One PUNCH Man——决策树和随机森林
文章目录
- 从LR到决策树
- 决策树介绍
- “树”的成长过程
- 这颗“树”长到什么时候停
- “树”怎么长
- ID3算法
- C4.5算法
- CART算法
- 随机森林
- Bagging思想
- 随机森林
从LR到决策树
之前的文章,我们介绍了LR逻辑回归。总结一下LR模型的优缺点:
优点
- 适合需要得到一个分类概率的场景。
- 实现效率较高。
- 很好处理线性特征。
缺点
- 当特征空间很大时,逻辑回归的性能不是很好。
- 不能很好地处理大量多类特征。
- 对于非线性特征,需要进行转换。
决策树的出现就是为了解决LR模型不足的地方。
决策树的优点
- 模拟人的直观决策规则。
- 可以处理非线性特征。
- 考虑了特征之间的相互作用。
我们可以思考一下一个决策问题:是否去相亲,一个女孩的母亲要给这个女孩介绍对象。

LR模型是一股脑儿的把所有特征塞入学习,而决策树更像是编程语言中的if-else一样,去做条件判断,这就是根本性的区别。
决策树介绍
“树”的成长过程
决策树基于“树”结构进行决策的,这时我们就要面临两个问题 :
- “树”怎么长。
- 这颗“树”长到什么时候停。
弄懂了这两个问题,那么这个模型就已经建立起来了,决策树的总体流程是“分而治之”的思想,一是自根至叶的递归过程,一是在每个中间节点寻找一个“划分”属性,相当于就是一个特征属性了。接下来我们来逐个解决以上两个问题。
这颗“树”长到什么时候停
- 当前结点包含的样本全属于同一类别,无需划分。例如:样本当中都是决定去相亲的,属于同一类别,就是不管特征如何改变都不会影响结果,这种就不需要划分了。
- 当前属性集为空,或是所有样本在所有属性上取值相同,无法划分;例如:所有的样本特征都是一样的,就造成无法划分了,训练集太单一。
- 当前结点包含的样本集合为空,不能划分。
“树”怎么长
在生活当中,我们都会碰到很多需要做出决策的地方,例如:吃饭地点、数码产品购买、旅游地区等,你会发现在这些选择当中都是依赖于大部分人做出的选择,也就是跟随大众的选择。其实在决策树当中也是一样的,当大部分的样本都是同一类的时候,那么就已经做出了决策。
我们可以把大众的选择抽象化,这就引入了一个概念就是纯度,想想也是如此,大众选择就意味着纯度越高。好,在深入一点,就涉及到一句话:信息熵越低,纯度越高。介绍一下熵的概念,这是一个物理学概念,表示“一个系统的混乱程度”。系统的不确定性越高,熵就越大。
计算一个系统的信息熵的公式如下所示:
E n t ( D ) = − ∑ k = 1 ∣ y ∣ p k l o g 2 p k Ent(D)=-\sum_{k=1}^{|y|} p_k log_2{p_k} Ent(D)=−∑k=1∣y∣pklog2pk
其中, P k P_k Pk表示当前样本集合D中,第k类样本所占比例的百分比。
举一个的例子:对游戏活跃用户进行分层,分为高活跃、中活跃、低活跃,游戏A按照这个方式划分,用户比例分别为20%,30%,50%。游戏B按照这种方式划分,用户比例分别为5%,5%,90%。
那么游戏A对于这种划分方式的熵为:
![]()
同理游戏B对于这种划分方式的熵为:
![]()
所以,游戏A的不确定性比游戏B高。用简单通俗的话来讲,游戏B要不就在上升期,要不就在衰退期,它的未来已经很确定了,所以熵低。而游戏A的未来有更多的不确定性,它的熵更高。
介绍完熵的概念,我们继续看信息增益。为了便于理解,我们还是以一个实际的例子来说明信息增益的概念。信息增益公式:
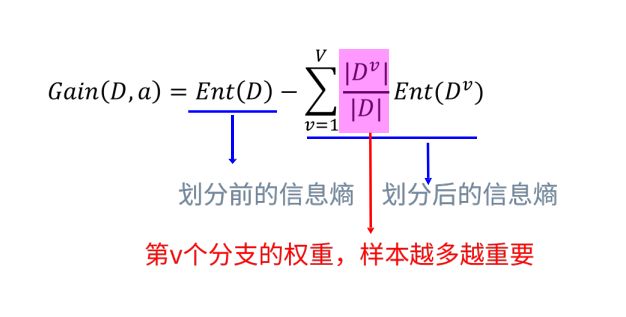
举个栗子,假设有下表样本:

第一列是id号,第二列为性别,第三列为活跃度,最后一列用户是否流失。我们要解决一个问题:性别和活跃度两个特征,哪个对用户流失影响更大?我们通过计算信息熵可以解决这个问题。
按照分组统计,我们可以得到如下信息:

其中Positive为正样本(已流失),Negative为负样本(未流失),下面的数值为不同划分下对应的人数。那么可得到三个熵:
整体熵:
![]()
性别熵:
![]()
![]()
性别信息增益:
![]()
同理计算活跃度熵:
![]()
活跃度信息增益:
![]()
活跃度的信息增益比性别的信息增益大,也就是说,活跃度对用户流失的影响比性别大。在做特征选择或者数据分析的时候,我们应该重点考察活跃度这个指标。
ID3算法
解释:在根节点处计算信息熵,然后根据属性依次划分并计算其节点的信息熵,用根节点信息熵–属性节点的信息熵=信息增益,根据信息增益进行降序排列,排在前面的就是第一个划分属性,其后依次类推,这就得到了决策树的形状,也就是怎么“长”了。
也就是上述的性别与活跃度对用户流失的判断里,活跃度的信息增益更大,所以我们选择活跃度来作为第一个划分属性,然后才是性别。
不过,信息增益有一个问题:对可取值数目(特征)较多的属性有所偏好,例如:考虑将“编号”作为一个属性,“编号”不是二元的,它的特征更多。这就引出了另一个 算法C4.5。
C4.5算法
为了解决信息增益的问题,引入一个信息增益率:

属性a的可能取值数目越多(即V越大),则IV(a)的值通常就越大。信息增益比本质: 是在信息增益的基础之上乘上一个惩罚参数。特征个数较多时,惩罚参数较小;特征个数较少时,惩罚参数较大。不过有一个缺点:
缺点:信息增益比偏向取值较少的特征。
使用信息增益比:基于以上缺点,并不是直接选择信息增益率最大的特征,而是现在候选特征中找出信息增益高于平均水平的特征,然后在这些特征中再选择信息增益率最高的特征。
CART算法
另外一个表示纯度的方法,叫做基尼指数(讨厌的公式):

表示在样本集合中一个随机选中的样本被分错的概率。举例来说,现在一个袋子里有3种颜色的球若干个,伸手进去掏出2个球,颜色不一样的概率,这下明白了吧。Gini(D)越小,数据集D的纯度越高。
举个例子
假设现在有特征 “学历”,此特征有三个特征取值: “本科”,“硕士”, “博士”,
当使用“学历”这个特征对样本集合D进行划分时,划分值分别有三个,因而有三种划分的可能集合,划分后的子集如下:
- 划分点: “本科”,划分后的子集合 : {本科},{硕士,博士}
- 划分点: “硕士”,划分后的子集合 : {硕士},{本科,博士}
- 划分点: “硕士”,划分后的子集合 : {博士},{本科,硕士}
对于上述的每一种划分,都可以计算出基于 划分特征= 某个特征值 将样本集合D划分为两个子集的纯度:
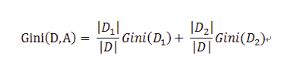
因而对于一个具有多个取值(超过2个)的特征,需要计算以每一个取值作为划分点,对样本D划分之后子集的纯度Gini(D,Ai),(其中Ai 表示特征A的可能取值)
然后从所有的可能划分的Gini(D,Ai)中找出Gini指数最小的划分,这个划分的划分点,便是使用特征A对样本集合D进行划分的最佳划分点。到此就可以长成一棵“大树”了。
随机森林
Bagging思想
Bagging是bootstrap aggregating。思想就是从总体样本当中随机取一部分样本进行训练,通过多次这样的结果,进行投票获取平均值作为结果输出,这就极大可能的避免了不好的样本数据,从而提高准确度。因为有些是不好的样本,相当于噪声,模型学入噪声后会使准确度不高。
举个例子:
假设有1000个样本,如果按照以前的思维,是直接把这1000个样本拿来训练,但现在不一样,先抽取800个样本来进行训练,假如噪声点是这800个样本以外的样本点,就很有效的避开了。重复以上操作,提高模型输出的平均值。
随机森林
RandomForest(随机森林)是一种基于树模型的Bagging的优化版本,一棵树的生成肯定还是不如多棵树,因此就有了随机森林,解决决策树泛化能力弱的特点。
而同一批数据,用同样的算法只能产生一棵树,这时Bagging策略可以帮助我们产生不同的数据集。Bagging策略来源于bootstrap aggregation:从样本集(假设样本集N个数据点)中重采样选出Nb个样本(有放回的采样,样本数据点个数仍然不变为N),在所有样本上,对这n个样本建立分类器(ID3\C4.5\CART\SVM\LOGISTIC),重复以上两步m次,获得m个分类器,最后根据这m个分类器的投票结果,决定数据属于哪一类。
总的来说就是随机选择样本数,随机选取特征,随机选择分类器,建立多颗这样的决策树,然后通过这几课决策树来投票,决定数据属于哪一类(投票机制有一票否决制、少数服从多数、加权多数)
优点:
- 在当前的很多数据集上,相对其他算法有着很大的优势,表现良好。
- 它能够处理很高维度(feature很多)的数据,并且不用做特征选择(因为特征子集是随机选择的)。
- 在训练完后,它能够给出哪些feature比较重要。
- 训练速度快,容易做成并行化方法(训练时树与树之间是相互独立的)。
- 在训练过程中,能够检测到feature间的互相影响。
- 对于不平衡的数据集来说,它可以平衡误差。
- 如果有很大一部分的特征遗失,仍可以维持准确度。
缺点:
- 随机森林已经被证明在某些噪音较大的分类或回归问题上会过拟合。
- 对于有不同取值的属性的数据,取值划分较多的属性会对随机森林产生更大的影响,所以随机森林在这种数据上产出的属性权值是不可信的。