用于图匹配和对象发现的挖掘与或图Mining And-Or Graphs for Graph Matching and Object Discovery
用于图匹配和对象发现的与或图挖掘

[声明:文章中公式较多,此编辑器不能识别公式,在编辑过程中公式图片丢失,故公式还请参考英文文献Mining And-Or Graphs for Graph Matching and Object Discovery]
摘要
本文在图匹配的技术基础上重新阐述了图挖掘理论,并将其应用范围扩展到计算机视觉。给定一组属性关系图(ARG),我们建议使用分层的And-Or图(AoG)来模拟嵌入在ARG中的最大尺寸公共子图的模式,并且我们开发一种通用方法来挖掘AoG模型 从未标记的ARGs。这种方法提供了从未注释的视觉数据挖掘层次模型而无需对对象进行穷举搜索的问题的一般解决方案。我们将我们的方法应用于RGB / RGB-D图像和视频,以展示其通用性和广泛的适用性。该代码将在https://sites.google.com/site/quanshizhang/mining-and-or-graphs上提供。
1.介绍
在本文中,我们重新定义图挖掘的概念,它最初是为从表格数据中发现频繁的实体关系而开发的,并重新制定其理论以解决计算机视觉中的问题。我们的理论旨在发现一种分层模式来表示嵌入在许多未注释的归因关系图(ARG)中的常见子图。这种图挖掘问题的理论解决方案可以在诸如对象发现和识别,场景理解等的不同视觉任务中具有广泛的应用。各种视觉数据(例如RGB / RGB-D图像和视频)可以表示为ARGs。每个ARG节点可以包含不同的一元属性以表示不同的高维局部特征。边上的成对属性测量对象部分之间的空间关系。我们定义一个分层的And-Or Graph(AoG)模型来表示一组ARG中的公共子图,如图1所示。顶部AND节点是一组OR节点的组合。每个OR节点描述本地部分,并且具有几个备选终端节点作为本地模式候选。
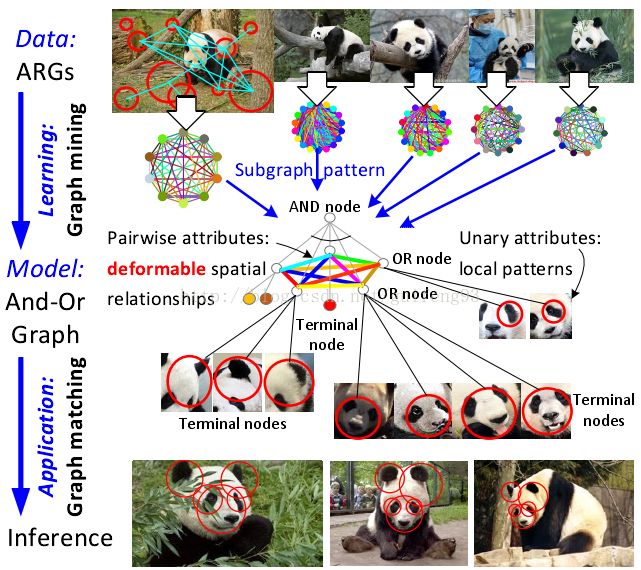
图1.And-Or图(AoG)。AoG模拟嵌入在ARG中的公共子图的规则性和变化性。顶部AND节点具有多个OR节点作为不同的对象部分。每个OR节点具有若干终端以表示替代的本地模式。AoG模型可以表示各种视觉数据,我们提出了一个RGB图像的例子。节点/边缘颜色表示高维一元/成对属性。
子图模式/一元属性:局部模式/成对属性:可变空间关系/ AND节点/ OR节点/终端节点/
任务:在这项研究中,我们的目标是从一些ARG(未标记数据)挖掘(学习)AoG(模型)。给定ARG和初始图模板,我们的方法逐渐将此模板修改为具有最大数量的OR节点的目标AoG。在图形挖掘过程中,我们发现新的OR节点和终端节点,删除冗余节点,更新属性和训练AoG的匹配参数。开采的AoG具有稳定的图匹配性能,可以用于以前看不到的ARG(图像或视频)中的对象推理。
这项研究扩展了图形匹配/挖掘和无监督学习两个领域的概念,这些概述如下。
图形匹配与挖掘:如图1所示。 1,图匹配可以看作是对象推理。它通过全局优化将小图形模板(模型)中的节点映射到目标ARG(例如图像)。
相反,图形挖掘从相反的角度呈现:当我们使用ARG来表示图像时,ARG中的公共子图对应于内部的共同对象。图挖掘被开发作为发现共同子图并为它们的原型模式建模以获得良好匹配性能的问题的理论解决方案。因此,这可以被认为是从未标记的数据学习可变形模型的一般方法。
