Xgboost使用教程
文章目录
- 参数
- 通用参数(General Parameters)
- Booster参数(Booster Parameters)
- 学习目标参数(Task Parameters)
- 实例
- XGBClassifier
- XGBRegression
- 调参
参数
Xgboost的参数分为三种:
通用参数(General Parameters)
该参数控制在提升(boosting)过程中使用哪种booster,常用的booster有树模型(tree)和线性模型(linear model)。
| 参数 | 说明 |
|---|---|
| booster | 有两种模型可以选择gbtree和gblinear,[default=gbtree]。gbtree使用基于树的模型进行提升计算,gblinear使用线性模型进行提升计算 |
| silent | 取0时表示打印出运行时信息,取1时不打印运行时的信息。[default=0] |
| nthread | [default 当前系统可以获得的最大线程数] |
| num_feature | boosting过程中用到的特征维数,设置为特征个数。XGBoost会自动设置,不需要手工设置 |
Booster参数(Booster Parameters)
这取决于使用哪种booster。
(1)tree booster
| 参数 | 说明 |
|---|---|
| eta | [default=0.3],为了防止过拟合,更新过程中用到的收缩步长。在每次提升计算之后,算法会直接获得新特征的权重。 eta通过缩减特征的权重使提升计算过程更加保守。 |
| gamma | [default=0],模型在默认情况下,对于一个节点的划分只有在其loss function 得到结果大于0的情况下才进行,而gamma 给定了所需的最低loss function的值 |
| max_depth | [default=6],树的深度越大,则对数据的拟合程度越高(过拟合程度也越高)。即该参数也是控制过拟合,常取值:3-10 |
| min_child_weight | [default=1],孩子节点中最小的样本权重和。如果一个叶子节点的样本权重和小于min_child_weight则拆分过程结束。在现行回归模型中,这个参数是指建立每个模型所需要的最小样本数。调大这个参数能够控制过拟合,取值范围为: [0,∞] |
| max_delta_step | [default=0],通常不需要此参数 |
| subsample | [default=1],用于训练模型的子样本占整个样本集合的比例。如果设置为0.5则意味着XGBoost将随机的从整个样本集合中抽取出50%的子样本建立树模型,这能够防止过拟合。 |
| colsample_bytree | [default=1],在建立树时对特征随机采样的比例 |
| scale_pos_weight | [default=0],大于0的取值可以处理类别不平衡的情况。帮助模型更快收敛 |
(2)linear booster
| 参数 | 说明 |
|---|---|
| lambda | [default=0],L2 正则的惩罚系数 |
| alpha | [default=0],L1 正则的惩罚系数 |
| lambda_bias | [default=0],在偏置上的L2正则 |
学习目标参数(Task Parameters)
控制学习的场景,例如在回归问题中会使用不同的参数控制排序
| 参数 | 说明 |
|---|---|
| objective | [ default=reg:linear ],定义学习任务及相应的学习目标,可选的目标函数如下: “reg:linear”,线性回归(默认值)。 “reg:logistic”,逻辑回归。 “binary:logistic”,二分类的逻辑回归问题,输出为概率。 “multi:softmax”,采用softmax函数处理多分类问题,同时需要设置参数num_class用于指定类别个数 |
| eval_metric | 用于指定评估指标,可以传递各种评估方法组成的list。常用的评估指标如下: rmse’,用于回归任务 ‘mlogloss’,用于多分类任务 error’,用于二分类任务 ‘auc’,用于二分类任务 |
| seed | [ default=0 ],随机数的种子 |
| num_class | 用于设置多分类问题的类别个数。 |
实例
XGBClassifier
1、初始化模型
from xgboost import XGBClassifier
# 重要参数:
xgb_model = XGBClassifier(
max_depth=3,
learning_rate=0.1,
n_estimators=100, # 使用多少个弱分类器
objective='binary:logistic',
booster='gbtree',
gamma=0,
min_child_weight=1,
max_delta_step=0,
subsample=1,
colsample_bytree=1,
reg_alpha=0,
reg_lambda=1,
seed=None # 随机数种子
)
2、传入数据进行训练
xgb_model.fit(
X, # array, DataFrame 类型
y, # array, Series 类型
eval_set=None, # 用于评估的数据集,例如:[(X_train, y_train), (X_test, y_test)]
