相信很多来这里的人和我第一次到这里一样,都是想找一种比较好的目标跟踪算法,或者想对目标跟踪这个领域有比较深入的了解,虽然这个问题是经典目标跟踪算法,但事实上,可能我们并不需要那些曾经辉煌但已被拍在沙滩上的tracker(目标跟踪算法),而是那些即将成为经典的,或者就目前来说最好用、速度和性能都看的过去tracker。我比较关注目标跟踪中的相关滤波方向,接下来我帮您介绍下我所认识的目标跟踪,尤其是相关滤波类方法,分享一些我认为比较好的算法,顺便谈谈我的看法。
1.图片来自某些slides和paper,如有侵权请提醒删除。
2.以下内容主要是论文的简单总结,代码分析和个人看法,不涉及任何公司内部资料。
3.转载请注明出处,谢谢。
4.如有错误欢迎指出,非常感谢。有问题可以私信我,也可以在评论区提出,时间有限但也都会尽量回复,同时感谢各位道友帮忙解答。
第一部分:目标跟踪速览
先跟几个SOTA的tracker混个脸熟,大概了解一下目标跟踪这个方向都有些什么。一切要从2013年的那个数据库说起。。如果你问别人近几年有什么比较niubility的跟踪算法,大部分人都会扔给你吴毅老师的论文,OTB50和OTB100(OTB50这里指OTB-2013,OTB100这里指OTB-2015,50和100分别代表视频数量,方便记忆):
- Wu Y, Lim J, Yang M H. Online object tracking: A benchmark [C]// CVPR, 2013.
- Wu Y, Lim J, Yang M H. Object tracking benchmark [J]. TPAMI, 2015.
顶会转顶刊的顶级待遇,在加上引用量1480+320多,影响力不言而喻,已经是做tracking必须跑的数据库了,测试代码和序列都可以下载: Visual Tracker Benchmark,OTB50包括50个序列,都经过人工标注:

两篇论文在数据库上对比了包括2012年及之前的29个顶尖的tracker,有大家比较熟悉的OAB, IVT, MIL, CT, TLD, Struck等,大都是顶会转顶刊的神作,由于之前没有比较公认的数据库,论文都是自卖自夸,大家也不知道到底哪个好用,所以这个database的意义非常重大,直接促进了跟踪算法的发展,后来又扩展为OTB100发到TPAMI,有100个序列,难度更大更加权威,我们这里参考OTB100的结果,首先是29个tracker的速度和发表时间(标出了一些性能速度都比较好的算法):

接下来再看结果(更加详细的情况建议您去看论文比较清晰):
直接上结论:平均来看Struck, SCM, ASLA的性能比较高,排在前三不多提,着重强调CSK,第一次向世人展示了相关滤波的潜力,排第四还362FPS简直逆天了。速度排第二的是经典算法CT(64fps)(与SCM, ASLA等都是那个年代最热的稀疏表示)。如果对更早期的算法感兴趣,推荐另一篇经典的survey(反正我是没兴趣也没看过):
- Yilmaz A, Javed O, Shah M. Object tracking: A survey [J]. CSUR, 2006.
2012年以前的算法基本就是这样,自从2012年AlexNet问世以后,CV各个领域都有了巨大变化,所以我猜你肯定还想知道2013到2017年发生了什么,抱歉我也不知道(容我卖个关子),不过我们可以肯定的是,2013年以后的论文一定都会引用OTB50这篇论文,借助谷歌学术中的被引用次数功能,得到如下结果:

这里仅列举几个引用量靠前的,依次是Struck转TPAMI, 三大相关滤波方法KCF, CN, DSST, 和VOT竞赛,这里仅作示范,有兴趣可以亲自去试试。(这么做的理论依据是:一篇论文,在它之前的工作可以看它的引用文献,之后的工作可以看谁引用了它;虽然引用量并不能说明什么,但好的方法大家基本都会引用的(表示尊重和认可);之后还可以通过限定时间来查看某段时间的相关论文,如2016-2017就能找到最新的论文了,至于论文质量需要仔细甄别;其他方向的重要论文也可以这么用,顺藤摸瓜,然后你就知道大牛是哪几位,接着关注跟踪一下他们的工作 ) 这样我们就大致知道目标跟踪领域的最新进展应该就是相关滤波无疑了,再往后还能看到相关滤波类算法有SAMF, LCT, HCF, SRDCF等等。当然,引用量也与时间有关,建议分每年来看。此外,最新版本OPENCV3.2除了TLD,也包括了几个很新的跟踪算法 OpenCV: Tracking API:

TrackerKCF接口实现了KCF和CN,影响力可见一斑,还有个GOTURN是基于深度学习的方法,速度虽快但精度略差,值得去看看。tracking方向的最新论文,可以跟进三大会议(CVPR/ICCV/ECCV) 和arXiv。
第二部分:背景介绍
接下来总体介绍下目标跟踪。这里说的目标跟踪,是通用单目标跟踪,第一帧给个矩形框,这个框在数据库里面是人工标注的,在实际情况下大多是检测算法的结果,然后需要跟踪算法在后续帧紧跟住这个框,以下是VOT对跟踪算法的要求:

通常目标跟踪面临几大难点(吴毅在VALSE的slides):外观变形,光照变化,快速运动和运动模糊,背景相似干扰:

平面外旋转,平面内旋转,尺度变化,遮挡和出视野等情况:

