Apache Kafka 0.9.0 教程 中文版 1. Getting Started
原文地址:http://kafka.apache.org/documentation.html#introduction
翻译自 刘岳峰
1. Getting Started
1.1 Introduction
Kafka是一个分布式的,分区的,复制的提交日志服务。它提供了一个消息系统的功能,但是具有独特的设计。
这些都是什么意思呢?
首先让我们回顾一些基本的消息术语:
- Kafka以类型的形式维护消息的feed,称为topics。
- 我们将发布消息到一个Kafka topic的进程称为producers。
- 我们将订阅topics并且处理已发布消息的feed的进程称为consumers。
- Kafka运行在由一个或多个servers组成的集群上,每个server被称作broker。
因此,从较高的层次上来说,producers在network上发送消息到Kafka集群,集群依次处理这些消息给consumers,就像这样:
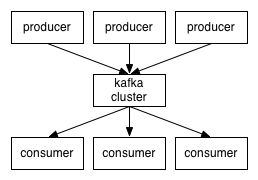
客户端和服务器间的通信由一个简单的,高性能的,语言无关的TCP协议来完成。我们为Kafka提供了一个Java客户端,但是还有很多其他语言的客户端。
Topics and Logs
我们首先来研究下Kafka提供的高层次抽象 - topic。一个topic是已发布的消息的一个类别或者说是feed的名字。针对每个topic,Kafka集群都提供了一个分区的log,看起来像下面这样:

每个分区都是一个有序的,持续追加的不可变消息序列,即一个提交日志(commit log)。分区里的每个消息都被赋予了一个顺序的id号,称作offset,在分区中唯一标识了这个消息。
Kafka集群保持了所有的已发布的消息,无论它们是否已被消费,它们将在一个可配置的时间段内被保持。例如,log的持有期被设置成2天,则该消息被发布2天以内都是对消费者可用的,2天以后它将被丢弃从而释放空间。Kafka的性能针对数据大小保持有效恒定,因此保持大量的数据不是什么问题。
事实上,在每个消费者层面被存储的唯一的元数据是消费者在log中的位置,称作offset。offset被消费者控制:通常一个消费者在读取消息时会线性的递增其offset,但事实上这个位置是被消费者控制的,消费者可以按任何顺序消费消息。例如,一个消费者可以重设到一个较老的offset去重新处理。
这些特性组合起来,意味着Kafka消费者是非常廉价的——它们的运行对集群或者其他消费者没什么大的影响。例如,你可以使用我们的命令行工具来tail出任意topic的内容,而不影响到任意既存消费者的消费。
log上的分区有几个目的。首先,它们使得log的size可以超出单个server所适合的大小。每个单独的分区都必须适应于承载它的server,但是一个topic可以有许多分区,因此它可以处理任意大小的数据总量。另外,它们充当并行的单位-稍后再介绍更多内容。
Distribution
log的分区被分布到各个Kafka集群的服务器上,每个server处理一部分分区的数据和请求。为了容错,每个分区都被复制到几台服务器上,服务器的台数可以配置。
每个分区都有一个server充当"leader",且有0个或多个server充当"followers"。leader处理分区的所有读、写请求,而follower被动地复制leader。如果leader失败,follower中的一个将自动变成新的leader。每个server都充当它上面的一部分分区的leader和其他部分分区的follower,因此在集群间负载是有效均衡的。
Producers
生产者发布数据到它们选择的topics。生产者负责选择哪个消息被分派到topic上的哪个分区。可以通过循环(round-robin)来简单地实现负载均衡,或者也可以通过一些语义分区函数(例如基于消息的一些key)。稍后再介绍更多有关分区运用的内容。
Consumers
传统上,消息分发有两种模型:队列和发布-订阅。在队列模型上,一组消费者从一个服务器读取,且每个消息被其中一个消费者读取;在发布-订阅模型上,消息被广播到所有消费者。Kafka提供了一个消费者抽象——消费者组(consumer group),来归纳这两种模型。
消费者以一个消费者组名来标识自身,发布到topic上的每个消息都被分发到订阅了该topic的消费者组内的一个消费者实例。消费者实例可以分属独立的进程或者独立的机器。
如果所有消费者实例属于同一个消费者组,则这就像传统的队列式负载均衡。
如果所有的消费者实例属于不同的消费者组,则这就像发布-订阅模式,所有消费都被广播到所有消费者。
然而更常见的是,我们发现topic有少量的消费者组,每个组即为一个逻辑订阅者。每个组由许多消费者实例组成,这提供了扩展性和容错性。语义上这跟发布-订阅没什么不同,订阅者是一群消费者而非一个单独的进程。

一个由两个服务器组成的Kafka集群,包括四个分区(P0-P3)和两个消费者组。消费者组A有两个实例,B有四个。
Kafka还提供了比传统消息系统更强的顺序保证。
一个传统的队列在服务器上顺序的保存消息,如果多个消费者消费队列里的消息,则服务器以消息被存储的顺序来分发消息。然而,尽管服务器顺序分发消息,因为消息是被已补分发到消费者,所以它们可能没按顺序抵达不同的消费者。这实际上意味着在并行消费时,消息的顺序会丢失。消息系统通常通过"唯一消费者"来提供变通,即只运行一个进程消费队列,显然这意味着不支持并行执行。
