支持向量机(SVM)介绍
目标
本文档尝试解答如下问题:
- 如何使用OpenCV函数 CvSVM::train 训练一个SVM分类器, 以及用 CvSVM::predict 测试训练结果。
什么是支持向量机(SVM)?
支持向量机 (SVM) 是一个类分类器,正式的定义是一个能够将不同类样本在样本空间分隔的超平面。 换句话说,给定一些标记(label)好的训练样本 (监督式学习), SVM算法输出一个最优化的分隔超平面。
如何来界定一个超平面是不是最优的呢? 考虑如下问题:
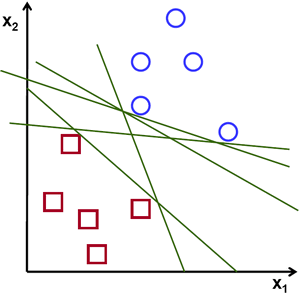
假设给定一些分属于两类的2维点,这些点可以通过直线分割, 我们要找到一条最优的分割线.
Note
在这个示例中,我们考虑卡迪尔平面内的点与线,而不是高维的向量与超平面。 这一简化是为了让我们以更加直觉的方式建立起对SVM概念的理解, 但是其基本的原理同样适用于更高维的样本分类情形。
在上面的图中, 你可以直觉的观察到有多种可能的直线可以将样本分开。 那是不是某条直线比其他的更加合适呢? 我们可以凭直觉来定义一条评价直线好坏的标准:
距离样本太近的直线不是最优的,因为这样的直线对噪声敏感度高,泛化性较差。 因此我们的目标是找到一条直线,离所有点的距离最远。
由此, SVM算法的实质是找出一个能够将某个值最大化的超平面,这个值就是超平面离所有训练样本的最小距离。这个最小距离用SVM术语来说叫做 间隔(margin) 。 概括一下,最优分割超平面 最大化 训练数据的间隔。
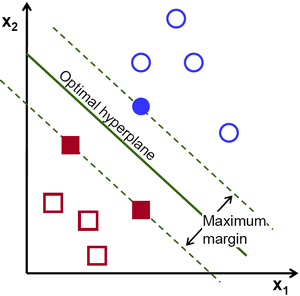
如何计算最优超平面?
下面的公式定义了超平面的表达式:
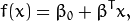
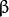 叫做 权重向量 ,
叫做 权重向量 , 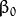 叫做 偏置(bias) 。
叫做 偏置(bias) 。
See also
关于超平面的更加详细的说明可以参考T. Hastie, R. Tibshirani 和 J. H. Friedman的书籍 Elements of Statistical Learning , section 4.5 (Seperating Hyperplanes)。
最优超平面可以有无数种表达方式,即通过任意的缩放 和 。 习惯上我们使用以下方式来表达最优超平面
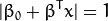
式中  表示离超平面最近的那些点。 这些点被称为 支持向量**。 该超平面也称为 **canonical 超平面.
表示离超平面最近的那些点。 这些点被称为 支持向量**。 该超平面也称为 **canonical 超平面.
通过几何学的知识,我们知道点 到超平面 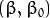 的距离为:
的距离为:
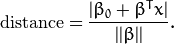
特别的,对于 canonical 超平面, 表达式中的分子为1,因此支持向量到canonical 超平面的距离是
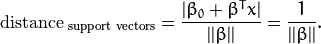
刚才我们介绍了间隔(margin),这里表示为 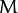 , 它的取值是最近距离的2倍:
, 它的取值是最近距离的2倍:
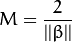
最后最大化 转化为在附加限制条件下最小化函数 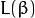 。 限制条件隐含超平面将所有训练样本
。 限制条件隐含超平面将所有训练样本 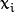 正确分类的条件,
正确分类的条件,

式中 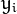 表示样本的类别标记。
表示样本的类别标记。
这是一个拉格朗日优化问题,可以通过拉格朗日乘数法得到最优超平面的权重向量 和偏置 。
源码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 |
#include |