Android开发常见面试
引言
本文主要罗列Android开发面试中遇到的一些Android技术面试题,仅供大家参考,如有写的不对的地方,也欢迎大家指正,话不多说,我们开始吧。
1. 什么是ANR 如何避免它?
ANR的定义:
首先,ANR(Application Not responding)是指应用程序未响应,Android系统对于一些事件需要在一定的时间范围内完成,如果超过预定时间能未能得到有效响应或者响应时间过长,都会造成ANR。ANR由消息处理机制保证,Android在系统层实现了一套精密的机制来发现ANR,核心原理是消息调度和超时处理。
其次,ANR机制主体实现在系统层。所有与ANR相关的消息,都会经过系统进程(system_server)调度,然后派发到应用进程完成对消息的实际处理,同时,系统进程设计了不同的超时限制来跟踪消息的处理。 一旦应用程序处理消息不当,超时限制就起作用了,它收集一些系统状态,譬如CPU/IO使用情况、进程函数调用栈,并且报告用户有进程无响应了(ANR对话框)。
然后,ANR问题本质是一个性能问题。ANR机制实际上对应用程序主线程的限制,要求主线程在限定的时间内处理完一些最常见的操作(启动服务、处理广播、处理输入), 如果处理超时,则认为主线程已经失去了响应其他操作的能力。主线程中的耗时操作,譬如密集CPU运算、大量IO、复杂界面布局等,都会降低应用程序的响应能力。
不同的组件发生ANR的时间不一样,Activity是5秒,BroadCastReceiver是10秒,Service是20秒(均为前台)。
如果开发机器上出现问题,我们可以通过查看/data/anr/traces.txt即可,最新的ANR信息在最开始部分。
- 主线程被IO操作(从4.0之后网络IO不允许在主线程中)阻塞。
- 主线程中存在耗时的计算
- 主线程中错误的操作,比如Thread.wait或者Thread.sleep等 Android系统会监控程序的响应状况,一旦出现下面两种情况,则弹出ANR对话框
- 应用在5秒内未响应用户的输入事件(如按键或者触摸)
- BroadcastReceiver未在10秒内完成相关的处理
- Service在特定的时间内无法处理完成 20秒
如何避免:
1、使用AsyncTask处理耗时IO操作。
2、使用Thread或者HandlerThread时,调用Process.setThreadPriority(Process.THREAD_PRIORITY_BACKGROUND)设置优先级,否则仍然会降低程序响应,因为默认Thread的优先级和主线程相同。
3、使用Handler处理工作线程结果,而不是使用Thread.wait()或者Thread.sleep()来阻塞主线程。
4、Activity的onCreate和onResume回调中尽量避免耗时的代码。 BroadcastReceiver中onReceive代码也要尽量减少耗时,建议使用IntentService处理。
解决方案:
将所有耗时操作,比如访问网络,Socket通信,查询大 量SQL 语句,复杂逻辑计算等都放在子线程中去,然 后通过handler.sendMessage、runonUIThread、AsyncTask、RxJava等方式更新UI。无论如何都要确保用户界面的流畅 度。如果耗时操作需要让用户等待,那么可以在界面上显示度条。
当ANR被发现后,两个很重要的日志输出是:CPU使用情况和进程的函数调用栈,这两类日志是我们解决ANR问题的利器。
2. Activity和Fragment生命周期有哪些?

(1). 生命周期的几种普通情况
①针对一个特定的Activity,第一次启动,回调如下:onCreate()->onStart()->onResume()
②用户打开新的Activiy的时候,上述Activity的回调如下:onPause()->onStop()
③再次回到原Activity时,回调如下:onRestart()->onStart()->onResume()
④按back键回退时,回调如下:onPause()->onStop()->onDestory()
⑤按Home键切换到桌面后又回到该Actitivy,回调如下:onPause()->onStop()->onRestart()->onStart()->onResume()
⑥调用finish()方法后,回调如下:onDestory()(以在onCreate()方法中调用为例,不同方法中回调不同,通常都是在onCreate()方法中调用)
(2). 特殊情况下的生命周期
上面是普通情况下Activity生命周期的一些流程,但是在一些特殊情况下,Activity的生命周期的经历有些异常,下面就是两种特殊情况。
①横竖屏切换
在横竖屏切换的过程中,会发生Activity被销毁并重建的过程。
在了解这种情况下的生命周期时,首先应该了解这两个回调:onSaveInstanceState和onRestoreInstanceState。
在Activity由于异常情况下终止时,系统会调用onSaveInstanceState来保存当前Activity的状态。这个方法的调用是在onStop之前,它和onPause没有既定的时序关系,该方法只在Activity被异常终止的情况下调用。当异常终止的Activity被重建以后,系统会调用onRestoreInstanceState,并且把Activity销毁时onSaveInstanceState方法所保存的Bundle对象参数同时传递给onRestoreInstanceState和onCreate方法。因此,可以通过onRestoreInstanceState方法来恢复Activity的状态,该方法的调用时机是在onStart之后。其中onCreate和onRestoreInstanceState方法来恢复Activity的状态的区别: onRestoreInstanceState回调则表明其中Bundle对象非空,不用加非空判断。onCreate需要非空判断。建议使用onRestoreInstanceState。
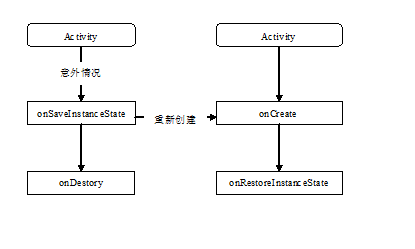
横竖屏切换的生命周期:onPause()->onSaveInstanceState()-> onStop()->onDestroy()->onCreate()->onStart()->onRestoreInstanceState->onResume()
可以通过在AndroidManifest文件的Activity中指定如下属性:
android:configChanges = “orientation| screenSize”
来避免横竖屏切换时,Activity的销毁和重建,而是回调了下面的方法:
@Override
public void onConfigurationChanged(Configuration newConfig) {
super.onConfigurationChanged(newConfig);
}
②资源内存不足导致优先级低的Activity被杀死
Activity优先级的划分和下面的Activity的三种运行状态是对应的。
(1) 前台Activity——正在和用户交互的Activity,优先级最高。
(2) 可见但非前台Activity——比如Activity中弹出了一个对话框,导致Activity可见但是位于后台无法和用户交互。
(3) 后台Activity——已经被暂停的Activity,比如执行了onStop,优先级最低。
当系统内存不足时,会按照上述优先级从低到高去杀死目标Activity所在的进程。我们在平常使用手机时,能经常感受到这一现象。这种情况下数组存储和恢复过程和上述情况一致,生命周期情况也一样。
3. AsyncTask的缺陷和问题,说说他的原理
AsyncTask是什么?
AsyncTask是一种轻量级的异步任务类,它可以在线程池中执行后台任务,然后把执行的进度和最终结果传递给主线程并在主线程中更新UI。
AsyncTask是一个抽象的泛型类,它提供了Params、Progress和Result这三个泛型参数,其中Params表示参数的类型,Progress表示后台任务的执行进度和类型,而Result则表示后台任务的返回结果的类型,如果AsyncTask不需要传递具体的参数,那么这三个泛型参数可以用Void来代替。
关于线程池:
AsyncTask对应的线程池ThreadPoolExecutor都是进程范围内共享的,且都是static的,所以是Asynctask控制着进程范围内所有的子类实例。由于这个限制的存在,当使用默认线程池时,如果线程数超过线程池的最大容量,线程池就会爆掉(3.0后默认串行执行,不会出现个问题)。针对这种情况,可以尝试自定义线程池,配合Asynctask使用。
关于默认线程池:
AsyncTask里面线程池是一个核心线程数为CPU + 1,最大线程数为CPU * 2 + 1,工作队列长度为128的线程池,线程等待队列的最大等待数为28,但是可以自定义线程池。线程池是由AsyncTask来处理的,线程池允许tasks并行运行,需要注意的是并发情况下数据的一致性问题,新数据可能会被老数据覆盖掉。所以希望tasks能够串行运行的话,使用SERIAL_EXECUTOR。
AsyncTask在不同的SDK版本中的区别:
调用AsyncTask的execute方法不能立即执行程序的原因及改善方案通过查阅官方文档发现,AsyncTask首次引入时,异步任务是在一个独立的线程中顺序的执行,也就是说一次只执行一个任务,不能并行的执行,从1.6开始,AsyncTask引入了线程池,支持同时执行5个异步任务,也就是说只能有5个线程运行,超过的线程只能等待,等待前的线程直到某个执行完了才被调度和运行。换句话说,如果进程中的AsyncTask实例个数超过5个,那么假如前5都运行很长时间的话,那么第6个只能等待机会了。这是AsyncTask的一个限制,而且对于2.3以前的版本无法解决。如果你的应用需要大量的后台线程去执行任务,那么只能放弃使用AsyncTask,自己创建线程池来管理Thread。不得不说,虽然AsyncTask较Thread使用起来方便,但是它最多只能同时运行5个线程,这也大大局限了它的作用,你必须要小心设计你的应用,错开使用AsyncTask时间,尽力做到分时,或者保证数量不会大于5个,否就会遇到上面提到的问题。可能是Google意识到了AsynTask的局限性了,从Android 3.0开始对AsyncTask的API做出了一些调整:每次只启动一个线程执行一个任务,完了之后再执行第二个任务,也就是相当于只有一个后台线程在执行所提交的任务。
一些问题:
1.生命周期
很多开发者会认为一个在Activity中创建的AsyncTask会随着Activity的销毁而销毁。然而事实并非如此。AsynTask会一直执行,直到doInBackground()方法执行完毕,然后,如果cancel(boolean)被调用,那么onCancelled(Result result)方法会被执行;否则,执行onPostExecute(Result result)方法。如果我们的Activity销毁之前,没有取消AsyncTask,这有可能让我们的应用崩溃(crash)。因为它想要处理的view已经不存在了。所以,我们是必须确保在销毁活动之前取消任务。总之,我们使用AsyncTask需要确保AsyncTask正确的取消。
2.内存泄漏
如果AsyncTask被声明为Activity的非静态内部类,那么AsyncTask会保留一个对Activity的引用。如果Activity已经被销毁,AsyncTask的后台线程还在执行,它将继续在内存里保留这个引用,导致Activity无法被回收,引起内存泄漏。
3.结果丢失
屏幕旋转或Activity在后台被系统杀掉等情况会导致Activity的重新创建,之前运行的AsyncTask会持有一个之前Activity的引用,这个引用已经无效,这时调用onPostExecute()再去更新界面将不再生效。
4.并行还是串行
在Android1.6之前的版本,AsyncTask是串行的,在1.6之后的版本,采用线程池处理并行任务,但是从Android 3.0开始,为了避免AsyncTask所带来的并发错误,又采用一个线程来串行执行任务。可以使用executeOnExecutor()方法来并行地执行任务。
AsyncTask原理
AsyncTask中有两个线程池(SerialExecutor和THREAD_POOL_EXECUTOR)和一个Handler(InternalHandler),其中线程池SerialExecutor用于任务的排队,而线程池THREAD_POOL_EXECUTOR用于真正地执行任务,InternalHandler用于将执行环境从线程池切换到主线程。
sHandler是一个静态的Handler对象,为了能够将执行环境切换到主线程,这就要求sHandler这个对象必须在主线程创建。由于静态成员会在加载类的时候进行初始化,因此这就变相要求AsyncTask的类必须在主线程中加载,否则同一个进程中的AsyncTask都将无法正常工作。
4. android中进程的优先级
- 前台进程:
即与用户正在交互的Activity或者Activity用到的Service等,如果系统内存不足时前台进程是最晚被杀死的
处于正在与用户交互的activity
与前台activity绑定的service
调用了startForeground()方法的service
正在执行oncreate(),onstart(),ondestroy方法的 service。
进程中包含正在执行onReceive()方法的BroadcastReceiver。
- 可见进程:
可以是处于暂停状态(onPause)的Activity或者绑定在其上的Service,即被用户可见,但由于失了焦点而不能与用户交互
为处于前台,但仍然可见的activity(例如:调用了onpause()而还没调用onstop()的activity)。典型情况是:运行activity时,弹出对话框(dialog等),此时的activity虽然不是前台activity,但是仍然可见。
可见activity绑定的service。(处于上诉情况下的activity所绑定的service)
- 服务进程:
其中运行着使用startService方法启动的Service,虽然不被用户可见,但是却是用户关心的,例如用户正在非音乐界面听的音乐或者正在非下载页面下载的文件等;当系统要空间运行,前两者进程才会被终止
- 后台进程:
其中运行着执行onStop方法而停止的程序,但是却不是用户当前关心的,例如后台挂着的QQ,这时的进程系统一旦没了有内存就首先被杀死
- 空进程:
不包含任何应用程序的进程,这样的进程系统是一般不会让他存在的
5. Bunder传递对象为什么需要序列化?Serialzable和Parcelable的区别?
因为bundle传递数据时只支持基本数据类型,所以在传递对象时需要序列化转换成可存储或可传输的本质状态(字节流)。序列化后的对象可以在网络、IPC(比如启动另一个进程的Activity、Service和Reciver)之间进行传输,也可以存储到本地。
Serializable(Java自带):
Serializable 是序列化的意思,表示将一个对象转换成存储或可传输的状态。序列化后的对象可以在网络上进传输,也可以存储到本地。
除了Serializable之外,使用Parcelable也可以实现相同的效果,不过不同于将对象进行序列化,Parcelable方式的实现原理是将一个完整的对象进行分解,而分解后的每一部分都是Intent所支持的数据类型,这也就实现传递对象的功能了。

总结:
两者最大的区别在于 存储媒介的不同,Serializable 使用 I/O 读写存储在硬盘上,而 Parcelable 是直接 在内存中读写。很明显,内存的读写速度通常大于 IO 读写,所以在 Android 中传递数据优先选择 Parcelable。
Serializable 会使用反射,序列化和反序列化过程需要大量 I/O 操作, Parcelable 自已实现封送和解封(marshalled &unmarshalled)操作不需要用反射,数据也存放在 Native 内存中,效率要快很多。
6. 动画
总的来说,Android动画可以分为两类,最初的传统动画和Android3.0 之后出现的属性动画;
传统动画又包括 帧动画(Frame Animation)和补间动画(Tweened Animation)。
PropertyAnimation 属性动画3.0引入,属性动画核心思想是对值的变化。
原理及特点:
1.属性动画(ObjectAnimator和ValueAnimator):
插值器:作用是根据时间流逝的百分比来计算属性变化的百分比
估值器:在1的基础上由这个东西来计算出属性到底变化了多少数值的类
其实就是利用插值器和估值器,来计出各个时刻View的属性,然后通过改变View的属性来实现View的动画效果。
2.View动画:
只是影像变化,view的实际位置还在原来地方。
3.帧动画:
是在xml中定义好一系列图片之后,使用AnimatonDrawable来播放的动画。
Property Animation 动画有两个步聚:
1.计算属性值
2.为目标对象的属性设置属性值,即应用和刷新动画

计算属性分为3个过程:
过程一:
计算已完成动画分数 elapsed fraction。为了执行一个动画,你需要创建一个ValueAnimator,并且指定目标对象属性的开始、结束和持续时间。在调用 start 后的整个动画过程中,ValueAnimator 会根据已经完成的动画时间计算得到一个0 到 1 之间的分数,代表该动画的已完成动画百分比。0表示 0%,1 表示 100%。
过程二:
计算插值(动画变化率)interpolated fraction 。当 ValueAnimator计算完已完成的动画分数后,它会调用当前设置的TimeInterpolator,去计算得到一个interpolated(插值)分数,在计算过程中,已完成动画百分比会被加入到新的插值计算中。
过程三:
计算属性值当插值分数计算完成后,ValueAnimator会根据插值分数调用合适的 TypeEvaluator去计算运动中的属性值。 以上分析引入了两个概念:已完成动画分数(elapsed fraction)、插值分数( interpolated fraction )。
它们的区别:
属性动画才是真正的实现了 view 的移动,补间动画对view 的移动更像是在不同地方绘制了一个影子,实际对象还是处于原来的地方。 当动画的 repeatCount 设置为无限循环时,如果在Activity退出时没有及时将动画停止,属性动画会导致Activity无法释放而导致内存泄漏,而补间动画却没问题。 xml 文件实现的补间动画,复用率极高。在 Activity切换,窗口弹出时等情景中有着很好的效果。 使用帧动画时需要注意,不要使用过多特别大的图,容导致内存不足。
为什么属性动画移动后仍可点击?
播放补间动画的时候,我们所看到的变化,都只是临时的。而属性动画呢,它所改变的东西,却会更新到这个View所对应的矩阵中,所以当ViewGroup分派事件的时候,会正确的将当前触摸坐标,转换成矩阵变化后的坐标,这就是为什么播放补间动画不会改变触摸区域的原因了。
7. Context相关
什么是Context
源码中的注释是这么来解释Context的:Context提供了关于应用环境全局信息的接口。它是一个抽象类,它的实现被Android系统所提供。它允许获取以应用为特征的资源和类型,是一个统领一些资源(应用程序环境变量等)的上下文。也就是说,它描述了一个应用程序环境的信息(即上下文)。
通过它我们可以获取应用程序的资源和类(包括应用级别操作,如启动Activity,发广播,接受Intent等)。既然上面Context是一个抽象类,那么肯定有他的实现类,我们在Context的源码中可以看到如下关系图:

Context的两个子类分工明确,其中ContextImpl是Context的具体实现类,ContextWrapper是Context的包装类。Activity,Application,Service虽都继承自ContextWrapper(Activity继承自ContextWrapper的子类ContextThemeWrapper),但它们初始化的过程中都会创建ContextImpl对象,由ContextImpl实现Context中的方法。
使用context时的注意点:
1、Activity和Service以及Application的Context是不一样的,Activity继承自ContextThemeWraper.其他的继承自ContextWrapper。
2、每一个Activity和Service以及Application的Context是一个新的ContextImpl对象。
3、getApplication()用来获取Application实例的,但是这个方法只有在Activity和Service中才能调用的到。那也许在绝大多数情况下我们都是在Activity或者Servic中使用Application的,但是如果在一些其它的场景,比如BroadcastReceiver中也想获得Application的实例,这时就可以借助getApplicationContext()方法,getApplicationContext()比getApplication()方法的作用域会更广一些,任何一个Context的实例,只要调用getApplicationContext()方法都可以拿到我们的Application对象。
4、创建对话框时不可以用Application的context,只能用Activity的context。
5、Context的数量等于Activity的个数 + Service的个数 +1,这个1为Application。
Context作用域
虽然Context神通广大,但并不是随便拿到一个Context实例就可以为所欲为,它的使用还是有一些规则限制的。由于Context的具体实例是由ContextImpl类去实现的,因此在绝大多数场景下,Activity、Service和Application这三种类型的Context都是可以通用的。不过有几种场景比较特殊,比如启动Activity,还有弹出Dialog。出于安全原因的考虑,Android是不允许Activity或Dialog凭空出现的,一个Activity的启动必须要建立在另一个Activity的基础之上,也就是以此形成的返回栈。而Dialog则必须在一个Activity上面弹出(除非是System Alert类型的Dialog),因此在这种场景下,我们只能使用Activity类型的Context,否则将会出错。

(1)如果我们用ApplicationContext去启动一个LaunchMode为standard的Activity的时候会报错android.util.AndroidRuntimeException: Calling startActivity from outside of an Activity context requires the FLAG_ACTIVITY_NEW_TASK flag. Is this really what you want?
这是因为非Activity类型的Context并没有所谓的任务栈,所以待启动的Activity就找不到栈了。解决这个问题的方法就是为待启动的Activity指定FLAG_ACTIVITY_NEW_TASK标记位,这样启动的时候就为它创建一个新的任务栈,而此时Activity是以singleTask模式启动的。所有这种用Application启动Activity的方式不推荐使用,Service同Application。
(2)怎么在Service中创建Dialog对话框?
在我们取得Dialog对象后,需给它设置类型,即:
dialog.getWindow().setType(WindowManager.LayoutParams.TYPE_SYSTEM_ALERT)
在Manifest中加上权限:
Context引起的内存泄露
Context并不能随便乱用,用的不好有可能会引起内存泄露的问题,下面就示例两种错误的引用方式。
(1)错误的单例模式
public class Singleton {
private static Singleton instance;
private Context mContext;
private Singleton(Context context) {
this.mContext = context;
}
public static Singleton getInstance(Context context) {
if (instance == null) {
instance = new Singleton(context);
}
return instance;
}
}
这是一个非线程安全的单例模式,instance作为静态对象,其生命周期要长于普通的对象,其中也包含Activity,假如Activity A去getInstance获得instance对象,传入this,常驻内存的Singleton保存了你传入的Activity A对象,并一直持有,即使Activity被销毁掉,但因为它的引用还存在于一个Singleton中,就不可能被GC掉,这样就导致了内存泄漏。
(2)View持有Activity引用
public class MainActivity extends Activity {
private static Drawable mDrawable;
@Override
protected void onCreate(Bundle saveInstanceState) {
super.onCreate(saveInstanceState);
setContentView(R.layout.activity_main);
ImageView iv = new ImageView(this);
mDrawable = getResources().getDrawable(R.drawable.ic_launcher);
iv.setImageDrawable(mDrawable);
}
}
有一个静态的Drawable对象,当ImageView设置这个Drawable时,ImageView保存了mDrawable的引用,而ImageView传入的this是MainActivity的mContext,因为被static修饰的mDrawable是常驻内存的,MainActivity是它的间接引用,MainActivity被销毁时,也不能被GC掉,所以造成内存泄漏。
正确使用Context
一般Context造成的内存泄漏,几乎都是当Context销毁的时候,却因为被引用导致销毁失败,而Application的Context对象可以理解为随着进程存在的,所以我们总结出使用Context的正确姿势:
- 当Application的Context能搞定的情况下,并且生命周期长的对象,优先使用Application的Context。
- 不要让生命周期长于Activity的对象持有到Activity的引用。
- 尽量不要在Activity中使用非静态内部类,因为非静态内部类会隐式持有外部类实例的引用,如果使用静态内部类,将外部实例引用作为弱引用持有。
8. 更新UI方式
Activity.runOnUiThread(Runnable)
View.post(Runnable),View.postDelay(Runnable, long)(可以理解为在当前操作视图UI线程添加队列)
Handler
AsyncTask
Rxjava
LiveData
9. ContentProvider使用方法
进行跨进程通信,实现进程间的数据交互和共享。通过Context 中 getContentResolver() 获得实例,通过 Uri匹配进行数据的增删改查。ContentProvider使用表的形式来组织数据,无论数据的来源是什么,ConentProvider 都会认为是一种表,然后把数据组织成表格。

原理
ContentProvider的底层是采用 Android中的Binder机制
具体使用

1. 统一资源标识符(URI)
定义:Uniform Resource Identifier,即统一资源标识符
作用:唯一标识 ContentProvider & 其中的数据
外界进程通过 URI 找到对应的ContentProvider & 其中的数据,再进行数据操作
具体使用
URI分为 系统预置 & 自定义,分别对应系统内置的数据(如通讯录、日程表等等)和自定义数据库

// 设置URI
Uri uri = Uri.parse("content://com.carson.provider/User/1")
// 上述URI指向的资源是:名为 `com.carson.provider`的`ContentProvider` 中表名 为`User` 中的 `id`为1的数据
// 特别注意:URI模式存在匹配通配符* & #
// 匹配任意长度的任何有效字符的字符串
// 以下的URI 表示 匹配provider的任何内容
content://com.example.app.provider/*
// #:匹配任意长度的数字字符的字符串
// 以下的URI 表示 匹配provider中的table表的所有行
content://com.example.app.provider/table/#
2. MIME数据类型
解释:MIME:全称Multipurpose Internet Mail Extensions,多功能Internet 邮件扩充服务。它是一种多用途网际邮件扩充协议,在1992年最早应用于电子邮件系统,但后来也应用到浏览器。MIME类型就是设定某种扩展名的文件用一种应用程序来打开的方式类型,当该扩展名文件被访问的时候,浏览器会自动使用指定应用程序来打开。多用于指定一些客户端自定义的文件名,以及一些媒体文件打开方式。
作用:指定某个扩展名的文件用某种应用程序来打开 如指定.html文件采用text应用程序打开、指定.pdf文件采用flash应用程序打开
具体使用:
ContentProvider根据 URI 返回MIME类型
3. ContentProvider类
ContentProvider主要以表格的形式组织数据,同时也支持文件数据,只是表格形式用得比较多
每个表格中包含多张表,每张表包含行 & 列,分别对应记录 & 字段,同数据库
主要方法
进程间共享数据的本质是:添加、删除、获取 & 修改(更新)数据
所以ContentProvider的核心方法也主要是上述4个作用
<-- 4个核心方法 -->
public Uri insert(Uri uri, ContentValues values)
// 外部进程向 ContentProvider 中添加数据
public int delete(Uri uri, String selection, String[] selectionArgs)
// 外部进程 删除 ContentProvider 中的数据
public int update(Uri uri, ContentValues values, String selection, String[] selectionArgs)
// 外部进程更新 ContentProvider 中的数据
public Cursor query(Uri uri, String[] projection, String selection, String[] selectionArgs, String sortOrder)
// 外部应用 获取 ContentProvider 中的数据
// 注:
// 1. 上述4个方法由外部进程回调,并运行在ContentProvider进程的Binder线程池中(不是主线程)
// 2. 存在多线程并发访问,需要实现线程同步
// a. 若ContentProvider的数据存储方式是使用SQLite & 一个,则不需要,因为SQLite内部实现好了线程同步,若是多个SQLite则需要,因为SQL对象之间无法进行线程同步
// b. 若ContentProvider的数据存储方式是内存,则需要自己实现线程同步
<-- 2个其他方法 -->
public boolean onCreate()
// ContentProvider创建后 或 打开系统后其它进程第一次访问该ContentProvider时 由系统进行调用
// 注:运行在ContentProvider进程的主线程,故不能做耗时操作
public String getType(Uri uri)
// 得到数据类型,即返回当前 Url 所代表数据的MIME类型
4. ContentResolver类
ContentProvider类并不会直接与外部进程交互,而是通过ContentResolver 类
ContentResolver负责统一管理不同 ContentProvider间的操作,通过 URI 即可操作 不同的ContentProvider 中的数据,外部进程通过 ContentResolver类 从而与ContentProvider类进行交互。
ContentResolver 类提供了与ContentProvider类相同名字 & 作用的4个方法
// 外部进程向 ContentProvider 中添加数据
public Uri insert(Uri uri, ContentValues values)
// 外部进程 删除 ContentProvider 中的数据
public int delete(Uri uri, String selection, String[] selectionArgs)
// 外部进程更新 ContentProvider 中的数据
public int update(Uri uri, ContentValues values, String selection, String[] selectionArgs)
// 外部应用 获取 ContentProvider 中的数据
public Cursor query(Uri uri, String[] projection, String selection, String[] selectionArgs, String sortOrder)
5. ContentUris类
作用:操作 URI
具体使用 核心方法有两个:
withAppendedId() 作用:向URI追加一个id
parseId()作用:从URL中获取id
6. UriMatcher类
作用:在ContentProvider 中注册URI
根据 URI 匹配 ContentProvider 中对应的数据表
7. ContentObserver类
定义:内容观察者
作用:观察 Uri引起ContentProvider 中的数据变化 & 通知外界(即访问该数据访问者)
ContentProvider、ContentResolver、ContentObserver 之间的关系?
ContentProvider:管理数据,提供数据的增删改查操作,数据源可以是数据库、文件、XML、网络等,ContentProvider为这些数据的访问提供了统一的接口,可以用来做进程间数据共享。
ContentResolver:ContentResolver可以为不同URI操作不同的ContentProvider中的数据,外部进程可以通过ContentResolver与ContentProvider进行交互。
ContentObserver:观察ContentProvider中的数据变化,并将变化通知给外界。
10. ContentProvider的权限管理(读写分离,权限控制)和批处理。
对于ContentProvider暴露出来的数据,应该是存储在自己应用内存中的数据,对于一些存储在外部存储器上的数据,并不能限制访问权限,使用ContentProvider就没有意义了。对于ContentProvider而言,有很多权限控制,可以在AndroidManifest.xml文件中对节点的属性进行配置,一般使用如下一些属性设置:
权限管理
android:grantUriPermssions:临时许可标志。
android:permission:Provider读写权限。
android:readPermission:Provider的读权限。
android:writePermission:Provider的写权限。
android:enabled:标记允许系统启动Provider。
android:exported:标记允许其他应用程序使用这个Provider。
android:multiProcess:标记允许系统启动Provider相同的进程中调用客户端。
批处理操作
ContentProvider和ContentResolver为我们提供了基础的接口,能满足大部分需求。但是当处理的数据量比较大的时候,我们可以选择调用多次ContentResolver的对应函数 或者 使用批处理操作。当然 后者性能会比较好些。
-
[bulkInsert]
如果只是涉及到单表的批量插入,我们可以直接使用 bulkInsert(Uri uri, ContentValues[] values) 进行批量插入即可。 -
[ContentProviderOperation]
为了使批量更新、插入、删除数据更加方便,android系统引入了 ContentProviderOperation类。
在官方开发文档中推荐使用ContentProviderOperations,有一下原因:
(1). 所有的操作都在一个事务中执行,这样可以保证数据完整性
(2). 由于批量操作在一个事务中执行,只需要打开和关闭一个事务,比多次打开关闭多个事务性能要好些
(3). 使用批量操作和多次单个操作相比,减少了应用和content provider之间的上下文切换,这样也会提升应用的性能,并且减少占用CPU的时间,当然也会减少电量的消耗。
要创建ContentProviderOperation对象,则需要使用 ContentProviderOperation.Builder类,通过调用下面几个静态函数来获取一个Builder 对象:
newInsert 创建一个用于执行插入操作的Builder(支持多表)
newUpdate 创建一个用于执行更新操作的Builder
newDelete 创建一个用于执行删除操作的Builder
newAssertQuery 可以理解为断点查询,也就是查询有没有符合条件的数据,如果没有,会抛出一个OperationApplicationException异常
11. HandlerThread
- HandlerThread原理
当系统有多个耗时任务需要执行时,每个任务都会开启个新线程去执行耗时任务,这样会导致系统多次创建和销毁线程,从而影响性能。为了解决这一问题,Google提出了HandlerThread,HandlerThread本质上是一个线程类,它继承了Thread。HandlerThread有自己的内部Looper对象,可以进行loopr循环。通过获取HandlerThread的looper对象传递给Handler对象,可以在handleMessage()方法中执行异步任务。创建HandlerThread后必须先调用HandlerThread.start()方法,Thread会先调用run方法,创建Looper对象。当有耗时任务进入队列时,则不需要开启新线程,在原有的线程中执行耗时任务即可,否则线程阻塞。它在Android中的一个具体的使用场景是IntentService。由于HanlderThread的run()方法是一个无限循环,因此当明确不需要再使用HandlerThread时,可以通过它的quit或者quitSafely方法来终止线程的执行。
-
HanlderThread的优缺点
HandlerThread优点是异步不会堵塞,减少对性能的消耗。
HandlerThread缺点是不能同时继续进行多任务处理,要等待进行处理,处理效率较低。
HandlerThread与线程池不同,HandlerThread是一个串队列,背后只有一个线程。 -
怎样使用HandlerThread?
-
创建HandlerThread的实例对象
HandlerThread handlerThread = new HandlerThread(“myHandlerThread”);
该参数表示线程的名字,可以随便选择。 -
启动我们创建的HandlerThread线程
handlerThread.start(); -
将我们的handlerThread与Handler绑定在一起。 还记得是怎样将Handler与线程对象绑定在一起的吗?其实很简单,就是将线程的looper与Handler绑定在一起,代码如下:
mThreadHandler = new Handler(mHandlerThread.getLooper()) {
@Override
public void handleMessage(Message msg) {
checkForUpdate();
if(isUpdate){
mThreadHandler.sendEmptyMessage(MSG_UPDATE_INFO);
}
}
};
12. IntentService
IntentService是一种特殊的Service,它继承了Service并且它是一个抽象类,因此必须创建它的子类才能使用IntentService
-
原理
在实现上,IntentService封装了HandlerThread和Handler。当IntentService被第一次启动时,它的onCreate()方法会被调用,onCreat()方法会创建一个HandlerThread,然后使用它的Looper来构造一个Handler对象mServiceHandler,这样通过mServiceHandler发送的消息最终都会在HandlerThread中执行。
生成一个默认的且与主线程互相独立的工作者线程来执行所有传送至onStartCommand()方法的Intetnt。
生成一个工作队列来传送Intent对象给onHandleIntent()方法,同一时刻只传送一个Intent对象,这样一来,你就不必担心多线程的问题。在所有的请求(Intent)都被执行完以后会自动停止服务,所以,你不需要自己去调用stopSelf()方法来停止。

-
实现步骤
步骤1:定义IntentService的子类:传入线程名称、复写onHandleIntent()方法
步骤2:在Manifest.xml中注册服务
步骤3:在Activity中开启Service服务 -
对比
IntentService与Service的区别
- 从属性 & 作用上来说 Service:依赖于应用程序的主线程(不是独立的进程 or 线程)
不建议在Service中编写耗时的逻辑和操作,否则会引起ANR;
IntentService:创建一个工作线程来处理多线程任务 - Service需要主动调用stopSelft()来结束服务,而IntentService不需要(在所有intent被处理完后,系统会自动关闭服务)
IntentService与其他线程的区别
- IntentService内部采用了HandlerThread实现,作用类似于后台线程;
- 与后台线程相比,IntentService是一种后台服务,优势是:优先级高(不容易被系统杀死),从而保证任务的执行。
对于后台线程,若进程中没有活动的四大组件,则该线程的优先级非常低,容易被系统杀死,无法保证任务的执行
- 注意事项
-
该服务提供了一个onBind()方法的默认实现,它返回null。
所以不需要用bindService启动intentService -
提供了一个onStartCommand()方法的默认实现,它将Intent先传送至工作队列,然后从工作队列中每次取出一个传送至onHandleIntent()方法,在该方法中对Intent做相应的处理。
-
为什么在mServiceHandler的handleMessage()回调方法中执行完onHandlerIntent()方法后要使用带参数的stopSelf()方法?
因为stopSel()方法会立即停止服务,而stopSelf(int startId)会等待所有的消息都处理完毕后才终止服务,一般来说,stopSelf(int startId)在尝试停止服务之前会判断最近启动服务的次数是否和startId相等,如果相等就立刻停止服务,不相等则不停止服务。
13. Thread、AsyncTask、IntentService的使用场景与特点
-
Thread线程,独立运行与于 Activity 的,当Activity 被 finish 后,如果没有主动停止 Thread或者 run 方法没有执行完,其会一直执行下去。
-
AsyncTask 封装了两个线程池和一个Handler(SerialExecutor用于排队,THREAD_POOL_EXECUTOR为真正的执行任务,Handler将工作线程切换到主线程),其必须在 UI线程中创建,execute 方法必须在 UI线程中执行,一个任务实例只允许执行一次,执行多次抛出异常,用于网络请求或者简单数据处理。
-
IntentService:处理异步请求,实现多线程,在onHandleIntent中处理耗时操作,多个耗时任务会依次执行,执行完毕自动结束。
14. Merge、ViewStub 的作用
Merge: 减少视图层级,可以删除多余的层级。
ViewStub: 按需加载,减少内存使用量、加快渲染速度、不支持 merge 标签。
15. activity的startActivity和context的startActivity区别?
(1)、从Activity中启动新的Activity时可以直接mContext.startActivity(intent)就好
(2)、如果从其他Context中启动Activity则必须给intent设置Flag:
intent.setFlags(Intent.FLAG_ACTIVITY_NEW_TASK) ;
mContext.startActivity(intent);
16. Android怎么加速启动Activity?
- onCreate() 中不执行耗时操作 把页面显示的 View 细分一下,放在 AsyncTask 里逐步显示,用 Handler 更好。这样用户的看到的就是有层次有步骤的一个个的 View 的展示,不会是先看到一个黑屏,然后一下显示所有 View。最好做成动画,效果更自然。
- 利用多线程的目的就是尽可能的减少 onCreate() 和 onReume() 的时间,使得用户能尽快看到页面,操作页面。
- 减少主线程阻塞时间
- 提高 Adapter 和 AdapterView 的效率
- 优化布局文件
17. Handler机制
在Android中使用消息机制,我们首先想到的就是Handler。没错,Handler是Android消息机制的上层接口。Handler的使用过程很简单,通过它可以轻松地将一个任务切换到Handler所在的线程中去执行。通常情况下,Handler的使用场景就是更新UI
Android消息循环流程图如下所示:
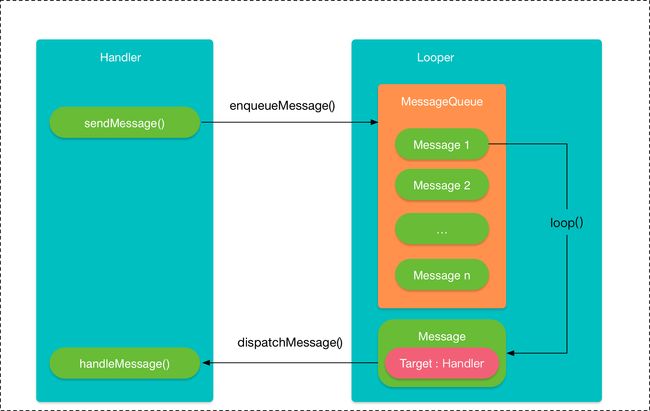
- 消息机制的模型
消息机制主要包含:MessageQueue,Handler和Looper这三大部分,以及Message
- message:需要传递的消息,可以传递数据。
- MessageQueue:消息队列,负责消息的存储与管理,负责管理由 Handler 发送过来的 Message。读取会自动删除消息,单链表维护,插入和删除上有优势。在其next()方法中会无限循环,不断判断是否有消息,有就返回这条消息并移除。
- Looper:消息循环器,负责关联线程以及消息的分发,在该线程下从 MessageQueue获取 Message,分发给Handler,Looper创建的时候会创建一个 MessageQueue,调用loop()方法的时候消息循环开始,其中会不断调用messageQueue的next()方法,当有消息就处理,否则阻塞在messageQueue的next()方法中。当Looper的quit()被调用的时候会调用messageQueue的quit(),此时next()会返回null,然后loop()方法也就跟着退出。
- Handler:消息处理器,主要功能是向消息池发送各种消息事件(Handler.sendMessage)和处理相应消息事件。
-
消息机制的架构
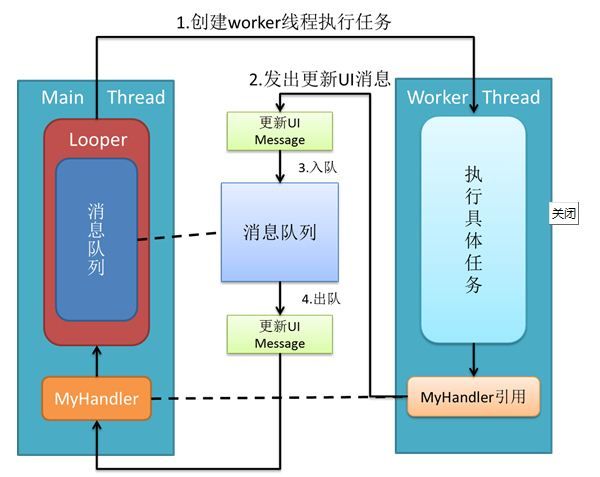
消息机制的运行流程:在子线程执行完耗时操作,当Handler发送消息时,将会调用MessageQueue.enqueueMessage,向消息队列中添加消息。当通过Looper.loop开启循环后,会不断地从线程池中读取消息,即调用MessageQueue.next,然后调用目标Handler(即发送该消息的Handler)的dispatchMessage方法传递消息,然后返回到Handler所在线程,目标Handler收到消息,调用handleMessage方法,接收消息,处理消息。
-
MessageQueue,Handler和Looper三者之间的关系
每个线程中只能存在一个Looper,Looper是保存在ThreadLocal中的。主线程(UI线程)已经创建了一个Looper,所以在主线程中不需要再创建Looper,但是在其他线程中需要创建Looper。每个线程中可以有多个Handler,即一个Looper可以处理来自多个Handler的消息。 Looper中维护一个MessageQueue,来维护消息队列,消息队列中的Message可以来自不同的Handler。 -
Handler 引起的内存泄露原因以及最佳解决方案
Handler 允许我们发送延时消息,如果在延时期间用户关闭了 Activity,那么该 Activity 会泄露。 这个泄露是因为 Message 会持有 Handler,而又因为 Java 的特性,内部类会持有外部类,使得 Activity 会被 Handler 持有,这样最终就导致 Activity 泄露。
解决:将 Handler 定义成静态的内部类,在内部持有 Activity 的弱引用,并在Acitivity的onDestroy()中调用handler.removeCallbacksAndMessages(null)及时移除所有消息。 -
为什么我们能在主线程直接使用 Handler,而不需要创建 Looper ?
通常我们认为 ActivityThread 就是主线程。事实上它并不是一个线程,而是主线程操作的管理者。在 ActivityThread.main() 方法中调用了 Looper.prepareMainLooper() 方法创建了 主线程的 Looper ,并且调用了 loop() 方法,所以我们就可以直接使用 Handler 了。 -
主线程的 Looper 不允许退出
主线程不允许退出,退出就意味 APP 要挂。 -
Handler 里藏着的 Callback 能干什么?
Handler.Callback 有优先处理消息的权利 ,当一条消息被 Callback 处理并拦截(返回 true),那么 Handler 的 handleMessage(msg) 方法就不会被调用了;如果 Callback 处理了消息,但是并没有拦截,那么就意味着一个消息可以同时被 Callback 以及 Handler 处理。 -
创建 Message 实例的最佳方式
为了节省开销,Android 给 Message 设计了回收机制,所以我们在使用的时候尽量复用 Message ,减少内存消耗:
通过 Message 的静态方法 Message.obtain();
通过 Handler 的公有方法 handler.obtainMessage()。 -
主线程的死循环一直运行是不是特别消耗CPU资源呢?
并不是,这里就涉及到Linux pipe/epoll机制,简单说就是在主线程的MessageQueue没有消息时,便阻塞在loop的queue.next()中的nativePollOnce()方法里,此时主线程会释放CPU资源进入休眠状态,直到下个消息到达或者有事务发生,通过往pipe管道写端写入数据来唤醒主线程工作。这里采用的epoll机制,是一种IO多路复用机制,可以同时监控多个描述符,当某个描述符就绪(读或写就绪),则立刻通知相应程序进行读或写操作,本质是同步I/O,即读写是阻塞的。所以说,主线程大多数时候都是处于休眠状态,并不会消耗大量CPU资源。 -
消息分发的优先级:
Message的回调方法:message.callback.run(),优先级最高;
Handler中Callback的回调方法:Handler.mCallback.handleMessage(msg),优先级仅次于1;
Handler的默认方法:Handler.handleMessage(msg),优先级最低。
对于很多情况下,消息分发后的处理方法是第3种情况,即Handler.handleMessage(),一般地往往通过覆写该方法从而实现自己的业务逻辑。
18. 程序A能否接收到程序B的广播?
能,使用全局的BroadCastRecevier能进行跨进程通信,但是注意它只能被动接收广播。此外,LocalBroadCastRecevier只限于本进程的广播间通信。
- 实现原理
Android中的广播使用了设计模式中的观察者模式:基于消息的发布/订阅事件模型。
因此,Android将广播的发送者 和 接收者 解耦,使得系统方便集成,更易扩展
模型中有3个角色:
消息订阅者(广播接收者)
消息发布者(广播发布者)
消息中心(AMS,即Activity Manager Service)

原理描述:
- 广播接收者 通过 Binder机制在 AMS 注册
- 广播发送者 通过 Binder 机制向 AMS 发送广播
- AMS 根据 广播发送者 要求,在已注册列表中,寻找合适的广播接收者
寻找依据:IntentFilter / Permission - AMS将广播发送到合适的广播接收者相应的消息循环队列中
- 广播接收者通过 消息循环 拿到此广播,并回调 onReceive()
特别注意:广播发送者 和 广播接收者的执行 是 异步的,发出去的广播不会关心有无接收者接收,也不确定接收者到底是何时才能接收到;
- 广播接收器注册
注册的方式分为两种:静态注册、动态注册
静态注册:
在AndroidManifest.xml里通过 标签声明
//用于指定此广播接收器将接收的广播类型
//本示例中给出的是用于接收网络状态改变时发出的广播
-
广播的类型
普通广播(Normal Broadcast)
系统广播(System Broadcast)
有序广播(Ordered Broadcast)sendOrderedBroadcast(intent);
粘性广播(Sticky Broadcast)
App应用内广播(Local Broadcast) -
App应用内广播(Local Broadcast)
-
Broadcast存在的问题:
其他App针对性发出与当前App intent-filter相匹配的广播,由此导致当前App不断接收广播并处理;
其他App注册与当前App一致的intent-filter用于接收广播,获取广播具体信息; 即会出现安全性 & 效率性的问题。 -
解决方案:使用App应用内广播(Local Broadcast)
(1). App应用内广播可理解为一种局部广播,广播的发送者和接收者都同属于一个App。
(2). 相比于全局广播(普通广播),App应用内广播优势体现在:安全性高 & 效率高 -
具体使用1 - 将全局广播设置成局部广播
i. 注册广播时将exported属性设置为false,使得非本App内部发出的此广播不被接收
ii. 广播发送和接收时,增设相应权限permission,用于权限验证
iii. 发送广播时指定该广播接收器所在的包名,此广播将只会发送到此包中的App内与之相匹配的有效广播接收器中
通过 intent.setPackage(packageName) 指定报名 -
具体使用2 - 使用封装好的LocalBroadcastManager类 使用方式上与全局广播几乎相同,只是注册/取消注册广播接收器和发送广播时将参数的context变成了LocalBroadcastManager的单一实例
注:对于LocalBroadcastManager方式发送的应用内广播,只能通过LocalBroadcastManager动态注册,不能静态注册
19. 线程池的相关知识
提到线程池就必须先说一下线程池的优点,线程池的优点可以概括为以下四点:
- 重用线程池中的线程,避免因为线程的创建和销毁所带来的性能开销;
- 线程池旨在线程的复用,就避免了创建线程和销毁线程所带来的时间消耗,减少线程频繁调度的开销,从而节约系统资源,提高系统吞吐量;
- 能有效控制线程池的最大并发数,避免大量的线程之间因互相抢占系统资源而导致的阻塞现象;
- 能够对线程进行简单的管理,并提供定时执行以及指定时间间隔循环执行等功能。
Android中的线程池都是直接或间接通过配置ThreadPoolExecutor来实现不同特性的线程池.Android中最常见的类具有不同特性的线程池分别为FixThreadPool、CachedhreadPool、SingleThreadPool、ScheduleThreadPool
- FixThreadPool
只有核心线程,并且数量固定的,也不会被回收,所有线程都活动时,因为队列没有限制大小,新任务会等待执行.
优点:更快的响应外界请求.
-
SingleThreadPool
只有一个核心线程,确保所有的任务都在同一线程中按序完成.因此不需要处理线程同步的问题. -
CachedThreadPool
只有非核心线程,最大线程数非常大,所有线程都活动时会为新任务创建新线程,否则会利用空闲线程(60s空闲时间,过了就会被回收,所以线程池中有0个线程的可能)处理任务.
优点:任何任务都会被立即执行(任务队列SynchronousQuue相当于一个空集合);比较适合执行大量的耗时较少的任务.
- ScheduledThreadPool
核心线程数固定,非核心线程(闲着没活干会被立即回收数)没有限制.
优点:执行定时任务以及有固定周期的重复任务
- 定制线程池
ThreadPoolExecutor 的构造方法提供了一些列的参数来配置线程池,先来了解一下 ThreadPoolExecutor 的构造方法中各个参数的含义,这些参数将直接影响到线程池的功能特性。
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {...
}
-
corePoolSize
线程池的核心线程数,默认情况下,核心线程会在线程池中一直存活,即使它们处于闲置状态。但如果将 ThreadPoolExecutor 的 allowCoreThreadTimeOut 属性设置为 true ,那么闲置的核心线程在等待新任务到来时会有超时策略,这个时间间隔是由 keepAliveTime 所指定,当等待时间超过 keepAliveTime 所指定的时长后,核心线程就会被终止。 -
maximumPoolSize
线程池所能容纳的最大线程数,当活动线程数达到这个数值后,后续的新任务将会被阻塞
如果队列满了,并且已创建的线程数小于最大线程数,则线程池会再创建新的线程执行任务。值得注意的是如果使用了无界的任务队列这个参数就没什么效果。 -
keepAliveTime
非核心线程闲置时的超时时长,超过这个时长,非核心线程就会被回收。当 ThreadPoolExecutor 的 allowCoreThreadTimeOut 属性设置为 true 时,keepAliveTime 同样会作用于核心线程。 -
unit
用于指定 keepAliveTime 参数的时间单位,这是一个枚举,常用的有 TimeUnit .MILLISECONDS 和 TimeUnit .SECONDS。 -
workQueue
线程池中的任务队列,通过线程池的 execute 方法提交的 Runnable 对象会存储在这个参数中
-
ArrayBlockingQueue:是一个基于数组结构的有界阻塞队列,此队列按 FIFO(先进先出)原则对元素进行排序。
-
LinkedBlockingQueue:一个基于链表结构的阻塞队列,此队列按FIFO (先进先出) 排序元素,吞吐量通常要高于ArrayBlockingQueue。静态工厂方法Executors.newFixedThreadPool()使用了这个队列。
-
SynchronousQueue:一个不存储元素的阻塞队列。每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态,吞吐量通常要高于LinkedBlockingQueue,静态工厂方法Executors.newCachedThreadPool使用了这个队列。
-
PriorityBlockingQueue:一个具有优先级的无限阻塞队列。
-
threadFactory
线程工厂,为线程池提供创建新的线程的功能。threadFactory 是一个接口,它只有一个方法: public abstract Thread newThread (Runnable r)
用于设置创建线程的工厂,可以通过线程工厂给每个创建出来的线程设置更有意义的名字。 -
RejectedExecutionHandler
通常叫做拒绝策略,在线程池已经关闭的情况下 ,或者任务太多导致最大线程数和任务队列已经饱和,无法再接收新的任务 。在上面两种情况下,只要满足其中一种时,在使用 execute() 来提交新的任务时将会拒绝,而默认的拒绝策略是抛一个 RejectedExecutionException 异常。
ThreadPoolExecutor 执行任务时策略
以下用 currentSize 表示线程池中当前线程数量
- 当 currentSize < corePoolSize 时,将会直接启动一个核心线程来执行任务。
- 当 currentSize >= corePoolSize ,那么任务会被插入到任务队列中排队等待执行。
- 如果任务队列已满,但 currentSize < maximumPoolSize,那么会立刻启动一个非核心线程来执行任务
- 如果任务队列已满,并且 currentSize > maximumPoolSize,那么就拒绝执行任务,ThreadPoolExecutor 会调用 RejectedExecutionHandler 的 rejectedExecution 方法来通知调用者。
Android 线程池的使用
java线程池的使用
20. Fragment详解
-
什么是Fragment ?
你可以简单的理解为,Fragment是显示在Activity中的Activity。它可以显示在Activity中,然后它也可以显示出一些内容。因为它拥有自己的生命周期,可以接受处理用户的事件,并且你可以在一个Activity中动态的添加,替换,移除不同的Fragment,因此对于信息的展示具有很大的便利性。 -
FragmentTransaction事务
transaction.add() 向Activity中添加一个Fragment
transaction.remove() 从Activity中移除一个Fragment,如果被移除的Fragment没有添加到回退栈(回退栈后面会详细说),这个Fragment实例将会被销毁
transaction.replace() 使用另一个Fragment替换当前的,实际上就是remove()然后add()的合体
transaction.hide() 隐藏当前的Fragment,仅仅是设为不可见,并不会销毁
transaction.show() 显示之前隐藏的Fragment
detach() 会将view从UI中移除,和remove()不同,此时fragment的状态依然由FragmentManager维护
attach() 重建view视图,附加到UI上并显示
ransatcion.commit() 提交事务 -
Fragment的回退栈
FragmentTransaction.addToBackStack(String)
Fragment的回退栈是用来保存每一次Fragment事务发生的变化 如果你将Fragment任务添加到回退栈,当用户点击后退按钮时,将看到上一次的保存的Fragment。一旦Fragment完全从后退栈中弹出,用户再次点击后退键,则退出当前Activity -
Fragment与Activity之间的通信
Fragment依附于Activity存在,因此与Activity之间的通信可以归纳为以下几点:
- 如果你Activity中包含自己管理的Fragment的引用,可以通过引用直接访问所有的Fragment的public方法
- 如果Activity中未保存任何Fragment的引用,那么没关系,每个Fragment都有一个唯一的TAG或者ID,可以通过getFragmentManager.findFragmentByTag()或者findFragmentById()获得任何Fragment实例,然后进行操作
- Fragment中可以通过getActivity()得到当前绑定的Activity的实例,然后进行操作。
- 为了解除Fragment和Activity的耦合,借助Fragment声明接口,来回调事件,Activity实现此接口即可
21. Android事件分发机制
– 主要发生的Touch事件有如下四种:
MotionEvent.ACTION_DOWN:按下View(所有事件的开始)
MotionEvent.ACTION_MOVE:滑动View
MotionEvent.ACTION_CANCEL:非人为原因结束本次事件
MotionEvent.ACTION_UP:抬起View(与DOWN对应)
-
事件在哪些对象之间进行传递?
Activity、ViewGroup、View
一个点击事件产生后,传递顺序是:Activity(Window) -> ViewGroup -> View
Android的UI界面是由Activity、ViewGroup、View及其派生类组合而成的 -
事件分发过程由哪些方法协作完成?
dispatchTouchEvent() 、onInterceptTouchEvent()和onTouchEvent()

-
事件分发机制流程介绍
事件分发过程由dispatchTouchEvent() 、onInterceptTouchEvent()和onTouchEvent()三个方法协助完成
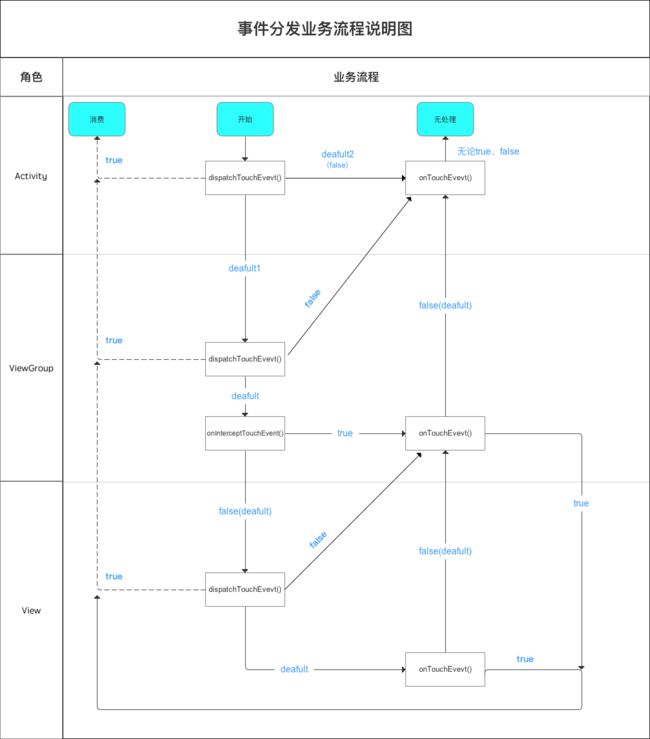
super:调用父类方法
true:消费事件,即事件不继续往下传递
false:不消费事件,事件也不继续往下传递 / 交由给父控件onTouchEvent()处理
如果都是不消费事件的话,就是一个完整的U型状态
事件依次是:Activity.dispatchTouchEvent -->ViewGroup.dispatchTouchEvent—>ViewGroup.onInterceptTouchEvent—>View.dispatchTouchEvent—>View.onTouchEvent—>ViewGroup.onTouchEvent—>Activity.onTouchEvent
- 当前View的MotionEvent.ACTION_CANCEL是什么情况下触发的
当控件收到前驱事件(什么叫前驱事件?一个从DOWN一直到UP的所有事件组合称为完整的手势,中间的任意一次事件对于下一个事件而言就是它的前驱事件)之后,后面的事件如果被父控件拦截,那么当前控件就会收到一个CANCEL事件,并且把这个事件会传递给它的子事件。
22. LruCache原理解析
一般来说,缓存策略主要包含缓存的添加、获取和删除这三类操作。如何添加和获取缓存这个比较好理解,那么为什么还要删除缓存呢?这是因为不管是内存缓存还是硬盘缓存,它们的缓存大小都是有限的。当缓存满了之后,再想其添加缓存,这个时候就需要删除一些旧的缓存并添加新的缓存。
因此LRU(Least Recently Used)缓存算法便应运而生,LRU是最近最少使用的算法,它的核心思想是当缓存满时,会优先淘汰那些最近最少使用的缓存对象。采用LRU算法的缓存有两种:LrhCache和DisLruCache,分别用于实现内存缓存和硬盘缓存,其核心思想都是LRU缓存算法。
- LruCache的介绍
LruCache是Android 3.1所提供的一个缓存类,所以在Android中可以直接使用LruCache实现内存缓存。而DisLruCache目前在Android 还不是Android SDK的一部分,但Android官方文档推荐使用该算法来实现硬盘缓存。
LruCache是个泛型类,主要算法原理是把最近使用的对象用强引用(即我们平常使用的对象引用方式)存储在 LinkedHashMap 中。当缓存满时,把最近最少使用的对象从内存中移除,并提供了get和put方法来完成缓存的获取和添加操作。
- LruCache的使用
LruCache的使用非常简单,我们就已图片缓存为例。
int maxMemory = (int) (Runtime.getRuntime().totalMemory() / 1024);
int cacheSize = maxMemory / 8;
mMemoryCache = new LruCache
@Override
protected int sizeOf(String key, Bitmap value) {
return value.getRowBytes() * value.getHeight() / 1024;
}
};
①设置LruCache缓存的大小,一般为当前进程可用容量的1/8。
②重写sizeOf方法,计算出要缓存的每张图片的大小。
注意: 缓存的总容量和每个缓存对象的大小所用单位要一致。
- LruCache的实现原理
LruCache的核心思想很好理解,就是要维护一个缓存对象列表,其中对象列表的排列方式是按照访问顺序实现的,即一直没访问的对象,将放在队尾,即将被淘汰。而最近访问的对象将放在队头,最后被淘汰。

那么这个队列到底是由谁来维护的,前面已经介绍了是由LinkedHashMap来维护。
而LinkedHashMap是由数组+双向链表的数据结构来实现的。其中双向链表的结构可以实现访问顺序和插入顺序,使得LinkedHashMap中的
通过下面构造函数来指定LinkedHashMap中双向链表的结构是访问顺序还是插入顺序。
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
LinkedHashMap特性就是最近访问的最后输出,那么这就正好满足的LRU缓存算法的思想。可见LruCache巧妙实现,就是利用了LinkedHashMap的这种数据结构。
-
trimToSize()方法控制容量
trimToSize()方法不断地删除LinkedHashMap中队尾的元素,即近期最少访问的,直到缓存大小小于最大值。 -
总结
LruCache中维护了一个集合LinkedHashMap,该LinkedHashMap是以访问顺序排序的。当调用put()方法时,就会在结合中添加元素,并调用trimToSize()判断缓存是否已满,如果满了就用LinkedHashMap的迭代器删除队尾元素,即近期最少访问的元素。当调用get()方法访问缓存对象时,就会调用LinkedHashMap的get()方法获得对应集合元素,同时会更新该元素到队头。
23. View测量、布局及绘制原理
View的绘制是从上往下一层层迭代下来的。DecorView–>ViewGroup(—>ViewGroup)–>View ,按照这个流程从上往下,依次measure(测量),layout(布局),draw(绘制)。

-
Measure流程
顾名思义,就是测量每个控件的大小。
调用measure()方法,进行一些逻辑处理,然后调用onMeasure()方法,在其中调用setMeasuredDimension()设定View的宽高信息,完成View的测量操作。

MeasureSpec由两部分组成,一部分是测量模式,另一部分是测量的尺寸大小。
其中,Mode模式共分为三类
UNSPECIFIED :不对View进行任何限制,要多大给多大,一般用于系统内部
EXACTLY:对应LayoutParams中的match_parent和具体数值这两种模式。检测到View所需要的精确大小,这时候View的最终大小就是SpecSize所指定的值,
AT_MOST :对应LayoutParams中的wrap_content。View的大小不能大于父容器的大小。 -
Layout流程
测量完View大小后,就需要将View布局在Window中,View的布局主要通过确定上下左右四个点来确定的。
其中布局也是自上而下,不同的是ViewGroup先在layout()中确定自己的布局,然后在onLayout()方法中再调用子View的layout()方法,让子View布局。在Measure过程中,ViewGroup一般是先测量子View的大小,然后再确定自身的大小。 -
Draw过程
View的绘制过程遵循如下几步:
①绘制背景 background.draw(canvas)
②绘制自己(onDraw)
③绘制Children(dispatchDraw)
④绘制装饰(onDrawScrollBars) -
总结
从View的测量、布局和绘制原理来看,要实现自定义View,根据自定义View的种类不同,可能分别要自定义实现不同的方法。但是这些方法不外乎:onMeasure()方法,onLayout()方法,onDraw()方法。
-
onMeasure()方法:单一View,一般重写此方法,针对wrap_content情况,规定View默认的大小值,避免于match_parent情况一致。ViewGroup,若不重写,就会执行和单子View中相同逻辑,不会测量子View。一般会重写onMeasure()方法,循环测量子View。
-
onLayout()方法:**单一View,不需要实现该方法。ViewGroup必须实现,该方法是个抽象方法,实现该方法,来对子View进行布局。
-
onDraw()方法:**无论单一View,或者ViewGroup都需要实现该方法,因其是个空方法
24. Android Bitmap压缩策略
现在的高清大图,动辄就要好几M,而Android对单个应用所施加的内存限制,导致加载Bitmap的时候很容易出现内存溢出。如下异常信息,便是在开发中经常需要的:
java.lang.OutofMemoryError:bitmap size exceeds VM budget
为了解决这个问题,就出现了Bitmap的高效加载策略。其实核心思想很简单。假设通过ImageView来显示图片,很多时候ImageView并没有原始图片的尺寸那么大,这个时候把整个图片加载进来后再设置给ImageView,显然是没有必要的,因为ImageView根本没办法显示原始图片。这时候就可以按一定的采样率来将图片缩小后再加载进来,这样图片既能在ImageView显示出来,又能降低内存占用从而在一定程度上避免OOM,提高了Bitmap加载时的性能。
Bitmap高效加载的具体方式
-
要选择合适的图片规格(bitmap类型)
ALPHA_8 每个像素占用1byte内存
ARGB_4444 每个像素占用2byte内存
ARGB_8888 每个像素占用4byte内存(默认)
RGB_565 每个像素占用2byte内存 -
降低采样率
BitmapFactory.Options 参数inSampleSize的使用,先把options.inJustDecodeBounds设为true,只是去读取图片的大小,在拿到图片的大小之后和要显示的大小做比较通过calculateInSampleSize()函数计算inSampleSize的具体值,得到值之后。options.inJustDecodeBounds设为false读图片资源
当inSampleSize=1,即采样后的图片大小为图片的原始大小。小于1,也按照1来计算。 当inSampleSize>1,即采样后的图片将会缩小,缩放比例为1/(inSampleSize的二次方)。
例如:一张1024 ×1024像素的图片,采用ARGB8888格式存储,那么内存大小1024×1024×4=4M。如果inSampleSize=2,那么采样后的图片内存大小:512×512×4=1M。
注意:官方文档支出,inSampleSize的取值应该总是2的指数,如1,2,4,8等。如果外界传入的inSampleSize的值不为2的指数,那么系统会向下取整并选择一个最接近2的指数来代替。比如3,系统会选择2来代替。当时经验证明并非在所有Android版本上都成立。
- 复用内存
SoftReference和inBitmap參数的结合
通过软引用(内存不够的时候才会回收掉),复用内存块,不需要再重新给这个bitmap申请一块新的内存,避免了一次内存的分配和回收,从而改善了运行效率。
inBitmap參数(在Android3.0才開始有的,详情查阅API中的BitmapFactory.Options參数信息)
这个參数主要是提供给我们进行复用内存中的Bitmap,假设设置了此參数,且满足以下条件的时候:
Bitmap一定要是可变的,即inmutable设置一定为ture;
Android4.4以下的平台,须要保证inBitmap和即将要得到decode的Bitmap的尺寸规格一致;
Android4.4及其以上的平台,仅仅须要满足inBitmap的尺寸大于要decode得到的Bitmap的尺寸规格就可以;
-
使用recycle()方法及时回收内存
-
压缩图片
BitmapFactory获取的图片宽高信息和图片的位置以及程序运行的设备有关,比如同一张图片放在不同的drawable目录下或者程序运行在不同屏幕密度的设备上,都可能导致BitmapFactory获取到不同的结果,和Android的资源加载机制有关。
25. 内存泄露,怎样查找,怎么产生的内存泄露?
- 资源对象没关闭造成的内存泄漏
描述: 资源性对象比如(Cursor,File文件等)往往都用了一些缓冲,我们在不使用的时候,应该及时关闭它们,以便它们的缓冲及时回收内存。它们的缓冲不仅存在于 java虚拟机内,还存在于java虚拟机外。如果我们仅仅是把它的引用设置为null,而不关闭它们,往往会造成内存泄漏。因为有些资源性对象,比如SQLiteCursor(在析构函数finalize(),如果我们没有关闭它,它自己会调close()关闭),如果我们没有关闭它,系统在回收它时也会关闭它,但是这样的效率太低了。因此对于资源性对象在不使用的时候,应该调用它的close()函数,将其关闭掉,然后才置为null.在我们的程序退出时一定要确保我们的资源性对象已经关闭。
程序中经常会进行查询数据库的操作,但是经常会有使用完毕Cursor后没有关闭的情况。如果我们的查询结果集比较小,对内存的消耗不容易被发现,只有在常时间大量操作的情况下才会复现内存问题,这样就会给以后的测试和问题排查带来困难和风险。
-
构造Adapter时,没有使用缓存的convertView
描述: 以构造ListView的BaseAdapter为例,在BaseAdapter中提供了方法: public View getView(int position, ViewconvertView, ViewGroup parent) 来向ListView提供每一个item所需要的view对象。初始时ListView会从BaseAdapter中根据当前的屏幕布局实例化一定数量的 view对象,同时ListView会将这些view对象缓存起来。当向上滚动ListView时,原先位于最上面的list item的view对象会被回收,然后被用来构造新出现的最下面的list item。这个构造过程就是由getView()方法完成的,getView()的第二个形参View convertView就是被缓存起来的list item的view对象(初始化时缓存中没有view对象则convertView是null)。由此可以看出,如果我们不去使用 convertView,而是每次都在getView()中重新实例化一个View对象的话,即浪费资源也浪费时间,也会使得内存占用越来越大。 -
Bitmap对象不在使用时调用recycle()释放内存
描述: 有时我们会手工的操作Bitmap对象,如果一个Bitmap对象比较占内存,当它不在被使用的时候,可以调用Bitmap.recycle()方法回收此对象的像素所占用的内存,但这不是必须的,视情况而定。可以看一下代码中的注释
/* •Free up the memory associated with thisbitmap’s pixels, and mark the •bitmap as “dead”, meaning itwill throw an exception if getPixels() or •setPixels() is called, and will drawnothing. This operation cannot be •reversed, so it should only be called ifyou are sure there are no •further uses for the bitmap. This is anadvanced call, and normally need •not be called, since the normal GCprocess will free up this memory when •there are no more references to thisbitmap. / -
试着使用关于application的context来替代和activity相关的context
这是一个很隐晦的内存泄漏的情况。有一种简单的方法来避免context相关的内存泄漏。最显著地一个是避免context逃出他自己的范围之外。使用Application context。这个context的生存周期和你的应用的生存周期一样长,而不是取决于activity的生存周期。如果你想保持一个长期生存的对象,并且这个对象需要一个context,记得使用application对象。你可以通过调用 Context.getApplicationContext() or Activity.getApplication()来获得。 -
注册没取消造成的内存泄漏
一些Android程序可能引用我们的Anroid程序的对象(比如注册机制)。即使我们的Android程序已经结束了,但是别的引用程序仍然还有对我们的Android程序的某个对象的引用,泄漏的内存依然不能被垃圾回收。调用registerReceiver后未调用unregisterReceiver。 比如:假设我们希望在锁屏界面(LockScreen)中,监听系统中的电话服务以获取一些信息(如信号强度等),则可以在LockScreen中定义一个 PhoneStateListener的对象,同时将它注册到TelephonyManager服务中。对于LockScreen对象,当需要显示锁屏界面的时候就会创建一个LockScreen对象,而当锁屏界面消失的时候LockScreen对象就会被释放掉。 但是如果在释放 LockScreen对象的时候忘记取消我们之前注册的PhoneStateListener对象,则会导致LockScreen无法被垃圾回收。如果不断的使锁屏界面显示和消失,则最终会由于大量的LockScreen对象没有办法被回收而引起OutOfMemory,使得system_process 进程挂掉。 虽然有些系统程序,它本身好像是可以自动取消注册的(当然不及时),但是我们还是应该在我们的程序中明确的取消注册,程序结束时应该把所有的注册都取消掉。 -
集合中对象没清理造成的内存泄漏
我们通常把一些对象的引用加入到了集合中,当我们不需要该对象时,并没有把它的引用从集合中清理掉,这样这个集合就会越来越大。如果这个集合是static的话,那情况就更严重了。 -
查找内存泄漏
查找内存泄漏可以使用Android Studio 自带的AndroidProfiler工具或MAT,也可以使用Square产品的LeakCanary.
26. LeakCanary 内存泄露监测原理研究
在LeakCanary中,检测主要分为三步:1.检测一个对象是否是可疑的泄漏对象;2.如果第一步发现可疑对象,dump内存快照,通过分析.hprof文件,确定怀疑的对象是否真的泄漏。3.将分析的结果展示
- 原理
WeakReference与ReferenceQueue
监测机制利用了Java的WeakReference和ReferenceQueue,通过将Activity(对象)包装到WeakReference中,被WeakReference包装过的Activity对象如果被回收,该WeakReference引用会被放到ReferenceQueue中,通过监测ReferenceQueue里面的内容就能检查到Activity是否能够被回收。检查方法如下:
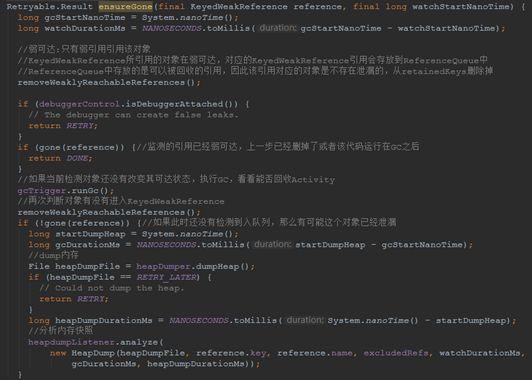
- 首先通过removeWeaklyReachablereference来移除已经被回收的Activity引用
- 通过gone(reference)判断当前弱引用对应的Activity是否已经被回收,如果已经回收说明activity能够被GC,直接返回即可。
- 如果Activity没有被回收,调用GcTigger.runGc方法运行GC,GC完成后在运行第1步,然后运行第2步判断Activity是否被回收了,如果这时候还没有被回收,那就说明Activity可能已经泄露。
- 如果Activity泄露了,就抓取内存dump文件(Debug.dumpHprofData)
LeakCanary 内存泄露监测原理研究
27. Oom 是否可以try catch ?
只有在一种情况下,这样做是可行的:
在try语句中声明了很大的对象,导致OOM,并且可以确认OOM是由try语句中的对象声明导致的,那么在catch语句中,可以释放掉这些对象,解决OOM的问题,继续执行剩余语句。
但是这通常不是合适的做法。
Java中管理内存除了显式地catch OOM之外还有更多有效的方法:比如SoftReference, WeakReference, 硬盘缓存等。 在JVM用光内存之前,会多次触发GC,这些GC会降低程序运行的效率。 如果OOM的原因不是try语句中的对象(比如内存泄漏),那么在catch语句中会继续抛出OOM。
28. Activity的启动模式以及应用场景
-
启动模式的类别
Android提供了四种Activity启动方式:
标准模式(standard)
栈顶复用模式(singleTop)
栈内复用模式(singleTask)
单例模式(singleInstance) -
标准模式(standard)
每启动一次Activity,就会创建一个新的Activity实例并置于栈顶。谁启动了这个Activity,那么这个Activity就运行在启动它的那个Activity所在的栈中。
应用场景: 绝大多数Activity。如果以这种方式启动的Activity被跨进程调用,在5.0之前新启动的Activity实例会放入发送Intent的Task的栈的顶部,尽管它们属于不同的程序,这似乎有点费解看起来也不是那么合理,所以在5.0之后,上述情景会创建一个新的Task,新启动的Activity就会放入刚创建的Task中,这样就合理的多了。
- 栈顶复用模式(singleTop)
如果需要新建的Activity位于任务栈栈顶,那么此Activity的实例就不会重建,而是重用栈顶的实例。并回调如下方法:
@Override
protected void onNewIntent(Intent intent) {
super.onNewIntent(intent);
}
由于不会重建一个Activity实例,则不会回调其他生命周期方法。
如果栈顶不是新建的Activity,就会创建该Activity新的实例,并放入栈顶。
应用场景: 在通知栏点击收到的通知,然后需要启动一个Activity,这个Activity就可以用singleTop,否则每次点击都会新建一个Activity。当然实际的开发过程中,测试妹纸没准给你提过这样的bug:某个场景下连续快速点击,启动了两个Activity。如果这个时候待启动的Activity使用 singleTop模式也是可以避免这个Bug的。同standard模式,如果是外部程序启动singleTop的Activity,在Android 5.0之前新创建的Activity会位于调用者的Task中,5.0及以后会放入新的Task中。
- 栈内复用模式(singleTask)
该模式是一种单例模式,即一个栈内只有一个该Activity实例。该模式,可以通过在AndroidManifest文件的Activity中指定该Activity需要加载到那个栈中,即singleTask的Activity可以指定想要加载的目标栈。singleTask和taskAffinity配合使用,指定开启的Activity加入到哪个栈中。
在这种模式下,如果Activity指定的栈不存在,则创建一个栈,并把创建的Activity压入栈内。如果Activity指定的栈存在,如果其中没有该Activity实例,则会创建Activity并压入栈顶,如果其中有该Activity实例,则把该Activity实例之上的Activity杀死清除出栈,重用并让该Activity实例处在栈顶,然后调用onNewIntent()方法。
应用场景: 大多数App的主页。对于大部分应用,当我们在主界面点击回退按钮的时候都是退出应用,那么当我们第一次进入主界面之后,主界面位于栈底,以后不管我们打开了多少个Activity,只要我们再次回到主界面,都应该使用将主界面Activity上所有的Activity移除的方式来让主界面Activity处于栈顶,而不是往栈顶新加一个主界面Activity的实例,通过这种方式能够保证退出应用时所有的Activity都能报销毁。在跨应用Intent传递时,如果系统中不存在singleTask Activity的实例,那么将创建一个新的Task,然后创建SingleTask Activity的实例,将其放入新的Task中。
- 单例模式(singleInstance)
作为栈内复用模式(singleTask)的加强版,打开该Activity时,直接创建一个新的任务栈,并创建该Activity实例放入新栈中。一旦该模式的Activity实例已经存在于某个栈中,任何应用再激活该Activity时都会重用该栈中的实例。
应用场景: 呼叫来电界面。这种模式的使用情况比较罕见,在Launcher中可能使用。或者你确定你需要使Activity只有一个实例。建议谨慎使用。
29. ThreadLocal的原理
ThreadLocal是一个关于创建线程局部变量的类。使用场景如下所示:
实现单个线程单例以及单个线程上下文信息存储,比如交易id等。
实现线程安全,非线程安全的对象使用ThreadLocal之后就会变得线程安全,因为每个线程都会有一个对应的实例。 承载一些线程相关的数据,避免在方法中来回传递参数。
当需要使用多线程时,有个变量恰巧不需要共享,此时就不必使用synchronized这么麻烦的关键字来锁住,每个线程都相当于在堆内存中开辟一个空间,线程中带有对共享变量的缓冲区,通过缓冲区将堆内存中的共享变量进行读取和操作,ThreadLocal相当于线程内的内存,一个局部变量。每次可以对线程自身的数据读取和操作,并不需要通过缓冲区与 主内存中的变量进行交互。并不会像synchronized那样修改主内存的数据,再将主内存的数据复制到线程内的工作内存。ThreadLocal可以让线程独占资源,存储于线程内部,避免线程堵塞造成CPU吞吐下降。
在每个Thread中包含一个ThreadLocalMap,ThreadLocalMap的key是ThreadLocal的对象,value是独享数据。
30. MVP,MVC解释和实践
- MVC:
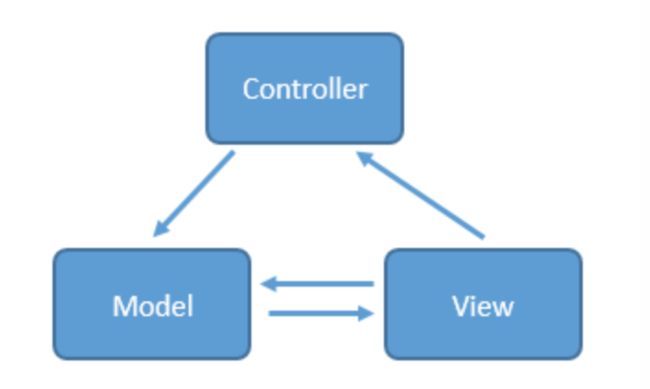
- 视图层(View) 对应于xml布局文件和java代码动态view部分
- 控制层(Controller) MVC中Android的控制层是由Activity来承担的,Activity本来主要是作为初始化页面,展示数据的操作,但是因为XML视图功能太弱,所以Activity既要负责视图的显示又要加入控制逻辑,承担的功能过多
- 模型层(Model) 针对业务模型,建立数据结构和相关的类,它主要负责网络请求,数据库处理,I/O的操作
总结
具有一定的分层,model彻底解耦,controller和view并没有解耦 层与层之间的交互尽量使用回调或者去使用消息机制去完成,尽量避免直接持有 controller和view在android中无法做到彻底分离,但在代码逻辑层面一定要分清 业务逻辑被放置在model层,能够更好的复用和修改增加业务。
MVC还有一个重要的缺陷,大家看上面那幅图,view层和model层是相互可知的,这意味着两层之间存在耦合,耦合对于一个大型程序来说是非常致命的,因为这表示开发,测试,维护都需要花大量的精力。
- MVP:
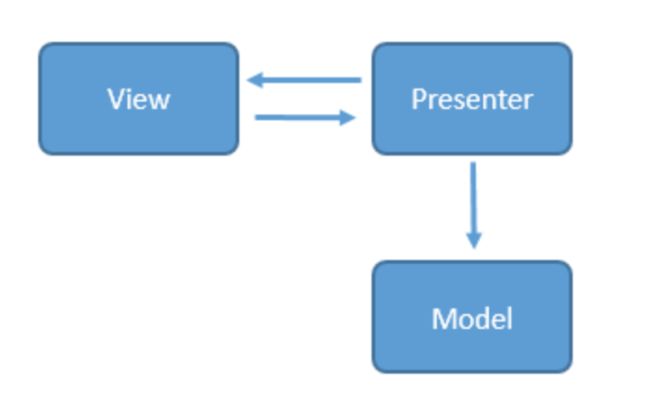
通过引入接口BaseView,让相应的视图组件如Activity,Fragment去实现BaseView,实现了视图层的独立,通过中间层Preseter实现了Model和View的完全解耦。MVP彻底解决了MVC中View和Controller傻傻分不清楚的问题,但是随着业务逻辑的增加,一个页面可能会非常复杂,UI的改变是非常多,会有非常多的case,这样就会造成View的接口会很庞大。
从图中就可以看出,最明显的差别就是view层和model层不再相互可知,完全的解耦,取而代之的presenter层充当了桥梁的作用,用于操作view层发出的事件传递到presenter层中,presenter层去操作model层,并且将数据返回给view层,整个过程中view层和model层完全没有联系。看到这里大家可能会问,虽然view层和model层解耦了,但是view层和presenter层不是耦合在一起了吗?其实不是的,对于view层和presenter层的通信,我们是可以通过接口实现的,具体的意思就是说我们的activity,fragment可以去实现实现定义好的接口,而在对应的presenter中通过接口调用方法。不仅如此,我们还可以编写测试用的View,模拟用户的各种操作,从而实现对Presenter的测试。这就解决了MVC模式中测试,维护难的问题。
31. 应用多进程
正常情况下,一个apk启动后只会运行在一个进程中,其进程名为AndroidManifest.xml文件中指定的应用包名,所有的基本组件都会在这个进程中运行。但是如果需要将某些组件(如Service、Activity等)运行在单独的进程中,就需要用到android:process属性了。我们可以为android的基础组件指定process属性来指定它们运行在指定进程中。
-
有什么好处
1)我们知道Android系统对每个应用进程的内存占用是有限制的,而且占用内存越大的进程,通常被系统杀死的可能性越大。让一个组件运行在单独的进程中,可以减少主进程所占用的内存,降低被系统杀死的概率.2)如果子进程因为某种原因崩溃了,不会直接导致主程序的崩溃,可以降低我们程序的崩溃率。
3)即使主进程退出了,我们的子进程仍然可以继续工作,假设子进程是推送服务,在主进程退出的情况下,仍然能够保证用户可以收到推送消息。
-
怎么来实现
对process属性的设置有两种形式:
第一种形式如 android:process=":remote",以冒号开头,冒号后面的字符串原则上是可以随意指定的。如果我们的包名为“com.example.processtest”,则实际的进程名为“com.example.processtest:remote”。这种设置形式表示该进程为当前应用的私有进程,其他应用的组件不可以和它跑在同一个进程中。第二种情况如 android:process="com.example.processtest.remote",以小写字母开头,表示运行在一个以这个名字命名的全局进程中,其他应用通过设置相同的ShareUID可以和它跑在同一个进程。 -
有哪些陷阱
我们已经开启了应用内多进程,那么,开启多进程是不是只是我们看到的这么简单呢?其实这里面会有一些陷阱,稍微不注意就会陷入其中。我们首先要明确的一点是进程间的内存空间时不可见的。从而,开启多进程后,我们需要面临这样几个问题:
1)Application的多次重建。(通过进程名来区分当前是哪个进程)
2)静态成员的失效。
3)文件共享问题。
4)断点调试问题。
从上面的例子中我们可以看到,android实现应用内多进程并不是简单的设置属性process就可以了,而是会产生很多特殊的问题。像前面提到的,android启动多进程模式后,不仅静态变量会失效,而且类似的如同步锁机制、单例模式也会存在同样的问题。这就需要我们在使用的时候多加注意。而且设置多进程之后,各个进程间就无法直接相互访问数据,只能通过AIDL等进程间通信方式来交换数据。
- 多进程使用场景
-
常驻后台任务应用
类似音乐类、跑步健身类、手机管家类等长时间需要在后台运行的应用。这些应用的特点就是,当用户切到别的应用,或者关掉手机屏幕的时候,应用本身的核心模块还在正常运行,提供服务。如果因为手机内存过低,或者是进程重要性降低,导致应用被杀掉,后台服务停止,对于这些应用来说,就是灭顶之灾。合理利用多进程,将核心后台服务模块和其他UI模块进行分离,保证应用能更稳定的提供服务,从而提升用户体验。 -
多模块应用
多进程还有一种非常有用的场景,就是多模块应用。如果里面肯定会有很多模块,假如有地图模块、大图浏览、自定义WebView等等(这些都是吃内存大户),还会有一些诸如下载服务,监控服务等等,一个成熟的应用一定是多模块化的。
多进程不光解决OOM问题,还能更有效、合理的利用内存。我们可以在适当的时候生成新的进程,在不需要的时候及时杀掉,合理分配,提升用户体验。减少系统被杀掉的风险。