Kafka在这一点做的更好。通过并行的概念,即topic内的分区,Kafka同时提供了顺序保证以及消费者进程间的负载均衡。这是通过将topic内的分区分派给消费者组的消费者来实现的,每个分区只被消费者组内的一个消费者消费。由此,我们保证了某个消费者是某个分区的唯一读者,并且顺序消费数据。因为有很多分区,这就使得在很多消费者实例上仍然能保证均衡负载。但是注意,一个消费者组内的消费者不可以比分区更多。
Kafka只提供了一个分区内的消息顺序,而不是topic间的不同分区的顺序。每个分区的顺序性,加上基于key的数据分区能力对大部分应用是有效的。但是,如果你需要所有消息间的全体顺序,可以通过使每个topic只有一个分区来实现,这也意味着每个消费者组只支持一个消费者进程。
Guarantees
在高层次上,Kafka提供如下保证:
- 生产者发送到某个topic分区的消息将被有序追加。即,如果消息M1和M2是被同一个生产者发送的,并且M1先发送,则M1将有比M2更小的offset,且在log中出现的更早。
- 一个消费者实例看到的消息的顺序等同于它们在log中被存储的顺序。
- 对于一个复制因子为N的topic,我们可以容忍至多N-1个服务器失败而不会丢失任何已提交到log的消息。
1.2 Use Cases
这里列出一些流行的Apache Kafka用例。更多实战领域的概览,请参照 this blog post .Messaging
Kafka可取代传统的消息代理并工作的很好。有很多原因要使用消息代理(为了与数据生产者解耦,缓存未处理的消息等等)。与大部分消息系统相比,Kafka拥有更好的吞吐量,内建的分区,复制和容错能力,这使得Kafka成为大规模消息处理系统的优秀解决方案。
根据我们的经验,消息系统一般多为低吞吐,但可能要求更低的端对端延时,且经常依赖于健壮的持久性保证, Kafka提供了这些。在这个领域Kafka不亚于传统的消息系统如ActiveMQ或者RabbitMQ。
Website Activity Tracking
Kafka初始的用例是能够重建一个用户活动追踪管道,作为一系列实时的发布订阅feeds。这意味着站点活动(页面浏览,搜索或者用户进行的其他活动)被发布到集中的topics,其中每个活动类型一个topic。这些feeds可用于一系列用例的订阅,这些用例包括实时处理,实时监控以及加载到Hadoop或离线数据仓库系统进行离线处理和报告。
活动追踪多为很大数据量,因为针对每个用户pv都产生很多活动消息。
Metrics
Kafka常被用作运行监控数据。包括分布式应用的聚合统计,用来生产运行数据的集中feeds。Log Aggregation
许多人使用Kafka作为日志聚合解决方案的一个替代。典型的日志聚合整理从server上取下的物理log文件并将它们放置到一个中央区域(一个文件服务器或者HDFS)进行处理。Kafka抽象了文件的细节,并将log或者event data更简洁的抽象成一个消息流。这允许低延时的处理,并更易于支持多数据源及分布式数据消费。相比于以log为中心的系统,类似Scribe或者Flume,Kafka提供了同样的优异性能,由复制带来的更健壮的持久保证,以及更低的端对端延时。
Stream Processing
许多用户最终对数据进行多级处理,此时来自topic的原始数据被消费,然后进行聚合,再丰富,或者为了进一步的消费而转变成新的Kafka topics。例如,一个文章推荐的处理流可能会从RSS feeds来抓取文章内容,然后将其发布到"articles" topic;进一步的处理可以帮助文章内容进行规范化或者去重,并发布到一个面向更简洁的文章内容的topic;最后一步可以将这些内容匹配到用户。这创建了一幅由独立topics构成的实时数据流。Storm和Samza是实现这种转变的流行框架。Event Sourcing
事件溯源是一种应用设计风格,状态的转变被记录成时间顺序的记录序列。Kafka对很大容量日志 存储的支持,使其很适合作为以这种风格建造的应用的后端。Commit Log
Kafka可以为分布式系统起到一种外部的提交日志的作用。日志帮助复制节点间的数据,并为失败的节点充当同步机制以恢复它们的数据。Kafka的日志压缩特性可以起到该作用。在这种用途下,Kafka很类似于Apache BookKeeper项目。
1.3 Quick Start
本教程假设你从头开始,并且没有任何既存的Kafka或者ZooKeeper数据。
Step 1: Download the code
Download the 0.9.0.0 release and un-tar it.> tar -xzf kafka_2.11-0.9.0.0.tgz > cd kafka_2.11-0.9.0.0
Step 2: Start the server
Kafka使用ZooKeeper,所以如果你还没有的话,你需要首先启动一台ZooKeeper服务器。你可以使用随kafka发放的便捷脚本包来得到一个快速得到一个单节点ZooKeeper实例。
> bin/zookeeper-server-start.sh config/zookeeper.properties [2013-04-22 15:01:37,495] INFO Reading configuration from: config/zookeeper.properties (org.apache.zookeeper.server.quorum.QuorumPeerConfig) ...现在启动Kafka服务器:
