FCOS论文以及代码详解(从头到尾带你过一遍代码)(1)
话不多说直接上论文标题和代码:
论文题目:FCOS: Fully Convolutional One-Stage Object Detection
论文链接:https://arxiv.org/abs/1904.01355.
代码链接:https://github.com/tianzhi0549/FCOS
我自己详细注释的代码链接:https://github.com/StiphyJay/FCOS_annotation_in_detail
论文核心思想:
该文章基于FCN实现了anchor-free的物体检测任务,并且方式更加简介,此外引入了中心度(centerness)的概念,可以有效降低一部分低质量的检测框的权重,实现更高精度的检测.
文章摘要:
 本文提出一种基于像素级预测一阶全卷积目标检测(FCOS)来解决目标检测问题,类似于语音分割。目前大多数先进的目标检测模型,例如RetinaNet、SSD、YOLOv3、Faster R-CNN都依赖于预先定义的锚框。相比之下,本文提出的FCOS是anchor box free,而且也是proposal free,就是不依赖预先定义的锚框或者提议区域。通过去除预先定义的锚框,FCOS完全的避免了关于锚框的复杂运算,例如训练过程中计算重叠度,而且节省了训练过程中的内存占用。更重要的是,本文避免了和锚框有关且对最终检测结果非常敏感的所有超参数。由于后处理只采用非极大值抑制(NMS),所以本文提出的FCOS比以往基于锚框的一阶检测器具有更加简单的优点。
本文提出一种基于像素级预测一阶全卷积目标检测(FCOS)来解决目标检测问题,类似于语音分割。目前大多数先进的目标检测模型,例如RetinaNet、SSD、YOLOv3、Faster R-CNN都依赖于预先定义的锚框。相比之下,本文提出的FCOS是anchor box free,而且也是proposal free,就是不依赖预先定义的锚框或者提议区域。通过去除预先定义的锚框,FCOS完全的避免了关于锚框的复杂运算,例如训练过程中计算重叠度,而且节省了训练过程中的内存占用。更重要的是,本文避免了和锚框有关且对最终检测结果非常敏感的所有超参数。由于后处理只采用非极大值抑制(NMS),所以本文提出的FCOS比以往基于锚框的一阶检测器具有更加简单的优点。
anchor-based方法
anchor-based的方法首先在Faster-RCNN里面被提出和应用,具体的内容我会在专栏得其他博客进行讲解。
anchor-based方法的缺点
1. 检测器的性能对于锚框的尺寸,长款比例以及数量非常敏感,因此锚框相关的超参数都需要非常仔细的调节。
2. 即使在小心的设计之后,因为锚框的尺寸和长宽比是固定的,检测器在处理形变较大的候选对象时比较困难,尤其是对于小目标。预先定义的锚框还限制了检测器的泛化能力,它们需要针对不同对象大小或长宽比进行设计。
3. 为了提高召回率,anchor-based检测器需要去在输入图像上稠密的放置anchor boxes,而大部分anchor boxes在训练期间被标记为负样本,造成了政府样本的不平衡.
4. 采用anchor boxes会引入和真值边框计算交并比(IOU),引入大量的计算,增加了计算量和内存占用.
FCOS方法的优点
1.FCOS的检测方法与许多其他基于FCN的任务(比如语义分割)是一样的,可以使得它更容易重用这些人物的思想。
2.检测不需要proposal和anchor,大大减少了设计参数的数量。而设计参数通常需要启发式调优,并且涉及到许多技巧,以便获得好的性能。 因此,我们的新检测框架使得检测器,特别是其训练,更加简单。
3. 通过消除anchor,检测器可以完全避免于锚框相关的复杂计算(例如锚框和真值框之间的IOU计算和匹配),可以更快的训练和测试,并且占用更少的内存。
4. FCOS在所有one-stage方法中实现了sota的性能,并且FCOS可以作为two-stage检测器的区域建议网络(RPN),实现优于基于锚点的RPN算法的性能。因此,锚框对于物件检测是否必要还需要重新思考。
5. FCOS还可以在轻微的修改后立即扩展到其他的视觉任务中,包括实例分割和关键点检测。
相关工作
基于锚框(two-stage)的检测器:Fast-RCNN, Faster-RCNN,SSD, YOLOv2。
无锚框(one-stage)的检测器:YOVOv1,CornerNet.
