总结自论文:Faster_RCNN,与Pytorch代码:
本文主要介绍代码第二部分:model/ , 首先分析一些主要理论操作,然后在代码分析里详细介绍其具体实现。
首先在参考文章的基础上进一步详细绘制了模型的流程图。在 上一篇博客中介绍了模型的上半部分,本文将对模型的下半部分做一介绍。

Faster-RCNN流程图
1. roi_module.py


from collections import namedtuple from string import Template import cupy, torch import cupy as cp import torch as t from torch.autograd import Function from model.utils.roi_cupy import kernel_backward, kernel_forward Stream = namedtuple('Stream', ['ptr']) @cupy.util.memoize(for_each_device=True) def load_kernel(kernel_name, code, **kwargs): cp.cuda.runtime.free(0) code = Template(code).substitute(**kwargs) kernel_code = cupy.cuda.compile_with_cache(code) return kernel_code.get_function(kernel_name) CUDA_NUM_THREADS = 1024 def GET_BLOCKS(N, K=CUDA_NUM_THREADS): return (N + K - 1) // K class RoI(Function): """ NOTE:only CUDA-compatible """ def __init__(self, outh, outw, spatial_scale): self.forward_fn = load_kernel('roi_forward', kernel_forward) self.backward_fn = load_kernel('roi_backward', kernel_backward) self.outh, self.outw, self.spatial_scale = outh, outw, spatial_scale def forward(self, x, rois): # NOTE: MAKE SURE input is contiguous too x = x.contiguous() rois = rois.contiguous() self.in_size = B, C, H, W = x.size() self.N = N = rois.size(0) output = t.zeros(N, C, self.outh, self.outw).cuda() self.argmax_data = t.zeros(N, C, self.outh, self.outw).int().cuda() self.rois = rois args = [x.data_ptr(), rois.data_ptr(), output.data_ptr(), self.argmax_data.data_ptr(), self.spatial_scale, C, H, W, self.outh, self.outw, output.numel()] stream = Stream(ptr=torch.cuda.current_stream().cuda_stream) self.forward_fn(args=args, block=(CUDA_NUM_THREADS, 1, 1), grid=(GET_BLOCKS(output.numel()), 1, 1), stream=stream) return output def backward(self, grad_output): ##NOTE: IMPORTANT CONTIGUOUS # TODO: input grad_output = grad_output.contiguous() B, C, H, W = self.in_size grad_input = t.zeros(self.in_size).cuda() stream = Stream(ptr=torch.cuda.current_stream().cuda_stream) args = [grad_output.data_ptr(), self.argmax_data.data_ptr(), self.rois.data_ptr(), grad_input.data_ptr(), self.N, self.spatial_scale, C, H, W, self.outh, self.outw, grad_input.numel()] self.backward_fn(args=args, block=(CUDA_NUM_THREADS, 1, 1), grid=(GET_BLOCKS(grad_input.numel()), 1, 1), stream=stream ) return grad_input, None class RoIPooling2D(t.nn.Module): def __init__(self, outh, outw, spatial_scale): super(RoIPooling2D, self).__init__() self.RoI = RoI(outh, outw, spatial_scale) def forward(self, x, rois): return self.RoI(x, rois) def test_roi_module(): ## fake data### B, N, C, H, W, PH, PW = 2, 8, 4, 32, 32, 7, 7 bottom_data = t.randn(B, C, H, W).cuda() bottom_rois = t.randn(N, 5) bottom_rois[:int(N / 2), 0] = 0 bottom_rois[int(N / 2):, 0] = 1 bottom_rois[:, 1:] = (t.rand(N, 4) * 100).float() bottom_rois = bottom_rois.cuda() spatial_scale = 1. / 16 outh, outw = PH, PW # pytorch version module = RoIPooling2D(outh, outw, spatial_scale) x = t.autograd.Variable(bottom_data, requires_grad=True) rois = t.autograd.Variable(bottom_rois) output = module(x, rois) output.sum().backward() def t2c(variable): npa = variable.data.cpu().numpy() return cp.array(npa) def test_eq(variable, array, info): cc = cp.asnumpy(array) neq = (cc != variable.data.cpu().numpy()) assert neq.sum() == 0, 'test failed: %s' % info # chainer version,if you're going to run this # pip install chainer import chainer.functions as F from chainer import Variable x_cn = Variable(t2c(x)) o_cn = F.roi_pooling_2d(x_cn, t2c(rois), outh, outw, spatial_scale) test_eq(output, o_cn.array, 'forward') F.sum(o_cn).backward() test_eq(x.grad, x_cn.grad, 'backward') print('test pass')