> bin/kafka-server-start.sh config/server.properties [2013-04-22 15:01:47,028] INFO Verifying properties (kafka.utils.VerifiableProperties) [2013-04-22 15:01:47,051] INFO Property socket.send.buffer.bytes is overridden to 1048576 (kafka.utils.VerifiableProperties) ...
Step 3: Create a topic
让我创建一个单分区单副本的topic,命名为"test":> bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test现在我们可以通过运行list topic命令来查看这个topic:
> bin/kafka-topics.sh --list --zookeeper localhost:2181 test或者,除了手动创建topics以外,你还可以配置你的代理,让它在发布到一个不存在的topic时自动创建该topic。
Step 4: Send some messages
Kafka自带一个命令行客户端,可以从文件或者标准输入取得输入然后作为消息发送到Kafka集群。默认每行被当做独自的消息发送。
运行生产者(脚本),然后输入一些消息到控制台使其发送到服务器。
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test This is a message This is another message
Step 5: Start a consumer
Kafka也有一个命令行的消费者,可以将消息输出到标准输出上。
> bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning This is a message This is another message
如果你已经在不同的终端运行上面这些命令,你就可以在生产者终端输入消息,然后在消费者终端看到它们被打印出来。
所有的命令行工具都有额外的选项;不带参数的运行这些命令会显示更详细的使用信息。
Step 6: Setting up a multi-broker cluster
目前为止我们一直在单个代理商运行,不过这很无趣。对Kafka而言,单个单利只是一个大小为1的集群,因此无需过多更改就可以启动更多的代理实例。为了感触一下,让我们将集群扩展到3个节点(还是全都在我们的本地机器)。
首先我们为每个代理创建各自的config文件:> cp config/server.properties config/server-1.properties > cp config/server.properties config/server-2.properties现在编辑这些文件,设置以下属性:
config/server-1.properties:
broker.id=1
port=9093
log.dir=/tmp/kafka-logs-1
config/server-2.properties:
broker.id=2
port=9094
log.dir=/tmp/kafka-logs-2
broker.id属性各节点在集群中唯一且永久的名字。因为我们让这些代理都运行在同一台机器,所以我们必须修改端口号和日志目录,这样才能避免所有代理都注册到同一端口,否则他们的数据会互相覆盖。
我们已经启动了ZooKeeper和单节点的代理,所以只需再启动两个新的节点:> bin/kafka-server-start.sh config/server-1.properties & ... > bin/kafka-server-start.sh config/server-2.properties & ...现在创建一个复制因子为3的新的topic:
> bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 1 --topic my-replicated-topic
Ok了,但是既然我们是一个集群,我们怎样才能知道哪个代理在做什么呢?可以运行"describe topics"来查看:
> bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic my-replicated-topic Topic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs: Topic: my-replicated-topic Partition: 0 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0
现在解释一下输出。第一行给出了所有分区的总结,每个额外的行给出一个分区的信息。因为这个topic我们只有一个分区,所以只有额外的行只有一行。
- "leader" 是负责给定分区的读写的节点。每个节点都会是随机的一部分分区的leader。
- "replicas"是负责该分区的日志复制节点列表,无论该节点是否为leader,甚至无论它们是否还存活。
- "isr" 一个"in-sync"复制节点集合。这是复制节点列表的子集,这些节点都处于存活状态且被连接到leader。
注意在我的例子里,节点1是这个topic中唯一分区的leader。
我们可以针对我们创建的原始的topic运行该命令来看看它在哪里:
> bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic test Topic:test PartitionCount:1 ReplicationFactor:1 Configs: Topic: test Partition: 0 Leader: 0 Replicas: 0 Isr: 0
没什么惊喜,原始的topic没有任何副本,且在server 0上,即我们创建的集群中的唯一server。
让我们发布一些消息到我们的新的topic上:
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic my-replicated-topic ... my test message 1 my test message 2 ^C现在让我们消费这些消息:
> bin/kafka-console-consumer.sh --zookeeper localhost:2181 --from-beginning --topic my-replicated-topic ... my test message 1 my test message 2 ^C
现在让我们测试一下容错性。代理1正充当leader,所以我们杀掉它:
> ps | grep server-1.properties 7564 ttys002 0:15.91 /System/Library/Frameworks/JavaVM.framework/Versions/1.6/Home/bin/java... > kill -9 7564
其他的从属节点被选为Leader,并且节点1已经不在in-sync副本集合中:
> bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic my-replicated-topic Topic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs: Topic: my-replicated-topic Partition: 0 Leader: 2 Replicas: 1,2,0 Isr: 2,0
但是消息依然可供消费,尽管原来负责写入的leader已经挂掉:
> bin/kafka-console-consumer.sh --zookeeper localhost:2181 --from-beginning --topic my-replicated-topic ... my test message 1 my test message 2 ^C
Step 7: Use Kafka Connect to import/export data
在控制台写入数据并将其输出回控制台很适合练手,但是你可能想要使用来自其他源的数据,或者将数据从Kafka导出到其他系统。针对很多系统,你可以使用Kafka Connect来导入或者导出数据,而非编写自定义的数据集成代码。Kafka Connect 是Kafka包含的导入或导出数据到Kafka的工具。它是一个运行connectors的可扩展的工具,实现了与外部系统交互的定制逻辑。在这个quickstart中,我们将看到如何运行Kafka Connect提供的简单连接器来从一个文件导入数据到Kafka的topic,并将数据从Kafka的topic导出到一个文件。首先,我们从创建一些测试用的种子数据开始:
> echo -e "foo\nbar" > test.txt
接着,我们启动两个连接器,运行在单机模式,即他们运行在单个,本地,专用进程上。我们提供三个配置文件作为参数。第一个总是Kafka Connect进程的配置文件,包括共同配置例如要连接的Kafka代理,和数据的序列化格式等。生下来的两个文件每个详述一个要创建的连接器。这些文件包括一个唯一的连接器名,要初始化的连接器类,以及连接器所需的其他配置信息。
> bin/connect-standalone.sh config/connect-standalone.properties config/connect-file-source.properties config/connect-file-sink.properties
这些包含在Kafka中的样例配置文件,使用了我们稍早前启动的默认的本地集群配置,并创建了两个连接器:第一个是个source连接器,从一个输入文件读取行,并创建消息到Kafka的topic;第二个是个sink连接器,从Kafka topic读取消息,并转化为行写入到输出文件。在启动中你会看到一些日志消息,其中一些表明连接器正在初始化。一旦Kafka Connect启动完,source连接器将开始逐行读取test.txt并将它们生产到topic connect-test,而sink连接器开始从topic connect-test读取消息,并将它们写出到文件test.sink.txt。
我们可以通过检查输出文件的内容来验证数据已经传输了整个管道。
> cat test.sink.txt foo bar
注意数据被存储在Kafka的topic
connect-test上,
因此我们也可以运行一个命令行消费者去查看topic中的数据(或者使用自定义的消费者代码去处理它):
> bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic connect-test --from-beginning
{"schema":{"type":"string","optional":false},"payload":"foo"}
{"schema":{"type":"string","optional":false},"payload":"bar"}
...