算法实现:
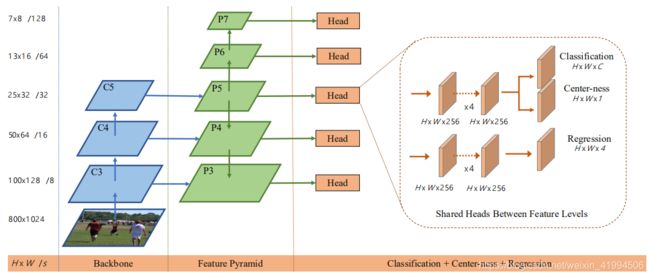 该方法一共有三部分组成,一个基础的特征提取网络(backbone),一个特征金字塔网络,一个head部分的得分与回归分支,来生成边界框和类别信息。
该方法一共有三部分组成,一个基础的特征提取网络(backbone),一个特征金字塔网络,一个head部分的得分与回归分支,来生成边界框和类别信息。
在此我们以一张800*1024大小的图片为例,介绍经过特征提取和特征金字塔之后每一层的特征维度,以及他们最后生成预测信息的特征维度。并介绍监督网络训练的真值是如何生成的。
代码解析:
github上面给出的训练模型的命令行指令如下:
python -m torch.distributed.launch \
--nproc_per_node=8 \
--master_port=$((RANDOM + 10000)) \
tools/train_net.py \
--config-file configs/fcos/fcos_imprv_R_50_FPN_1x.yaml \
DATALOADER.NUM_WORKERS 2 \
OUTPUT_DIR training_dir/fcos_imprv_R_50_FPN_1x
运行时首先进入到FCOS文件的目录下,再运行上述命令行.
运行后进入到tools/train_net.py文件下,文件中main函数代码如下:
# 解析命令行参数,例如--config-file
parser = argparse.ArgumentParser(description="PyTorch Object Detection Training")
parser.add_argument(
"--config-file", #配置文件
default="",
metavar="FILE",
help="path to config file",
type=str,
)
#此参数是通过torch.distributed.launch传递过来的,我们设置位置参数来接受
# local_rank代表当前程序进程使用的GPU标号
parser.add_argument("--local_rank", type=int, default=0)
parser.add_argument(
"--skip-test",
dest="skip_test",
help="Do not test the final model",
action="store_true",
)
parser.add_argument(
"opts",
help="Modify config options using the command-line",
default=None,
nargs=argparse.REMAINDER, #所有剩余的命令行参数都被收集到一个列表中
)
args = parser.parse_args()
#判断机器上gpu的数量,大于1时自动使用分布式训练
#world_size是由torch.distributed.launch.py产生
# 具体数值为 nproc_per_node*node(node就是主机数)
num_gpus = int(os.environ["WORLD_SIZE"]) if "WORLD_SIZE" in os.environ else 1 #判断当前系统环境变量中是否有"WORLD_SIZE" 如果没有num_gpus=1
args.distributed = num_gpus > 1 #False
if args.distributed: #False
torch.cuda.set_device(args.local_rank)
torch.distributed.init_process_group\
(
backend="nccl", init_method="env://"
)
synchronize()
#yacs的具体用法 可以参考印象笔记
#参数默认在fcos_core/config_defaults.py中 其余参数由config_file opts覆盖
cfg.merge_from_file(args.config_file) #从yaml文件中读取参数 即configs/fcos/fcos_R_50_FPN_1x.yaml
cfg.merge_from_list(args.opts) #也可以从命令行进行参数重写
cfg.freeze() #冻结参数 防止不小心被更改 cfg被传入train()
output_dir = cfg.OUTPUT_DIR #输出模型路径 存放一些日志信息
if output_dir:
mkdir(output_dir) #创建对应的输出路径
#写入日志文件 包括gpu数量,系统环境,配置文件参数等
logger = setup_logger("fcos_core", output_dir, get_rank())
logger.info("Using {} GPUs".format(num_gpus))
logger.info(args)
logger.info("Collecting env info (might take some time)")
logger.info("\n" + collect_env_info())
logger.info("Loaded configuration file {}".format(args.config_file))
with open(args.config_file, "r") as cf:
config_str = "\n" + cf.read()
logger.info(config_str)
logger.info("Running with config:\n{}".format(cfg))
model = train(cfg, args.local_rank, args.distributed) #local_rank=0 distributed=False
if not args.skip_test:
run_test(cfg, model, args.distributed)
整个训练过程中的参数读取有两个文件,一个是fcos_core/config/defaults.py ,一个是configs/fcos/fcos_R_50_FPN_1x.yaml,模型的训练代码是
model = train(cfg, args.local_rank, args.distributed)
通过此行代码调用同一个程序文件中的函数train(),该函数主要是以下几个部分:
第一部分
学习率,优化器,模型的训练配置等
model = build_detection_model(cfg) #实例化模型
device = torch.device(cfg.MODEL.DEVICE) #cfg.MODEL.DEVICE="cuda" 将torch.tensor分配到cuda 即GPU上
model.to(device) #将模型放在gpu上运行
optimizer = make_optimizer(cfg, model) # 定义网络训练优化器
scheduler = make_lr_scheduler(cfg, optimizer) #设置学习率
第二部分
数据集的加载
data_loader = make_data_loader(
cfg,
is_train=True,
is_distributed=distributed, #False
start_iter=arguments["iteration"], # 0
)
第三部分
然后进行训练:
do_train(
model,
data_loader,
optimizer,
scheduler,
checkpointer,
device,
checkpoint_period,
arguments,
)
在训练这部分,我们需要传入设置好参数的网络,已经加载好的数据集,优化器,学习率等等之类的参数.do_train()函数
是调用的fcos_core/engine/trainer.py文件中的函数:
def do_train(
model,
data_loader,
optimizer,
scheduler,
