Tensorflow实现AlexNet
0、CNN结构演化历史的图
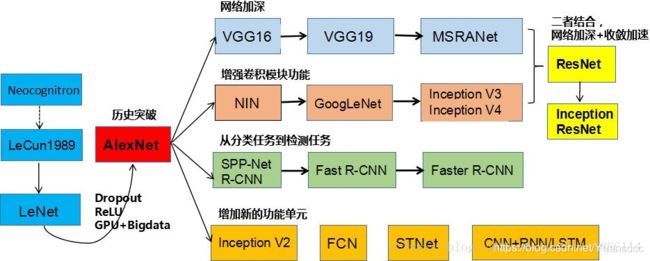
一、AlexNet
1、 模型介绍
AlexNet是由Alex KrizhevskyAlex Krizhevsky 提出的首个应用于图像分类的深层卷积神经网络,该网络在2012年ILSVRC(ImageNet Large Scale Visual Recognition Competition)图像分类竞赛中以15.3%的top-5测试错误率赢得第一名^{[2]}[2]。AlexNet使用GPU代替CPU进行运算,使得在可接受的时间范围内模型结构能够更加复杂,它的出现证明了深层卷积神经网络在复杂模型下的有效性,使CNN在计算机视觉中流行开来,直接或间接地引发了深度学习的热潮。
2、 模型结构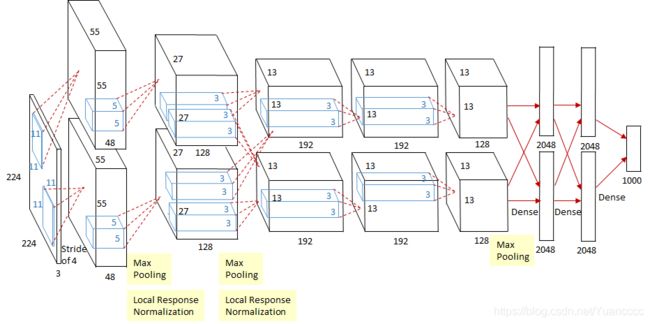
图4.3 AlexNet网络结构图
如图4.3所示,除去下采样(池化层)和局部响应规范化操作(Local Responsible Normalization, LRN),AlexNet一共包含8层,前5层由卷积层组成,而剩下的3层为全连接层。网络结构分为上下两层,分别对应两个GPU的操作过程,除了中间某些层(C_3C3卷积层和F_{6-8}F6−8全连接层会有GPU间的交互),其他层两个GPU分别计算结 果。最后一层全连接层的输出作为softmaxsoftmax的输入,得到1000个图像分类标签对应的概率值。除去GPU并行结构的设计,AlexNet网络结构与LeNet十分相似,其网络的参数配置如表4.2所示。
3、 模型特性
【1】所有卷积层都使用ReLU作为非线性映射函数,使模型收敛速度更快
【2】在多个GPU上进行模型的训练,不但可以提高模型的训练速度,还能提升数据的使用规模
【3】使用LRN对局部的特征进行归一化,结果作为ReLU激活函数的输入能有效降低错误率
【4】重叠最大池化(overlapping max pooling),即池化范围z与步长s存在关系z>sz>s(如S_{max}Smax中核尺度为3\times3/23×3/2),避免平均池化(average pooling)的平均效应
【5】使用随机丢弃技术(dropout)选择性地忽略训练中的单个神经元,避免模型的过拟合
4、论文原文翻译及代码
(1)AlexNet论文(ImageNet Classification with Deep Convolutional Neural Networks)(译)
(2)对论文的理解
深度学习AlexNet模型详细分析
(3)代码:https://blog.csdn.net/qq_28123095/article/details/79776329
或 https://blog.csdn.net/jyy555555/article/details/80498275
或 https://blog.csdn.net/taoyanqi8932/article/details/71081390
二、Tensorflow实现AlexNet
1、设计AlexNet网络结构
from datetime import datetime
import math
import time
import tensorflow as tf
#总共测试100个batch的数据
batch_size=32
num_batches=100
#print_actications:显示网络每层结构的函数
def print_activations(t):
print(t.op.name,'',t.get_shape().as_list())
#t.op.name:显示其名称;t.get_shape.as_list():tensor尺寸
#1.1、定义Alexnet的卷积层
def inference(images):
parameters=[]
#conv1,input=[batch,224,224,3],output=[batch,56,56,64],k=[11,11,3,64],s=[1,4,4,1]
#pool1,input=[batch,56,56,64],output=[batch,27,27,64],k=[1,3,3,1],s=[1,2,2,1]
with tf.name_scope('conv1') as scope:#自动将scope中生成的Variable自动命名为conv1/xxx
kernel=tf.Variable(tf.truncated_normal([11,11,3,64],dtype=tf.float32,stddev=1e-1),name='weigths')
#tf.truncated_normal:截断的正太分布函数(标准差为0.1)
conv=tf.nn.conv2d(images,kernel,[1,4,4,1],padding='SAME')
biases=tf.Variable(tf.constant(0.0,shape=[64],dtype=tf.float32),trainable=True,name='biases')
bias=tf.nn.bias_add(conv,biases)
conv1=tf.nn.relu(bias,name=scope)
print_activations(conv1)
parameters+=[kernel,biases]
#使用tf.nn.lrn对前面输出的tensor conv1进行LRN处理
lrn1=tf.nn.lrn(conv1,4,bias=1.0,alpha=0.001/9,beta=0.75,name='lrn1')
pool1=tf.nn.max_pool(lrn1,ksize=[1,3,3,1],strides=[1,2,2,1],padding='VALID',name='pool1')
print_activations(pool1)
