MD5密码算法分析与实现
MD5(Message Digest Algorithm 5,信息摘要算法5),由Ron Rivest设计,该密码算法对输入的信息以512bit进行分组(以及初始化的4个32bit分组),每个分组又分为16个32bit的子分组。该16个子分组进行4轮循环处理后(与SHA相似),生成4个32bit的散列值即级联后为128位的散列值。
一、算法分析:
1、分组与填充:
首先填充与分组,消息的后面一个bit填充1,接着全部填充为0,使得信息长度为 :(N * 512 - 64)bit,留下的64bit用来填充为文件/消息的bit长度。即填充和保存长度以后,整个进行分组加密的长度为:(N * 512 - 64) +64bit=N*512bit。将填充后的消息进行分组,共N组,每组512bit。(关于分组与填充可参考: 单向散列函数SHA-1算法分析与实现 )
2、循环处理:
N个分组按顺序进行操作,每一组的操作函数输入有三部分,输出有一部分:
输入:
①分组信息:512bit信息的16个子分组M0~M15(Mi);
②上一组输出的散列值:上一组输出的128bit散列值(4个32bit分组A、B、C、D)作为本组的另一部分输入。
③和循环步骤有关的Ti:Ti = 2^32 * abs(sin(i)) 的整数部分,i为弧度(i从1~64)。作为第三部分输入。
输出:
128bit的散列值。(如果是最后一个分组,则是最终MD5散列值,不是最后一个分组,则是下一个512bit分组的输入)。
每一个512bit都有的四轮循环(MD4是3轮),其循环过程如下:
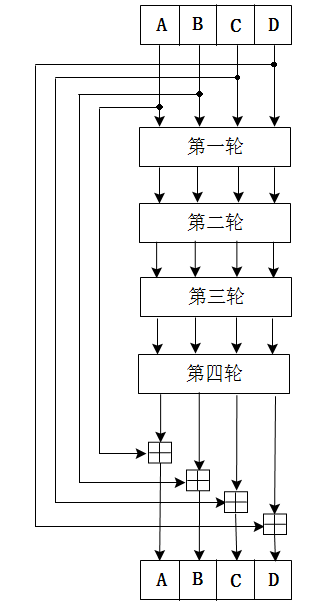
A += loop(A);
B += loop(B);
C += loop(C);
D += loop(D);
3、单步处理的过程:
而每一轮循环中分为16步(4轮64步),每一次操作的过程如下所示:
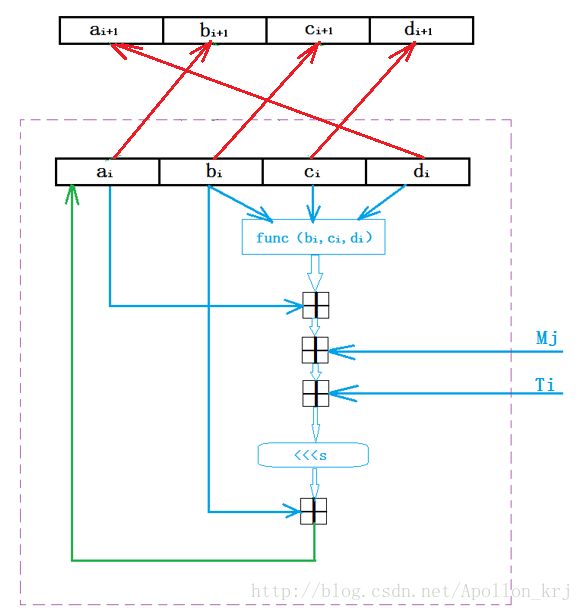
这十六步则是虚线框内步骤的16次重复:
①ai = bi + [(func(ai,bi,ci) + ai + Mj + Ti) <<< s],i从0~63线性增加,j是非线性变化。Mj =M[j],Ti = 2^32 * abs(sin(i)) 。
②ai+1 = di;
③bi+1 = ai;
④ci+1 = bi;
⑤di+1 = ci;
⑥下一步ai+1、bi+1、ci+1、di+1作为新的输入,继续以上步骤共执行64次。
其中:
a0 = A;
b0 = B;
c0 = C;
d0 = D;
每一组的初始的a0、b0、c0、d0都是由4个散列分组ABCD赋值的。ABCD是上一组的输出散列值,第一组不存在上一组,初始值为:
A = 0X01234567
B = 0X89ABCDEF
C = 0XFEDCBA98
D = 0X76543210
四轮循环的步骤都是一样的,区别在于func(a,b,c)的形式、循环左移s位的位数、以及Mj、Ti的值的不同(Ti和步骤i有关,上面已经给出公式)。不同的Mj、不同的s与不同的函数分别如下:
第一轮(16步):
①func(X,Y,Z) = (X & Y) | (~X & Z)
②Mj = M[i],(i,j均为0~15线性增加。Mj的j是步数,M[i]的i是16组的子分组索引),这16步是线性变化的。
③s是7、12、17、22的循环使用。第二轮(16步):
①func(X,Y,Z) = (X & Z) | (Y & ~Z)
②index(Mj) = [index(Mj-1) + 5] % 16。设Mj的索引p,Mj-1索引为q,则p = (q + 5) % 16,即Mj = M[p] = M[(q+5) mod 16],其中M0 = M[1]。
∴M0~M15: M[1]、M[6]、M[11]、M[0]、M[5]、M[10]、M[15]、M[4]、M[9]、M[14]、M[3]、M[8]、M[13]、M[2]、M[7]、M[12]
③s是5、9、14、20的循环使用。第三轮(16步):
①func(X,Y,Z) = X ^ Y ^ Z
②index(Mj) = [index(Mj-1) + 3] % 16**。**其中M0 = M[5]。
③s是4、11、16、23的循环使用。第四轮(16步):
①func(X,Y,Z) = Y ^ (X | ~Z)
②index(Mj) = [index(Mj-1) + 7] % 16**。**其中M0 = M[0]。
③s是6、10、15、21的循环使用。
二、算法实现:
由于64步中Mj、Ti、s、func()都不尽相同。则在编写程序时直接将Mj的索引、Ti的值、s直接计算出来再进行函数调用,而func()只有四个,则用四个函数分别实现。即调用过程为:
func_1();//16次调用,每次的参数都不一样,直接给出来
func_2();//16次调用
func_3();//16次调用
func_4();//16次调用
具体的功能代码如下所示:
/*
*Mail:[email protected]
*Author:Kangruojin
*Time:2017年7月21日13:00:36
*Version:V1.1
*/
#include "md5.h"
void md5_algroithm(char const * file)
{
unsigned char plaintext[64] = {0}; //用来接收文件中读取的一个512bit的分组
FILE * fp = fopen(file, "r");//打开文件
assert(fp != NULL);
MD5STR md5;//定义结构体变量,结构体保存散列值和文件长度
fseek(fp, 0, SEEK_END);
size_t len = ftell(fp);
fseek(fp, 0, SEEK_SET);
md5_init(&md5, len);//获取文件长度,初始化结构体
while(!feof(fp)){//每次读取一个分组,没到文件末尾则继续读取
len = fread(plaintext, 64, 1, fp);
if(!feof(fp)){//未到文件末尾
md5_calcHashValue(&md5, plaintext);//文件还未读取完毕,则直接处理,不需要补位
}
else{
//文件读取完毕则需要补位处理
len = strlen((const char *)plaintext);//因为到文件尾时,返回的是0,而不是读取到的字节个数
md5_padding(&md5, plaintext, len);//补位函数中直接调用处理函数,则返回值跳出循环
break;
}
memset(plaintext, 0, 64);//每次分组处理完毕,缓冲区清零
}
md5_showHashValue(&md5);//输出散列值
fclose(fp);
}
void md5_showHashValue(MD5STR * md5)
{
for(int i = 0; i < 4; i++){
//从低地址到高地址依次输出
printf("%02x",((uint8 *)(md5->state))[i*4 + 0]);
printf("%02x",((uint8 *)(md5->state))[i*4 + 1]);
printf("%02x",((uint8 *)(md5->state))[i*4 + 2]);
printf("%02x",((uint8 *)(md5->state))[i*4 + 3]);
}
printf("\n");
}
void md5_init(MD5STR * md5, uint32 len)
{
md5->length[1] = 0;
//字节数乘以8为bit数
md5->length[0] = len << 3;
md5->length[1] = len >> 29;
//散列值初始化,注意值的存放方式
md5->state[0] = 0X67452301;
md5->state[1] = 0XEFCDAB89;
md5->state[2] = 0X98BADCFE;
md5->state[3] = 0X10325476;
}
void md5_padding(MD5STR * md5, unsigned char * data, uint32 len)
{
if(len < 56){//信息长度小于56则不用增加新分组
data[len] |= 0X80;//补1
for(int i = 0; i < 8; i++){
data[i + 56] = ((uint8 *)(md5->length))[i];//填充长度信息,数据高位放在高地址(小端)
}
md5_calcHashValue(md5, data);//填充完毕后计算散列值
}
else{//大于等于56需要增加新分组
unsigned char * newData = (unsigned char *)malloc(128);
if(newData == NULL){
perror("malloc at padding\n");
exit(EXIT_FAILURE);
}
memset(newData, 0, 128);
memcpy(newData, data, len);
newData[len] |= 0X80;
for(int i = 0; i < 8; i++){
newData[i + 120] = ((uint8 *)(md5->length))[i];
}
md5_calcHashValue(md5, newData);//包含数据信息的分组
md5_calcHashValue(md5, newData + 64);//包含长度信息的新增加的分组
free(newData);//内存释放
}
}
void md5_calcHashValue(MD5STR * md5, unsigned char * data)
{
uint32 m[16] = {0};
calcM(m, data);//根据输入的512bit进行Mj的自分组计算
//初始化a、b、c、d(前一组的散列值输出,或最初始的ABCD)
uint32 a = md5->state[0];
uint32 b = md5->state[1];
uint32 c = md5->state[2];
uint32 d = md5->state[3];
/*
*第一轮
*①func(X,Y,Z) = (X & Y) | (~X & Z)
*②Mj = M[i]
*③s=7、12、17、22。
*/
FirstRound(a, b, c, d, m[ 0], 7, 0xd76aa478); //64个Ti直接计算出来,而不是让计算机根据公式再去计算
FirstRound(d, a, b, c, m[ 1], 12, 0xe8c7b756);
FirstRound(c, d, a, b, m[ 2], 17, 0x242070db);
FirstRound(b, c, d, a, m[ 3], 22, 0xc1bdceee);
FirstRound(a, b, c, d, m[ 4], 7, 0xf57c0faf);
FirstRound(d, a, b, c, m[ 5], 12, 0x4787c62a);
FirstRound(c, d, a, b, m[ 6], 17, 0xa8304613);
FirstRound(b, c, d, a, m[ 7], 22, 0xfd469501);
FirstRound(a, b, c, d, m[ 8], 7, 0x698098d8);
FirstRound(d, a, b, c, m[ 9], 12, 0x8b44f7af);
FirstRound(c, d, a, b, m[10], 17, 0xffff5bb1);
FirstRound(b, c, d, a, m[11], 22, 0x895cd7be);
FirstRound(a, b, c, d, m[12], 7, 0x6b901122);
FirstRound(d, a, b, c, m[13], 12, 0xfd987193);
FirstRound(c, d, a, b, m[14], 17, 0xa679438e);
FirstRound(b, c, d, a, m[15], 22, 0x49b40821);
/*第二轮
*①func(X,Y,Z) = (X & Z) | (Y & ~Z)
*②index(Mj) = [index(Mj-1) + 5] % 16,其中M0 = M[1]
*③s = 5、9、14、20
*/
SecondRound(a, b, c, d, m[ 1], 5, 0xf61e2562);
SecondRound(d, a, b, c, m[ 6], 9, 0xc040b340);
SecondRound(c, d, a, b, m[11], 14, 0x265e5a51);
SecondRound(b, c, d, a, m[ 0], 20, 0xe9b6c7aa);
SecondRound(a, b, c, d, m[ 5], 5, 0xd62f105d);
SecondRound(d, a, b, c, m[10], 9, 0x02441453);
SecondRound(c, d, a, b, m[15], 14, 0xd8a1e681);
SecondRound(b, c, d, a, m[ 4], 20, 0xe7d3fbc8);
SecondRound(a, b, c, d, m[ 9], 5, 0x21e1cde6);
SecondRound(d, a, b, c, m[14], 9, 0xc33707d6);
SecondRound(c, d, a, b, m[ 3], 14, 0xf4d50d87);
SecondRound(b, c, d, a, m[ 8], 20, 0x455a14ed);
SecondRound(a, b, c, d, m[13], 5, 0xa9e3e905);
SecondRound(d, a, b, c, m[ 2], 9, 0xfcefa3f8);
SecondRound(c, d, a, b, m[ 7], 14, 0x676f02d9);
SecondRound(b, c, d, a, m[12], 20, 0x8d2a4c8a);
/*
*第三轮:
*①func(X,Y,Z) = X ^ Y ^ Z
*②index(Mj) = [index(Mj-1) + 3] % 16,其中M0 = M[5]
*③s=4、11、16、23
*/
ThirdRound(a, b, c, d, m[ 5], 4, 0xfffa3942);
ThirdRound(d, a, b, c, m[ 8], 11, 0x8771f681);
ThirdRound(c, d, a, b, m[11], 16, 0x6d9d6122);
ThirdRound(b, c, d, a, m[14], 23, 0xfde5380c);
ThirdRound(a, b, c, d, m[ 1], 4, 0xa4beea44);
ThirdRound(d, a, b, c, m[ 4], 11, 0x4bdecfa9);
ThirdRound(c, d, a, b, m[ 7], 16, 0xf6bb4b60);
ThirdRound(b, c, d, a, m[10], 23, 0xbebfbc70);
ThirdRound(a, b, c, d, m[13], 4, 0x289b7ec6);
ThirdRound(d, a, b, c, m[ 0], 11, 0xeaa127fa);
ThirdRound(c, d, a, b, m[ 3], 16, 0xd4ef3085);