主要利用cupy实现ROI Pooling的前向传播和反向传播。NMS和ROI pooling利用了:cupy和chainer ,没用过,占个坑先。
其主要任务是对于一张图象得到的feature map(512, w/16, h/16),然后利用sample_roi的bbox坐标去在特征图上裁剪下来所有roi对应的特征图(训练:128, 512, w/16, h/16)、(测试:300,512,w/16,h/16)。
2 . region_proposal_network.py
import numpy as np from torch.nn import functional as F import torch as t from torch import nn from model.utils.bbox_tools import generate_anchor_base from model.utils.creator_tool import ProposalCreator class RegionProposalNetwork(nn.Module): """Region Proposal Network introduced in Faster R-CNN. This is Region Proposal Network introduced in Faster R-CNN [#]_. This takes features extracted from images and propose class agnostic bounding boxes around "objects". .. [#] Shaoqing Ren, Kaiming He, Ross Girshick, Jian Sun. \ Faster R-CNN: Towards Real-Time Object Detection with \ Region Proposal Networks. NIPS 2015. Args: in_channels (int): The channel size of input. mid_channels (int): The channel size of the intermediate tensor. ratios (list of floats): This is ratios of width to height of the anchors. anchor_scales (list of numbers): This is areas of anchors. Those areas will be the product of the square of an element in :obj:`anchor_scales` and the original area of the reference window. feat_stride (int): Stride size after extracting features from an image. initialW (callable): Initial weight value. If :obj:`None` then this function uses Gaussian distribution scaled by 0.1 to initialize weight. May also be a callable that takes an array and edits its values. proposal_creator_params (dict): Key valued paramters for :class:`model.utils.creator_tools.ProposalCreator`. .. seealso:: :class:`~model.utils.creator_tools.ProposalCreator` """ def __init__( self, in_channels=512, mid_channels=512, ratios=[0.5, 1, 2], anchor_scales=[8, 16, 32], feat_stride=16, proposal_creator_params=dict(), ): super(RegionProposalNetwork, self).__init__() self.anchor_base = generate_anchor_base( anchor_scales=anchor_scales, ratios=ratios) self.feat_stride = feat_stride self.proposal_layer = ProposalCreator(self, **proposal_creator_params) n_anchor = self.anchor_base.shape[0] self.conv1 = nn.Conv2d(in_channels, mid_channels, 3, 1, 1) self.score = nn.Conv2d(mid_channels, n_anchor * 2, 1, 1, 0) self.loc = nn.Conv2d(mid_channels, n_anchor * 4, 1, 1, 0) normal_init(self.conv1, 0, 0.01) normal_init(self.score, 0, 0.01) normal_init(self.loc, 0, 0.01) def forward(self, x, img_size, scale=1.): """Forward Region Proposal Network. Here are notations. * :math:`N` is batch size. * :math:`C` channel size of the input. * :math:`H` and :math:`W` are height and witdh of the input feature. * :math:`A` is number of anchors assigned to each pixel. Args: x (~torch.autograd.Variable): The Features extracted from images. Its shape is :math:`(N, C, H, W)`. img_size (tuple of ints): A tuple :obj:`height, width`, which contains image size after scaling. scale (float): The amount of scaling done to the input images after reading them from files. Returns: (~torch.autograd.Variable, ~torch.autograd.Variable, array, array, array): This is a tuple of five following values. * **rpn_locs**: Predicted bounding box offsets and scales for \ anchors. Its shape is :math:`(N, H W A, 4)`. * **rpn_scores**: Predicted foreground scores for \ anchors. Its shape is :math:`(N, H W A, 2)`. * **rois**: A bounding box array containing coordinates of \ proposal boxes. This is a concatenation of bounding box \ arrays from multiple images in the batch. \ Its shape is :math:`(R', 4)`. Given :math:`R_i` predicted \ bounding boxes from the :math:`i` th image, \ :math:`R' = \\sum _{i=1} ^ N R_i`. * **roi_indices**: An array containing indices of images to \ which RoIs correspond to. Its shape is :math:`(R',)`. * **anchor**: Coordinates of enumerated shifted anchors. \ Its shape is :math:`(H W A, 4)`. """ n, _, hh, ww = x.shape anchor = _enumerate_shifted_anchor( np.array(self.anchor_base), self.feat_stride, hh, ww) n_anchor = anchor.shape[0] // (hh * ww) h = F.relu(self.conv1(x)) rpn_locs = self.loc(h) # UNNOTE: check whether need contiguous # A: Yes rpn_locs = rpn_locs.permute(0, 2, 3, 1).contiguous().view(n, -1, 4) rpn_scores = self.score(h) rpn_scores = rpn_scores.permute(0, 2, 3, 1).contiguous() rpn_fg_scores = \ rpn_scores.view(n, hh, ww, n_anchor, 2)[:, :, :, :, 1].contiguous() rpn_fg_scores = rpn_fg_scores.view(n, -1) rpn_scores = rpn_scores.view(n, -1, 2) rois = list() roi_indices = list() for i in range(n): roi = self.proposal_layer( rpn_locs[i].cpu().data.numpy(), rpn_fg_scores[i].cpu().data.numpy(), anchor, img_size, scale=scale) batch_index = i * np.ones((len(roi),), dtype=np.int32) rois.append(roi) roi_indices.append(batch_index) rois = np.concatenate(rois, axis=0) roi_indices = np.concatenate(roi_indices, axis=0) return rpn_locs, rpn_scores, rois, roi_indices, anchor def _enumerate_shifted_anchor(anchor_base, feat_stride, height, width): # Enumerate all shifted anchors: # # add A anchors (1, A, 4) to # cell K shifts (K, 1, 4) to get # shift anchors (K, A, 4) # reshape to (K*A, 4) shifted anchors # return (K*A, 4) # !TODO: add support for torch.CudaTensor # xp = cuda.get_array_module(anchor_base) # it seems that it can't be boosed using GPU import numpy as xp shift_y = xp.arange(0, height * feat_stride, feat_stride) shift_x = xp.arange(0, width * feat_stride, feat_stride) shift_x, shift_y = xp.meshgrid(shift_x, shift_y) shift = xp.stack((shift_y.ravel(), shift_x.ravel(), shift_y.ravel(), shift_x.ravel()), axis=1) A = anchor_base.shape[0] K = shift.shape[0] anchor = anchor_base.reshape((1, A, 4)) + \ shift.reshape((1, K, 4)).transpose((1, 0, 2)) anchor = anchor.reshape((K * A, 4)).astype(np.float32) return anchor def _enumerate_shifted_anchor_torch(anchor_base, feat_stride, height, width): # Enumerate all shifted anchors: # # add A anchors (1, A, 4) to # cell K shifts (K, 