在本研究中与传统的单层模式不同,我们定义了一个分层AoG用于建模子图模式的规则性和可变性。每个OR节点包含多个备选终端节点作为本地模式候选。此外,我们还将负(背景)ARG的概念纳入图挖掘的范围。我们有区别地学习AoG模型,专门包含在积极ARGs内。
优点:通用性,适用性和效率 在知识发现方面,我们的方法有以下优点。通用性:与面向某些特定类型的数据的技术不同,我们的方法可以应用于各种视觉数据(例如RGB / RGBD图像和视频)。人们可以使用自己的ARG贡献(特征)来表示这些视觉数据。
适用性:有必要开发一种技术,以同时处理所有类型的视觉变化广泛的适用性,这对现有的无人监管方法提出了巨大的挑战。在我们的方法中,考虑对象遮挡,并且纹理,滚动旋转,尺度和姿态的类内变化都可以被自动挖掘并且被形成为ARG中的属性变化。
效率:在大数据时代,挖掘效率已逐渐成为一个新的瓶颈。 我们提出一种近似但有效的方法来直接发现AoG模型,而不列举来自ARG的AoG节点。
贡献可概括如下:1)我们重新制定计算机视觉领域的图表挖掘理论。 特别地,我们提出了用于对子图模式建模的分层AoG。 2)我们要求模式完全由正ARG包含以确保其区分能力。 3)为了视觉知识发现的目的,我们提出了一种一般的图表挖掘方法,可以自动提取最大化AoG而不应用枚举策略。 4)我们的方法可以应用于各种类型的视觉数据。
2.相关工作
图挖掘:最初,“挖掘最大尺寸子图模式”的概念是在“标记图”的领域中发展起来的,例如最大频繁子图(MFS)提取[29]和最大碎片挖掘[33,36]。然而,这些方法要求人们手动地为图中的每个节点/边缘分配某个标签,或者基于本地一致性来确定一些图间节点对应候选。此外,它们通常对图挖掘应用耗时的节点枚举。因此,这些方法面向表格数据。
然而,对于表示视觉数据的ARG,挖掘理论应该在图匹配的技术基础上重新表述1(1不像图表挖掘定向到标记图,视觉ARG挖掘技术(如[39,41]和我们的)作为开始挖掘过程的初始图模板的不准确片段模式)。视觉ARG通常具有大的属性变化,并且不能以局部方式提供节点标签/对应。相反,两个ARG之间的匹配应该通过全局优化计算为二次分配问题(QAP)。[19,1]从图像估计共同对象或图结构,但他们没有提供一个通用的解决方案的图论。Zhang等人。[39,41]做了视觉ARG的图挖掘的开创性研究。相比之下,我们的方法更适合于视觉数据。与[39,41]中的单层模式不同,我们定义了一个分层的AoG来表示对象知识。此外,我们引入负ARG的概念,以确保模式的辨别能力。
学习图匹配:图像/图像匹配理论已经发展了几十年[24,5,6,35,12,28,4]。给定图形模板,学习图形匹配的方法通常训练参数或细化模板以实现稳定的匹配性能。它们中的大多数[3,2,18,30]是监督方法,即匹配分配必须标记用于训练。相比之下,无监督方法与图表挖掘更相关。Leordeanu 等人。[20]训练的属性权重,和Zhang等人。[40]以无监督的方式细化了模板结构。这些方法无法从未标记的图发现新节点。Yan等人。[35]发现图之间的公共节点对应,而不学习模型。
弱监督学习,协同分割和对象发现:弱监督模型学习的理论中的两个问题早已被忽视。首先,两个相互依赖的术语-对象相似性和部分相似性-通常不能在对象发现过程中同时测量。[22,7]从未标记的图像首先穷尽搜索对象候选,然后使用对象级相似候选的聚类来训练基于部分的模型。首先以局部方式从图像中提取频繁出现的部分,然后使用它们来定义共同的对象。相反,我们的理论以更令人信服的方式发现对象,即同时考虑部分相似性和全局对象结构。
第二,其他方法通常通过选择性地建模一些视觉变化并忽略其他方法来简化视觉敏锐的问题。例如,分割[14]和对象发现[32]主要基于纹理信息,难以发现适当地编码结构知识,而轮廓模型[16,34]关注几何形状和忽略纹理。相比之下,我们的分层AoG模型可以编码视觉数据中的不同变化。