#conv2,input=[batch,27,27,64],output=[batch,27,27,192],k=[5,5,64,192],s=[1,1,1,1]
#pool2,input=[batch,27,27,192],output=[batch,13,13,192],k=[1,3,3,1],s=[1,2,2,1]
with tf.name_scope('conv2') as scope:
kernel=tf.Variable(tf.truncated_normal([5,5,64,192],dtype=tf.float32,stddev=1e-1),name='weigths')
conv=tf.nn.conv2d(pool1,kernel,[1,1,1,1],padding='SAME')
biases=tf.Variable(tf.constant(0.0,shape=[192],dtype=tf.float32),trainable=True,name='biases')
bias=tf.nn.bias_add(conv,biases)
conv2=tf.nn.relu(bias,name=scope)
print_activations(conv2)
parameters+=[kernel,biases]
lrn2=tf.nn.lrn(conv2,4,bias=1.0,alpha=0.001/9,beta=0.75,name='lrn2')
pool2=tf.nn.max_pool(lrn2,ksize=[1,3,3,1],strides=[1,2,2,1],padding='VALID',name='pool2')
print_activations(pool2)
#conv3,input=[batch,13,13,192],output=[batch,13,13,384],k=[3,3,192,384],s=[1,1,1,1]
with tf.name_scope('conv3') as scope:
kernel=tf.Variable(tf.truncated_normal([3,3,192,384],dtype=tf.float32,stddev=1e-1),name='weigths')
conv=tf.nn.conv2d(pool2,kernel,[1,1,1,1],padding='SAME')
biases=tf.Variable(tf.constant(0.0,shape=[384],dtype=tf.float32),trainable=True,name='biases')
bias=tf.nn.bias_add(conv,biases)
conv3=tf.nn.relu(bias,name=scope)
print_activations(conv3)
parameters+=[kernel,biases]
#conv4,input=[batch,13,13,384],output=[batch,13,13,256],k=[3,3,384,256],s=[1,1,1,1]
with tf.name_scope('conv4') as scope:
kernel=tf.Variable(tf.truncated_normal([3,3,384,256],dtype=tf.float32,stddev=1e-1),name='weigths')
conv=tf.nn.conv2d(conv3,kernel,[1,1,1,1],padding='SAME')
biases=tf.Variable(tf.constant(0.0,shape=[256],dtype=tf.float32),trainable=True,name='biases')
bias=tf.nn.bias_add(conv,biases)
conv4=tf.nn.relu(bias,name=scope)
print_activations(conv4)
parameters+=[kernel,biases]
#conv5,input=[batch,13,13,256],output=[batch,13,13,256],k=[3,3,256,256],s=[1,1,1,1]
#pool2,input=[batch,13,13,256],output=[batch,6,6,256],k=[1,3,3,1],s=[1,2,2,1]
with tf.name_scope('conv5') as scope:
kernel=tf.Variable(tf.truncated_normal([3,3,256,256],dtype=tf.float32,stddev=1e-1),name='weigths')
conv=tf.nn.conv2d(conv4,kernel,[1,1,1,1],padding='SAME')
biases=tf.Variable(tf.constant(0.0,shape=[256],dtype=tf.float32),trainable=True,name='biases')
bias=tf.nn.bias_add(conv,biases)
conv5=tf.nn.relu(bias,name=scope)
print_activations(conv5)
parameters+=[kernel,biases]
pool5=tf.nn.max_pool(conv5,ksize=[1,3,3,1],strides=[1,2,2,1],padding='VALID',name='pool5')
print_activations(pool5)
return pool5,parameters
#1.2、定义AlexNet的全连接层
def full_connection(pool5):
fc_1=flatten(pool5) #(batch,9216)