checkpointer,
device,
checkpoint_period,
arguments,
):
logger = logging.getLogger("fcos_core.trainer")
logger.info("Start training")
meters = MetricLogger(delimiter=" ")
max_iter = len(data_loader)
start_iter = arguments["iteration"] # 0
model.train()
start_training_time = time.time()
end = time.time()
pytorch_1_1_0_or_later = is_pytorch_1_1_0_or_later()
#从数据集中读取图片和对应的标签
for iteration, (images, targets, _) in enumerate(data_loader, start_iter):
data_time = time.time() - end
iteration = iteration + 1
arguments["iteration"] = iteration
# in pytorch >= 1.1.0, scheduler.step() should be run after optimizer.step()
if not pytorch_1_1_0_or_later:
scheduler.step()
images = images.to(device)
targets = [target.to(device) for target in targets]
# loss_dict 即为losses = {"loss_cls": loss_box_cls, "loss_reg": loss_box_reg, "loss_centerness": loss_centerness}
loss_dict = model(images, targets)
losses = sum(loss for loss in loss_dict.values()) #分类 回归 以及中心度部分的loss都相加和
# reduce losses over all GPUs for logging purposes
loss_dict_reduced = reduce_loss_dict(loss_dict)
losses_reduced = sum(loss for loss in loss_dict_reduced.values())
meters.update(loss=losses_reduced, **loss_dict_reduced)
optimizer.zero_grad()
losses.backward()
optimizer.step()
在上面的函数中关于读取数据以及标签,并进行训练的部分主要是一下几行代码:
for iteration, (images, targets, _) in enumerate(data_loader, start_iter):
images = images.to(device)
targets = [target.to(device) for target in targets]
loss_dict = model(images, targets)
因此,我们要去关注,images是如何产生的,targets是如何产生的,以及model这个模型的结构是什么,图像送入这个模型,会经过哪些网络,经过哪些维度变化.
下面,我们先介绍数据集方面的读取,本论文训练采用的是coco数据集
COCO数据集的下载网址:coco dataset 下载
回到train_net程序中,数据集的加载部分代码调用的为fcos_core/data/build.py:
paths_catalog = import_file(
"fcos_core.config.paths_catalog", cfg.PATHS_CATALOG, True)
DatasetCatalog = paths_catalog.DatasetCatalog
dataset_list = cfg.DATASETS.TRAIN if is_train else cfg.DATASETS.TEST
transforms = build_transforms(cfg, is_train)
datasets = build_dataset(dataset_list, transforms, DatasetCatalog, is_train)
通过上述代码生成训练网络的coco数据集列表,列表形式如下:
train: (“coco_2014_train”, “coco_2014_valminusminival”)
而后采用build_transforms函数对输入的图片进行随机水平分割,归一化等操作,最后再调用同一文件中的函数build_dataset来从数据集列表中读取图片数据.build_dataset函数中的部分代码如下:
for dataset_name in dataset_list:
data = dataset_catalog.get(dataset_name)
factory = getattr(D, data["factory"])
args = data["args"]
if data["factory"] == "COCODataset":
args["remove_images_without_annotations"] = is_train
if data["factory"] == "PascalVOCDataset":
args["use_difficult"] = not is_train
args["transforms"] = transforms
dataset = factory(**args)
这部分是输入数据集的列表,直接返回对应的数据集路径,第一行代码得到的data是一个字典,形式如下:
{‘factory’: ‘COCODataset’, ‘args’: {‘root’: ‘datasets/coco/val2014’, ‘ann_file’: ‘datasets/coco/annotations/instances_val2014.json’}},然后后面通过在字典中加入键值对,使得字典包含有一些其他信息.然后使用dataset = factory(**args)代码将字典中的数值取出,用于实例化factory这个类,而factory这个类对应的就是factory = getattr(D, data[“factory”]) 这段代码中的D这个类别,也就是对应的是fcos_core/data/datasets/coco.py程序中的COCODataset类.代码如下:
class COCODataset(torchvision.datasets.coco.CocoDetection):
def __init__(
self, ann_file, root, remove_images_without_annotations, transforms=None
):
super(COCODataset, self).__init__(root, ann_file)
self.ids = sorted(self.ids)
if remove_images_without_annotations:
ids = []
for img_id in self.ids:
ann_ids = self.coco.getAnnIds(imgIds=img_id, iscrowd=None)
anno = self.coco.loadAnns(ann_ids)
if has_valid_annotation(anno):
ids.append(img_id)
self.ids = ids
self.json_category_id_to_contiguous_id = {v: i + 1 for i, v in enumerate(self.coco.getCatIds())}
self.contiguous_category_id_to_json_id = {v: k for k, v in self.json_category_id_to_contiguous_id.items()}