和-或图:比较变形零件模型(DPM),分层AoG模型在其对象描述中具有更多的表达能力和更多的透明度。开拓性研究[25,31]都以监督的方式训练AoG。相反,我们建议直接挖掘这样的AoG而不标记对象边界框。

图2.各种视觉数据的ARG属性的表示。为了清楚起见,我们示出可能不包含所有节点的子ARG。
(图例翻译:
基于用于RGB-D图像的边缘段的ARG/基于用于RGB图像的中间层补丁的ARG/基于用于视频的SIFT点的ARG
一元属性:
1)3D线长度;2)线端子处的HOG特征;
1)HOG特征;
1)128维SIFT特征
成对属性:
1)两条线之间的3D角度;2)局部坐标系中中心线的方向和长度;
1)两个贴片之间的比例;2)中心线取向;3)每个贴片的中心线长度和标度之间的比率;
成对属性)
3.和-或图表示
ARG:如图3所示,ARG中是三元组
,其中和分别表示节点和边集。所有节点对完全连接以形成完整的图。
表示一元属性集合。每个节x都有个N一元属性。成对属性的集合
使用
成对属性分配每个边
。每个属性对应于特征向量。
属性(特征):对于不同的可视数据,我们可以使用不同的一元和成对属性来表示局部特征和空间关系。
例如,在我们的实验中,我们使用四种类型的ARG来表示三种视觉数据,包括RGB-D图像,RGB图像和视频。我们说明了图2中三种类型的ARG的属性设计。在这些ARG中,我们使用1)对象边缘的线段,2)自动学习中间层补丁,以及3)SIFT点作为图形节点。因此,它们的一元属性可以被定义为1)在线终端处提取的HoG特征的组合和线长度,2)中间块的HoG特征,以及3)128维SIFT特征。
因此,每个节点x1和x2之间的成对属性可以被定义为1)x1和x2的自己方向之间的角度,2)连接x1和x2的线的方向(即,x1的中心线和x2),3)中心线与x1和x2中的每一个之间的角度,4)x1和x2的比例之间的比率,以及5)中心线长度与每个节点的比例之间的比率。此外,人们可以为每个特定任务设计自己的属性。
AoG:类似地,分层AoG被定义为五元组G = (V, Ω, FV, FE, W)。AoG有三层。顶部AND节点具有一组OR节点s∈V。每个OR节点具有一组终端节点ψs∈Ωs。每个终端节点ψs具有Nu个属性。
表示终端节点的整体集合。我们连接所有OR节点对以形成完整的图。每个边包含Np个成对属性
(
4.推理:AoG的图匹配
AoG G和ARG之间的匹配用
表示。它在每个OR节点s∈V下选择一个终端节点ψs∈Ωs,并将ψs 映射到一个ARG节点xs∈V,给出为
。所有的映射分配由
表示。匹配过程可以被公式化为以下概率/能量函数的最大化/最小化。关于Ψ和x:
其中 的匹配概率/能量。总匹配能量由一元和成对匹配能量组成,即
。为了简化符号,我们使用
。匹配能量可以使用平方属性差来定义:
其中测量欧几里得距离。我们设计一个虚拟节点“none”来进行遮挡。当其在中的对应节点被遮蔽时,ψs被分配为无。
表示与无匹配的能量。
分别表示属性
的权重。匹配参数被设置为
。
我们使用OR节点的边缘匹配能量,由表示以评估s的局部匹配质量。
对于每个OR节点,我们对OR节点应用标准推理策略[25,31],即将其最佳端子ψs∈ Ωs匹配到使其一元匹配能量。
因此,节点对应关系(x,Ψ)由,这是典型的QAP。以局部方式选择最佳端点Ψ。可以通过MRF 关于{xs}的能量最小化来估计匹配分配x。我们使用TRW-S [15]进行能量最小化。