dim=fc_1.shape[1].value #9216
with tf.name_scope('full_connection_1'):
fc1_w = tf.Variable(tf.truncated_normal(shape=[dim, 4096], dtype=tf.float32, mean=0,
stddev=0.1), name='weights')
fc1_b = tf.Variable(tf.constant(value=0.0, dtype=tf.float32, shape=[4096]), name='biases')
fc1 = tf.matmul(fc_1, fc1_w) + fc1_b
with tf.name_scope('full_connection_2'):
fc2_w = tf.Variable(tf.truncated_normal(shape=[4096, 4096], dtype=tf.float32, mean=0,
stddev=0.1), name='weights')
fc2_b = tf.Variable(tf.constant(value=0.0, dtype=tf.float32, shape=[4096]), name='biases')
fc2 = tf.matmul(fc1, fc2_w) + fc2_b
with tf.name_scope('full_connection_3'):
fc3_w = tf.Variable(tf.truncated_normal(shape=[4096, 1000], dtype=tf.float32, mean=0,
stddev=0.1), name='weights')
fc3_b = tf.Variable(tf.constant(value=0.0, dtype=tf.float32, shape=[1000]), name='biases')
logits = tf.matmul(fc2, fc3_w) + fc3_b
return logits
2、定义函数time_tensorflow_run :评估AlexNet每轮计算时间
def time_tensorflow_run(session,target,info_string):
'''
参数:
session:输入是TensorFlow的Session
target:需要评估的运算算子
info_string:测试的名称
'''
num_steps_burn_in=10 #定义预热轮数,作用是给程序预热,只考虑10轮迭代之后的计算
total_duration=0 #记录总时间
total_duration_squared=0.0 #平方和
for i in range(num_batches+num_steps_burn_in):
start_time=time.time() #time.time():记录时间
_=session.run(target)
duration=time.time()-start_time
if i>=num_steps_burn_in:
if not i % 10:
print('%s:step %d,duration=%.3f'%(datetime.now(),i-num_steps_burn_in,duration))
total_duration+=duration
total_duration_squared+=duration*duration
mn=total_duration/num_batches #平均耗时
vr=total_duration_squared/num_batches-mn*mn
sd=math.sqrt(vr) #标准差
print('%s:%s across %d steps,%.3f +/- %.3f sec / batch'%(datetime.now(),info_string,num_batches,mn,sd))3、定义主函数run_benchmake
我们不需要ImageNets数据集来训练,只使用随机图片数据来测试前馈和反馈计算的耗时
def run_benchmake():
with tf.Graph().as_default():
image_size=224
image = tf.Variable(tf.random_normal([batch_size,
image_size,
image_size,3],dtype=tf.float32,stddev=1e-1))
pool5,parameters=inference(image)
init=tf.global_variables_initializer()
sess=tf.Session()
sess.run(init)
time_tensorflow_run(sess,pool5,'Forward')
objective=tf.nn.l2_loss(pool5)#l2_loss:简单的可以理解成张量中的每一个元素进行平方,然后求和,最后乘一个1/2,一般用于优化目标函数中的正则项,防止参数太多复杂容易过拟合
grad=tf.gradients(objective,parameters)
time_tensorflow_run(sess,grad,'Forward-backword')
#运行主函数
run_benchmake()tf.gradients实现回归
运行结果:
conv1 [32, 56, 56, 64]
pool1 [32, 27, 27, 64]
conv2 [32, 27, 27, 192]
pool2 [32, 13, 13, 192]
conv3 [32, 13, 13, 384]
conv4 [32, 13, 13, 256]
conv5 [32, 13, 13, 256]
pool5 [32, 6, 6, 256]
2019-05-27 22:25:39.788447:step 0,duration=1.109