1, 4) to get # shift anchors (K, A, 4) # reshape to (K*A, 4) shifted anchors # return (K*A, 4) # !TODO: add support for torch.CudaTensor # xp = cuda.get_array_module(anchor_base) import torch as t shift_y = t.arange(0, height * feat_stride, feat_stride) shift_x = t.arange(0, width * feat_stride, feat_stride) shift_x, shift_y = xp.meshgrid(shift_x, shift_y) shift = xp.stack((shift_y.ravel(), shift_x.ravel(), shift_y.ravel(), shift_x.ravel()), axis=1) A = anchor_base.shape[0] K = shift.shape[0] anchor = anchor_base.reshape((1, A, 4)) + \ shift.reshape((1, K, 4)).transpose((1, 0, 2)) anchor = anchor.reshape((K * A, 4)).astype(np.float32) return anchor def normal_init(m, mean, stddev, truncated=False): """ weight initalizer: truncated normal and random normal. """ # x is a parameter if truncated: m.weight.data.normal_().fmod_(2).mul_(stddev).add_(mean) # not a perfect approximation else: m.weight.data.normal_(mean, stddev) m.bias.data.zero_()
这个脚本主要利用之前介绍的类与函数实现RPN网络:RegionProposalNetwork
因为是网络,所以继承自pytorch中的nn.Module
RPN网络流程我们之前介绍过一部分,这里完整的实现整个网络。
首先初始化网络的结构:特征(N,512,h,w)输入进来(原图像的大小:16*h,16*w),首先是加pad的512个3*3大小卷积核,输出仍为(N,512,h,w)。然后左右两边各有一个1*1卷积。左路为18个1*1卷积,输出为(N,18,h,w),即所有anchor的0-1类别概率(h*w约为2400,h*w*9约为20000)。右路为36个1*1卷积,输出为(N,36,h,w),即所有anchor的回归位置参数。
前向传播:输入特征即feature map,调用函数_enumerate_shifted_anchor生成全部20000个anchor。然后特征经过卷积,在经过两路卷积分别输出rpn_locs, rpn_scores。然后rpn_locs, rpn_scores作为ProposalCreator的输入产生2000个rois,同时还有 roi_indices,这个 roi_indices在此代码中是多余的,因为我们实现的是batch_siae=1的网络,一个batch只会输入一张图象。如果多张图象的话就需要存储索引以找到对应图像的roi。
注:函数_enumerate_shifted_anchor 介绍过了,就是利用9个anchor_base来生成所有20000个anchor的坐标。函数normal_init即对网络权重初始化。
3. faster_rcnn.py
from __future__ import division import torch as t import numpy as np import cupy as cp from utils import array_tool as at from model.utils.bbox_tools import loc2bbox from model.utils.nms import non_maximum_suppression from torch import nn from data.dataset import preprocess from torch.nn import functional as F from utils.config import opt class FasterRCNN(nn.Module): """Base class for Faster R-CNN. This is a base class for Faster R-CNN links supporting object detection API [#]_. The following three stages constitute Faster R-CNN. 1. **Feature extraction**: Images are taken and their \ feature maps are calculated. 2. **Region Proposal Networks**: Given the feature maps calculated in \ the previous stage, produce set of RoIs around objects. 3. **Localization and Classification Heads**: Using feature maps that \ belong to the proposed RoIs, classify the categories of the objects \ in the RoIs and improve localizations. Each stage is carried out by one of the callable :class:`torch.nn.Module` objects :obj:`feature`, :obj:`rpn` and :obj:`head`. There are two functions :meth:`predict` and :meth:`__call__` to conduct object detection. :meth:`predict` takes images and returns bounding boxes that are converted to image coordinates. This will be useful for a scenario when Faster R-CNN is treated as a black box function, for instance. :meth:`__call__` is provided for a scnerario when intermediate outputs are needed, for instance, for training and debugging. Links that support obejct