数据分析——利用pandas库进行数据的清洗与处理
数据清洗与准备
有时候数据对于特定的任务来说格式并不正确,需要转化为更加适合的数据形式。这里介绍数据清洗的有关基础知识。
文章目录
- 数据清洗与准备
- 一.过滤缺失值
- 二.补全缺失值
- 三.数据转换
- 1.删除重复值
- 2.使用函数或映射进行数据转换
- 3.替代值
- 4.重命名轴索引
- 5.离散化和分箱
- 6.检查和过滤异常值
- 7.置换和随机抽样
- 8.计算指标/虚拟变量
- 其他关于数据处理的文章和pandas基础知识:
- 1.python——pandas库之Series数据结构基础
- 2.python——pandas库之DataFrame数据结构基础
- 3.python之日期与时间处理模块及利用pandas处理时间序列数据
- 4.利用python进行数据分析——使用groupby机制对pandas对象类的数据进行聚合与分组操作
- 利用python进行数据分析——第11章时间序列
一.过滤缺失值
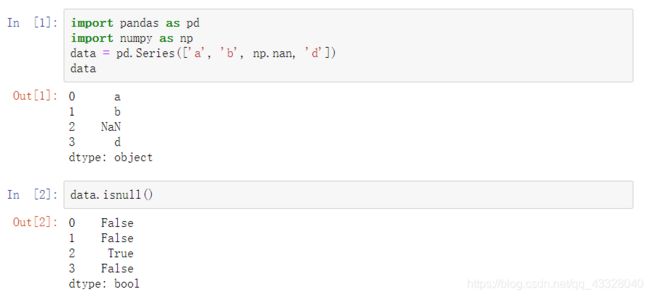
缺失数据在很多数据分析应用中都出现过,对于数值型数据,pandas使用浮 点值NaN来表示缺失值。可以用isnull()对一 个数组逐元素进行操作,返回布尔型判断结果,返回缺失值,而notnull()相反。
使用isnull来判断当前值是否为缺失值
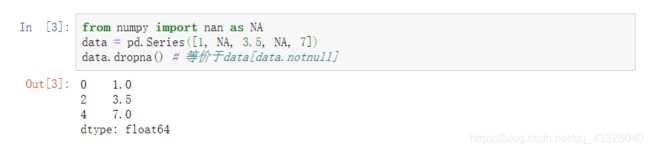
用dropna过滤缺失值是非常常见的,它会返回Series中所有的非空数据及其索引值,和data[data.notnull(0]是等价的。如下:
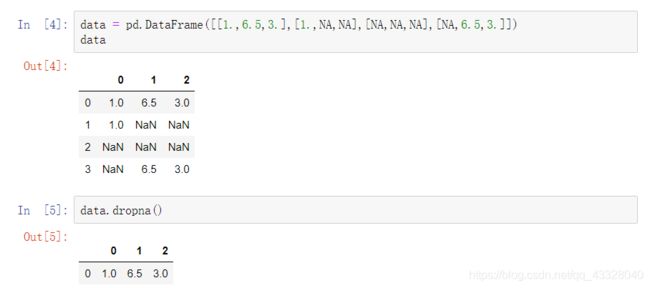
对于dataframe对象时,默认删除包含缺失值的行
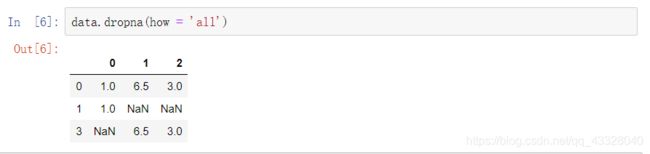
通过设置DataFrame对象中的参数how = ‘all’,将删除一行中所有值均为‘NA’的行
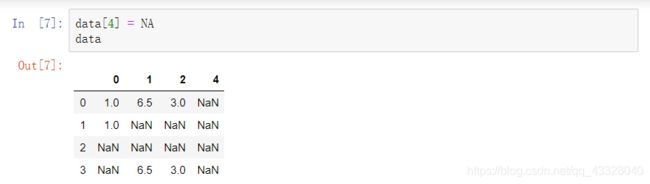
通过设置DataFrame对象中的参数axis = 1,将删除包含缺失值的列
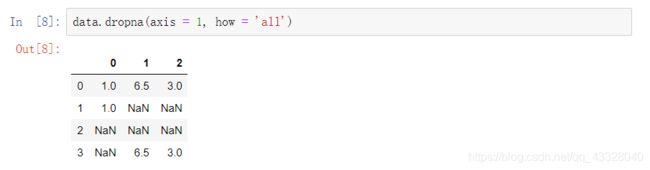
二.补全缺失值
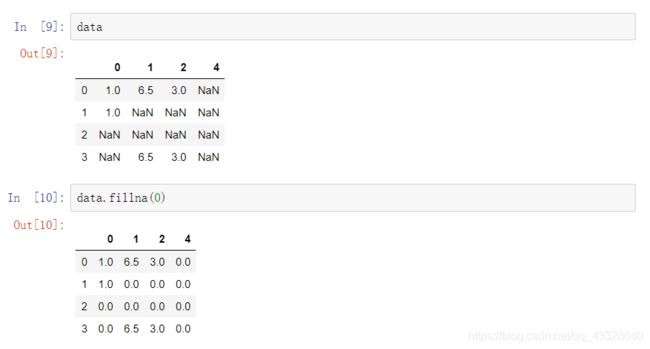
有时候需要用多种方法补全缺失值,而不是过滤缺失值,因为会丢弃其他数据。在大多数情况下,主要用fillna方法来补全缺失。里面可以用一个常数来替代缺失值。如下:
使用字典,对不同的列设定不同的填充值
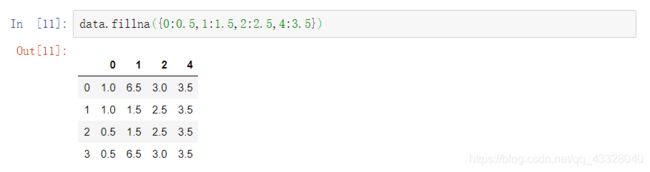
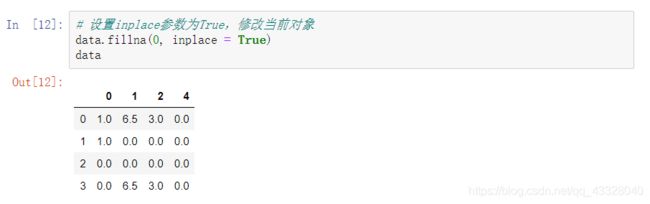
fillna返回的是一个新对象, 但也可以修改当前对象,设置参数inplace=True即可。
三.数据转换
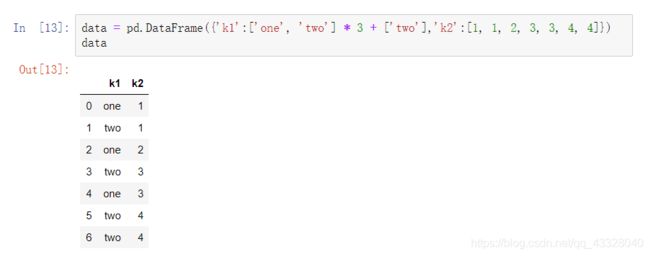
1.删除重复值
