一分钟一个Pandas小技巧(四)
暂更至此,有人看再更。
纸上得来终觉浅,绝知此事要躬行,所谓的熟练使用Pandas是建立在您大致了解每个函数功能上,希望本系列能给您带来些许收获。
本篇涉及的知识点:
- 一维表和二维表互换
- stack()和unstack()
- pivot()和pivot_table()
- 高性能查询和赋值
- query()
- eval()
- 快速计算同比环比、差异
- diff()
- pct_change()
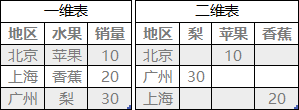
一维表和二维表互换
- 一维表是指表中各维相互独立,且不可再分的表
- 二维表是指表中部分列不独立,或者说可以归为一类的表
stack()和unstack()
从单词上看这是堆积、出栈的意思。那我们只要把行索引想象成栈那就很容易理解这两个函数了。
- stack是进栈,把列索引堆到行索引里面,那就形成了MultiIndex
- unstack是出栈,把行索引挤出到列索引去,那样就把MultiIndex变成了普通的Index
但是当原DataFrame没有MultiIndex时,unstack之后就会把列弹回到原Index前面形成MultiIndex。
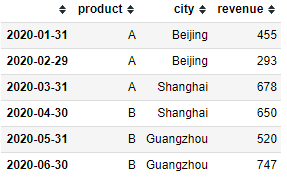
# 首先创建一个非MultiIndex的一维表
df=pd.DataFrame()
df['product']=['A','B']*3
df['city']=['Beijing','Shanghai','Guangzhou']*2
df['revenue']=np.random.randint(100,1000,6)
df.index = pd.date_range(start='2020/1/31',end='2020/6/30',freq='m',closed=None)
df

我们将列索引堆到行索引后面形成MultiIndex。
DataFrame.stack(level=- 1, dropna=True)
df.stack().to_frame()

使用unstack后的效果是这样的。
DataFrame.unstack(level=- 1, fill_value=None)
df.unstack().to_frame()

如之前所说,普通Index的DataFrame使用unstack后会把列索引堆到原本的行索引之前形成MultiIndex。
这上面两种情况看起来并不是我们所需要的结果,那我们看看stack和unstack在MultiIndex上的表现是如何的。
# 创建一个MultiIndex的DataFrame
val = np.random.randint(100, 1000, 7)
mul_index = pd.MultiIndex.from_tuples([(1, 'A'), (1, 'B'), (1, 'C'), (2, 'A'),
(2, 'B'), (3, "B"), (3, "C")])
df2 = pd.DataFrame(val, index=mul_index, columns=['revenue'])
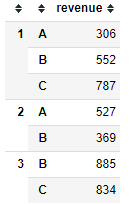
看一下MultiIndex使用stack后是什么效果。
df2.stack().to_frame()
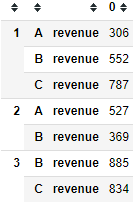
和普通的Index一样,将原本的列索引堆到行索引后面。再看一下MultiIndex使用unstack的效果。
df2.unstack()

unstack默认的level是-1,即最后一列,这里我们的行索引有两列,我们使用level=0看一下效果。
df_temp = df2.unstack(level=0,fill_value=0)
df_temp.columns = df_temp.columns.droplevel(level=0)
df_temp

相信聪明的你已经理解了这两个函数的意思。
仔细看unstack后列索引其实变成了MultiIndex,如果你只想保留一行列索引,可以像上面代码中一样使用drop_level()来删除。
pivot()和pivot_table()
或许上面两个函数还是有点迷糊,那下面的pivot和pivot_table函数一定是你熟悉的了。
df3=pd.DataFrame()
df3['product']=[x for x in ['A','B'] for i in range(0,3)]
df3['city']=['Beijing','Shanghai','Guangzhou']*2
df3['revenue']=np.random.randint(100,1000,6)
df3.index = pd.date_range(start='2020/1/31',end='2020/6/30',freq='m',closed=None)
我想看一下各城市各产品的销量,使用pivot的效果是这样的。
DataFrame.pivot(index=None, columns=None, values=None)
df3.pivot(index = 'city',columns='product',values='revenue')
![]()
啊对,没错,就是报错了。因为当作为索引的两列出现重复值时会报错。比如上面的第一二行同时出现了’A’,‘Beijing’。所以pivot()我就这么一提,我们更常用的是这个。
DataFrame.pivot_table(values=None, index=None, columns=None, aggfunc='mean', fill_value=None, margins=False, dropna=True, margins_name='All', observed=False)
来看看个城市的累计销量、最大值和平均值。
df3.pivot_table(index = 'city',values='revenue',aggfunc=['sum','mean','max'])
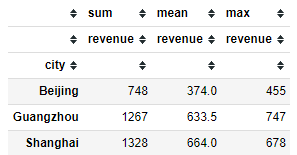
pivot_table()支持聚合函数,所以这两个函数我们只要使用pivot_table()就好了,有人可能问Excel直接拖动不是更快吗?