连接器持续的处理数据,所以我们可以添加数据到文件,然后看它流过整个管道:
> echo "Another line" >> test.txt
你应当在命令行消费者的输出以及sink文件中看到这行。
1.4 Ecosystem
在主发布版外,有相当多的工具与Kafka互相整合。ecosystem page 列出了很多,包括流处理系统,Hadoop整合,监控,以及部署工具。
1.5 Upgrading From Previous Versions
Upgrading from 0.8.0, 0.8.1.X or 0.8.2.X to 0.9.0.0
0.9.0.0 has potential breaking changes (please review before upgrading) and an inter-broker protocol change from previous versions. For a rolling upgrade:- Update server.properties file on all brokers and add the following property: inter.broker.protocol.version=0.8.2.X
- Upgrade the brokers. This can be done a broker at a time by simply bringing it down, updating the code, and restarting it.
- Once the entire cluster is upgraded, bump the protocol version by editing inter.broker.protocol.version and setting it to 0.9.0.0.
- Restart the brokers one by one for the new protocol version to take effect
Note: If you are willing to accept downtime, you can simply take all the brokers down, update the code and start all of them. They will start with the new protocol by default.
Note: Bumping the protocol version and restarting can be done any time after the brokers were upgraded. It does not have to be immediately after.
Potential breaking changes in 0.9.0.0
- Java 1.6 is no longer supported.
- Scala 2.9 is no longer supported.
- Broker IDs above 1000 are now reserved by default to automatically assigned broker IDs. If your cluster has existing broker IDs above that threshold make sure to increase the reserved.broker.max.id broker configuration property accordingly.
- Configuration parameter replica.lag.max.messages was removed. Partition leaders will no longer consider the number of lagging messages when deciding which replicas are in sync.
- Configuration parameter replica.lag.time.max.ms now refers not just to the time passed since last fetch request from replica, but also to time since the replica last caught up. Replicas that are still fetching messages from leaders but did not catch up to the latest messages in replica.lag.time.max.ms will be considered out of sync.
- Configuration parameter log.cleaner.enable is now true by default. This means topics with a cleanup.policy=compact will now be compacted by default, and 128 MB of heap will be allocated to the cleaner process via log.cleaner.dedupe.buffer.size. You may want to review log.cleaner.dedupe.buffer.size and the other log.cleaner configuration values based on your usage of compacted topics.
- MirrorMaker no longer supports multiple target clusters. As a result it will only accept a single --consumer.config parameter. To mirror multiple source clusters, you will need at least one MirrorMaker instance per source cluster, each with its own consumer configuration.
- Tools packaged under org.apache.kafka.clients.tools.* have been moved to org.apache.kafka.tools.*. All included scripts will still function as usual, only custom code directly importing these classes will be affected.
- The default Kafka JVM performance options (KAFKA_JVM_PERFORMANCE_OPTS) have been changed in kafka-run-class.sh.
- The kafka-topics.sh script (kafka.admin.TopicCommand) now exits with non-zero exit code on failure.
- The kafka-topics.sh script (kafka.admin.TopicCommand) will now print a warning when topic names risk metric collisions due to the use of a '.' or '_' in the topic name, and error in the case of an actual collision.
- The kafka-console-producer.sh script (kafka.tools.ConsoleProducer) will use the new producer instead of the old producer be default, and users have to specify 'old-producer' to use the old producer.
- By default all command line tools will print all logging messages to stderr instead of stout.
Deprecations in 0.9.0.0
- Altering topic configuration from the kafka-topics.sh script (kafka.admin.TopicCommand) has been deprecated. Going forward, please use the kafka-configs.sh script (kafka.admin.ConfigCommand) for this functionality.
- The kafka-consumer-offset-checker.sh (kafka.tools.ConsumerOffsetChecker) has been deprecated. Going forward, please use kafka-consumer-groups.sh (kafka.admin.ConsumerGroupCommand) for this functionality.
- The kafka.tools.ProducerPerformance class has been deprecated. Going forward, please use org.apache.kafka.tools.ProducerPerformance for this functionality (kafka-producer-perf-test.sh will also be changed to use the new class).