Kafka+Zookeeper集群搭建
Kafka+Zookeeper集群搭建
1、介绍
Apache kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,是消息中间件的一种,用于构建实时数据管道和流应用程序
2、安装前看官方文档(2.0.0版本)
学习一门技术,从官网入手是了解和学习最快的方法。
2.1 Kafka(2.0.0)
官方下载路径:http://kafka.apache.org/downloads
官方网站:http://kafka.apache.org/
推荐官方文档:https://kafka.apache.org/documentation/#configuration
中文文档:https://www.orchome.com/kafka/index
2.2 Zookeeper(3.5.5)
官方镜像下载路径:http://mirror.bit.edu.cn/apache/zookeeper/
官方网站:https://zookeeper.apache.org/
推荐官方文档:https://zookeeper.apache.org/doc/r3.5.5/
中文文档:https://blog.csdn.net/java_66666/article/details/81015302
主要要了解各组件的兼容性和硬件的兼容性。服务器的型号版本。在安装最新版本的集群时主要数据各组件的兼容性版本号要一致。以及版本的稳定性。
3 基础环境准备
本系统为RedHat7.5 ;如果已经搭建过其他集群可省略。
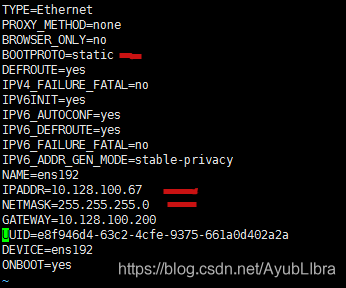
3.1 静态IP设置(每个节点)
vim /etc/sysconfig/network-scripts/ifcfg-ens192
service network restart
重启网络生效
3.2 编辑 /etc/hosts文件(每个节点)
vim /etc/hosts

3.3 关闭防火墙、禁止防火墙开启自启(每个节点)
systemctl stop firewalld 关闭防火墙
systemctl disable firewalld 禁止防火墙开机自启
vim /etc/selinux/config —> SELINUX=disabled (修改)
※如果不关闭,集群各节点间一定要相互添加白名单。但是外部无法访问。
– 列出zone truste的白名单
firewall-cmd --permanent --zone=trusted --list-sources
– 增加 192.168.100.* 网段到zone trusted(信任)
firewall-cmd --permanent --zone=trusted --add-source=ip
– 添加后需要重新加载
firewall-cmd --reload
SSH免密登陆(主节点)
ssh-keygen
然后三个回车,出现如下
复制公钥到其他节点
ssh-copy-id -i ~/.ssh/id_rsa.pub root@bigdata02
注意:
如果执行上面的命令如果出现.ssh目录不存在。
需要去其他节点执行ssh localhost
3.5 配置NTP 服务(所有节点)
统一时区: ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
安装ntp: yum -y install ntp
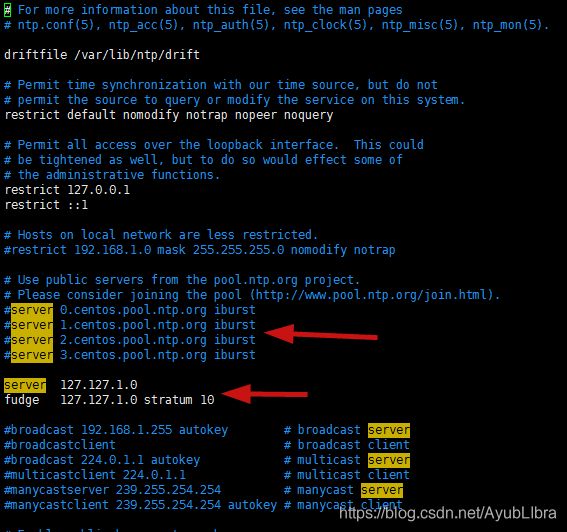
主节点配置: vim /etc/ntp.conf 参考如下图配置
主节点:
server 127.127.1.0
fudge 127.127.1.0 stratum 10
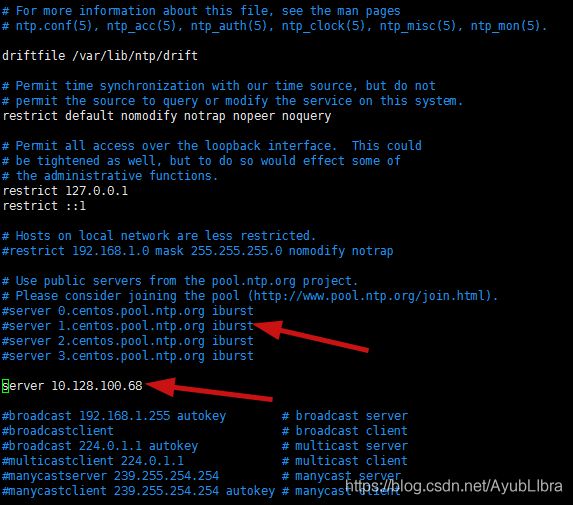
从节点:bigdata02/ip
配置完重新启动ntp服务:service ntpd restart
设置开机自启:systemctl enable ntpd.service
查看当前同步的时间服务器:ntpq -p
出现如下图代表配置正确。

3.6 JDK安装(所有节点)
查询已安装的java: rpm -qa | grep java
卸载openJava (.noarch可以不用卸载)
rpm -e --nodeps java-1.8.0-openjdk-headless-1.8.0…
安装JDK1.8版本以上
然后在/etc/profile 下配置环境变量。在执行
source /etc/profile
4 Zookeeper集群的安装
(1)下载Zookeeper安装包。
https://zookeeper.apache.org/releases.html#download
下载Zookeeper:apache-zookeeper-3.5.5-bin.tar.gz
(2)规划安装路径和数据目录。
/export/servers/
/data/zookeeper/data /data/zookeeper/logs
(3)通过xftp上传到指定目录安装包解压
tar -zxvf apache-zookeeper-3.5.5-bin.tar.gz -C /export/servers
(4)重新命名zookeeper
mv apache-zookeeper-3.5.5 zookeeper
4.1 修改配置文件(至少三节点)
1、进入/data/zookeeper/data的目录下。主要进行创建myid文件。
注意整个集群的myid都要不相同。
cd /data/zookeeper/data
vim myid #1,2,3...
![]()
2、进入/export/servers/zookeeper/conf目录,将zoo.simp.cfg文件改名为
mv zoo.simp.cfg zoo.cfg

参数解释:
tickTime:发送心跳的间隔时间,单位:毫秒dataDir:zookeeper保存数据的目录。clientPort:客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求。initLimit: 这个配置项是用来配置 Zookeeper 接受客户端(这里所说的客户端不是用户连接 Zookeeper服务器的客户端,而是 Zookeeper 服务器集群中连接到 Leader 的Follower 服务器)初始化连接时最长能忍受多少个心跳时间间隔数。
当已经超过 10个心跳的时间(也就是 tickTime)长度后 Zookeeper 服务器还没有收到客户端的返回信息,那么表明这个客户端连接失败。
总的时间长度就是 10*2000=20 秒syncLimit:这个配置项标识 Leader 与 Follower 之间发送消息,请求和应答时间长度,最长不能超过多少个 tickTime 的时间长度,
总的时间长度就是 2*2000=4 秒server.A=B:C:D:其 中
A 是一个数字,表示这个是第几号服务器(myid);
B 是这个服务器的 ip地址;
C 表示的是这个服务器与集群中的 Leader 服务器交换信息的端口;
D 表示的是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的 Leader,
而这个端口就是用来执行选举时服务器相互通信的端口。如果是伪集群的配置方式,由于 B 都是一样,
所以不同的 Zookeeper 实例通信端口号不能一样,所以要给它们分配不同的端口号。
4.2 配置环境变量
vim /etc/profile

source /etc/profile
4.3 启动zookeeper(所有节点都要启动)
由于已经配置了环境变量可以通过环境变量运行。
zkServer.sh start
显示:Starting zookeeper ... STARTED 表示启动成功
执行完毕,可以通过执行
zkServer.sh status
提示了这个节点了角色follow/leader说明集群启动成功。
4.4 注意
主要是要创建myid文件,以及配置文件中需要指向这个id。
5. Kafka2.0.0安装(最少三个节点)
(1)下载kafka安装包。
访问http://kafka.apache.org/downloads 下载Kafka
Kafka_2.11-2.0.0.tar.gz
(2)规划安装路径和数据目录。
export/servers/
/data/kafka/logs
(3)通过xftp上传到指定目录安装包解压
tar -zxvf Kafka_2.11-2.0.0.tar.gz -C /export/servers
(4)重新命名kafka
mv Kafka_2.11-2.0.0.tar.gz kafka
5.1 修改配置文件
进入config目录server.properties的文件。
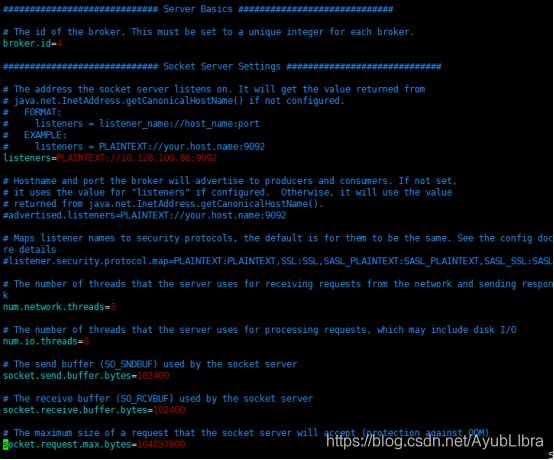

5.2 重要参数介绍
Broker.id: 1
#kafka当前节点的id
listeners=PLAINTEXT://10.128.100.86:9092
#监听IP和端口
log.dirs=/data/kafka/logs
#消息的存放目录
num.partitions=3
#分区的数目
offsets.topic.replication.factor=3
#偏移主题的复制因子
transaction.state.log.replication.factor=3
#事务主题的复制因子
transaction.state.log.min.isr=2
#重写了ISR
zookeeper.connect= 10.128.100.67:2181,10.128.100.68:2181,10.128.100.69:2181
#连接Zookeeper
zookeeper.connection.timeout.ms=6000
#连接超时
启动kafka(所有节点)
进入环境安装的目录/export/servers/kafka。
nohup bin/kafka-server-start.sh config/server.properties & #启动kafka
可以通过jps 命令查看java进程的启动。是否有kafka来查看进程是否启动成功。