平均边缘能量:给定一组ARG和AoG G,我们将G与每个
相匹配,并获得其匹配分配
计算。G中每个OR节点的平均匹配质量可以通过其平均边缘能量来测量:
 图3. 图形匹配的符号
图3. 图形匹配的符号
5. 学习:图挖掘
5.1 目的
在本小节中,我们定义图挖掘的目标,它描述了AoG的最优状态,用于指导所有挖
我们目的是最大化正匹配的概率的概率之间的差距。同时,我们也考虑他的AoG的复杂性,以避免过度拟合。正匹配的概率可以表示为
因为OR节点的实质终端分割将增加过拟合的风险,所以我们使用图大小来定义AoG复杂度,这类似于[31]。
因此,我们可以重写(5)中的目标
其中对于每个OR节点,分别表示其在正负匹配中的边际能量。生成损失表示边际能量之间的差距,描述了G的辨别力。
AoG的综合挖掘包括1)确定ARG中的相应子图,2)发现新的OR节点和终端节点,3)消除冗余节点,4)属性估计,以及5)匹配参数的训练。因此,我们提出以下子目标,即对象(a-d),来训练这些术语。对象(a-d)或者最大化(5)中的目标的上述对数形式2.(2请参见补充材料的证明。)
首先,对象(a)使用当前模式呈现对象推理过程。它估计每个正/负图像中最可能的对象,即通过图匹配计算每个正/负ARG 的最佳匹配分配。使用这些匹配分配来定义边际能量
。
对象(a):,
第二,对于每个OR节点,我们使用以下等式来均匀优化其一元和成对属性以及其终端节点的除法。
对象(b):
这类似于稀疏表示。首先,我们通过扩大正匹配和负匹配之间的匹配能量差距来最小化生成损失,使得AoG属性可以表示完全由正ARG包含的模式。第二,我们使用复杂度损失来限制终端数量。我们简单地在所有实验中为所有类别设置λ= 1.0。
第三,我们需要将当前模式增长到最大尺寸,即,通过发现新的OR节点lVl和删除冗余的OR节点。提取具有最大数量的OR节点的AoG。因此,我们应用阈值来控制节点发现和消除。
对象(c):
最后,我们使用线性SVM来训练匹配参数W,其是(9)中生成性损失的微型化的近似解。
 图4.图表挖掘的近似解的流程图
图4.图表挖掘的近似解的流程图
5.2 流程图
如图4所示,我们设计一个EM流程图挖掘在(5)中定义的最优AoG。 在开始,我们需要标记一个大致对应于一个对象片段的初始图形模板G0。然后,该算法递归优化图形模式,并将OR节点的数量增加到最大值G0→G1→……→Gn= AoG。在对象(a-d)的基础上,我们定义了总共六个操作来构造EM流程图。 我们可以证明2这些操作导致(5)的近似但有效的解。
初始化:我们在正ARG中标记对象,以初始化图形模板G0。G0是一个特殊的AoG,其中每个OR节点包含一个终端节点。甚至不良的标签,例如, 一个与背景区域混合的对象片段,是可以接受的。然后我们在W 中初始化参数
操作1,图匹配:我们使用对象(a)将G与正和负ARG中的每一个相匹配。
操作2,属性估计:这是基于对象(b)我们将每个终端/边缘上的一元/成对属性近似为其在正ARG中的相应节点/边之间的平均属性。
操作3,节点消除:给定匹配结果,我们使用对象(c)来识别最差OR节点为,则节点
及其所有终端将从G中删除;否则,他们不是。
操作4,节点发现:节点发现旨在为G发现新的OR节点y。我们使用对象(b,c)同时1)确定y的终端节点Ωy,2)估计其属性,以及3)计算其匹配分配
。由于新节点y应当与中的大多数正ARG很好地匹配,为了简化计算,我们忽略y匹配为零的小可能性。基于这个假设,我们已经证明2一个近似解,1)提供y的正匹配分配
的粗略估计,以及2)最小化其他参数的不确定性:
类将这些点分组到几个集群。以这种方式,我们可以构造终端集Ω并使用每个终端节点ψs∈Ωs来表示集群,即,该集群中的每个ARG节点
,的一元属性对应于聚类中心。我们需要继续合并最近的簇,直到下面的能量最小化2。
其中
操作6,参数训练:这在方法(d)中定义。给定当前的匹配分配,我们应用[43]中的技术来训练W中的参数。
6.实验
我们的方法提供了一个可以应用于各种视觉数据的视觉挖掘解决方案。因此,为了测试算法的通用性,我们在四个实验中将我们的方法应用于三种视觉数据(即RGB-D图像,RGB图像和视频)。在这些实验中,我们从这些视觉数据挖掘了38个类别的对象模型(即AoGs)。挖掘模型可以用于1)从未标记的训练数据收集对象样本,以及2)匹配在先前未看见的视频帧/图像中的对象。因此,我们在图匹配和对象发现方面评估我们的方法。
因为我们的方法扩展了图形匹配,图形挖掘和弱监督学习领域的概念,我们全面比较了我们的方法与13个竞争方法。这些方法包括图像/图匹配方法,图匹配的无人监督学习,从视觉ARG挖掘的开创性方法,对象发现和共同分割方法。

图5.实验1中开采的AoGs的平均模式大小随着τ的值的增加而单调增加。
6.1 四个实验的设置
输入是未标记的RGB-D / RGB图像和视频。在四个实验中,我们分别使用四种类型的ARG来表示这些数据。每个RGB-D / RGB图像或视频帧被表示为ARG。然后,我们挖掘AoGs作为这些ARG的类别模型。在实验1,2和4中,AoG用于匹配测试图像和视频中的对象,在实验3中,我们关注在挖掘过程中的对象发现性能。详细的实验设置如下。
实验1:从RGB-D图像挖掘:我们将该方法应用于Kinect RGB-D图像数据库[40]中的五个类别-电子书PC,饮料盒,篮子,桶和簸箕,[41,42]作为基准数据集,以评估图匹配性能。如图2所示,用于RGB-D图像的ARG由[40]设计,其对于图匹配中的旋转和尺度变化是鲁棒的。[40]从图像中提取对象边缘,并将它们分成线段。这些线段用作ARG的节点。
我们在参数的不同设置下测试了我们的方法的图表挖掘性能。如[41,40],给定的每个值,我们遵循留一交叉验证的过程来评估挖掘性能:[41]已经为每个类别标记了一组初始图模板G0,我们执行了一个单独的模型挖掘过程,以使用这些模板中的每一个产生一个AoG。通过所有开采的AoGs的平均性能评估整体图形挖掘性能。
实验2,从未标记的RGB图像挖掘:我们使用[40]中引入的第二种类型的ARG表示RGB图像。就像RGB-D图像的ARG一样,RGB图像的ARG也采用边缘段作为节点。我们使用ETHZ形状类数据集[11],其中包含五个类别,即苹果标志,瓶子,长颈鹿,杯子和天鹅。我们随机选择2/3的图像进行训练,留下另外1/3的测试。
实验3,基于中间层补丁的ARG挖掘:我们挖掘来自SIVAL数据集[25]的25个类别和来自PASCAL07-6×2(训练)数据集的12个类别[8]。我们应用由[43]设计的ARGs用于更一般的RGB图像。我们使用[26]提取中间层的补丁作为ARG节点3(见图2)(3对于来自PASCAL07数据集的图像,[26]从许多区域候选中选择中间层补丁[21]。
在这个实验中,我们学习了一个混合模型,每个类别有三个AoG组件。因此,我们标记了三个初始模板来开始挖掘过程。此外,我们修改操作1以在每个挖掘迭代中将ARG分离成三个AoG,其为每个ARG分配其最佳匹配的AoG。
实验4,从视频序列挖掘:我们从互联网收集了三个视频序列(包括猎豹,游泳女孩和青蛙),并使用我们的方法挖掘AoGs从这些视频中的可变形对象。在该实验中,每个视频帧被表示为ARG。我们应用由[43]设计的ARG来表示视频帧(见图2)。这些ARG将SIFT特征点作为节点。