detection API have method :meth:`predict` with the same interface. Please refer to :meth:`predict` for further details. .. [#] Shaoqing Ren, Kaiming He, Ross Girshick, Jian Sun. \ Faster R-CNN: Towards Real-Time Object Detection with \ Region Proposal Networks. NIPS 2015. Args: extractor (nn.Module): A module that takes a BCHW image array and returns feature maps. rpn (nn.Module): A module that has the same interface as :class:`model.region_proposal_network.RegionProposalNetwork`. Please refer to the documentation found there. head (nn.Module): A module that takes a BCHW variable, RoIs and batch indices for RoIs. This returns class dependent localization paramters and class scores. loc_normalize_mean (tuple of four floats): Mean values of localization estimates. loc_normalize_std (tupler of four floats): Standard deviation of localization estimates. """ def __init__(self, extractor, rpn, head, loc_normalize_mean = (0., 0., 0., 0.), loc_normalize_std = (0.1, 0.1, 0.2, 0.2) ): super(FasterRCNN, self).__init__() self.extractor = extractor self.rpn = rpn self.head = head # mean and std self.loc_normalize_mean = loc_normalize_mean self.loc_normalize_std = loc_normalize_std self.use_preset('evaluate') @property def n_class(self): # Total number of classes including the background. return self.head.n_class def forward(self, x, scale=1.): """Forward Faster R-CNN. Scaling paramter :obj:`scale` is used by RPN to determine the threshold to select small objects, which are going to be rejected irrespective of their confidence scores. Here are notations used. * :math:`N` is the number of batch size * :math:`R'` is the total number of RoIs produced across batches. \ Given :math:`R_i` proposed RoIs from the :math:`i` th image, \ :math:`R' = \\sum _{i=1} ^ N R_i`. * :math:`L` is the number of classes excluding the background. Classes are ordered by the background, the first class, ..., and the :math:`L` th class. Args: x (autograd.Variable): 4D image variable. scale (float): Amount of scaling applied to the raw image during preprocessing. Returns: Variable, Variable, array, array: Returns tuple of four values listed below. * **roi_cls_locs**: Offsets and scalings for the proposed RoIs. \ Its shape is :math:`(R', (L + 1) \\times 4)`. * **roi_scores**: Class predictions for the proposed RoIs. \ Its shape is :math:`(R', L + 1)`. * **rois**: RoIs proposed by RPN. Its shape is \ :math:`(R', 4)`. * **roi_indices**: Batch indices of RoIs. Its shape is \ :math:`(R',)`. """ img_size = x.shape[2:] h = self.extractor(x) rpn_locs, rpn_scores, rois, roi_indices, anchor = \ self.rpn(h, img_size, scale) roi_cls_locs, roi_scores = self.head( h, rois, roi_indices) return roi_cls_locs, roi_scores, rois, roi_indices def use_preset(self, preset): """Use the given preset during prediction. This method changes values of :obj:`self.nms_thresh` and :obj:`self.score_thresh`. These values are a threshold value used for non maximum suppression and a threshold value to discard low confidence proposals in :meth:`predict`, respectively. If the attributes need to be changed to something other than the values provided in the presets, please modify them