ThirdRound(b, c, d, a, m[ 6], 23, 0x04881d05);
ThirdRound(a, b, c, d, m[ 9], 4, 0xd9d4d039);
ThirdRound(d, a, b, c, m[12], 11, 0xe6db99e5);
ThirdRound(c, d, a, b, m[15], 16, 0x1fa27cf8);
ThirdRound(b, c, d, a, m[ 2], 23, 0xc4ac5665);
/*
*第四轮:
*①func(X,Y,Z) = Y ^ (X | ~Z)
*②index(Mj) = [index(Mj-1) + 7] % 16,其中M0 = M[0]。
*③s=6、10、15、21、。
*/
LastRound(a, b, c, d, m[ 0], 6, 0xf4292244);
LastRound(d, a, b, c, m[ 7], 10, 0x432aff97);
LastRound(c, d, a, b, m[14], 15, 0xab9423a7);
LastRound(b, c, d, a, m[ 5], 21, 0xfc93a039);
LastRound(a, b, c, d, m[12], 6, 0x655b59c3);
LastRound(d, a, b, c, m[ 3], 10, 0x8f0ccc92);
LastRound(c, d, a, b, m[10], 15, 0xffeff47d);
LastRound(b, c, d, a, m[ 1], 21, 0x85845dd1);
LastRound(a, b, c, d, m[ 8], 6, 0x6fa87e4f);
LastRound(d, a, b, c, m[15], 10, 0xfe2ce6e0);
LastRound(c, d, a, b, m[ 6], 15, 0xa3014314);
LastRound(b, c, d, a, m[13], 21, 0x4e0811a1);
LastRound(a, b, c, d, m[ 4], 6, 0xf7537e82);
LastRound(d, a, b, c, m[11], 10, 0xbd3af235);
LastRound(c, d, a, b, m[ 2], 15, 0x2ad7d2bb);
LastRound(b, c, d, a, m[ 9], 21, 0xeb86d391);
//4轮64步完毕后更新散列值缓冲区
md5->state[0] += a;
md5->state[1] += b;
md5->state[2] += c;
md5->state[3] += d;
}
void calcM(uint32 * m, unsigned char * data)
{
int i = 0;
int j = 0;
for(i = 0; i < 16; i++){
//低位->低位
m[i] = data[j + 0]
| (data[j + 1] << 8)
| (data[j + 2] << 16)
| (data[j + 3] << 24);
j += 4;
}
}
void FirstRound(uint32 &a, uint32 b, uint32 c, uint32 d, uint32 mj, uint8 s, uint32 ti)
{
uint32 tmp = (b & c) | ((~b) & d);//第一轮F函数
tmp += a + mj + ti;
a = b + ((tmp << s) | (tmp >> (32-s)));//循环左移s位
}
void SecondRound(uint32 &a, uint32 b, uint32 c, uint32 d, uint32 mj, uint8 s, uint32 ti)
{
uint32 tmp = (b & d) | (c & (~d));//第二轮F函数
tmp += a + mj + ti;
a = b + ((tmp << s) | (tmp >> (32-s)));
}
void ThirdRound(uint32 &a, uint32 b, uint32 c, uint32 d, uint32 mj, uint8 s, uint32 ti)
{
uint32 tmp = b ^ c ^ d;//第三轮F函数
tmp += a + mj + ti;
a = b + ((tmp << s) | (tmp >> (32-s)));
}
void LastRound(uint32 &a, uint32 b, uint32 c, uint32 d, uint32 mj, uint8 s, uint32 ti)
{
uint32 tmp = c ^ (b | (~d));//第四轮F函数
tmp += a + mj + ti;
a = b + ((tmp << s) | (tmp >> (32-s)));
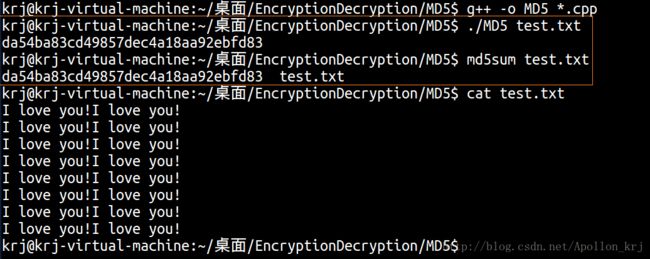
}测试(对于tes.txt的散列值计算和Linux自带的md5sum命令计算的结果一致):
参考资料:《应用密码学–协议算法与C源程序》[美]Bruce Schneier著 ,机械工业出版社。