家强,但是训练时间长了,反倒会变差。根据评价标准的不同,场景的不同,效果差的算法也可以逆袭。
参考资料:小象学院课程