哑编码官方代码自己的注解
代码和注释如下:
#-*- coding:utf-8 -*-
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
#参考链接:
# http://scikit-learn.org/stable/auto_examples/ensemble/plot_feature_transformation.html#sphx-glr-auto-examples-ensemble-plot-feature-transformation-py
import numpy as np
np.random.seed(10)
np.set_printoptions(threshold = 1e6)#设置打印数量的阈值
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import (RandomTreesEmbedding, RandomForestClassifier,GradientBoostingClassifier)
from sklearn.preprocessing import OneHotEncoder
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_curve
from sklearn.pipeline import make_pipeline
n_estimator = 10
X, y = make_classification(n_samples=100)#创造随机数据集
#这里产生的数据类别只有两种,0和1
#这里y_train是X_train的标签
#这里y_test 是X_test 的标签
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5)
#这里产生训练集和测试集
# It is important to train the ensemble of trees on a different subset是
# of the training data than the linear regression model to avoid
# overfitting, in particular if the total number of leaves is
# similar to the number of training samples
#y_train是X_train的标签
#y_train_lr是X_train_lr的标签
X_train, X_train_lr, y_train, y_train_lr = train_test_split(X_train, y_train,test_size=0.5)
#这里从训练集里面产生训练集和验证集
print"---------------------------------------------------------------------------------------"
print"y_train",y_train
print"---------------------------------------------------------------------------------------"
print"y_train_lr",y_train_lr
print"---------------------------------------------------------------------------------------"
#变量的含义:
#X_train
#y_train
#训练集
#X_test
#y_test
#测试集
#X_train_lr
#y_train_lr
#验证集
# Unsupervised transformation based on totally random trees
#-----------------------------随机森林稀疏编码+使用逻辑回归分类---------------------------------------------------------
rt_lm = LogisticRegression()#逻辑回归
rt = RandomTreesEmbedding(max_depth=3, n_estimators=n_estimator,random_state=0)#随机森林,这里用来降低维的数据映射到高维,方便分类器处理
pipeline = make_pipeline(rt, rt_lm)#
print"X_train=",X_train
print"y_train=",y_train
pipeline.fit(X_train, y_train)
print"X_test",X_test
y_pred_rt = pipeline.predict_proba(X_test)[:, 1]#判定为类别1的概率, pipeline.predict_proba(X_test)本身会返回两列,第0列对应于判定为类别0的概率,第1列对应于判定为类别1的概率
fpr_rt_lm, tpr_rt_lm, _ = roc_curve(y_test, y_pred_rt)#表示通过 rf特征处理,lr预测得到的模型 来拟合所得到的roc曲线
#缩写的含义
# pr_rt_lm =False-Positive-Ratio _ RandomForestTree _ LogisticRegression-Model
# tpr_rt_lm=True -Positive-Ratio _ RandomForestTree _ LogisticRegression-Model
# rf=RandomForestClassifier
#--------------------------------------仅仅使用随机森林分类----------------------------------------------------------------------------
# Supervised transformation based on random forests
rf = RandomForestClassifier(max_depth=3, n_estimators=n_estimator)
rf.fit(X_train, y_train)
y_pred_rf = rf.predict_proba(X_test)[:, 1]#使用随机森林
fpr_rf, tpr_rf, _ = roc_curve(y_test, y_pred_rf)
#使用随机森林预测结果y_pred_rf,并将该数据与原有的标签y_test进行绘制roc曲线(y_test与y_pred_rf进行比较,roc_curve函数相当于是一个检查预测答案是否正确的函数)
#-----------------------------使用随机森林apply编码(返回叶子编码)+哑编码+逻辑回归分类---------------------------------------------------------