2019-05-27 22:25:51.249102:step 10,duration=1.109
2019-05-27 22:26:02.329736:step 20,duration=1.092
2019-05-27 22:26:13.191357:step 30,duration=1.086
2019-05-27 22:26:24.291992:step 40,duration=1.145
2019-05-27 22:26:35.280620:step 50,duration=1.094
2019-05-27 22:26:46.328252:step 60,duration=1.115
2019-05-27 22:26:57.733905:step 70,duration=1.060
2019-05-27 22:27:08.696532:step 80,duration=1.072
2019-05-27 22:27:19.691161:step 90,duration=1.084
2019-05-27 22:27:29.651730:Forward across 100 steps,1.110 +/- 0.042 sec / batch
2019-05-27 22:28:09.204993:step 0,duration=3.561
2019-05-27 22:28:44.235996:step 10,duration=3.421
2019-05-27 22:29:19.995042:step 20,duration=3.458
2019-05-27 22:29:55.067048:step 30,duration=3.518
2019-05-27 22:30:30.999103:step 40,duration=3.534
2019-05-27 22:31:06.107111:step 50,duration=3.484
2019-05-27 22:31:41.660144:step 60,duration=3.486
2019-05-27 22:32:16.741151:step 70,duration=3.641
2019-05-27 22:32:55.026341:step 80,duration=3.091
2019-05-27 22:33:27.343189:step 90,duration=3.583
2019-05-27 22:33:56.139836:Forward-backword across 100 steps,3.505 +/- 0.242 sec / batch
去掉LRN层的运算结果:
conv1 [32, 56, 56, 64]
pool1 [32, 27, 27, 64]
conv2 [32, 27, 27, 192]
pool2 [32, 13, 13, 192]
conv3 [32, 13, 13, 384]
conv4 [32, 13, 13, 256]
conv5 [32, 13, 13, 256]
pool5 [32, 6, 6, 256]
2019-05-27 22:44:26.854911:step 0,duration=2.977
2019-05-27 22:44:38.492577:step 10,duration=0.863
2019-05-27 22:44:47.372085:step 20,duration=0.876
2019-05-27 22:44:59.104756:step 30,duration=1.560
2019-05-27 22:45:13.066554:step 40,duration=0.922
2019-05-27 22:45:21.611043:step 50,duration=0.831
2019-05-27 22:45:30.247537:step 60,duration=0.877
2019-05-27 22:45:39.611072:step 70,duration=0.937
2019-05-27 22:45:48.737594:step 80,duration=0.937
2019-05-27 22:45:57.988124:step 90,duration=0.960
2019-05-27 22:46:06.126589:Forward across 100 steps,1.022 +/- 0.363 sec / batch
2019-05-27 22:46:25.194680:step 0,duration=1.741
2019-05-27 22:46:42.159650:step 10,duration=1.881
2019-05-27 22:46:58.812603:step 20,duration=1.712
2019-05-27 22:47:15.056532:step 30,duration=1.602
2019-05-27 22:47:31.733485:step 40,duration=1.591
2019-05-27 22:47:48.761459:step 50,duration=1.780
2019-05-27 22:48:05.092393:step 60,duration=1.592
2019-05-27 22:48:21.730345:step 70,duration=1.629
2019-05-27 22:48:38.136283:step 80,duration=1.618
2019-05-27 22:48:55.500277:step 90,duration=1.657
2019-05-27 22:49:10.384128:Forward-backword across 100 steps,1.669 +/- 0.073 sec / batch
去掉LRN层后,准确率没有什么影响,时间下降了很多,所以读者可以自行考虑是否使用LRN。