Kafka+Spark Streaming+Redis Spark streaming实时读取kafka中数据完成wordcount并写入redis中
集群或虚拟机提前安装好spark、kafka和redis
windows环境安装好scala
用idea创建maven工程
spark版本2.2.0
pom文件内容如下:
4.0.0
spark
sparklearning
1.0-SNAPSHOT
1.7
1.7
UTF-8
2.11.7
2.2.0
org.apache.spark
spark-core_2.11
${spark.version}
org.apache.spark
spark-streaming-kafka-0-8_2.11
2.2.0
org.apache.spark
spark-streaming_2.11
2.2.0
org.apache.spark
spark-sql_2.11
2.2.0
redis.clients
jedis
2.9.0
${basedir}/src/main/scala
${basedir}/src/test/scala
${basedir}/src/main/resources
${basedir}/src/test/resources
maven-compiler-plugin
3.1
1.7
1.7
org.apache.maven.plugins
maven-shade-plugin
2.4.3
true
package
shade
*:*
*:*
META-INF/*.SF
META-INF/*.DSA
META-INF/*.RSA
reference.conf
log4j.properties
启动kafka
bin/kafka-server-start.sh config/server.properties在集群或者虚拟机中创建一个topic,取名wordcount2
我的机器名字为storm
bin/kafka-topics.sh --create --zookeeper storm:2181 --replication-factor 1 --partitions 3 --topic wordcount2
打开idea
创建 StatefulKafkaWordCountNew.scala的object文件
import org.apache.log4j.{Level, Logger}
import org.apache.spark.{HashPartitioner, SparkConf}
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
import redis.RedisClient
import redis.clients.jedis.Jedis
object StatefulKafkaWordCountNew {
Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
/**
* 第一个参数:聚合的key,就是单词
* 第二个参数,当前批次该单词出现的次数
* 第三个参数,初始值或累加中间结果
*/
val updateFunc =(iter: Iterator[(String, Seq[Int],Option[Int])]) => {
//iter.map(t => (t._1,t._2.sum + t._3.getOrElse(0)))
iter.map{case(x, y, z) => (x, y.sum+z.getOrElse(0))}
}
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("KafkaWordCountNew").setMaster("local[*]")
val ssc = new StreamingContext(conf, Seconds(3))
//如果要使用可更新历史数据(累加历史数据),那么就要把中间结果保存起来
ssc.checkpoint("ck-streaming")
val zkQuorum = "storm:2181"
val groupId = "wordcountnew"
val topic = Map[String, Int]("wordcount2" ->1)
//创建DStream,需要KafkaDStream
val data: ReceiverInputDStream[(String, String)] = KafkaUtils.createStream(ssc, zkQuorum, groupId, topic)
val lines: DStream[String] = data.map(_._2)
val words: DStream[String] = lines.flatMap(_.split(" "))
val wordAndOne: DStream[(String, Int)] = words.map((_, 1))
val reduced: DStream[(String, Int)] = wordAndOne.updateStateByKey(updateFunc,
new HashPartitioner(ssc.sparkContext.defaultParallelism),true)
//将结果写到redis中
reduced.foreachRDD({rdd =>
rdd.foreachPartition({it =>
//将一个分区里的数据一条一条写出
it.foreach({wordCount =>
//建立redis的客户端连接
val jedis: Jedis = RedisClient.pool.getResource
jedis.auth("DEVElop123")//redis的密码
jedis.hincrBy("wordCount",wordCount._1,wordCount._2)
})
})
})
reduced.print()
ssc.start()
ssc.awaitTermination()
}
}
创建RedisClient.scala的object文件
import org.apache.commons.pool2.impl.GenericObjectPoolConfig
import redis.clients.jedis.JedisPool
object RedisClient extends Serializable {
val redisHost = "fri.robot.kafka"//redis的host名称
val redisPort = 6379//端口
val redisTimeOut = 30000
lazy val pool = new JedisPool(new GenericObjectPoolConfig(),redisHost, redisPort, redisTimeOut)
lazy val hook = new Thread {
override def run = {
println("Execute hook thread: "+this)
pool.destroy()
}
}
sys.addShutdownHook(hook.run)
}
打开xshell,在kafka的wordcount2主题中创建消费者产生数据
kafka-console-producer.sh --broker-list storm:9092 --topic wordcount2 输入hello hello spark spark spark,等idea程序跑起来后回车![]()
运行idea中 StatefulKafkaWordCountNew
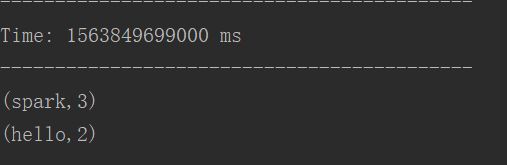
再次输入另外一个新批次,产生新的数据
这次输入hello hello USTB USTB

再看idea中的程序运行控制台
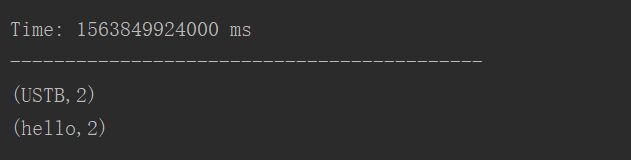
最后查看redis中是否记录了数据

到此本过程就完成了