self.id_to_img_map = {k: v for k, v in enumerate(self.ids)}
self.transforms = transforms
def __getitem__(self, idx):
img, anno = super(COCODataset, self).__getitem__(idx)
anno = [obj for obj in anno if obj["iscrowd"] == 0]
boxes = [obj["bbox"] for obj in anno]
boxes = torch.as_tensor(boxes).reshape(-1, 4)
target = BoxList(boxes, img.size, mode="xywh").convert("xyxy")
classes = [obj["category_id"] for obj in anno]
classes = [self.json_category_id_to_contiguous_id[c] for c in classes]
classes = torch.tensor(classes)
target.add_field("labels", classes)
masks = [obj["segmentation"] for obj in anno]
masks = SegmentationMask(masks, img.size, mode='poly')
target.add_field("masks", masks)
if anno and "keypoints" in anno[0]:
keypoints = [obj["keypoints"] for obj in anno]
keypoints = PersonKeypoints(keypoints, img.size)
target.add_field("keypoints", keypoints)
target = target.clip_to_image(remove_empty=True)
if self.transforms is not None:
img, target = self.transforms(img, target)
return img, target, idx
def get_img_info(self, index): #从图片id找到对应的图片信息
img_id = self.id_to_img_map[index]
img_data = self.coco.imgs[img_id]
return img_data
其中训练时候获取的图像images和真值targets数据都是从该类中的__getitem__获得的,该类通过读取对应的数据集真值,来获得一张图像的矩阵,以及对应的边界框角点,框中物体的类别ID.将这些数据存储在真值targets中.其中的img是通过继承torchvision.datasets.coco.CocoDetection这个类,直接从该类的__getitem__函数中获得的,torchvision.datasets.coco.CocoDetection类代码如下:
class CocoDetection(data.Dataset):
def __init__(self, root, annFile, transform=None, target_transform=None):
from pycocotools.coco import COCO
self.root = root
self.coco = COCO(annFile)
self.ids = list(self.coco.imgs.keys())
self.transform = transform
self.target_transform = target_transform
def __getitem__(self, index):
coco = self.coco
img_id = self.ids[index]
ann_ids = coco.getAnnIds(imgIds=img_id)
target = coco.loadAnns(ann_ids)
path = coco.loadImgs(img_id)[0]['file_name']
img = Image.open(os.path.join(self.root, path)).convert('RGB') #将图片转换成RGB格式
if self.transform is not None:
img = self.transform(img)
if self.target_transform is not None:
target = self.target_transform(target)
return img, target
torchvision.datasets.coco.CocoDetection.__getitem__函数,直接读取对应的图片id,然后从对应路径加载图片.
在获得images和targets之后,我们要做的就是把图像和目标一起送入网络看看,他们整体是如何经过网络进行运算的了.
关于网络运算部分,模型的搭建代码文件在fcos_core/modeling/detector/generalized_rcnn.py代码如下:
class GeneralizedRCNN(nn.Module):
def __init__(self, cfg):
super(GeneralizedRCNN, self).__init__()
self.backbone = build_backbone(cfg)
self.rpn = build_rpn(cfg, self.backbone.out_channels)
self.roi_heads = build_roi_heads(cfg, self.backbone.out_channels)
def forward(self, images, targets=None):
if self.training and targets is None:
raise ValueError("In training mode, targets should be passed")
images = to_image_list(images)
features = self.backbone(images.tensors)
proposals, proposal_losses = self.rpn(images, features, targets)
if self.roi_heads:
x, result, detector_losses = self.roi_heads(features, proposals, targets)
else:
x = features
result = proposals
detector_losses = {}
if self.training:
losses = {}
losses.update(detector_losses)
losses.update(proposal_losses)
return losses
return result
其中的backbone网络对应的代码为fcos_core/modeling/backbone/backbone.py 其对应的backbone部分函数构建对应的代码为:
def build_resnet_backbone(cfg):
body = resnet.ResNet(cfg)
model = nn.Sequential(OrderedDict([("body", body)]))
model.out_channels = cfg.MODEL.RESNETS.BACKBONE_OUT_CHANNELS #256 * 4
return model
resnet部分作为backbone的基础网络
暂时先写这么多,具体带有注释的代码,欢迎大家关注我的github主页.
https://github.com/StiphyJay/FCOS_annotation_in_detail
代码中有详实的注释和标注