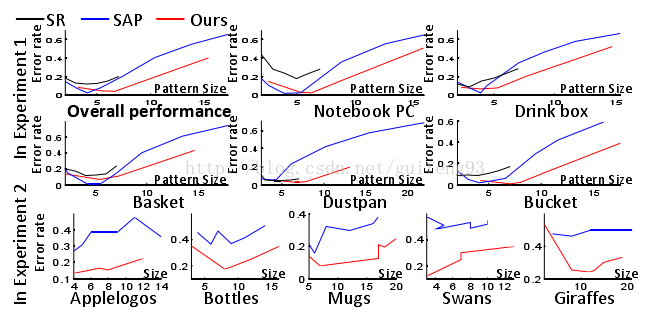
图6.平均错误匹配率。在实验1和2中,我们从RGB-D和RGB图像中挖掘基于边缘的子图案。我们的方法具有比其他基线更低的错误率。
6.2 基线
我们总共使用了十三种竞争方法。在图匹配和挖掘方面,七种方法遵循“学习模型或使用单个模板匹配对象”的场景。其他六种方法是最先进的对象发现和协同分割方法。
图匹配和挖掘:所有七种方法都提供相同的初始图形模板,以及相同的训练ARG和测试ARG集合,以确保公平的比较。
首先,我们将我们的方法与三个图像/图匹配方法进行比较。这些方法直接匹配图模板到没有训练的测试ARG。通常,存在用于图像匹配的两个典型范例。设计竞争方法MA以表示第一范例,即匹配能量的最小化。MA使用TRW-S[15]来最小化(1)中的匹配能量4。(4 这匹配两个没有分层结构的单层图形,这是(1)中Ψ≡1的能量的特殊情况。)然后,我们使用竞争方法MS和MT来表示第二范式,即最大化匹配兼容性。如在[17,20]中一样,匹配兼容性被定义为,其中它们使用绝对属性差来定义匹配能量。MS和MT分别使用光谱技术[17]和TRW-S[15]来计算
。
第二,我们将我们的方法与Leordeanu等人提出的图像匹配的无监督学习的基准进行比较[20]。基于[20] .LS和LT使用两种竞争方法,即LS和LT,来实现属性权重[17]和[15],分别,以解决在学习过程中的匹配优化。
第三,我们比较我们的方法[40],表示为SR。 SR通过删除“坏”节点来修改图模板的结构,但不涉及用于图挖掘的关键组件,即新模式节点的发现。
最后,我们将所提出的方法与较早的方法进行比较,该方法从视觉ARG挖掘软属性模式(SAP)。我们将初始化为unone,pnone和w作为初始化,以实现公平的比较。

图7.实验1中对象检测的AP。我们的方法在来自RGB-D图像的挖掘模型中表现更好。
对象发现和协同分割:每个模型挖掘中的操作1迭代可以被认为是对象发现的过程;因此,我们比较了挖掘AoG和六个最近的对象发现和协同分段方法之间的对象发现性能:显着性导向多类学习(bMCL)[44];一个最先进的对象发现方法[13](UnSL),其在Caltech-101[9]的子集上实现顶级性能(在纯度上测量约98%);前景共分段方法[14](MFC)两个多实例聚类方法BAMIC [38](具有最佳距离度量)和M3IC [37];以及在每个图像中通过[10]获得的最“显着”窗口的K均值聚类(称为SD,[44])。
6.3 评估指标,结果和分析
我们使用挖掘的AoGs在四个实验中匹配目标对象。图9示出了控制匹配结果的模式。参数控制模式大小5。(5对于在基线中使用的单层图模型,这是总节点数。对于我们的分层AoG,这是OR节点的数量。)图5示出了实验1中的值的尺寸变化。更大的值将产生更大的AoG。

图8.实验2和4中对象检测的AP。我们的方法从RGB图像和视频挖掘更好的模型。
图像/图匹配和挖掘方面的比较:我们使用以下两个指标来评估挖掘AoG的图匹配性能。首先,如在[42]中,使用误差匹配率(EMR)来测量匹配精度。当我们将AoG与正ARG匹配时,其错误率被定义为由AoG匹配但位于背景中的ARG节点的比例,即表示由AoG匹配的ARG节点的集合,并且
表示正确地定位在目标对象上的节点的子集。因此,给定AoG,在其所有的正匹配中计算其EMR。