by directly accessing the public attributes. Args: preset ({'visualize', 'evaluate'): A string to determine the preset to use. """ if preset == 'visualize': self.nms_thresh = 0.3 self.score_thresh = 0.7 elif preset == 'evaluate': self.nms_thresh = 0.3 self.score_thresh = 0.05 else: raise ValueError('preset must be visualize or evaluate') def _suppress(self, raw_cls_bbox, raw_prob): bbox = list() label = list() score = list() # skip cls_id = 0 because it is the background class for l in range(1, self.n_class): cls_bbox_l = raw_cls_bbox.reshape((-1, self.n_class, 4))[:, l, :] prob_l = raw_prob[:, l] mask = prob_l > self.score_thresh cls_bbox_l = cls_bbox_l[mask] prob_l = prob_l[mask] keep = non_maximum_suppression( cp.array(cls_bbox_l), self.nms_thresh, prob_l) keep = cp.asnumpy(keep) bbox.append(cls_bbox_l[keep]) # The labels are in [0, self.n_class - 2]. label.append((l - 1) * np.ones((len(keep),))) score.append(prob_l[keep]) bbox = np.concatenate(bbox, axis=0).astype(np.float32) label = np.concatenate(label, axis=0).astype(np.int32) score = np.concatenate(score, axis=0).astype(np.float32) return bbox, label, score def predict(self, imgs,sizes=None,visualize=False): """Detect objects from images. This method predicts objects for each image. Args: imgs (iterable of numpy.ndarray): Arrays holding images. All images are in CHW and RGB format and the range of their value is :math:`[0, 255]`. Returns: tuple of lists: This method returns a tuple of three lists, :obj:`(bboxes, labels, scores)`. * **bboxes**: A list of float arrays of shape :math:`(R, 4)`, \ where :math:`R` is the number of bounding boxes in a image. \ Each bouding box is organized by \ :math:`(y_{min}, x_{min}, y_{max}, x_{max})` \ in the second axis. * **labels** : A list of integer arrays of shape :math:`(R,)`. \ Each value indicates the class of the bounding box. \ Values are in range :math:`[0, L - 1]`, where :math:`L` is the \ number of the foreground classes. * **scores** : A list of float arrays of shape :math:`(R,)`. \ Each value indicates how confident the prediction is. """ self.eval() if visualize: self.use_preset('visualize') prepared_imgs = list() sizes = list() for img in imgs: size = img.shape[1:] img = preprocess(at.tonumpy(img)) prepared_imgs.append(img) sizes.append(size) else: prepared_imgs = imgs bboxes = list() labels = list() scores = list() for img, size in zip(prepared_imgs, sizes): img = t.autograd.Variable(at.totensor(img).float()[None], volatile=True) scale = img.shape[3] / size[1] roi_cls_loc, roi_scores, rois, _ = self(img, scale=scale) # We are assuming that batch size is 1. roi_score = roi_scores.data roi_cls_loc = roi_cls_loc.data roi = at.totensor(rois) / scale # Convert predictions to bounding boxes in image coordinates. # Bounding boxes are scaled to the scale of the input images. mean = t.Tensor(self.loc_normalize_mean).cuda(). \ repeat(self.n_class)[None] std = t.Tensor(self.loc_normalize_std).cuda(). \ repeat(self.n_class)[None] roi_cls_loc = (roi_cls_loc * std + mean) roi_cls_loc = roi_cls_loc.view(-1, self.n_class, 4) roi = roi.view(-1, 1, 4).expand_as(roi_cls_loc) cls_bbox = loc2bbox(at.tonumpy(roi).reshape((-1, 