eval_metric=None, # 评估函数,字符串类型,例如:'mlogloss'
early_stopping_rounds=None,
verbose=True, # 间隔多少次迭代输出一次信息
xgb_model=None
)
3、预测
xgb_model.predict(data) # 返回预测值
xgb_model.predict_proba(data) # 返回各个样本属于各个类别的概率
具体实例如下:
from xgboost import XGBClassifier
from sklearn.datasets import load_iris
from xgboost import plot_importance
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 加载样本数据集
iris = load_iris()
X,y = iris.data,iris.target
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=12343)
model = XGBClassifier(
max_depth=3,
learning_rate=0.1,
n_estimators=100, # 使用多少个弱分类器
objective='multi:softmax',
booster='gbtree',
gamma=0,
min_child_weight=1,
max_delta_step=0,
subsample=1,
colsample_bytree=1,
reg_alpha=0,
reg_lambda=1,
seed=0 # 随机数种子
)
model.fit(X_train,y_train, eval_set=[(X_train, y_train), (X_test, y_test)],
eval_metric='mlogloss', verbose=50, early_stopping_rounds=50)
# 对测试集进行预测
y_pred = model.predict(X_test)
#计算准确率
accuracy = accuracy_score(y_test,y_pred)
print('accuracy:%2.f%%'%(accuracy*100))
# 显示重要特征
plot_importance(model)
plt.show()

XGBRegression
import xgboost as xgb
from xgboost import plot_importance
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_boston
from sklearn.metrics import mean_squared_error
# 导入数据集
boston = load_boston()
X ,y = boston.data,boston.target
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=0)
model = xgb.XGBRegressor(max_depth=3,
learning_rate=0.1,
n_estimators=100,
objective='reg:linear', # 此默认参数与 XGBClassifier 不同
booster='gbtree',
gamma=0,
min_child_weight=1,
subsample=1,
colsample_bytree=1,
reg_alpha=0,
reg_lambda=1,
random_state=0)
model.fit(X_train,y_train, eval_set=[(X_train, y_train), (X_test, y_test)],
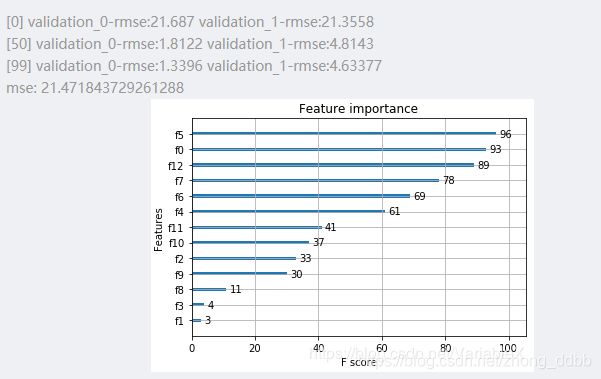
eval_metric='rmse', verbose=50, early_stopping_rounds=50)
# 对测试集进行预测
ans = model.predict(X_test)
mse = mean_squared_error(y_test,ans)
print('mse:', mse)
# 显示重要特征
plot_importance(model)
plt.show()
调参
此部分参考:机器学习系列(12)_XGBoost参数调优完全指南
为了确定boosting参数,我们要先给其它参数一个初始值。咱们先按如下方法取值:
1、max_depth = 5 :这个参数的取值最好在3-10之间。我选的起始值为5,但是你也可以选择其它的值。起始值在4-6之间都是不错的选择。
2、min_child_weight = 1:在这里选了一个比较小的值,因为这是一个极不平衡的分类问题。因此,某些叶子节点下的值会比较小。
3、gamma = 0: 起始值也可以选其它比较小的值,在0.1到0.2之间就可以。这个参数后继也是要调整的。
4、subsample, colsample_bytree = 0.8: 这个是最常见的初始值了。典型值的范围在0.5-0.9之间。
5、scale_pos_weight = 1: 这个值是因为类别十分不平衡。
第一步:确定学习速率和tree_based 参数调优的估计器数目
第二步: max_depth 和 min_weight 参数调优
第三步:gamma参数调优
第四步:调整subsample 和 colsample_bytree 参数
第五步:正则化参数调优