由于各种原因,DataFrame中会出现重复行,如下:
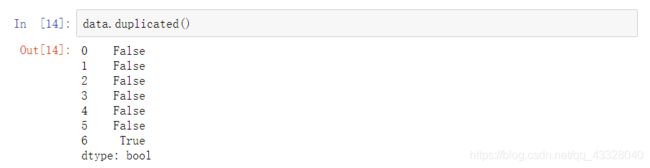
duplicated方法用于检查是否出现重复行(检查是否与之前出现过的行相同)
而drop_duplicates返回的是DataFrame对象,内容是duplicated返回数组中为False的部分。
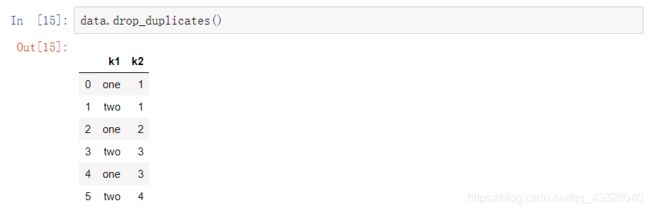
上面的方法默认是对列进行操作,可以在drop_duplicates方法的括号里边加入参数指定需要去除重复的列,加入参数keep = "last将会返回最后一个观测到的值。
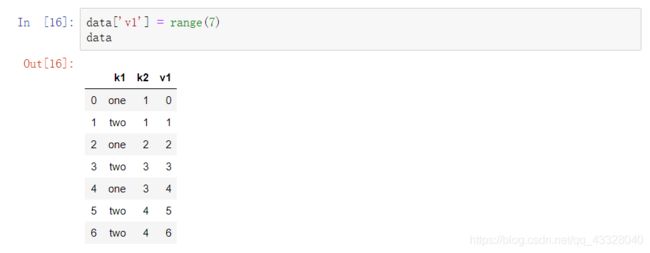
新添加一列:
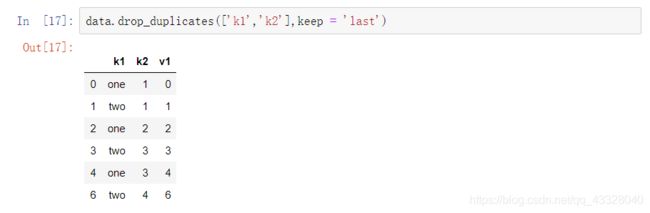
指定要检测的重复列
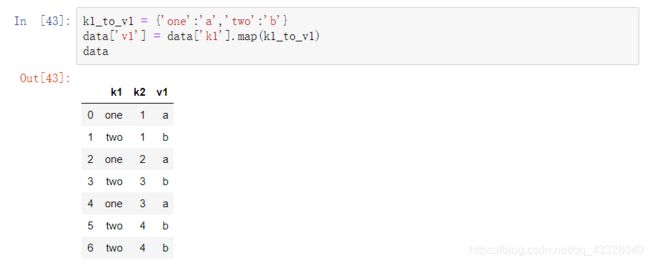
2.使用函数或映射进行数据转换
可以用map函数把一个函数或者包含映射关系的字典型对象加入到我们的数据列表中,如下:
3.替代值
可以用replace方法替换-些值,生成新的对象,也可以用字典的形式。
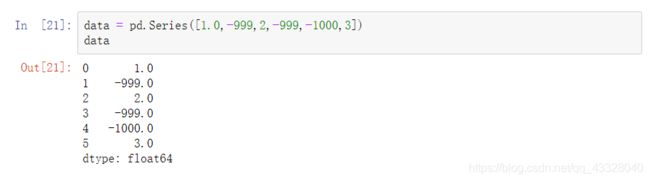
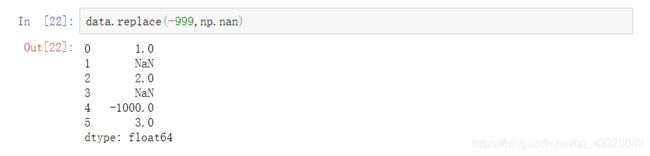
如果要替换多个值,可传入一个列表
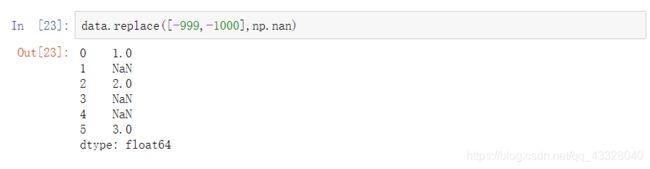
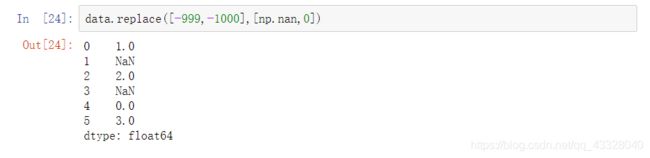
将不同的值替换为不同的值,可传入替换值的列表
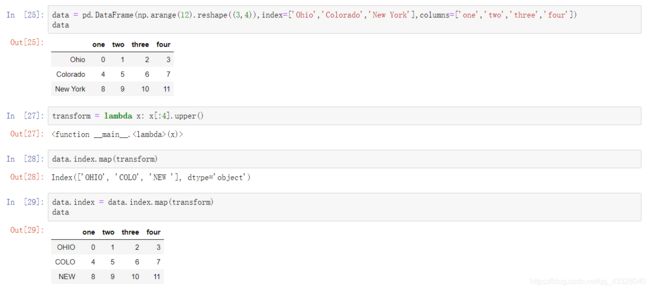
4.重命名轴索引
轴索引也有map方法,通过map方法对轴索引的名字进行改变
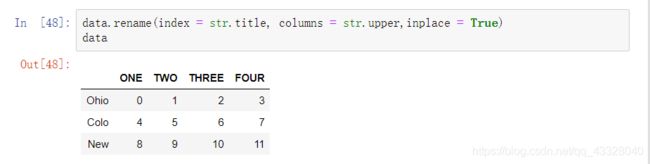
也可以使用rename方法,对轴索引的名字进行改变
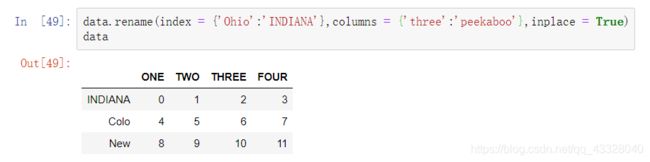
rename还可以与字典结合
5.离散化和分箱
连续值经常需要离散化,或者分离成多个‘箱子’进行分析。假设现在有一组人群的数据,准备将各个阶段的年龄进行分组,可以使用pandas中的cut方法

cut方法的有俩个参数,第一个参数表示要分类的数据,第二个参数相邻的俩个数构成一个‘箱子’,默认左开右闭
得到的cats是一个categories数组,使用其中的codes属性可以得到年龄的数据标签

使用categories方法,得到所有的‘箱子’

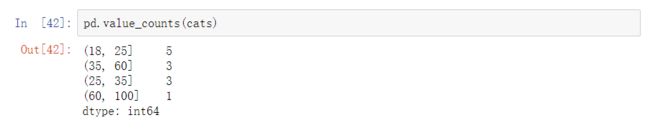
使用pd.value_counts(cats)得到各个箱子中数据的数量
通过设置参数right = False来改变那一边是封闭的

可以通过labels参数传递一个列表自定义箱名

当cut方法的第二个参数为整数n时,cut会将数据计算成n个等长的箱

6.检查和过滤异常值
现有一个具有正态分布数据的DataFrame:
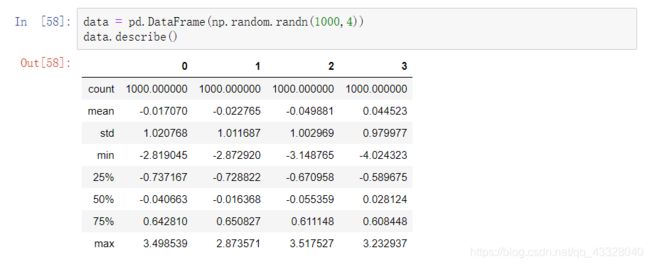
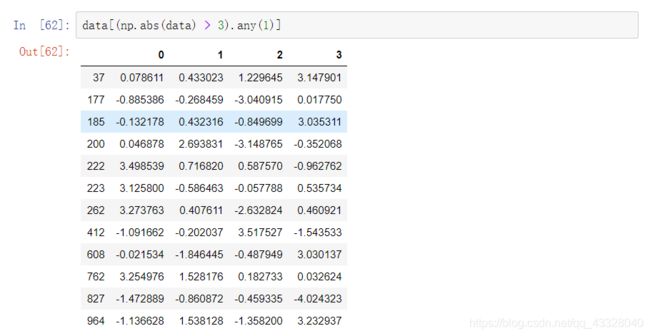
假设你想要的找出一列中绝对值大于三的值:

对布尔值的dataframe对象使用any方法,可以找出所有绝对值大于3的数
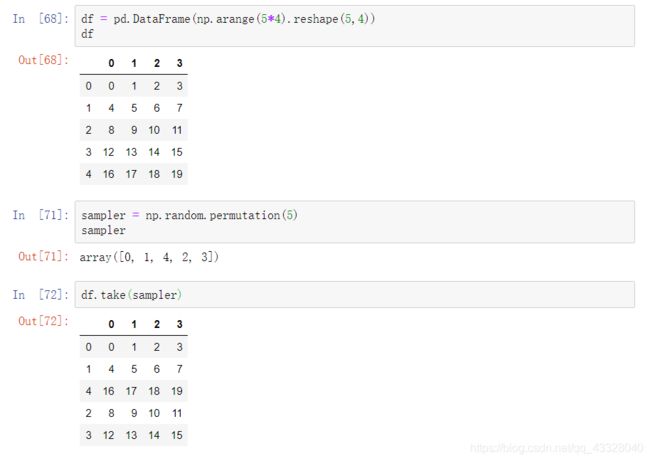
7.置换和随机抽样
使用numpy.random.permutation随机产生数据,可使用take函数或iloc函数对行索引的数据进行改变
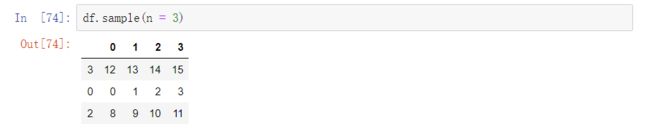
使用sample方法随机抽取不重复的子集
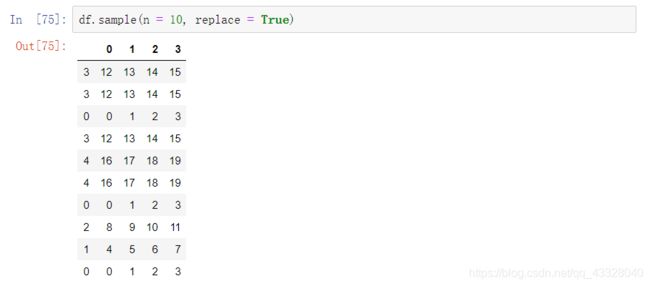
通过设置参数replace = True,允许sample方法随机抽取的数据有重复值
8.计算指标/虚拟变量
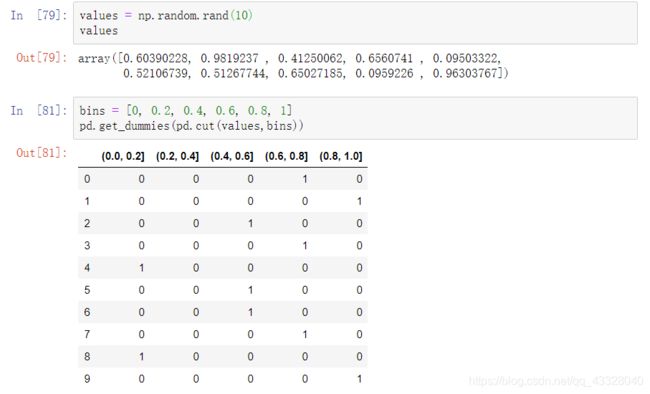
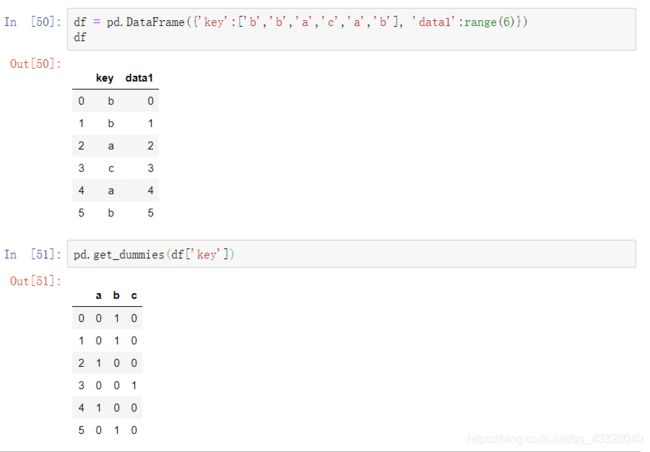
在dataframe中的一列有k个不同的值,可以通过getdummies方法衍生一个k列的值为1或0的矩阵
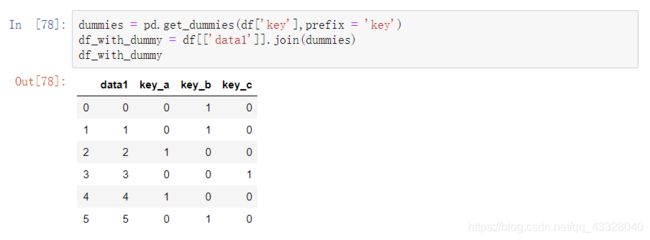
通过设置参数prefix为每一列上的变量设置前缀
将get_dummies与cut等离散化函数结合使用是统计应用的一个有用方法