正因为这些情况才让tracking变得很难,目前比较常用的数据库除了OTB,还有前面找到的VOT竞赛数据库(类比ImageNet),已经举办了四年,VOT2015和VOT2016都包括60个序列,所有序列也是免费下载 VOT Challenge | Challenges:
- Kristan M, Pflugfelder R, Leonardis A, et al. The visual object tracking vot2013 challenge results [C]// ICCV, 2013.
- Kristan M, Pflugfelder R, Leonardis A, et al. The Visual Object Tracking VOT2014 Challenge Results [C]// ECCV, 2014.
- Kristan M, Matas J, Leonardis A, et al. The visual object tracking vot2015 challenge results[C]// ICCV, 2015.
- Kristan M, Ales L, Jiri M, et al. The Visual Object Tracking VOT2016 Challenge Results[C]// ECCV, 2016.
OTB和VOT区别:OTB包括25%的灰度序列,但VOT都是彩色序列,这也是造成很多颜色特征算法性能差异的原因;两个库的评价指标不一样,具体请参考论文;VOT库的序列分辨率普遍较高,这一点后面分析会提到。对于一个tracker,如果论文在两个库(最好是OTB100和VOT2016)上都结果上佳,那肯定是非常优秀的(两个库调参你能调好,我服,认了~~),如果只跑了一个,个人更偏向于VOT2016,因为序列都是精细标注,且评价指标更好(人家毕竟是竞赛,评价指标发过TPAMI的),差别最大的地方,OTB有随机帧开始,或矩形框加随机干扰初始化去跑,作者说这样更加符合检测算法给的框框;而VOT是第一帧初始化去跑,每次跟踪失败(预测框和标注框不重叠)时,5帧之后重新初始化,VOT以short-term为主,且认为跟踪检测应该在一起不分离,detecter会多次初始化tracker。
补充:OTB在2013年公开了,对于2013以后的算法是透明的,论文都会去调参,尤其是那些只跑OTB的论文,如果关键参数直接给出还精确到小数点后两位,建议您先实测(人心不古啊~被坑的多了)。VOT竞赛的数据库是每年更新,还动不动就重新标注,动不动就改变评价指标,对当年算法是难度比较大,所以结果相对更可靠。(相信很多人和我一样,看每篇论文都会觉得这个工作太好太重要了,如果没有这篇论文,必定地球爆炸,宇宙重启~~所以就像大家都通过历年ILSVRC竞赛结果为主线了解深度学习的发展一样,第三方的结果更具说服力,所以我也以竞赛排名+是否公开源码+实测性能为标准,优选几个算法分析)
目标视觉跟踪(Visual Object Tracking),大家比较公认分为两大类:生成(generative)模型方法和判别(discriminative)模型方法,目前比较流行的是判别类方法,也叫检测跟踪tracking-by-detection,为保持回答的完整性,以下简单介绍。
生成类方法,在当前帧对目标区域建模,下一帧寻找与模型最相似的区域就是预测位置,比较著名的有卡尔曼滤波,粒子滤波,mean-shift等。举个例子,从当前帧知道了目标区域80%是红色,20%是绿色,然后在下一帧,搜索算法就像无头苍蝇,到处去找最符合这个颜色比例的区域,推荐算法ASMS vojirt/asms:
- Vojir T, Noskova J, Matas J. Robust scale-adaptive mean-shift for tracking [J]. Pattern Recognition Letters, 2014.
ASMS与DAT并称“颜色双雄”(版权所有翻版必究),都是仅颜色特征的算法而且速度很快,依次是VOT2015的第20名和14名,在VOT2016分别是32名和31名(中等水平)。ASMS是VOT2015官方推荐的实时算法,平均帧率125FPS,在经典mean-shift框架下加入了尺度估计,经典颜色直方图特征,加入了两个先验(尺度不剧变+可能偏最大)作为正则项,和反向尺度一致性检查。作者给了C++代码,在相关滤波和深度学习盛行的年代,还能看到mean-shift打榜还有如此高的性价比实在不容易(已泪目~~),实测性能还不错,如果您对生成类方法情有独钟,这个非常推荐您去试试。(某些算法,如果连这个你都比不过。。天台在24楼,不谢)
判别类方法,OTB50里面的大部分方法都是这一类,CV中的经典套路图像特征+机器学习, 当前帧以目标区域为正样本,背景区域为负样本,机器学习方法训练分类器,下一帧用训练好的分类器找最优区域:

与生成类方法最大的区别是,分类器采用机器学习,训练中用到了背景信息,这样分类器就能专注区分前景和背景,所以判别类方法普遍都比生成类好。举个例子,在训练时告诉tracker目标80%是红色,20%是绿色,还告诉它背景中有橘红色,要格外注意别搞错了,这样的分类器知道更多信息,效果也相对更好。tracking-by-detection和检测算法非常相似,如经典行人检测用HOG+SVM,Struck用到了haar+structured output SVM,跟踪中为了尺度自适应也需要多尺度遍历搜索,区别仅在于跟踪算法对特征和在线机器学习的速度要求更高,检测范围和尺度更小而已。这点其实并不意外,大多数情况检测识别算法复杂度比较高不可能每帧都做,这时候用复杂度更低的跟踪算法就很合适了,只需要在跟踪失败(drift)或一定间隔以后再次检测去初始化tracker就可以了。其实我就想说,FPS才TMD是最重要的指标,慢的要死的算法可以去死了(同学别这么偏激,速度是可以优化的)。经典判别类方法推荐Struck和TLD,都能实时性能还行,Struck是2012年之前最好的方法,TLD是经典long-term的代表,思想非常值得借鉴:
- Hare S, Golodetz S, Saffari A, et al. Struck: Structured output tracking with kernels [J]. IEEE TPAMI, 2016.
- Kalal Z, Mikolajczyk K, Matas J. Tracking-learning-detection [J]. IEEE TPAMI, 2012.
长江后浪推前浪,前面的已被排在沙滩上,这个后浪就是相关滤波和深度学习。相关滤波类方法correlation filter简称CF,也叫做discriminative correlation filter简称DCF,注意和后面的DCF算法区别,包括前面提到的那几个,也是后面要着重介绍的。深度学习(Deep ConvNet based)类方法,因为深度学习类目前不适合落地就不瞎推荐了,可以参考Winsty的几篇 Naiyan Wang - Home,还有VOT2015的冠军MDNet Learning Multi-Domain Convolutional Neural Networks for Visual Tracking,以及VOT2016的冠军TCNN http://www.votchallenge.net/vot2016/download/44_TCNN.zip,速度方面比较突出的如80FPS的SiamFC SiameseFC tracker和100FPS的GOTURN davheld/GOTURN,注意都是在GPU上。基于ResNet的SiamFC-R(ResNet)在VOT2016表现不错,很看好后续发展,有兴趣也可以去VALSE听作者自己讲解 VALSE-20160930-LucaBertinetto-Oxford-JackValmadre-Oxford-pu,至于GOTURN,效果比较差,但优势是跑的很快100FPS,如果以后效果也能上来就好了。做科研的同学深度学习类是关键,能兼顾速度就更好了。
- Nam H, Han B. Learning multi-domain convolutional neural networks for visual tracking [C]// CVPR, 2016.
- Nam H, Baek M, Han B. Modeling and propagating cnns in a tree structure for visual tracking. arXiv preprint arXiv:1608.07242, 2016.
- Bertinetto L, Valmadre J, Henriques J F, et al. Fully-convolutional siamese networks for object tracking [C]// ECCV, 2016.
- Held D, Thrun S, Savarese S. Learning to track at 100 fps with deep regression networks [C]// ECCV, 2016.
最后,深度学习END2END的强大威力在目标跟踪方向还远没有发挥出来,还没有和相关滤波类方法拉开多大差距(速度慢是天生的我不怪你,但效果总该很好吧,不然你存在的意义是什么呢。。革命尚未成功,同志仍须努力)。另一个需要注意的问题是目标跟踪的数据库都没有严格的训练集和测试集,需要离线训练的深度学习方法就要非常注意它的训练集有没有相似序列,而且一直到VOT2017官方才指明要限制训练集,不能用相似序列训练模型。
最后强力推荐两个资源。王强
@H Hakase
维护的相关滤波类资源 HakaseH/CF_benchmark_results ,详细分类和论文代码资源,走过路过别错过,相关滤波类算法非常全面,非常之用心!
(以上两位,看到了请来我处交一下广告费,9折优惠~~)
第三部分:相关滤波
介绍最经典的高速相关滤波类跟踪算法CSK, KCF/DCF, CN。很多人最早了解CF,应该和我一样,都是被下面这张图吸引了:
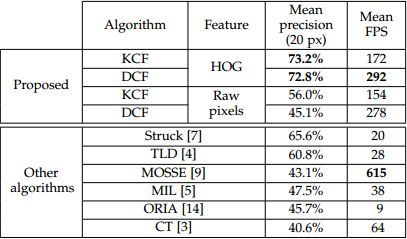
这是KCF/DCF算法在OTB50上(2014年4月就挂arVix了, 那时候OTB100还没有发表)的实验结果,Precision和FPS碾压了OTB50上最好的Struck,看惯了勉强实时的Struck和TLD,飙到高速的KCF/DCF突然有点让人不敢相信,其实KCF/DCF就是在OTB上大放异彩的CSK的多通道特征改进版本。注意到那个超高速615FPS的MOSSE(严重超速这是您的罚单),这是目标跟踪领域的第一篇相关滤波类方法,这其实是真正第一次显示了相关滤波的潜力。和KCF同一时期的还有个CN,在2014'CVPR上引起剧烈反响的颜色特征方法,其实也是CSK的多通道颜色特征改进算法。从MOSSE(615)到 CSK(362) 再到 KCF(172FPS), DCF(292FPS), CN(152FPS), CN2(202FPS),速度虽然是越来越慢,但效果越来越好,而且始终保持在高速水平:
- Bolme D S, Beveridge J R, Draper B A, et al. Visual object tracking using adaptive correlation filters [C]// CVPR, 2010.
- Henriques J F, Caseiro R, Martins P, et al. Exploiting the circulant structure of tracking-by- detection with kernels [C]// ECCV, 2012.
- Henriques J F, Rui C, Martins P, et al. High-Speed Tracking with Kernelized Correlation Filters [J]. IEEE TPAMI, 2015.
- Danelljan M, Shahbaz Khan F, Felsberg M, et al. Adaptive color attributes for real-time visual tracking [C]// CVPR, 2014.