第二,我们使用AoG来检测(匹配)多个先前未见的正和负ARG中的目标对象。我们使用最简单的方法来识别真假检测:给定阈值,如果匹配能量小于阈值6(6对于竞争方法MS,MT,LS,LT和SR,如果匹配兼容性大于阈值。),我们认为这是一个真正的检测;否则,它是错误检测。因此,我们可以通过选择不同的阈值绘制对象检测精确召回曲线。精确回忆曲线的平均精度(AP)被用作度量以评估基于匹配的对象检测。
图6比较了我们的方法与前两个实验中的七种竞争方法的错误率。注意,匹配性能是图案尺寸5的函数。具有太少节点的模式可能缺乏用于可靠匹配的足够信息,而太大模式可能包含不可靠节点,这降低了性能。SR方法不能产生大模式,因为它只是删除冗余节点,而没有发现新节点的能力。一般来说,我们的方法展示比竞争方法更低的匹配率。图6图7和图8显示了实验1,2和4中开采模式的AP。除了SR,SAP和我们的方法,其他竞争方法不能改变模式大小。如实验1中所述,我们使用不同的初始模板来为每个类别产生多个模型。因此,如图7所示,通过交叉验证计算图案大小和ER。我们的方法表现出优越的性能与竞争的方法。

图9.基于AoGs的匹配结果。我们绘制青蛙和猎豹模型的边缘连接,以显示其结构变形。
(图例翻译:在实验1中使用从RGB-D图像挖掘的AoG
使用从实验2中的RGB图像挖掘的AoGs
从实验3中的SIVAL数据集(第3行)和Pasca107数据集(第4行)中的RGB图像的对象发现
使用从实验4中的视频挖掘的AoG)
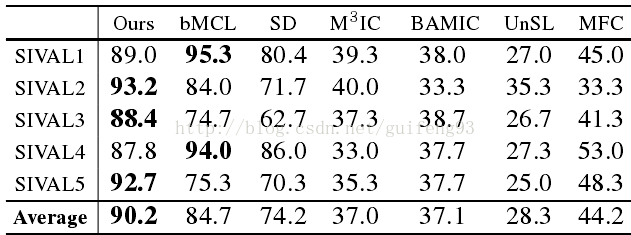
表1. SIVAL数据集中对象发现的平均纯度
表2. PASCAL07-6×2数据集中的平均本地化率
在共同分割和对象发现方面的比较:首先,我们在实验3中将我们的方法与六个对象发现和共分段方法进行比较。自动挖掘的类别模型可以用于从SVIAL数据集收集对象样本,考虑对象发现。如在对象发现工作[16,44]中,这样的对象集合被理解为未注释对象的聚类,并且聚类纯度被选择作为评估度量。我们把不同类别的模型作为聚类中心。对于数据集中的每个图像,我们使用所有模型来匹配此图像中的目标对象。我们将具有最低匹配能量的对象视为真实检测,并将其分配给其对应的群集。计算每个聚类的聚类纯度(背景对象被认为是不正确的样本)。注意[44]将数据集中的25个类别分别分为5个子组;即SIVAL1到SIVAL5。我们测量了每个这些亚组中的平均聚类纯度用于评价。请参见表1进行比较。我们的方法表现出更好的性能。
第二,使用平均本地化速率评估PASCAL07-6×2训练数据集中的对象发现性能。就像[22,7]中的“IOU>50%”标准,如果超过50%的检测到的补丁的中心在真正的对象边界框内,我们认为对象被正确定位。表2显示了平均定位率。我们的方法比MA(MA具有与我们相同的参数W)执行得更好。
7.讨论和结论
在本文中,我们通过定义一个通用形式的分层AoG模型来扩展图表挖掘理论,它代表了嵌入在正ARG中的公共子图。我们开发一个迭代框架来挖掘没有节点枚举的AoG模型。我们的方法发现新的OR节点和终端节点,删除冗余节点,估计属性和训练匹配参数。我们的方法的一般性和广泛的适用性通过一系列实验证明。
从模型学习的角度来看,我们的图挖掘理论有以下三个优点:1)AoG表示在建模对象中具有强表达力的分层可变形模板。 2)AoG可以开采而不标记对象位置。 3)我们不使用滑动窗口来枚举模型挖掘的对象候选。
在本文中,我们寻求探索这种新类型的图挖掘的一般理论解决方案,没有为特定的视觉任务的精心设计。然而,可以将任务特定的技术进一步添加到该挖掘平台以提高其性能。例如,我们可以为AoG设计根模板,并将其与非线性SVM组合。就像在[27],我们可以提取CNN特征的局部零件作为一元ARG属性。跟踪信息可用于指导从视频挖掘。