朴素贝叶斯+Python3实现高斯朴素贝叶斯
1. 什么是朴素贝叶斯法
朴素贝叶斯(naive Bayes)法是基于贝叶斯定理与特征条件独立假设的分类方法。对于给定的训练数据集,首先基于特征条件独立假设学习输入输出的联合概率分布;然后基于此模型,对给定的输入x,利用贝叶斯定理求出后验概率最大的输出y。朴素贝叶斯法实现简单,学习与预测的效率都很高,是一种常用的方法。
先举个例子来了解贝叶斯原理
一个袋子里有10个球,其中6个黑球,4个白球;那么随机抓取一个黑球的概率是0.6
这种情况下我们是站在上帝的视角,即知道事情的全貌再做判断(有多少个黑球,白球)在现实生活中,其实我们很难知道事情的全貌。贝叶斯则从实际场景出发,提了一个问题:
如果我们事先不知道白球和黑球的比例而是通过我们摸出来的球的颜色,能判断判断出袋子里面黑白球的比例么?
贝叶斯原理就是在我们不了解所有客观事实的情况下,同样可以先估计一个值,然后根据实际结果不断进行改正。
再来了解几个概率论理论后面会用到
先验概率:
通过经验判断实际发生的概率,比如说“佝偻病”的发病率是万分之一,就是先验概率。
后验概率:
后验概率就是发生结果之后,推测原因的概率。比如说某人查出来患有“佝偻病”,那么患病的原因可能是A, B 或 C。患有“佝偻病”的原因A的概率就是后验概率
条件概率:
事件A 在另外一个事件B已经发生条件下的发生概率,表示P(A|B)
1.1 基本方法
设输入空间X ⊆ \subseteq ⊆ R n R^n Rn 为 n 维向量的集合,输出空间为类标记集合 y = {c1, c2, ·········,ck,}。
输入特征向量 x ∈ \in ∈ X, 输出为类标记(class label)y ∈ \in ∈ Y。X是定义在输入空间 X 上的随机向量,y 是定义在输出空间 Y 上的随机变量。P(X,Y)是 X 和 Y的联合概率分布。训练数据集
T = { (x1,y1), (x2,y2),…,(xN,yN)}
由 P(X , Y) 独立同分布产生。
朴素贝叶斯法通过训练数据集学习联合概率分布 P( X, Y)。具体的,学习以先验概率分布及条件概率分布。先验概率分布
P( Y = ck ),k = 1,2,…,K
条件概率分布
P ( X = x | Y = ck) = P( X(1) = x(1),…,X(n) = xn|Y = ck) , k = 1,2,… ,K
于是学习到联合概率分布P(X,Y)。
条件概率分布 P (X = x|Y = ck) 有指数级数量的参数,其估计实际是不可行的。
事实上,假设x(j) 可取之有Sj 个,j = 1,2,…,n, Y可取值有 K 个,那么参数个数为 K ∏ j = 1 n S j \prod_{j=1}^n Sj ∏j=1nSj。
朴素贝叶斯法对条件概率分布作了条件独立性的假设。由于这是一个较强的假设,朴素贝叶斯法也由此得名。具体的,条件独立性假设是
P ( X = x | Y = ck) = P( X(1) = x(1),…,X(n) = xn|Y = ck) = ∏ j = 1 n \prod_{j=1}^n ∏j=1nP( X( j ) = x( j )|Y = ck)
朴素贝叶斯法实际上学习到生成数据的机制,所以属于生成模型。条件独立建设等于是说实例的各个特征之间互不影响。这一假设是朴素贝叶斯法变得简单,但有时会牺牲一定的分类准确率。
朴素贝叶斯分类时,对给定的输入 x, 通过学习到的模型计算后验概率分布P( Y = ck | X = x) , 将后验概率最大的类作为 x 的类输出。后验概率计算根据贝叶斯定理进行:
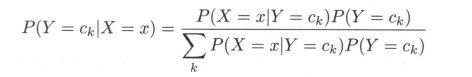
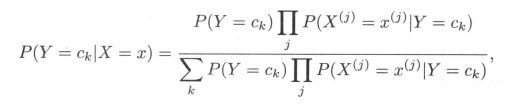
这是朴素贝叶斯法分类的基本公式。于是,朴素贝叶斯分类器可表示为
 注意到,在上式中分母对所有ck 都是相同的,所以,
注意到,在上式中分母对所有ck 都是相同的,所以,
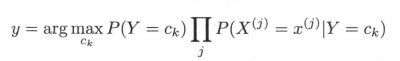
1.2 后验概率最大化的含义
朴素贝叶斯法将实例分到后验概率最大的类中。这等价于期望风险最小化。假设选择0-1损失函数:
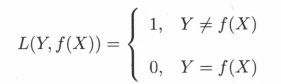
式中 f( X ) 是分类决策函数。这时,期望风险函数为
Rexp( f ) = E [ L ( Y, f ( X ) ) ]
期望是对联合分布P(X,Y)取的。由此取条件期望

这样一来,根据期望风险最小化准则就得到了后验概率最大化准则:
![]()
即朴素贝叶斯法所采用的原理
2. 朴素贝叶斯的参数估计
2.1.1 极大似然估计
在朴素贝叶斯法中,学习意味着估计 P(Y = ck) 和 P( X(j) = x(j) | Y = ck)。可以应用极大似然估计法估计相应的概率。先验概率P( Y = ck)的极大似然估计是
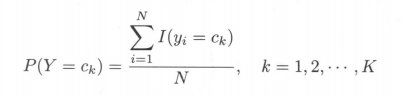
设第 j 个特征 x(j) 可能取值的集合为 {aj1,aj2,…,ajsj},条件概率P( X(j) = ajl | Y = ck)的极大似然估计是
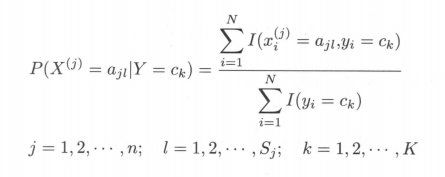
式中,xij 是第 i 个样本的第 j 个特征;ajl 是第 j 个特征可能取的第 l 个值;I 为指示函数。
2.1.2 学习与分类算法
下面给出偶素贝叶斯法的学习与分类算法
### 朴素贝叶斯算法(naive Bayes algorithm)
输入:训练数据 T = { (x1,y1), (x2,y2),…,(xN,yN)} ,其中 xi = (xi1,xi2,…,xin)T,xij 是第 i 个样本的第 j 个特征,xij ∈ \in ∈{ aj1,aj2,…,ajSj},ajl是第 j 个特征可能取的第 l 个值,j = 1,2,…,n,l = 1,2,… ,Sj,yi ∈ \in ∈{ c1, c2,…, ck};实例x;
输出:实例 x 的分类。
(1) 计算先验概率及条件概率
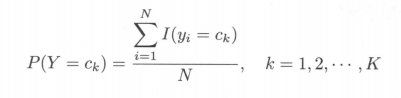

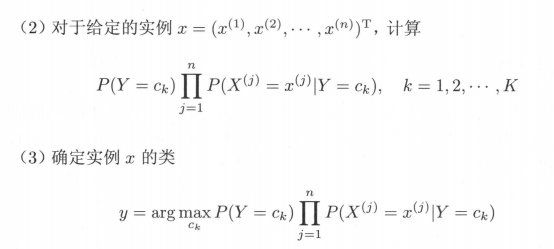
### 贝叶斯估计
用极大似然估计可能会出现所要估计的概率值为 0 的情况。这时会影响到后验概率的计算结果,使分类产生偏差。解决这一问题的方法是采用贝叶斯估计。具体地,条件概率的贝叶斯估计是
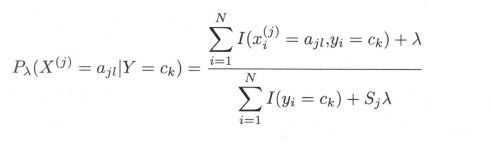
式中 λ \lambda λ >=0。等价于在随机变量各个取值的频数上赋予一个正数 λ \lambda λ > 0 。当 λ \lambda λ = 0时就是极大似然估计。常取 λ \lambda λ = 1,这时称为拉普拉斯平滑(Laplacian smoothing)。Sj为特征值可能取值的个数。显然,对任何 l = 1,2,…,Sj,k = 1,2,…,K,有
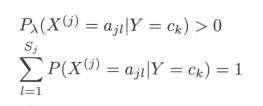
所以先验概率的贝叶斯估计是
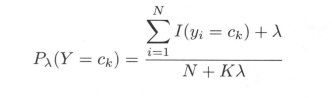
3. GaussianNB 高斯朴素贝叶斯+Python实现
特征的可能性假设为高斯
概率密度函数:
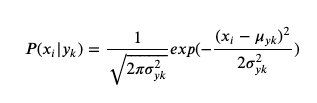
数学期望(mean):u
方差:
![]()
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from collections import Counter
import math
class NaiveBayes:
def __init__(self):
self.model = None
# 数学期望,踩坑,mean函数里不能加self,因为mean函数是静态方法
@staticmethod
def mean(X):
return sum(X) / float(len(X))
# 标准差
def stdev(self, x):
avg = self.mean(x)
return math.sqrt(sum([math.pow(i - avg, 2) for i in x]) / len(x))
# 高斯概密度函数
def gaussian_probability(self, x, mean, stdev):
ex = math.exp(-(pow(x - mean, 2) / (2 * pow(stdev, 2))))
return (1 / math.sqrt(2 * math.pi * pow(stdev, 2))) * ex
# 处理 X_train
def summarize(self, train_data):
summaries = [(self.mean(i), self.stdev(i)) for i in zip(*train_data)]
return summaries
# 分别求出数学期望和标准差
def fit(self, x, y):
# 利用集合不重复的特点,求出y可能的取值
labels = list(set(y))
data = {label: [] for label in labels}
for f, label in zip(x, y):
data[label].append(f)
#print(data.items())
self.model = {label: self.summarize(value) for label, value in data.items()}
return "ok"
# 计算概率
def calculate_probabilities(self, input_data):
# summaries:{0.0: [(5.0, 0.37),(3.42, 0.40)], 1.0: [(5.8, 0.449),(2.7, 0.27)]}
# input_data:[1.1, 2.2]
probabilities = {}
for label, value in self.model.items():
probabilities[label] = 1
for i in range(len(value)):
mean, stdev = value[i]
probabilities[label] *= self.gaussian_probability(input_data[i], mean, stdev)
return probabilities
# 类别
def predict(self, x_test):
# 将预测数据在所有类别中的概率进行排序,并取概率最高的类别
label = sorted(self.calculate_probabilities(x_test).items(), key=lambda x: x[-1])[-1][0]
return label
# 准确率
def score(self, x_test, y_test):
right = 0
for x, y in zip(x_test, y_test):
if self.predict(x) == y:
right += 1
return right / float(len(x_test))
if __name__ == '__main__':
# data
def create_data():
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['label'] = iris.target
df.columns = ['sepal length', 'sepal width', 'petal length', 'petal width', 'label']
data = np.array(df.iloc[:100, :])
# print(data)
return data[:, :-1], data[:, -1]
X, y = create_data()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
model = NaiveBayes()
model.fit(X_train, y_train)
print(model.predict([4.4, 3.2, 1.3, 0.2]))
print(model.score(X_test, y_test))
4. 总结
- 朴素贝叶斯法是典型的生成学习方法。生成方法由训练、数据学习联合概率分布
P(X, Y) 然后求得后验概率分布 P(YIX) 。具体来说,利用训练数据学习 P(XIY)
P(Y) 的估计,得到联合概率分布:
P(X, Y) = P(Y)P(XIY)
概率估计方法可以是极大似然估计或贝叶斯估计
- 朴素贝叶斯法的基本假设是条件独立性,
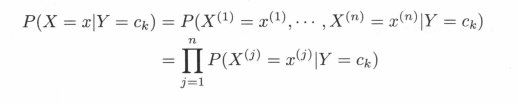
这是一个较强的假设。由于这一假设,模型包含的条件概率的数量大为减少,朴素贝
叶斯法的学习与预测大为简化。因而朴素贝叶斯法高效,且易于实现。其缺点是分类
的性能不一定很高。
- 朴素贝叶斯法利用贝叶斯定理与学到的联合概率模型进行分类预测。
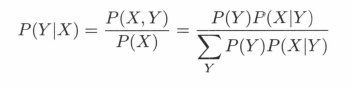
将输入 x 分到后验概率最大的类 y。
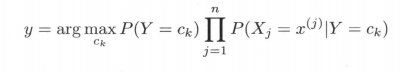
后验概率最大等价于0-1 损失函数时的期望风险最小化。
如果你觉得这篇文章有收获就给我点个赞吧!
下期预告:决策树