总结
上面四个函数我个人的话unstack()和pivot_table()用的更多,因为经常groupby好几个维度,形成了MultiIndex就要使用unstack()来转为二维表来展示。
而一般数据存储方式都是以一维表为主,所以stack()就用的较少了。
高性能查询和赋值
query()
query()用来查询过滤,可以赋值。
DataFrame.query(expr, inplace=False, **kwarg)
同样如上我们随机创建一个DataFrame。
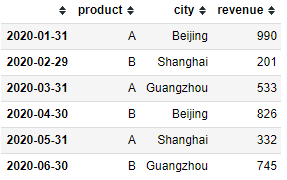
现在我要查询上海地区A产品的销售情况。
# 方法一
df[(df['product']=='A')&(df['city']=='Shanghai')]
# 方法二
product = 'A'
city='Shanghai'
df.query('product == @product and city == @city')

上面两种方式出来的结果是一样的,都是我们需要的。我们对这两种方式进行性能的检查。

之前创建的DataFrame只有6行,现在我们将数据行扩大到6万行再进行测试。
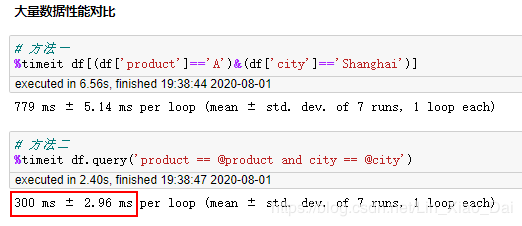
很明显到了万行的数据量时,query比复杂索引要快的多。
eval()
现在我们需要对数据进行运算赋值,我们再试试看普通的方式和eval有什么区别。
DataFrame.eval(expr, inplace=False, **kwargs)
同样先随机创建一个DataFrame。
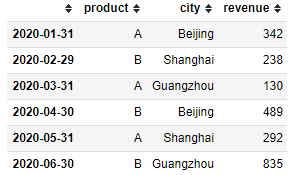
现在我想要将revenue标准化。
# 普通的赋值方式
df['z-score'] = (df['revenue'] -
df['revenue'].mean()) / df['revenue'].std(ddof=0)
# 使用eval
df['z-socre_eval'] = df.eval('(revenue-revenue.mean())/revenue.std(ddof=0)')
# eval可以直接赋值或修改已有的列,注意写法,要加上inplace=True
df.eval('new=(revenue-revenue.mean())/revenue.std(ddof=0)', inplace=True)
# 使用sklearn
from sklearn.preprocessing import scale
df['scale'] = scale(df['revenue'])
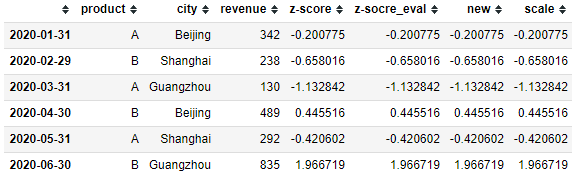
上面几种效果是一样的,我们来对比一下性能。
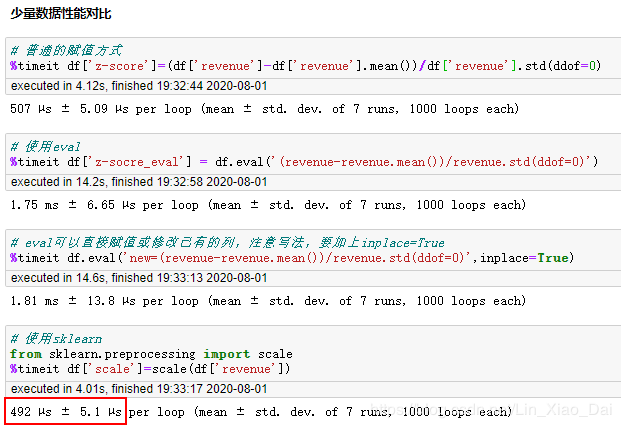
在数据只有6行的情况下,调用sklearn包进行数据标准化最快。接下来将数据扩展到6万行我们在看一下对比。
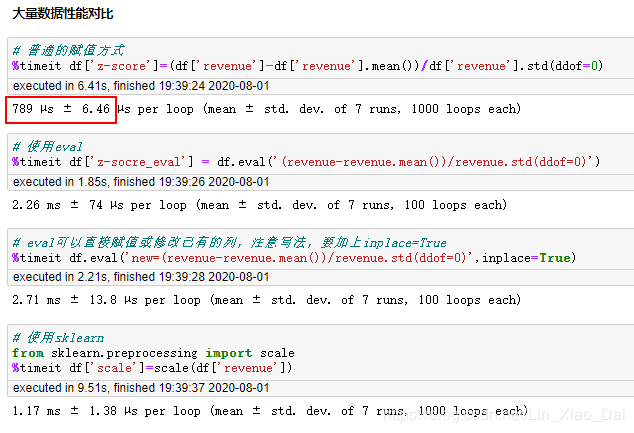

好像eval还比普通的赋值方式慢一些?
总结
数据量小的时候复杂索引和query()都可以,超过万行了更推荐使用query()。至于eval嘛…我还是选择普通的赋值方式吧。
月同比环比、差异
pct_change(),diff()
DataFrame.pct_change(periods=1, fill_method='pad', limit=None, freq=None, **kwargs)
DataFrame.diff(periods=1, axis=0)
pct_change()是计算百分比差异,diff()是计算差异,两者都可以作用于DataFrameGroupBy。
year = [2019,2020]
month = range(1,13)
from itertools import product
df = pd.DataFrame()
df['product'] = ['A']*24
df['revenue'] = np.random.randint(100, 1000, 24)
df.index = pd.to_datetime([f"{i[0]}/{i[1]}" for i in product(year, month)])
df['较上月差异'] = df.revenue.diff()
df['月环比'] = df.revenue.pct_change()
df['月同比'] = df.revenue.pct_change(12)

往期回顾
一分钟一个Pandas小技巧(一)
一分钟一个Pandas小技巧(二)
一分钟一个Pandas小技巧(三)
点个关注不吃亏
微信关注"林胖学Python"后台回复"pandas4"即可获取本文源码。