rf_enc = OneHotEncoder()
rf_lm = LogisticRegression()
rf_enc.fit(rf.apply(X_train))
rf_lm.fit(rf_enc.transform(rf.apply(X_train_lr)), y_train_lr)#这里的transform就是在进行编码,相当于predict,y_train_lr在这里是标签
y_pred_rf_lm = rf_lm.predict_proba(rf_enc.transform(rf.apply(X_test)))[:, 1]#这里的transofrm函数是在把数据转化为哑编码。[:, 1]依然表示判断为1的类别的概率
fpr_rf_lm, tpr_rf_lm, _ = roc_curve(y_test, y_pred_rf_lm)
#-----------------------------仅仅使用梯度上升分类----------------------------------------------------------
grd = GradientBoostingClassifier(n_estimators=n_estimator)
grd.fit(X_train, y_train)
y_pred_grd = grd.predict_proba(X_test)[:, 1]#使用梯度上升
fpr_grd, tpr_grd, _ = roc_curve(y_test, y_pred_grd)#_代表这个变量我们不关心
#-----------------------------使用梯度上升apply编码+哑编码+逻辑回归分类----------------------------------------------------------
grd_enc = OneHotEncoder()#使用哑编码
grd_enc.fit(grd.apply(X_train)[:, :, 0])
grd_lm = LogisticRegression()
print"类型",type(grd.apply(X_train_lr)[:, :, 0])#X_train_lr中的裸数据集,不带标签
print"grd.apply(X_train_lr)[:, :, 0]=",grd.apply(X_train_lr)
grd_lm.fit(grd_enc.transform(grd.apply(X_train_lr)[:, :, 0]), y_train_lr)#X_train_lr是验证集中的裸数据(不带标签),y_train_lr是X_train_lr对应的标签
y_pred_grd_lm = grd_lm.predict_proba(grd_enc.transform(grd.apply(X_test)[:, :, 0]))[:, 1]#使用逻辑回归,这里transform是在进行哑编码,[:, 1]依然表示判断为1的类别的概率
#这里的[:, :, 0]是因为返回的nd.arrary类型中,是一个三维数组,大概样子是:
# [[[3],
# [2],
# [3]],
# [[3],
# [3],
# [4]]]
fpr_grd_lm, tpr_grd_lm, _ = roc_curve(y_test, y_pred_grd_lm)
#上面一段代码注意:
#X_test是测试集的裸数据(不带标签)
#y_test是测试集X_test对应的标签
#☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆
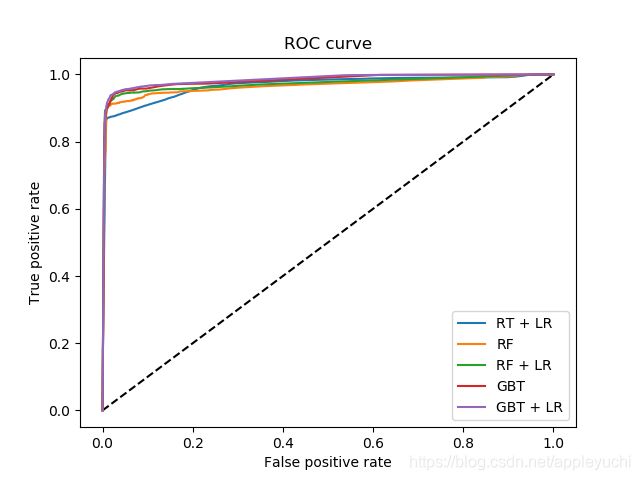
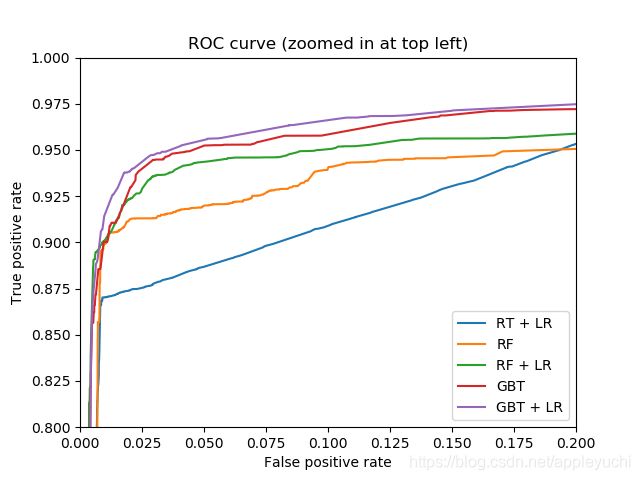
#下面就是画了两张图,注意,这两张图是同一张图,只是X轴的绘制范围限定得不同罢了
#两张图都是TP vs FP(True Positive vs False Positive)
plt.figure(1)
plt.plot([0, 1], [0, 1], 'k--')#黑色短线,可以查询下面的这个链接来得知
#参考链接:
# https://blog.csdn.net/ztf312/article/details/49933497
# 调用格式为:plot(x,y)
plt.plot(fpr_rt_lm, tpr_rt_lm, label='RT + LR')#随机森林embedding编码+逻辑回归预测
plt.plot(fpr_rf, tpr_rf, label='RF')#仅随机森林预测
plt.plot(fpr_rf_lm, tpr_rf_lm, label='RF + LR')#随机森林apply编码+哑编码+逻辑回归预测
plt.plot(fpr_grd, tpr_grd, label='GBT')#仅梯度上升预测
plt.plot(fpr_grd_lm,tpr_grd_lm,label='GBT + LR')#梯度上升编码+哑编码+逻辑回归预测
plt.xlabel('False positive rate')
plt.ylabel('True positive rate')
plt.title('ROC curve')
plt.legend(loc='best')
plt.show()
print"-----------------------------到此为止画完第1张图--------------------------------------------"
plt.figure(2)
plt.xlim(0, 0.2)
plt.ylim(0.8, 1)#这里的xlim和ylim是用来限定绘图范围的
plt.plot([0, 1], [0, 1], 'k--')
plt.plot(fpr_rt_lm, tpr_rt_lm, label='RT + LR')#随机森林embedding编码+逻辑回归预测
plt.plot(fpr_rf, tpr_rf, label='RF')#仅随机森林预测
plt.plot(fpr_rf_lm, tpr_rf_lm, label='RF + LR')#随机森林apply编码+哑编码+逻辑回归预测
plt.plot(fpr_grd, tpr_grd, label='GBT')#仅梯度上升预测
plt.plot(fpr_grd_lm,tpr_grd_lm,label='GBT + LR')#梯度上升编码+哑编码+逻辑回归预测
plt.xlabel('False positive rate')
plt.ylabel('True positive rate')
plt.title('ROC curve (zoomed in at top left)')
plt.legend(loc='best')
plt.show()
print"-----------------------------到此为止画完第2张图--------------------------------------------"运行结果如下: