8.docker使用问题总结
docker使用问题总结
1. docker报【Error response from daemon: Error running DeviceCreate (createSnapDevice) dm_task_run failed】错
解决办法:
# systemctl stop docker.service
# thin_check /var/lib/docker/devicemapper/devicemapper/metadata
If there were no errors then proceed with:
# thin_check --clear-needs-check-flag /var/lib/docker/devicemapper/devicemapper/metadata
# systemctl start docker.service
If there were errors, you are on your own, but 'man thin_check' and 'man thin_repair' may be helpful...
========================================================
2. docker默认添加的iptables(ip相关的自己定制):
docker nat表部分:
docker0IP=`ifconfig docker0 |grep 'inet' | cut -d ' ' -f 10`
iptables -A POSTROUTING -t nat -s $docker0IP/30 ! -o docker0 -j MASQUERADE
DockerChain="DOCKER"
iptables -t nat -nL $DockerChain
if [ "x$?" != "x0" ] ; then
iptables -t nat -N $DockerChain
fi
iptables -A PREROUTING -m addrtype --dst-type LOCAL -t nat -j $DockerChain
iptables -A OUTPUT -m addrtype --dst-type LOCAL -t nat -j $DockerChain ! --dst 127.0.0.0/8
iptables -P FORWARD ACCEPT
docker 默认添加为:
iptables -A POSTROUTING -t nat -s 172.17.0.0/16 ! -o docker0 -j MASQUERADE
DockerChain="DOCKER"
iptables -t nat -nL $DockerChain
iptables -A PREROUTING -m addrtype --dst-type LOCAL -t nat -j $DockerChain
iptables -A OUTPUT -m addrtype --dst-type LOCAL -t nat -j $DockerChain ! --dst 127.0.0.0/8
iptables -P FORWARD ACCEPT
参考代码:
https://github.com/docker/docker/blob/2ad81da856c123acf91eeff7ab607376bd27d9ba/vendor/src/github.com/docker/libnetwork/drivers/bridge/setup_ip_tables.go
https://github.com/docker/docker/blob/2ad81da856c123acf91eeff7ab607376bd27d9ba/vendor/src/github.com/docker/libnetwork/iptables/iptables.go
=========================================================
3.docker报类似如下错误【chown socket at step GROUP: No such process】,导致启动失败:
# journalctl -xn
-- Logs begin at Tue 2014-12-30 13:07:53 EST, end at Tue 2014-12-30 13:25:23 EST. --
Dec 30 13:12:30 ITX kernel: ip_tables: (C) 2000-2006 Netfilter Core Team
Dec 30 13:22:53 ITX systemd[1]: Starting Cleanup of Temporary Directories...
-- Subject: Unit systemd-tmpfiles-clean.service has begun with start-up
-- Defined-By: systemd
-- Support: http://lists.freedesktop.org/mailman/listinfo/systemd-devel
--
-- Unit systemd-tmpfiles-clean.service has begun starting up.
Dec 30 13:22:53 ITX systemd[1]: Started Cleanup of Temporary Directories.
-- Subject: Unit systemd-tmpfiles-clean.service has finished start-up
-- Defined-By: systemd
-- Support: http://lists.freedesktop.org/mailman/listinfo/systemd-devel
--
-- Unit systemd-tmpfiles-clean.service has finished starting up.
--
-- The start-up result is done.
Dec 30 13:25:23 ITX systemd[1]: Starting Docker Socket for the API.
-- Subject: Unit docker.socket has begun with start-up
-- Defined-By: systemd
-- Support: http://lists.freedesktop.org/mailman/listinfo/systemd-devel
--
-- Unit docker.socket has begun starting up.
Dec 30 13:25:23 ITX systemd[1868]: Failed to chown socket at step GROUP: No such process
Dec 30 13:25:23 ITX systemd[1]: docker.socket control process exited, code=exited status=216
Dec 30 13:25:23 ITX systemd[1]: Failed to listen on Docker Socket for the API.
-- Subject: Unit docker.socket has failed
-- Defined-By: systemd
-- Support: http://lists.freedesktop.org/mailman/listinfo/systemd-devel
--
-- Unit docker.socket has failed.
--
-- The result is failed.
Dec 30 13:25:23 ITX systemd[1]: Dependency failed for Docker Application Container Engine.
-- Subject: Unit docker.service has failed
-- Defined-By: systemd
-- Support: http://lists.freedesktop.org/mailman/listinfo/systemd-devel
--
-- Unit docker.service has failed.
--
-- The result is dependency.
Dec 30 13:25:23 ITX systemd[1]: Unit docker.socket entered failed state.
解决办法:
方法1.添加docker用户组(groupadd docker,如果/etc/group用统一配置管理的话记得在源group文件中添加docker组信息)
方法2.修改/usr/lib/systemd/system/docker.socket文件:
[Unit]
Description=Docker Socket for the API
PartOf=docker.service
[Socket]
ListenStream=/var/run/docker.sock
SocketMode=0660
SocketUser=root
SocketGroup=docker 这里改成:SocketGroup=root 或其他存在的组
[Install]
WantedBy=sockets.target
如下操作可选:
systemctl enable docker.service && systemctl enable docker.socket:
# systemctl list-unit-files | grep docker
docker.service disabled
docker.socket disabled
# chkconfig docker on #如果chkconfig不能使用则执行:systemctl enable docker.service
Note: Forwarding request to 'systemctl enable docker.service'.
ln -s '/usr/lib/systemd/system/docker.service' '/etc/systemd/system/multi-user.target.wants/docker.service'
# systemctl list-unit-files|grep docker
docker.service enabled
docker.socket disabled
# systemctl enable docker.socket
ln -s '/usr/lib/systemd/system/docker.socket' '/etc/systemd/system/sockets.target.wants/docker.socket'
# systemctl list-unit-files|grep docker
docker.service enabled
docker.socket enabled
参考链接:
http://www.milliondollarserver.com/?cat=7
===============================================================
4.当宿主机上只有一个容器时,删除容器有时会导致宿主机网路瞬断
解决方法:
1.修改/etc/sysconfig/ntpd配置文件增加"-L"选项,如
cat /etc/sysconfig/ntpd
# Command line options for ntpd
OPTIONS="-g -L"
2.重启ntpd服务:systemctl restart ntpd
参考链接:
https://access.redhat.com/solutions/261123
ntp服务细节全解析
========================================================
5.docker1.6+按照官方文档搭建的私有registry, 但是docker login的时候报错
Username: ever
Password:
Email:
Error response from daemon: Unexpected status code [404] :
404 Not Found
解决方法:大概说就是docker 1.6+ 需要registry 2.0, 此外还需要nginx的一个配置,而且这个配置官方文档错的,本来应该用set_more_header,文档用的add_header
官方v1 image和 v2 image迁移工具,可以看一下 https://github.com/docker/migrator,推荐书籍浙大的《docker 容器和容器云》
========================================================
6.docker1.8 pull镜像服务端的访问日志:
127.0.0.1 - - [16/Oct/2015:10:08:52 +0000] "GET /v2/ HTTP/1.1" 401 194 "-" "docker/1.8.3 go/go1.4.2 git-commit/f4bf5c7 kernel/4.2.0-1.el7.elrepo.x86_64 os/linux arch/amd64" "-"
127.0.0.1 - - [16/Oct/2015:10:08:52 +0000] "GET /v1/_ping HTTP/1.1" 404 168 "-" "docker/1.8.3 go/go1.4.2 git-commit/f4bf5c7 kernel/4.2.0-1.el7.elrepo.x86_64 os/linux arch/amd64" "-"
127.0.0.1 - - [16/Oct/2015:10:08:52 +0000] "POST /v1/users/ HTTP/1.1" 404 168 "-" "docker/1.8.3 go/go1.4.2 git-commit/f4bf5c7 kernel/4.2.0-1.el7.elrepo.x86_64 os/linux arch/amd64" "-"
docker应该访问v2接口却去访问v1的接口了
解决方法:docker和registry之间通过一个header来协商api的版本
========================================================
7.docker容器重启或宿主的iptables服务重启后容器无法接收到udp数据包(Failed to receive UDP traffic):
原因:重启容器或重启宿主的iptables服务,在重启过程中,因为在某个时间点,对docker服务做的nat会因为重启失效,物理机会返回端口不可用(如:8888 port unreachable)的错误,这条返回会更新ip_conntrack表的缓存为类似这样:
ipv4 2 udp 17 29 src=xx.xx.xx.xx dst=xx.xx.xx.xx sport=xxxx dport=xxxx [UNREPLIED] src=xx.xx.xx.xx dst=xx.xx.xx.xx sport=xxxx dport=xxxx mark=0 zone=0 use=2
从而导致iptables启动后,数据包再过来,也会依据已有的conntrack缓存,不会被转发到docker容器里面。
解决方法:清理conntrack缓存(可以使用conntrack-tool: conntrack -F)
相关链接:https://github.com/docker/docker/issues/8795 清理conntrack
========================================================
8.docker宿主机新增分区(/ssd),docker必须重启,起容器时在该分区的数据卷(-v /ssd:/ssd)才能生效
解决方法(慎用):修改/usr/lib/systemd/system/docker.service
[Unit]
Description=Docker Application Container Engine
Documentation=http://docs.docker.com
After=network.target docker.socket
Requires=docker.socket
[Service]
Type=notify
EnvironmentFile=-/etc/sysconfig/docker
EnvironmentFile=-/etc/sysconfig/docker-storage
ExecStart=/usr/bin/docker -d $OPTIONS $DOCKER_STORAGE_OPTIONS
ExecStartPost=/usr/bin/chmod 777 /var/run/docker.sock
LimitNOFILE=1048576
LimitNPROC=1048576
MountFlags=private #将这里修改成 MountFlags=shared
[Install]
WantedBy=multi-user.target
相关链接:https://huaminchen.wordpress.com/2015/05/19/how-docker-handles-mount-namespace/
========================================================
9.MFS+DOCKER的文件挂载问题
mfs在本地挂载如下
mfsmount /mnt -H ip -P port -S /
这样本地就有一个/mnt的mfs目录了
但是使用docker run -it -v /mnt:/mnt image:tags /bin/bash
之后发现容器内部还是本地的目录,并不是mfs的挂载目录。大小也不对。查看系统日志发现一个警告:
Jul 16 11:52:36 TENCENT64 docker: [error] mount.go:12 [warning]: couldn’t run auplink before unmount: exec: “auplink”: executable file not found
in $PATH
本地找不到这个auplink的命令,导致docker挂载异常,centos安装如下:
yum install aufs-util
然后需要重启docker
systemctl restart docker
重启容器就可以了
到现在为止docker挂载mfs总共莫名其妙的出过两次问题:
1.mfs修改了挂载目录,但是没有重启docker,结果不论如何启动,抓取日志,依旧没有办法在docker容器中看到mfs的挂载目录。
2.在启动进入容器之后,删除了大量的文件,操作过程已经结束,但是mfs有回收站机制,文件没放到了回收站,真正的数据清理其实并没有进行。这个状态你可以在mfs.cgi页面可以看到。结果在容器中mkdir创建文件夹的时候报device is busy.
这两个错误,我都是重启docker之后才解决的。我认为可能是docker底层的文件服务,cgroup或者aufs有点问题。这个问题暂且留着。
其他网友总结的问题
========================================================
10.docker v1版私有仓库,镜像第一次上传时索引写入db,但是镜像上传失败(search可以找到,但是delete接口删除失败),仓库报错如下:
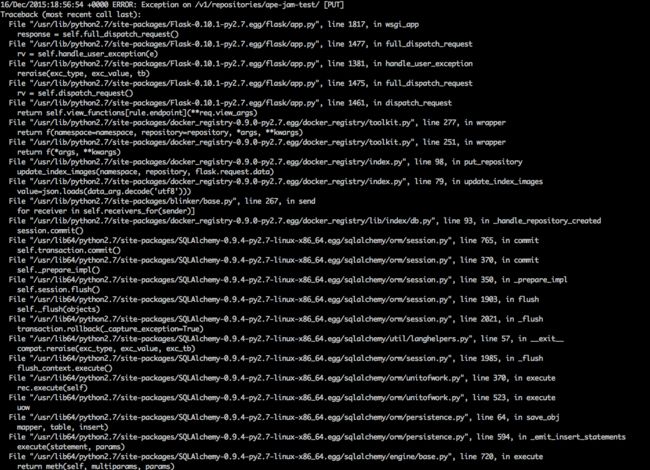

原因:索引已经写入db,但是镜像上传失败,此时会再次写入索引,进而引起name不唯一的报错
解决方法:索引存在sqlite数据库中,去数据库中把报错的镜像索引删掉即可(sqlite3 docker-registry.db;.tables;select * from repository;)。
========================================================
11.device mapper discard的宕机。
原因:这个问题反复出现在某些服务器上,宕机重启后通过IPMI consule进入时系统已经重新挂载了CoreDump的Kernel,看到CoreDump生成dump之前进行Recover操作和Data Copying操作,导致恢复时间很慢。通过Coredump分析属于Kernel在DM discard方面的一个BUG,方法为禁用docker devicemapper的discard。
解决方法:设置docker启动参数"--storage-opt dm.mountopt=nodiscard --storage-opt dm.blkdiscard=false"
========================================================
12.docker启动报错[error] attach_loopback.go:42 There are no more loopback devices available,完整错误日志:
systemd[1]: Starting Docker Application Container Engine...
docker[47518]: 2016/02/03 14:50:32 docker daemon: 1.3.2 39fa2fa/1.3.2; execdriver: native; graphdriver:
docker[47518]: [b98612a1] +job serveapi(fd://, tcp://0.0.0.0:2375, unix:///var/run/docker.sock)
docker[47518]: [error] attach_loopback.go:42 There are no more loopback devices available.
docker[47518]: 2016/02/03 14:50:32 loopback mounting failed
systemd[1]: docker.service: main process exited, code=exited, status=1/FAILURE
systemd[1]: Failed to start Docker Application Container Engine.
systemd[1]: Unit docker.service entered failed state.
systemd[1]: docker.service failed.
原因:because your host system does not have the loopback files in it's dev for docker to use.
解决方法:Use something like this on your host then run the container and it will pick up the devices.
#!/bin/bash
for i in {0..6}
do
mknod -m 0660 /dev/loop$i b 7 $i
done
docker 官方issue:git issue
====================================================================
13.docker执行命令(如docker rm等)报错:
runtime/cgo: pthread_create failed: Resource temporarily unavailable
SIGABRT: abort
PC=0x7f4d400d45d7
goroutine 0 [idle]:
goroutine 16 [running]:
runtime.asmcgocall(0x403ea0, 0x7f4d40bc1f20) 。。。。。。
原因:机器资源达到上限
解决办法:找到达到上限的资源,查明具体原因,并解决(如将limit值加大,/usr/lib/systemd/system/docker.service中增加LimitCORE=infinity,TasksMax=1048576)
[Unit]
Description=Docker Application Container Engine
Documentation=http://docs.docker.com
After=network.target docker.socket
Requires=docker.socket
[Service]
Type=notify
EnvironmentFile=-/etc/sysconfig/docker
EnvironmentFile=-/etc/sysconfig/docker-storage
ExecStart=/usr/bin/docker -d $OPTIONS $DOCKER_STORAGE_OPTIONS
ExecStartPost=/usr/bin/chmod 777 /var/run/docker.sock
LimitNOFILE=1048576
LimitNPROC=1048576
LimitCORE=infinity
TasksMax=1048576
MountFlags=private
[Install]
WantedBy=multi-user.target
git issue
=============================================================
14.使用pipework给容器设置IP报错(Error: argument "veth1pl1.507589e+06" is wrong: "name" too long)
原因:
pipework在设置容器的ip时需要添加vethpair,而虚拟网卡名默认为v${CONTAINER_IFNAME}pl${NSPID},其中CONTAINER_IFNAME为容器内虚拟网卡名,如eth0,NSPID为容器在宿主机上的pid,当pid过大时会转为科学计数法显示(如1507589显示为1.507589e+06),但内核要求虚拟网卡名长度不能超过16 bytes,而此时
v${CONTAINER_IFNAME}pl${NSPID}长度超过了内核的限制,因此在执行:ip link add name $LOCAL_IFNAME mtu $MTU type veth peer name $GUEST_IFNAME mtu $MTU 时报错 (如:ip link add name veth1pl1.507589e+06 mtu 1500 type veth peer name veth1pg1.507589e+06 mtu 1500报错Error: argument "veth1pl1.507589e+06" is wrong: "name" too long)
相关代码:
DOCKERPID=$(docker inspect --format='{{ .State.Pid }}' $GUESTNAME)
NSPID=$DOCKERPID
LOCAL_IFNAME="v${CONTAINER_IFNAME}pl${NSPID}"
ip link add name $LOCAL_IFNAME mtu $MTU type veth peer name $GUEST_IFNAME mtu $MTU
解决办法:
1.pid过大时不要转为科学计数法,修改pipework中
DOCKERPID=$(docker inspect --format='{{ .State.Pid }}' $GUESTNAME) 为
DOCKERPID=$(docker inspect --format='{{ .State.Pid }}' $GUESTNAME|awk '{printf("%d",$0)}') 即可
2.虚拟网卡名生成方法修改为其他方式,保证长度不超过16 byets即可
==============================================
15.docker不设置privileged,无法ssh进容器(centos7安装了ssh的镜像)
解决方法:
将ssh配置中的 UsePAM yes改成UsePAM no就可以不用设置privileged了(UsePAM 做一些用户记接入控制)
==============================================
16.docker rmi $image报错:(Error response from daemon: No such id: xxxxxxxxxxxx
2017/05/10 13:53:59 Error: failed to remove one or more images)
解决方法:
某个容器使用的镜像不存在了(docker ps -a某个容器的镜像显示是报错中的id就是这个容器),将此容器删除即可。
=============================================================
17. docker run|start container报Unit docker-${container_id}.scope already exists错误
原因:之前的容器在停止或删除时,scope没有被systemd清楚掉
解决办法:
方法1. systemctl stop docker-${container_id}.scope
方法2. 重启机器(如果机器可以重启的话)
相关问题官方链接
==============================================================
18.docker使用centos7镜像,yum报fakesystemd-1-17.el7.centos.noarch has installed conflicts systemd: fakesystemd-1-17.el7.centos.noarch错
解决方法:yum swap -y fakesystemd systemd && yum install -y systemd-devel
======================网上发现的其他问题================================
5. 遇到的问题
5.1 幽灵容器问题
我们环境中早期的Docker 是1.5版本的,在升级1.7的时候,部分container的进程从容器逃逸,容器处于Destroyed状态,容器进行任何stop、remove都会出现如下报错
Container does not exist: container destroyed。这是个社区已知的问题,目前社区没有完整的解决方案。升级过程中先关闭老的容器后再升级Docker可以避免该问题。出现问题之后要恢复相对麻烦。
5.2 用户隔离不足
我们测试环境中,容器密度较大。Container新建用户对外全部映射为 UID 500或者501,出现了Resource Temporarily unavailable。
CentOS默认用户UID从500开始,虽然ulimit设置上限是相对独立的,但是统计已经使用资源时却是一起统计的。所以在密度较大的测试和预生产环境可能会出现这样的问题。我们的解法是在我们添加的FirstBoot中创建一个随机UID的用户。这样相同的镜像创建出的用户UID也不同。大家各自统计,尽可能避免问题。
5.3 NFS Server无法启动
这个问题是两个小问题:
1. kernel模块的reload设置。
2. kthreadd创建进程。
第一个问题代表了一系列问题,这个是由于因为文件系统没有kernel的目录,模块依赖关系无从查起。通常此类服务都可以在配置文件中关闭模块的reload过程,例如NFS就可以配置。第二个问题是rpc.nfsd 通知kernel去建立nfsd服务,kernel通过kthreadd来创建nfsd服务。所以nfsd进程不会出现在Container内部,而是暴露在宿主机上。
5.4 线程数量上限” fork: Cannot allocate memory”
我们的环境中出现过1次,表现为宿主机无法ssh登录,通过IPMI Console进行登录闪断。这个问题原因是由于某个应用的问题导致生成大量的线程,达到了系统线程的上线。
我们认为:
1. pid_max 和 threads-max 值如何设置不影响单个进程的线程数量,上限目前为32768
2. pid_max 和 threads-max 影响所有线程的总量,二者较小者为系统上限。超过系统上限后部分系统命令都无法使用。
3. 调整系统上限后虽然可以有更多的线程,但是太多的线程将会对系统稳定性造成影响。
解决思路
1. 环境中所有宿主机将/proc/sys/kernel/pid-max设置为65535,并通过nagios监控告警宿主机上的线程数量。
2. 从应用层(tomcat)限制线程上限。
5.5 .device mapper discard导致的宕机
这个问题反复出现在某些服务器上,宕机重启后通过IPMI consule进入时系统已经重新挂载了CoreDump的Kernel,看到CoreDump生成dump之前进行Recover操作和Data Copying操作,导致恢复时间很慢。通过Coredump分析属于Kernel在DM discard方面的一个BUG,方法为禁用docker devicemapper的discard。具体为设置docker启动参数”–storage-opt dm.mountopt=nodiscard –storage-opt dm.blkdiscard=false”。该问题已经在多个公司分享中看到,解决思路也基本一致。
原文链接
=========================其他链接================================
Linux内核bug引起Mesos、Kubernetes、Docker的TCP/IP数据包失效
docker容器根目录为只读的解决办法
使用 Device Mapper来改变Docker容器的大小,获取更快的池
Docker Device Mapper 使用 direct-lvm
Docker内部存储结构(devicemapper)解析(下篇)
Docker基础技术:DeviceMapper Docker内部存储结构(devicemapper)解析
docker 跨主机网络:overlay 简介
Docker网络解决方案 Docker 网络配置 docker网络配置方法总结
使用mesos管理docker集群(mesos,marathon,chronos)
docker的跨主机解决方案weave----遇到的坑(1)
docker的跨主机解决方案weave----遇到的坑(2)