CSK和KCF都是Henriques J F(牛津大学)João F. Henriques 大神先后两篇论文,影响后来很多工作,核心部分的岭回归,循环移位的近似密集采样,还给出了整个相关滤波算法的详细推导。还有岭回归加kernel-trick的封闭解,多通道HOG特征。
Martin Danelljan大牛(林雪平大学)用多通道颜色特征Color Names(CN)去扩展CSK得到了不错的效果,算法也简称CN Coloring Visual Tracking 。
MOSSE是单通道灰度特征的相关滤波,CSK在MOSSE的基础上扩展了密集采样(加padding)和kernel-trick,KCF在CSK的基础上扩展了多通道梯度的HOG特征,CN在CSK的基础上扩展了多通道颜色的Color Names。HOG是梯度特征,而CN是颜色特征,两者可以互补,所以HOG+CN在近两年的跟踪算法中成为了hand-craft特征标配。最后,根据KCF/DCF的实验结果,讨论两个问题:
- 1. 为什么只用单通道灰度特征的KCF和用了多通道HOG特征的KCF速度差异很小?
第一,作者用了HOG的快速算法fHOG,来自Piotr's Computer Vision Matlab Toolbox,C代码而且做了SSE优化。如对fHOG有疑问,请参考论文Object Detection with Discriminatively Trained Part Based Models第12页。
第二,HOG特征常用cell size是4,这就意味着,100*100的图像,HOG特征图的维度只有25*25,而Raw pixels是灰度图归一化,维度依然是100*100,我们简单算一下:27通道HOG特征的复杂度是27*625*log(625)=47180,单通道灰度特征的复杂度是10000*log(10000)=40000,理论上也差不多,符合表格。
看代码会发现,作者在扩展后目标区域面积较大时,会先对提取到的图像块做因子2的下采样到50*50,这样复杂度就变成了2500*log(2500)=8495,下降了非常多。那你可能会想,如果下采样再多一点,复杂度就更低了,但这是以牺牲跟踪精度为代价的,再举个例子,如果图像块面积为200*200,先下采样到100*100,再提取HOG特征,分辨率降到了25*25,这就意味着响应图的分辨率也是25*25,也就是说,响应图每位移1个像素,原始图像中跟踪框要移动8个像素,这样就降低了跟踪精度。在精度要求不高时,完全可以稍微牺牲下精度提高帧率(但看起来真的不能再下采样了)。
- 2. HOG特征的KCF和DCF哪个更好?
大部分人都会认为KCF效果超过DCF,而且各属性的准确度都在DCF之上,然而,如果换个角度来看,以DCF为基准,再来看加了kernel-trick的KCF,mean precision仅提高了0.4%,而FPS下降了41%,这么看是不是挺惊讶的呢?除了图像块像素总数,KCF的复杂度还主要和kernel-trick相关。所以,下文中的CF方法如果没有kernel-trick,就简称基于DCF,如果加了kernel-trick,就简称基于KCF(剧透基本各占一半)。当然这里的CN也有kernel-trick,但请注意,这是Martin Danelljan大神第一次使用kernel-trick,也是最后一次。。。
这就会引发一个疑问,kernel-trick这么强大的东西,怎么才提高这么点?这里就不得不提到Winsty的另一篇大作:
- Wang N, Shi J, Yeung D Y, et al. Understanding and diagnosing visual tracking systems[C]// ICCV, 2015.
一句话总结,别看那些五花八门的机器学习方法,那都是虚的,目标跟踪算法中特征才是最重要的(就是因为这篇文章我粉了WIN叔哈哈),以上就是最经典的三个高速算法,CSK, KCF/DCF和CN,推荐。
第四部分:14年的尺度自适应
VOT与OTB一样最早都是2013年出现的,但VOT2013序列太少,第一名的PLT代码也找不到,没有参考价值就直接跳过了。直接到了VOT2014竞赛 VOT2014 Benchmark 。这一年有25个精挑细选的序列,38个算法,那时候深度学习的战火还没有烧到tracking,所以主角也只能是刚刚展露头角就独霸一方的CF,下面是前几名的详细情况:

前三名都是相关滤波CF类方法,第三名的KCF已经很熟悉了,这里稍微有点区别就是加了多尺度检测和子像素峰值估计,再加上VOT序列的分辨率比较高(检测更新图像块的分辨率比较高),导致竞赛中的KCF的速度只有24.23(EFO换算66.6FPS)。这里speed是EFO(Equivalent Filter Operations),在VOT2015和VOT2016里面也用这个参数衡量算法速度,这里一次性列出来供参考(MATLAB实现的tracker实际速度要更高一些):

其实前三名除了特征略有差异,核心都是KCF为基础扩展了多尺度检测,概要如下:
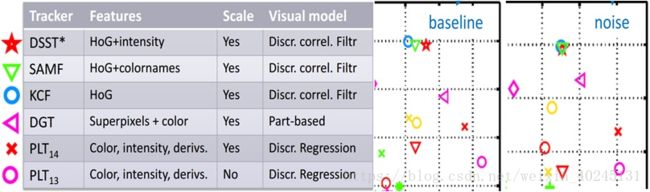
尺度变化是跟踪中比较基础和常见的问题,前面介绍的KCF/DCF和CN都没有尺度更新,如果目标缩小,滤波器就会学习到大量背景信息,如果目标扩大,滤波器就跟着目标局部纹理走了,这两种情况都很可能出现非预期的结果,导致漂移和失败。
SAMF ihpdep/samf,浙大Yang Li的工作,基于KCF,特征是HOG+CN,多尺度方法是平移滤波器在多尺度缩放的图像块上进行目标检测,取响应最大的那个平移位置及所在尺度:
- Li Y, Zhu J. A scale adaptive kernel correlation filter tracker with feature integration[C]// ECCV, 2014.
Martin Danelljan的DSST Accurate scale estimation for visual tracking,只用了HOG特征,DCF用于平移位置检测,又专门训练类似MOSSE的相关滤波器检测尺度变化,开创了平移滤波+尺度滤波,之后转TPAMI做了一系列加速的版本fDSST,非常+非常+非常推荐:
- Danelljan M, Häger G, Khan F, et al. Accurate scale estimation for robust visual tracking[C]// BMVC, 2014.
- Danelljan M, Hager G, Khan F S, et al. Discriminative Scale Space Tracking [J]. IEEE TPAMI, 2017.
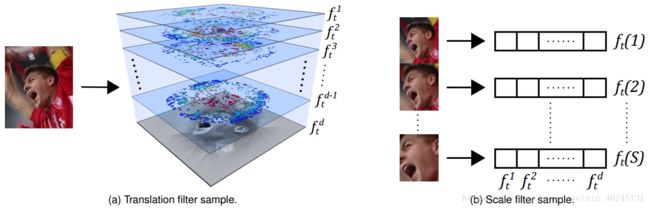
简单对比下这两种尺度自适应的方法:
- DSST和SAMF所采用的尺度检测方法哪个更好?
首先给大家讲个笑话:Martin Danelljan大神提出DSST之后,他的后续论文就再没有用过(直到最新CVPR的ECO-HC中为了加速用了fDSST)。
- 虽然SAMF和DSST都可以跟上普通的目标尺度变化,但SAMF只有7个尺度比较粗,而DSST有33个尺度比较精细准确;
- DSST先检测最佳平移再检测最佳尺度,是分步最优,而SAMF是平移尺度一起检测,是平移和尺度同时最优,而往往局部最优和全局最优是不一样的;
- DSST将跟踪划分为平移跟踪和尺度跟踪两个问题,可以采用不同的方法和特征,更加灵活,但需要额外训练一个滤波器,每帧尺度检测需要采样33个图像块,之后分别计算特征、加窗、FFT等,尺度滤波器比平移滤波器慢很多;SAMF只需要一个滤波器,不需要额外训练和存储,每个尺度检测就一次提特征和FFT,但在图像块较大时计算量比DSST高。
所以尺度检测DSST并不总是比SAMF好,其实在VOT2015和VOT2016上SAMF都是超过DSST的,当然这主要是因为特征更好,但至少说明尺度方法不差。总的来说,DSST做法非常新颖,速度更快,SAMF同样优秀也更加准确。
- DSST一定要33个尺度吗?
DSST标配33个尺度非常非常敏感,轻易降低尺度数量,即使你增加相应步长,尺度滤波器也会完全跟不上尺度变化。关于这一点可能解释是,训练尺度滤波器用的是一维样本,而且没有循环移位,这就意味着一次训练更新只有33个样本,如果降低样本数量,会造成训练不足,分类器判别力严重下降,不像平移滤波器有非常多的移位样本(个人看法欢迎交流)。总之,请不要轻易尝试大幅降低尺度数量,如果非要用尺度滤波器33和1.02就很好。
以上就是两种推荐的尺度检测方法,以后简称为类似DSST的多尺度和类似SAMF的多尺度。如果更看重速度,加速版的fDSST,和仅3个尺度的SAMF(如VOT2014中的KCF)就是比较好的选择;如果更看重精确,33个尺度的DSST,及7个尺度的SAMF就比较合适。
第五部分:边界效应
接下来到了VOT2015竞赛 VOT2015 Challenge | Home ,这一年有60个精挑细选的序列,62个tracker,最大看点是深度学习开始进击tracking领域,MDNet直接拿下当年的冠军,而结合深度特征的相关滤波方法DeepSRDCF是第二名,主要解决边界效应的SRDCF仅HOG特征排在第四:

随着VOT竞赛的影响力扩大,举办方也是用心良苦,经典的和顶尖的齐聚一堂,百家争鸣,多达62个tracker皇城PK,华山论剑。除了前面介绍的深度学习和相关滤波,还有结合object proposals(类物体区域检测)的EBT(EBT:Proposal与Tracking不得不说的秘密 - 知乎专栏)排第三,Mean-Shift类颜色算法ASMS是推荐实时算法,还有前面提到的另一个颜色算法DAT,而在第9的那个Struck已经不是原来的Struck了。除此之外,还能看到经典方法如OAB, STC, CMT, CT, NCC等都排在倒数位置, 经典方法已经被远远甩在后面。
在介绍SRDCF之前,先来分析下相关滤波有什么缺点。总体来说,相关滤波类方法对快速变形和快速运动情况的跟踪效果不好。
快速变形主要因为CF是模板类方法。容易跟丢这个比较好理解,前面分析了相关滤波是模板类方法,如果目标快速变形,那基于HOG的梯度模板肯定就跟不上了,如果快速变色,那基于CN的颜色模板肯定也就跟不上了。这个还和模型更新策略与更新速度有关,固定学习率的线性加权更新,如果学习率太大,部分或短暂遮挡和任何检测不准确,模型就会学习到背景信息,积累到一定程度模型跟着背景私奔了,一去不复返。如果学习率太小,目标已经变形了而模板还是那个模板,就会变得不认识目标。
快速运动主要是边界效应(Boundary Effets),而且边界效应产生的错误样本会造成分类器判别力不够强,下面分训练阶段和检测阶段分别讨论。
训练阶段,合成样本降低了判别能力。如果不加余弦窗,那么移位样本是长这样的:

除了那个最原始样本,其他样本都是“合成”的,100*100的图像块,只有1/10000的样本是真实的,这样的样本集根本不能拿来训练。如果加了余弦窗,由于图像边缘像素值都是0,循环移位过程中只要目标保持完整,就认为这个样本是合理的,只有当目标中心接近边缘时,目标跨越了边界的那些样本是错误的,这样虽不真实但合理的样本数量增加到了大约2/3(一维情况padding= 1)。但我们不能忘了即使这样仍然有1/3(3000/10000)的样本是不合理的,这些样本会降低分类器的判别能力。再者,加余弦窗也不是“免费的”,余弦窗将图像块的边缘区域像素全部变成0,大量过滤掉了分类器本来非常需要学习的背景信息,原本训练时判别器能看到的背景信息就非常有限,我们还加了个余弦窗挡住了背景,这样进一步降低了分类器的判别力(是不是上帝在我前遮住了帘。。不是上帝,是余弦窗)。
检测阶段,相关滤波对快速运动的目标检测比较乏力。相关滤波训练的图像块和检测的图像块大小必须是一样的,这就是说你训练了一个100*100的滤波器,那你也只能检测100*100的区域,如果打算通过加更大的padding来扩展检测区域,那样除了扩展了复杂度,并不会有什么好处。目标运动可能是目标自身移动,或摄像机移动,按照目标在检测区域的位置分四种情况来看:
- 如果目标在中心附近,检测准确且成功。
- 如果目标移动到了边界附近但还没有出边界,加了余弦窗以后,部分目标像素会被过滤掉,这时候就没法保证这里的响应是全局最大的,而且,这时候的检测样本和训练过程中的那些不合理样本很像,所以很可能会失败。
- 如果目标的一部分已经移出了这个区域,而我们还要加余弦窗,很可能就过滤掉了仅存的目标像素,检测失败。
- 如果整个目标已经位移出了这个区域,那肯定就检测失败了。
以上就是边界效应(Boundary Effets),推荐两个主流的解决边界效应的方法,其中SRDCF速度比较慢,并不适合实时场合。
Martin Danelljan的SRDCF Learning Spatially Regularized Correlation Filters for Visual Tracking,主要思路:既然边界效应发生在边界附近,那就忽略所有移位样本的边界部分像素,或者说限制让边界附近滤波器系数接近0:
- Danelljan M, Hager G, Shahbaz Khan F, et al. Learning spatially regularized correlation filters for visual tracking [C]// ICCV. 2015.
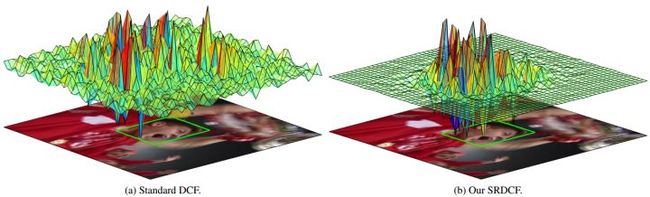
SRDCF基于DCF,类SAMF多尺度,采用更大的检测区域(padding = 4),同时加入空域正则化,惩罚边界区域的滤波器系数,由于没有闭合解,采用高斯-塞德尔方法迭代优化。检测区域扩大(1.5->4),迭代优化(破坏了闭合解)导致SRDCF只有5FP,但效果非常好是2015年的baseline。
另一种方法是Hamed Kiani提出的MOSSE改进算法,基于灰度特征的CFLM Correlation Filters with Limited Boundaries 和基于HOG特征的BACF Learning Background-Aware Correlation Filters for Visual Tracking,主要思路是采用较大尺寸检测图像块和较小尺寸滤波器来提高真实样本的比例,或者说滤波器填充0以保持和检测图像一样大,同样没有闭合解,采用ADMM迭代优化:
- Kiani Galoogahi H, Sim T, Lucey S. Correlation filters with limited boundaries [C]// CVPR, 2015.
- Kiani Galoogahi H, Fagg A, Lucey S. Learning Background-Aware Correlation Filters for Visual Tracking [C]// ICCV, 2017.
CFLB仅单通道灰度特征,虽然速度比较快167FPS,但性能远不如KCF,不推荐;最新BACF将特征扩展为多通道HOG特征,性能超过了SRDCF,而且速度比较快35FPS,非常推荐。
其实这两个解决方案挺像的,都是用更大的检测及更新图像块,训练作用域比较小的相关滤波器,不同点是SRDCF的滤波器系数从中心到边缘平滑过渡到0,而CFLM直接用0填充滤波器边缘。
VOT2015相关滤波方面还有排在第二名,结合深度特征的DeepSRDCF,因为深度特征都非常慢,在CPU上别说高速,实时都到不了,虽然性能非常高,但这里就不推荐,先跳过。
第六部分:颜色直方图与相关滤波
VOT2016竞赛 VOT2016 Challenge | Home,依然是VOT2015那60个序列,不过这次做了重新标注更加公平合理,今年有70位参赛选手,意料之中深度学习已经雄霸天下了,8个纯CNN方法和6个结合深度特征的CF方法大都名列前茅,还有一片的CF方法,最最最重要的是,良心举办方竟然公开了他们能拿到的38个tracker,部分tracker代码和主页,下载地址:VOT2016 Challenge | Trackers (以后妈妈再也不用担心我找不到源码了~),注意部分是下载链接,部分是源码压缩包,部分源码是二进制文件,好不好用一试便知,方便对比和研究,需要的赶快去试试。马上来看竞赛结果(这里仅列举前60个):
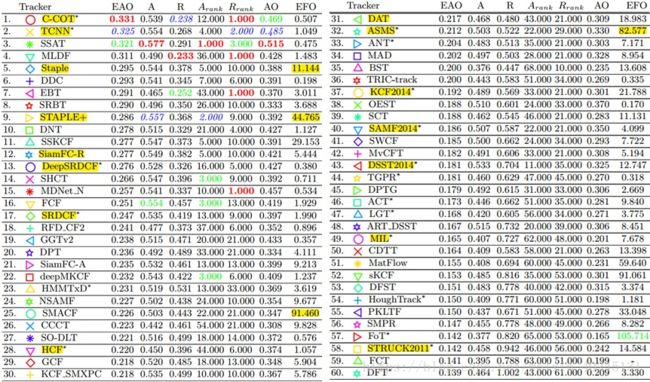
高亮标出来了前面介绍过的或比较重要的方法,结合多层深度特征的相关滤波C-COT排第一名,而CNN方法TCNN是VOT2016的冠军,作者也是VOT2015冠军MDNet,纯颜色方法DAT和ASMS都在中等水平(其实两种方法实测表现非常接近),其他tracker的情况请参考论文。再来看速度,SMACF没有公开代码,ASMS依然那么快,排在前10的方法中也有两个速度比较快,分别是排第5的Staple,和其改进算法排第9的STAPLE+,而且STAPLE+是今年的推荐实时算法。首先恭喜Luca Bertinetto的SiamFC和Staple都表现非常不错,然后再为大牛默哀三分钟(VOT2016的paper原文):
This was particularly obvious in case of SiamFC trackers, which runs orders higher than realtime (albeit on GPU), and Staple, which is realtime, but are incorrectly among the non-realtime trackers.
VOT2016竟然发生了乌龙事件,Staple在论文中CPU上是80FPS,怎么EFO在这里只有11?幸好公开代码有Staple和STAPLE+,实测下来,虽然我电脑不如Luca Bertinetto大牛但Staple我也能跑76FPS,而更可笑的是,STAPLE+比Staple慢了大约7-8倍,竟然EFO高出4倍,到底怎么回事呢?
首先看Staple的代码,如果您直接下载Staple并设置params.visualization = 1,Staple默认调用Computer Vision System Toolbox来显示序列图像,而恰好如果您没有这个工具箱,默认每帧都会用imshow(im)来显示图像,所以非常非常慢,而设置params.visualization = 0就跑的飞快(作者你是孙猴子派来的逗逼吗),建议您将显示图像部分代码替换成DSST中对应部分代码就可以正常速度运行和显示了。
再来看STAPLE+的代码,对Staple的改进包括额外从颜色概率图中提取HOG特征,特征增加到56通道(Staple是28通道),平移检测额外加入了大位移光流运动估计的响应,所以才会这么慢,而且肯定要慢很多。
所以很大可能是VOT举办方把Staple和STAPLE+的EFO弄反了,VOT2016的实时推荐算法应该是排第5的Staple,相关滤波结合颜色方法,没有深度特征更没有CNN,跑80FPS还能排在第五,这就是接下来主要介绍的,2016年最NIUBILITY的目标跟踪算法之一Staple (直接让排在后面的一众深度学习算法怀疑人生)。
颜色特征,在目标跟踪中颜色是个非常重要的特征,不管多少个人在一起,只要目标穿不用颜色的一幅就非常明显。前面介绍过2014年CVPR的CN是相关滤波框架下的模板颜色方法,这里隆重介绍统计颜色特征方法DAT Learning, Recognition, and Surveillance @ ICG ,帧率15FPS推荐:
- Possegger H, Mauthner T, Bischof H. In defense of color-based model-free tracking [C]// CVPR, 2015.
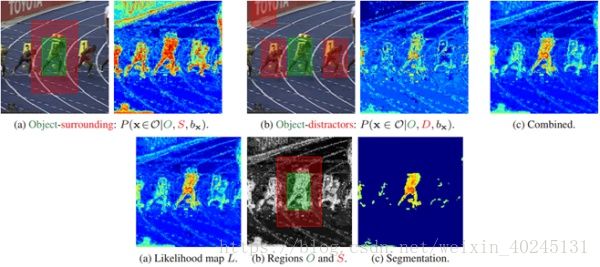
DAT统计前景目标和背景区域的颜色直方图并归一化,这就是前景和背景的颜色概率模型,检测阶段,贝叶斯方法判别每个像素属于前景的概率,得到像素级颜色概率图,再加上边缘相似颜色物体抑制就能得到目标的区域了。
如果要用一句话介绍Luca Bertinetto(牛津大学)的Staple Staple tracker,那就是把模板特征方法DSST(基于DCF)和统计特征方法DAT结合:
- Bertinetto L, Valmadre J, Golodetz S, et al. Staple: Complementary Learners for Real-Time Tracking [C]// CVPR, 2016.
前面分析了相关滤波模板类特征(HOG)对快速变形和快速运动效果不好,但对运动模糊光照变化等情况比较好;而颜色统计特征(颜色直方图)对变形不敏感,而且不属于相关滤波框架没有边界效应,快速运动当然也是没问题的,但对光照变化和背景相似颜色不好。综上,这两类方法可以互补,也就是说DSST和DAT可以互补结合:
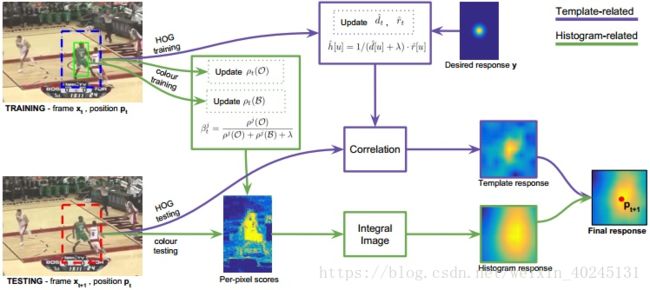
两个框架的算法高效无缝结合,25FPS的DSST和15FPS的DAT,而结合后速度竟然达到了80FPS。DSST框架把跟踪划分为两个问题,即平移检测和尺度检测,DAT就加在平移检测部分,相关滤波有一个响应图,像素级前景概率也有一个响应图,两个响应图线性加权得到最终响应图,其他部分与DSST类似,平移滤波器、尺度滤波器和颜色概率模型都以固定学习率线性加权更新。
另一种相关滤波结合颜色概率的方法是17CVPR的CSR-DCF,提出了空域可靠性和通道可靠性,没有深度特征性能直逼C-COT,速度可观13FPS:
- Lukežič A, Vojíř T, Čehovin L, et al. Discriminative Correlation Filter with Channel and Spatial Reliability [C]// CVPR, 2017.
CSR-DCF中的空域可靠性得到的二值掩膜就类似于CFLM中的掩膜矩阵P,在这里自适应选择更容易跟踪的目标区域且减小边界效应;以往多通道特征都是直接求和,而CSR-DCF中通道采用加权求和,而通道可靠性就是那个自适应加权系数。采用ADMM迭代优化,可以看出CSR-DCF是DAT和CFLB的结合算法。

VOT2015相关滤波还有排第一名的C-COT(别问我第一名为什么不是冠军,我也不知道),和DeepSRDCF一样先跳过。
第七部分:long-term和跟踪置信度
以前提到的很多CF算法,也包括VOT竞赛,都是针对short-term的跟踪问题,即短期(shor-term)跟踪,我们只关注短期内(如100~500帧)跟踪是否准确。但在实际应用场合,我们希望正确跟踪时间长一点,如几分钟或十几分钟,这就是长期(long-term)跟踪问题。
Long-term就是希望tracker能长期正确跟踪,我们分析了前面介绍的方法不适合这种应用场合,必须是short-term tracker + detecter配合才能实现正确的长期跟踪。
用一句话介绍Long-term,就是给普通tracker配一个detecter,在发现跟踪出错的时候调用自带detecter重新检测并矫正tracker。
介绍CF方向一篇比较有代表性的long-term方法,Chao Ma的LCT chaoma99/lct-tracker:
- Ma C, Yang X, Zhang C, et al. Long-term correlation tracking[C]// CVPR, 2015.
LCT在DSST一个平移相关滤波Rc和一个尺度相关滤波的基础上,又加入第三个负责检测目标置信度的相关滤波Rt,检测模块Online Detector是TLD中所用的随机蔟分类器(random fern),在代码中改为SVM。第三个置信度滤波类似MOSSE不加padding,而且特征也不加cosine窗,放在平移检测之后。

- 如果最大响应小于第一个阈值(叫运动阈值),说明平移检测不可靠,调用检测模块重新检测。注意,重新检测的结果并不是都采纳的,只有第二次检测的最大响应值比第一次检测大1.5倍时才接纳,否则,依然采用平移检测的结果。
- 如果最大响应大于第二个阈值(叫外观阈值),说明平移检测足够可信,这时候才以固定学习率在线更新第三个相关滤波器和随机蔟分类器。注意,前两个相关滤波的更新与DSST一样,固定学习率在线每帧更新。
LCT加入检测机制,对遮挡和出视野等情况理论上较好,速度27fps,实验只跑了OTB-2013,跟踪精度非常高,根据其他论文LCT在OTB-2015和 VOT上效果略差一点可能是两个核心阈值没有自适应, 关于long-term,TLD和LCT都可以参考 。
接下来介绍跟踪置信度。 跟踪算法需要能反映每一次跟踪结果的可靠程度,这一点非常重要,不然就可能造成跟丢了还不知道的情况。生成类(generative)方法有相似性度量函数,判别类(discriminative)方法有机器学习方法的分类概率。有两种指标可以反映相关滤波类方法的跟踪置信度:前面见过的最大响应值,和没见过的响应模式,或者综合反映这两点的指标。
LMCF(MM Wang的目标跟踪专栏:目标跟踪算法 - 知乎专栏 )提出了多峰检测和高置信度更新:
- Wang M, Liu Y, Huang Z. Large Margin Object Tracking with Circulant Feature Maps [C]// CVPR, 2017.
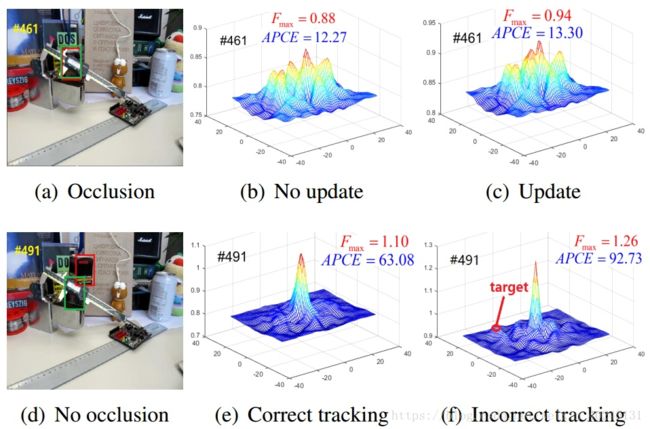
高置信度更新,只有在跟踪置信度比较高的时候才更新跟踪模型,避免目标模型被污染,同时提升速度。 第一个置信度指标是最大响应分数Fmax,就是最大响应值(Staple和LCT中都有提到)。 第二个置信度指标是平均峰值相关能量(average peak-to correlation energy, APCE),反应响应图的波动程度和检测目标的置信水平,这个(可能)是目前最好的指标,推荐:

跟踪置信度指标还有,MOSSE中的峰值旁瓣比(Peak to Sidelobe Ratio, PSR), 由相关滤波峰值,与11*11峰值窗口以外旁瓣的均值与标准差计算得到,推荐:

还有CSR-DCF的空域可靠性,也用了两个类似指标反映通道可靠性, 第一个指标也是每个通道的最大响应峰值,就是Fmax,第二个指标是响应图中第二和第一主模式之间的比率,反映每个通道响应中主模式的表现力,但需要先做极大值检测:

第八部分:卷积特征
最后这部分是Martin Danelljan的专场,主要介绍他的一些列工作,尤其是结合深度特征的相关滤波方法,代码都在他主页Visual Tracking,就不一一贴出了。
- Danelljan M, Shahbaz Khan F, Felsberg M, et al. Adaptive color attributes for real-time visual tracking [C]// CVPR, 2014.
在CN中提出了非常重要的多通道颜色特征Color Names,用于CSK框架取得非常好得效果,还提出了加速算法CN2,通过类PCA的自适应降维方法,对特征通道数量降维(10 -> 2),平滑项增加跨越不同特征子空间时的代价,也就是PCA中的协方差矩阵线性更新防止降维矩阵变化太大。
- Danelljan M, Hager G, Khan F S, et al. Discriminative Scale Space Tracking [J]. IEEE TPAMI, 2017.
DSST是VOT2014的第一名,开创了平移滤波+尺度滤波的方式。在fDSST中对DSST进行加速,PCA方法将平移滤波HOG特征的通道降维(31 -> 18),QR方法将尺度滤波器~1000*17的特征降维到17*17,最后用三角插值(频域插值)将尺度数量从17插值到33以获得更精确的尺度定位。
SRDCF是VOT2015的第四名,为了减轻边界效应扩大检测区域,优化目标增加了空间约束项,用高斯-塞德尔方法迭代优化,并用牛顿法迭代优化平移检测的子网格精确目标定位。
- Danelljan M, Hager G, Shahbaz Khan F, et al. Adaptive decontamination of the training set: A unified formulation for discriminative visual tracking [C]// CVPR, 2016.
SRDCFdecon在SRDCF的基础上,改进了样本和学习率问题。以前的相关滤波都是固定学习率线性加权更新模型,虽然这样比较简单不用保存以前样本,但在定位不准确、遮挡、背景扰动等情况会污染模型导致漂移。SRDCFdecon选择保存以往样本(图像块包括正,负样本),在优化目标函数中添加样本权重参数和正则项,采用交替凸搜索,首先固定样本权重,高斯-塞德尔方法迭代优化模型参数,然后固定模型参数,凸二次规划方法优化样本权重。
- Danelljan M, Hager G, Shahbaz Khan F, et al. Convolutional features for correlation filter based visual tracking [C]// ICCVW, 2015.
DeepSRDCF是VOT2015的第二名,将SRDCF中的HOG特征替换为CNN中单层卷积层的深度特征(也就是卷积网络的激活值),效果有了极大提升。这里用imagenet-vgg-2048 network,VGG网络的迁移能力比较强,而且MatConvNet就是VGG组的,MATLAB调用非常方便。论文还测试了不同卷积层在目标跟踪任务中的表现:

第1层表现最好,第2和第5次之。由于卷积层数越高语义信息越多,但纹理细节越少,从1到4层越来越差的原因之一就是特征图的分辨率越来越低,但第5层反而很高,是因为包括完整的语义信息,判别力比较强(本来就是用来做识别的)。

注意区分这里的深度特征和基于深度学习的方法,深度特征来自ImageNet上预训练的图像分类网络,没有fine-turn这一过程,不存在过拟合的问题。而基于深度学习的方法大多需要在跟踪序列上end-to-end训练或fine-turn,如果样本数量和多样性有限就很可能过拟合。
- Ma C, Huang J B, Yang X, et al. Hierarchical convolutional features for visual tracking[C]// ICCV, 2015.

值得一提的还有Chao Ma的HCF,结合多层卷积特征提升效果,用了VGG19的Conv5-4, Conv4-4和Conv3-4的激活值作为特征,所有特征都缩放到图像块分辨率,虽然按照论文应该是由粗到细确定目标,但代码中比较直接,三种卷积层的响应以固定权值1, 0.5, 0.02线性加权作为最终响应。虽然用了多层卷积特征,但没有关注边界效应而且线性加权的方式过于简单,HCF在VOT2016仅排在28名(单层卷积深度特征的DeepSRDCF是第13名)。
- Danelljan M, Robinson A, Khan F S, et al. Beyond correlation filters: Learning continuous convolution operators for visual tracking [C]// ECCV, 2016.

C-COT是VOT2016的第一名,综合了SRDCF的空域正则化和SRDCFdecon的自适应样本权重,还将DeepSRDCF的单层卷积的深度特征扩展为多成卷积的深度特征(VGG第1和5层),为了应对不同卷积层分辨率不同的问题,提出了连续空间域插值转换操作,在训练之前通过频域隐式插值将特征图插值到连续空域,方便集成多分辨率特征图,并且保持定位的高精度。目标函数通过共轭梯度下降方法迭代优化,比高斯-塞德尔方法要快,自适应样本权值直接采用先验权值,没有交替凸优化过程,检测中用牛顿法迭代优化目标位置。
注意以上SRDCF, SRDCFdecon,DeepSRDCF,C-COT都无法实时,这一系列工作虽然效果越来越好,但也越来越复杂,在相关滤波越来越慢失去速度优势的时候,Martin Danelljan在2017CVPR的ECO来了一脚急刹车,大神来告诉我们什么叫又好又快,不忘初心:
- Danelljan M, Bhat G, Khan F S, et al. ECO: Efficient Convolution Operators for Tracking[C]// CVPR, 2017.
ECO是C-COT的加速版,从模型大小、样本集大小和更新策略三个方便加速,速度比C-COT提升了20倍,加量还减价,EAO提升了13.3%,最最最厉害的是, hand-crafted features的ECO-HC有60FPS。。吹完了,来看看具体做法。
第一减少模型参数,定义了factorized convolution operator(分解卷积操作),效果类似PCA,用PCA初始化,然后仅在第一帧优化这个降维矩阵,以后帧都直接用,简单来说就是有监督降维,深度特征时模型参数减少了80%。
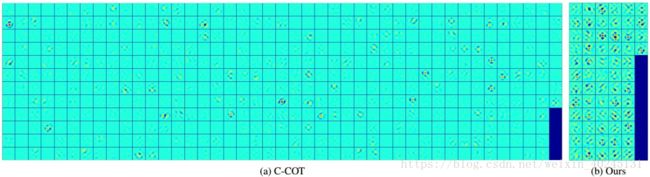
第二减少样本数量, compact generative model(紧凑的样本集生成模型),采用Gaussian Mixture Model (GMM)合并相似样本,建立更具代表性和多样性的样本集,需要保存和优化的样本集数量降到C-COT的1/8。
第三改变更新策略,sparser updating scheme(稀疏更新策略),每隔5帧做一次优化更新模型参数,不但提高了算法速度,而且提高了对突变,遮挡等情况的稳定性。但样本集是每帧都更新的,稀疏更新并不会错过间隔期的样本变化信息。
ECO的成功当然还有很多细节,而且有些我也看的不是很懂,总之很厉害就是了。。ECO实验跑了四个库(VOT2016, UAV123, OTB-2015, and TempleColor)都是第一,而且没有过拟合的问题,仅性能来说ECO是目前最好的相关滤波算法,也有可能是最好的目标跟踪算法。hand-crafted features版本的ECO-HC,降维部分原来HOG+CN的42维特征降到13维,其他部分类似,实验结果ECO-HC超过了大部分深度学习方法,而且论文给出速度是CPU上60FPS。
最后是来自Luca Bertinetto的CFNet End-to-end representation learning for Correlation Filter based tracking,除了上面介绍的相关滤波结合深度特征,相关滤波也可以end-to-end方式在CNN中训练了:
- Valmadre J, Bertinetto L, Henriques J F, et al. End-to-end representation learning for Correlation Filter based tracking [C]// CVPR, 2017.
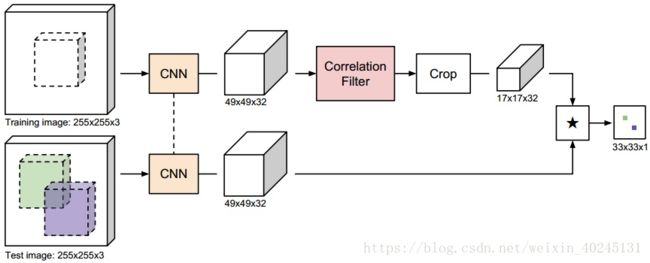
在SiamFC的基础上,将相关滤波也作为CNN中的一层,最重要的是cf层的前向传播和反向传播公式推导,两层卷积层的CFNet在GPU上是75FPS,综合表现并没有很多惊艳,可能是难以处理CF层的边界效应吧,持观望态度。
第九部分:2017年CVPR和ICCV结果
下面是CVPR 2017的目标跟踪算法结果:可能MD大神想说,一个能打的都没有!

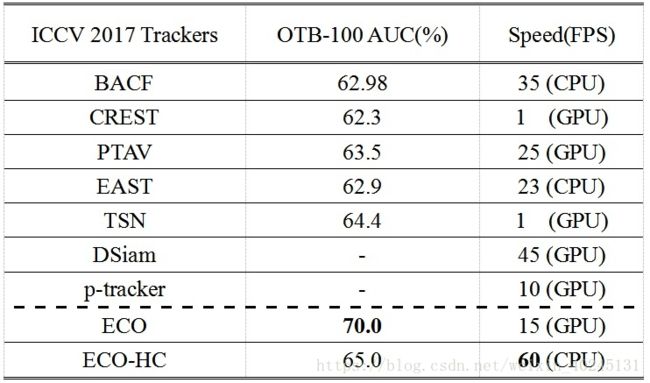
仿照上面的表格,整理了ICCV 2017的相关论文结果对比ECO:哎,还是一个能打的都没有!
第十部分:大牛推荐
凑个数,目前相关滤波方向贡献最多的是以下两个组(有创新有代码):
牛津大学:Joao F. Henriques和Luca Bertinetto,代表:CSK, KCF/DCF, Staple, CFNet (其他SiamFC, Learnet).
林雪平大学:Martin Danelljan,代表:CN, DSST, SRDCF, DeepSRDCF, SRDCFdecon, C-COT, ECO.
国内也有很多高校的优秀工作就不一一列举了。
___________________________________________________________________________
我的目标跟踪专栏:目标跟踪之相关滤波CF,长期更新,专注跟踪,但也会介绍计算机视觉和深度学习的各方面内容,拓展思路