4)), at.tonumpy(roi_cls_loc).reshape((-1, 4))) cls_bbox = at.totensor(cls_bbox) cls_bbox = cls_bbox.view(-1, self.n_class * 4) # clip bounding box cls_bbox[:, 0::2] = (cls_bbox[:, 0::2]).clamp(min=0, max=size[0]) cls_bbox[:, 1::2] = (cls_bbox[:, 1::2]).clamp(min=0, max=size[1]) prob = at.tonumpy(F.softmax(at.tovariable(roi_score), dim=1)) raw_cls_bbox = at.tonumpy(cls_bbox) raw_prob = at.tonumpy(prob) bbox, label, score = self._suppress(raw_cls_bbox, raw_prob) bboxes.append(bbox) labels.append(label) scores.append(score) self.use_preset('evaluate') self.train() return bboxes, labels, scores def get_optimizer(self): """ return optimizer, It could be overwriten if you want to specify special optimizer """ lr = opt.lr params = [] for key, value in dict(self.named_parameters()).items(): if value.requires_grad: if 'bias' in key: params += [{'params': [value], 'lr': lr * 2, 'weight_decay': 0}] else: params += [{'params': [value], 'lr': lr, 'weight_decay': opt.weight_decay}] if opt.use_adam: self.optimizer = t.optim.Adam(params) else: self.optimizer = t.optim.SGD(params, momentum=0.9) return self.optimizer def scale_lr(self, decay=0.1): for param_group in self.optimizer.param_groups: param_group['lr'] *= decay return self.optimizer
此脚本定义了Faster-RCNN的基本类FasterRCNN。Faster-RCNN的三个步骤:
- 特征提取:输入一张图片得到其特征图feature map
- RPN:给定特征图后产生一系列RoIs
- 定位与分类:利用这些RoIs对应的特征图对这些RoIs中的类别进行分类,并提升定位精度
在类FasterRCNN中便初始化了这三个重要步骤:
- self.extractor
- self.rpn
- self.head
函数forward实现前向传播:
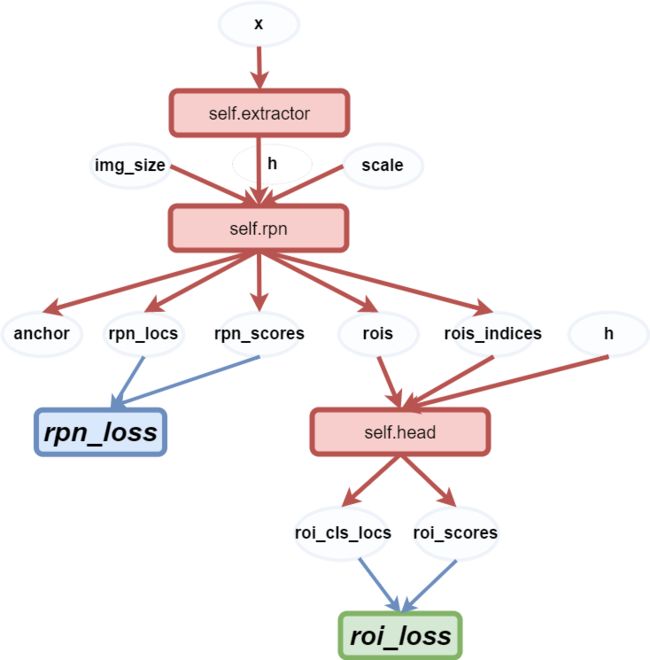

Faster-RCNN前向传播网络 边界框数量变化
注:AnchorTargetCreator和ProposalTargetCreator是为了生成训练的目标,只在训练阶段用到,ProposalCreator是RPN为Fast R-CNN生成RoIs,在训练和测试阶段都会用到。所以测试阶段ProposalCreator为Fast R-CNN生成了300个RoIs,不经ProposalCreator直接送给RoIHead网络。而训练阶段2000个RoI再经ProposalCreator得到128个RoI。(别忘了ProposalCreator的用途是为训练RoIHead网络分配ground truth的,测试阶段当然不需要了
预测过程:
函数predict实现了对测试集的图片预测,也是batch为1,即每次输入一张图片。
首先设置为eval()模式,然后对读入的图片求尺度scale,因为输入的图像经预处理就会有缩放,所以需记录缩放因子scale,这个缩放因子在ProposalCreator筛选roi时有用到,即将所有候选框按这个缩放因子映射回原图,超出原图边框的趋于将被截断。上图中经过前向传播后会输出roi_cls_locs和roi_scores。同时我们还需要输入到RoIhead的128个rois。因为ProposalCreator对loc做了归一化(-mean /std)处理,所以这里需要再*std+mean,此时的位置参数loc为roi_cls_loc。然后将这128个roi利用roi_cls_loc进行微调,得到新的cls_bbox。对于分类得分roi_scores,我们需要将其经过softmax后转为概率prob。值得注意的是我们此时得到的是对所有输入128个roi以及位置参数、得分的预处理,下面将筛选出最后最终的预测结果。
上面步骤是对网络RoIhead网络输出的预处理,函数_suppress将得到真正的预测结果。此函数是一个按类别的循环,l从1至20(0类为背景类)。即预测思想是按20个类别顺序依次验证,如果有满足该类的预测结果,则记录,否则转入下一类(一张图中也就几个类别而已)。例如筛选预测出第1类的结果,首先在cls_bbox中将所有128个预测第1类的bbox坐标找出,然后从prob中找出128个第1类的概率。因为阈值为0.7,也即概率>0.7的所有边框初步被判定预测正确,记录下来。然而可能有多个边框预测第1类中同一个物体,同类中一个物体只需一个边框,所以需再经基于类的NMS后使得每类每个物体只有一个边框,至此第1类预测完成,记录第1类的所有边框坐标、标签、置信度。接着下一类...,直至20类都记录下来,那么一张图片(也即一个batch)的预测也就结束了。
经测试,GTX1080、32G内存在可视化情况下,VOC2007 一个epoch:trainval 5011张36分钟完成,测试集test4952张13分钟完成。
最后定义了优化器optimizer:对于需要求导的参数 按照是否含bias赋予不同的学习率。默认是使用SGD,可选Adam,不过需更小的学习率。
4. faster_rcnn_vgg16.py
定义了类FasterRCNNVGG16,继承自上面的类FasterRCNN。
首先引入VGG16,然后拆分为特征提取网络和分类网络。冻结分类网络的前几层,不进行反向传播。
然后实现VGG16RoIHead网络。实现输入特征图、rois、roi_indices,输出roi_scls_locs和roi_scores。
类FasterRCNNVGG16分别对特征VGG16的特征提取部分、分类部分、RPN网络、VGG16RoIHead网络进行了实例化。
此外在对VGG16RoIHead网络的全连接层权重初始化过程中,按照图像是否为truncated分了两种初始化分方法。
Reference: